

多层面分析 etcd 与 PostgreSQL数据存储方案的差异
存储技术
描述
从历史背景、数据模型、客户端接口、存储、分布式以及维护等多层面分析 etcd 与 PostgreSQL 的差异。
作者罗锦华,API7.ai 技术专家/技术工程师,开源项目 pgcat,lua-resty-ffi,lua-resty-inspect 的作者。
历史背景
PostgreSQL 的实现始于 1986 年,由伯克利大学的 Michael Stonebraker 教授领导。经过几十年的发展,PostgreSQL 堪称目前最先进的开源关系型数据库。它有自由宽松的许可证,任何人都可以免费使用、修改和分发 PostgreSQL,不管是私用、商用还是学术研究目的。
PostgreSQL 全方位支持 OLTP 和 OLAP,具有强大的 SQL 查询能力和大量扩展,能满足几乎所有商业需求,所以近年来越来越被受到重视。事实上,PostgreSQL 强大的扩展性和高性能使得它能模拟任何其他不同类型数据库的功能。
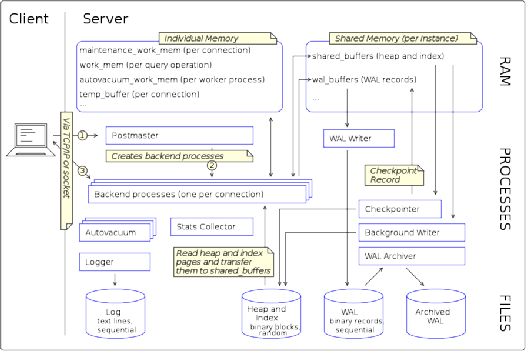
*图片来源(遵循 CC 3.0 BY-SA 版权协议)
而 etcd 又是如何诞生的呢?它解决了什么问题?
2013 年,有一个叫 CoreOS 的创业团队,他们构建了一个产品:Container Linux。它是一个开源、轻量级的操作系统,侧重自动化、快速部署应用服务,并要求应用程序都在容器中运行,同时提供集群化的管理方案,用户管理服务就像单机一样方便。
他们希望在重启任意一节点的时候,用户的服务不会因此而宕机,导致无法提供服务,因此需要运行多个副本。但是多个副本之间如何协调,如何避免变更的时候所有副本不可用呢?
为了解决这个问题,CoreOS 团队需要一个协调服务来存储服务配置信息、提供分布式锁等能力。怎么办呢?当然是分析业务场景、痛点、核心目标,然后是基于目标进行方案选型,评估是选择社区开源方案还是自己造轮子。这其实就是我们遇到棘手问题时的通用解决思路,CoreOS 团队同样如此。
一个协调服务,理想状态下大概需要满足以下五个目标:
1.高可用,数据多副本
2.数据一致性,数据副本之间的版本校对
3.低容量、仅存储关键元数据配置。协调服务保存的仅仅是服务、节点的配置信息(属于控制面配置),而不是与用户相关的数据,所以存储上不需要考虑数据分片,无需过度设计
4.功能:增删改查,监听数据变化的机制。协调服务保存了服务的状态信息,若服务有变更或异常,相比控制端定时去轮询检查一个个服务状态,若能快速推送变更事件给控制端,则可提升服务可用性、以及减少协调服务不必要的性能开销
5.运维复杂度
从 CAP 理论上来说,etcd 属于 CP 系统。
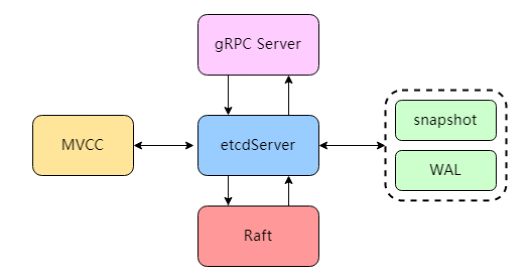
作为 kubernetes 集群的中枢组件 kube-apiserver 正是采用 etcd 作为底层存储。
一方面,k8s 集群中资源对象的创建都需要借助 etcd 来持久化;另一方面,正是 etcd 的数据 watch 机制,驱动着整个集群的 Informer 工作,从而达到源源不断的容器编排!因此,从技术角度说,Kubernetes 采用 etcd 的核心理由有:
1.etcd 采用 go 语言编写,和 k8s 技术栈一致,资源占用率低,部署异常简单。
2.etcd 的强一致性、watch、lease 等特性是 k8s 的核心依赖。
总而言之,etcd 是针对配置管理和分发这个特定需求而设计出来的分布式 KV 数据库,它是云原生软件,
开箱即用和高性能使得它在这个需求上优于传统数据库。
要比对 etcd 和 PostgreSQL 这两个不同类型的数据库,需要在同一个需求上去看才客观。
所以本文只针对配置管理这个需求来阐述两者的差异。
数据模型
不同数据库对用户所呈现的数据模型有所不同,它决定了数据库的适用场景。
key-value vs SQL
key-value 是 nosql 里面很流行的模型,也是 etcd 所采纳的设计,相比 SQL,它有什么好处呢?
我们先来看 SQL。
关系数据库维护表中的数据,提供了一种高效、直观和灵活的方式来存储和访问结构化信息。
表(也称为关系)由包含一个或多个数据类别的列和包含该类别定义的一组数据的行(也称为表记录)组成。应用程序通过指定查询来访问数据,这些查询使用诸如 project 之类的操作来标识属性、选择来标识元组以及连接来组合关系。数据库管理的关系模型是由 IBM 计算机科学家埃德加·科德在1970年开发的。
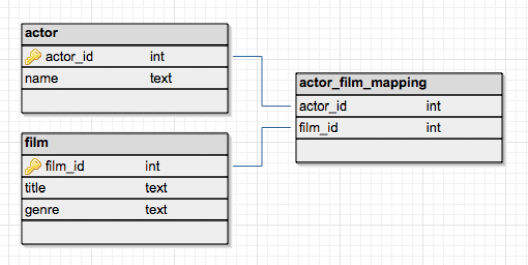
*图片来源(遵循 CC 3.0 BY-SA 版权协议)
每个表里面的记录没有唯一标识符,因为表被设计为可容纳多个重复行。如果需要做到 KV 查询,需要为表里面用作 key 的字段加上唯一索引。PostgreSQL 的索引默认是 btree,跟 etcd 一样,可以做 key 的范围查询。
结构化查询语言 (SQL) 是一种编程语言,用于在关系数据库中存储和处理信息。关系数据库以表格形式存储信息,行和列分别表示不同的数据属性和数据值之间的各种关系。您可以使用 SQL 语句从数据库中存储、更新、删除、搜索和检索信息。您还可以使用 SQL 来维护和优化数据库性能。
PostgreSQL 对 SQL 做了很多扩展,使得它是图灵完备的语言,使用 SQL 可以做任何复杂的操作,使得数据处理逻辑完全在服务端进行。
而 etcd 的定位是配置管理,配置数据一般是哈希表,所以将数据模型定位为 key-value,相当于只有全局一张大表,你可以对这张表进行增删查改。这张表只有两个字段,一个 key,一个 value,key 必须是唯一的,而且带有版本信息,而 value 的类型不做任何假设,所以客户端需要获取全量的 value 做进一步处理。
总的来说,etcd 的 kv 是而对 SQL 的简化,对于配置管理这个特定需求,更加方便和直观。
MVCC(多版本并发控制)
对于配置管理,数据版本化是其中一个刚需:
1.查询历史数据
2.通过比较版本可以知道数据的新旧
3.watch 数据需要以版本为根据,以便实现增量通知
etcd 和 PostgreSQL 都有 MVCC,但是它们的差异在哪里呢?
etcd 维护了一个全局递增的 64 位版本计数器(无需担心计数器溢出,因为即便一秒钟产生百万次更新,也需要几十万年才能用完),每个 key-value 在创建和更新的时候都会赋予版本。删除 key-value 时会创建一个墓碑,版本重置为0,也就是说,每次变更都产生新的版本,而不是原地更新。同时,etcd 保留了一个 key-value 的所有版本,并且对用户可见。此外,etcd 实现 MVCC 最大的好处是读写分离,读取数据无需加锁,满足了 etcd 以读为主的定位。
与 etcd 不同,PostgreSQL 的 MVCC 不是为了提供递增版本号,而是为了实现事务,也就是各类隔离级别,它对用户是透明的。MVCC 是一种乐观锁,它允许并发更新。表的每一行都有事务 ID 的记录,与 etcd 类似,xmin 对应了创建事务 ID,xmax 对应了更新事务 ID。
1.每个事务只能读取在它之前已经 commit 的事务
2.更新如果遇到版本冲突,会进行匹配重试,以决定是否更新
但是事务 ID 不能用于配置的版本控制,原因如下:
1.同一个事务内涉及到的所有行都被赋予同一个事务 ID,也就是说,它不是行级别的
2.只能读取最新版本的行,无法做历史查询
3.事务 ID 会变,因为事务 ID 是32位计数器,容易溢出,在 vacuum 的时候会被重置
4.无法根据事务 ID 实现 watch
所以 PostgreSQL 要做配置数据的版本控制,需要用其他形式来替代,没有开箱即用的支持。
客户端接口
接口设计决定了客户端的使用成本和资源消耗,通过分析接口差异,可以帮助我们如何选型。
etcd 提供了 kv/watch/lease API,实践证明它们特别满足配置管理的操作需求,那么在 PostgreSQL 上这些接口又如何实现呢?
PostgreSQL 对这些 API 没有开箱即用的功能,需要通过封装来实现,这里使用笔者开发的 pg_watch_demo 项目来做分析:
grpc/http vs tcp
PostgreSQL 是多进程架构,每个进程只能处理一个 tcp 连接,使用自定义协议通过 SQL 提供功能,采用一问一答的交互模型
(同一时间只能有一个查询执行中,类似 http1的同一时间只能处理一个请求,多个请求需要形成 pipeline),资源消耗大且比较低效,对于 QPS 大的场景需要前置连接池代理(例如 pgbouncer)来提高性能。
而 etcd 是 golang 的多协程架构,提供 grpc 和 restful 两种接口,使用方便,客户端容易集成;
资源消耗小,每条 grpc 连接可并发多个查询。
数据定义
etcd
message KeyValue {
bytes key = 1;
// 创建 key 的 revision
int64 create_revision = 2;
// 更新 key 的 revision
int64 mod_revision = 3;
// 版本递增计数器,每次更新递增,但是 delete 时会被清零用作墓碑
int64 version = 4;
bytes value = 5;
// key 使用的 lease 对象,用作 ttl,如果是0则没有 ttl
int64 lease = 6;
}
PostgreSQL
PostgreSQL 需要使用一个 table 来模拟 etcd 的全局数据空间:
CREATE TABLE IF NOT EXISTS config ( key text, value text, -- 等价于 `create_revision` 和 `mod_revision` -- 这里使用大整数的递增序列类型来模拟 revision revision bigserial, -- 墓碑 tombstone boolean NOT NULL DEFAULT false, -- 组合索引,先搜索 key,然后是 revision primary key(key, revision) );
get
etcd
etcd 的 get 参数比较丰富:
1.范围查询,例如 key 为 /abc,而 range_end 为 /abd,那么就可以获取以 /abc 为前缀的所有 key-value
2.历史查询,指定 revision,或者指定 mod_revision 范围
3.排序、限定返回数目
message RangeRequest {
...
bytes key = 1;
// 范围查询
bytes range_end = 2;
int64 limit = 3;
// 历史查询
int64 revision = 4;
// 排序
SortOrder sort_order = 5;
SortTarget sort_target = 6;
bool serializable = 7;
bool keys_only = 8;
bool count_only = 9;
// 历史查询
int64 min_mod_revision = 10;
int64 max_mod_revision = 11;
int64 min_create_revision = 12;
int64 max_create_revision = 13;
}
PostgreSQL
postgres 可以通过 SQL 完成 etcd 的 get 功能,甚至提供更多复杂的功能,因为 SQL 本身是语言,不是固定参数的接口可比拟的,这里简单展示只获取最新 revision 的 key-value。由于主键是组合索引,本身可以按范围搜索,所以速度会很快。
CREATE FUNCTION get1(kk text)
RETURNS table(r bigint, k text, v text, c bigint) AS $$
SELECT revision, key, value, create_time
FROM config
where key = kk and tombstone = false
ORDER BY key, revision desc
limit 1
$$ LANGUAGE sql;
put
etcd
message PutRequest {
bytes key = 1;
bytes value = 2;
int64 lease = 3;
// 是否返回修改前的 kv
bool prev_kv = 4;
bool ignore_value = 5;
bool ignore_lease = 6;
}
PostgreSQL
类似 etcd,更改不是原地执行,而是插入一个新行,赋予新的 revision。
CREATE FUNCTION set(k text, v text) RETURNS bigint AS $$ insert into config(key, value) values(k, v) returning revision; $$ LANGUAGE SQL;
delete
etcd
message DeleteRangeRequest {
bytes key = 1;
bytes range_end = 2;
bool prev_kv = 3;
}
PostgreSQL
类似 etcd,删除不是原地修改,而是插入一个新行,将 tombstone 字段设置为 true 以表示是墓碑。
CREATE FUNCTION del(k text) RETURNS bigint AS $$ insert into config(key, tombstone) values(k, true) returning revision; $$ LANGUAGE SQL;
watch
etcd
message WatchCreateRequest {
bytes key = 1;
// 指定 key 的范围
bytes range_end = 2;
// watch 的起始 revision
int64 start_revision = 3;
...
}
message WatchResponse {
ResponseHeader header = 1;
...
// 为了提高效率,可返回多个事件
repeated mvccpb.Event events = 11;
}
PostgreSQL
PostgreSQL 没有内置的 watch 功能,需要结合触发器和 channel 来实现。pg_notify 能将数据发送到侦听某个 channel 的所有应用程序
-- 触发器,用于 put/delete 事件的分发
CREATE FUNCTION notify_config_change() RETURNS TRIGGER AS $$
DECLARE
data json;
channel text;
is_channel_exist boolean;
BEGIN
IF (TG_OP = 'INSERT') THEN
-- 将改动用 JSON 编码
data = row_to_json(NEW);
-- 从 key 提取分发的 channel name
channel = (select SUBSTRING(NEW.key, '/(.*)/'));
-- 如果当前有应用在 watch,则通过 channel 发送事件
is_channel_exist = not pg_try_advisory_lock(9080);
if is_channel_exist then
PERFORM pg_notify(channel, data::text);
else
perform pg_advisory_unlock(9080);
end if;
END IF;
RETURN NULL; -- result is ignored since this is an AFTER trigger
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER notify_config_change
AFTER INSERT ON config
FOR EACH ROW EXECUTE FUNCTION notify_config_change();
由于是封装出来的 watch,所以需要客户端应用也要实现配合逻辑,以 golang 为例:
1.发起 listen。一旦 listen,所有 notify 数据会缓存起来(在 PostgreSQL 和 golang 的 channel 层面都可能存在缓存)
2.get_all(key_prefix, revision)。读取从指定 revision 开始的所有存量数据,每一个 key 只会返回最新 revision 数据,已删除的数据自动去除。也可以不指定 revision(这是最常见的情形),它会读取 key_prefix 前缀的所有 key 的最新数据。
3.watch 新数据,包括在第一步和第二步之间可能缓存起来的 notification,使得不错过这个时间窗口可能产生的新数据。对于已经在第二步读取过的 revision,在这步忽略掉。
func watch(l *pq.Listener) {
for {
select {
case n := <-l.Notify:
if n == nil {
log.Println("listener reconnected")
log.Printf("get all routes from rev %d including tombstones...
", latestRev)
// 重连的时候根据断开前的 revision 断点续传
str := fmt.Sprintf(`select * from get_all_from_rev_with_stale('/routes/', %d)`, latestRev)
rows, err := db.Query(str)
...
continue
}
...
// 应用要维护一个状态,里面记录已经接受到的最新的 revision
updateRoute(cfg)
case <-time.After(15 * time.Second):
log.Println("Received no events for 15 seconds, checking connection")
go func() {
// 长时间没收到事件,则检查一下连接是否健康
if err := l.Ping(); err != nil {
log.Println("listener ping error: ", err)
}
}()
}
}
}
log.Println("get all routes...")
// 应用在初始化的时候应该全量获取当前所有的 key-value,然后通过 watch 来增量监控更新
rows, err := db.Query(`select * from get_all('/routes/')`)
...
go watch(listener)
transaction
etcd
etcd 的事务是带有判断条件的多个操作的集合,事务做出的修改是原子提交的。
message TxnRequest {
// 指定事务执行条件
repeated Compare compare = 1;
// 条件满足要执行的多个操作
repeated RequestOp success = 2;
// 条件不满足要执行的多个操作
repeated RequestOp failure = 3;
}
PostgreSQL
用 DO 命令可以执行任何命令,包括存储过程,它支持很多语言,例如自带的 plpgsql、python 等,用这些语言可以实现任何条件判断、循环等控制逻辑,比 etcd 更丰富。
DO LANGUAGE plpgsql $$
DECLARE
n_plugins int;
BEGIN
SELECT COUNT(1) INTO n_plugins FROM get_all('/plugins/');
IF n_plugins = 0 THEN
perform set('/routes/1', 'foobar');
perform set('/upstream/1', 'foobar');
...
ELSE
...
END IF;
END;
$$;
lease
etcd
在 etcd 里面,可以创建 lease 对象,应用要定期去续约这个 lease 对象,使得它不过期。
每个 key-value 可以绑定一个 lease 对象,当 lease 对象过期时,所有绑定它的 key-value 都会过期,相当于自动被删除了。
message LeaseGrantRequest {
// lease 的存活时间
int64 TTL = 1;
int64 ID = 2;
}
// lease 续约
message LeaseKeepAliveRequest {
int64 ID = 1;
}
message PutRequest {
bytes key = 1;
bytes value = 2;
// lease ID,用于实现 ttl
int64 lease = 3;
...
}PostgreSQL
1.在 PostgreSQL 里面可以通过外键来维护 lease,查询的时候,如果有关联的 lease 对象且过期,则视为墓碑。
2.keepalive 请求更新 lease 表里面的 last_keepalive 时间戳。
CREATE TABLE IF NOT EXISTS config ( key text, value text, ... -- 通过外键来指定其绑定的 lease 对象 lease int64 references lease(id), ); CREATE TABLE IF NOT EXISTS lease ( id text, ttl int, last_keepalive timestamp; );
性能对比
PostgreSQL 需要通过封装来模拟 etcd 的各类 API,那么性能如何呢?
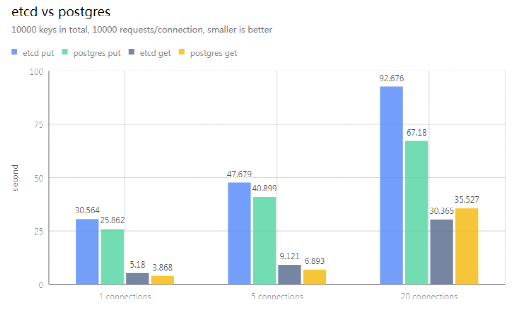
从结果可见,读写性能相差无几,而 PostgreSQL 甚至比 etcd 更快。
另外,一个更新从发生到应用接收到事件的延时决定了更新的分发效率,PostgreSQL 和 etcd 也是相差无几,客户端和服务端都在同一个机器测试时,watch 延时小于1毫秒。
但是 PostgreSQL 有如下缺陷值得说明:
1.每个更新对应的 WAL 日志更大,磁盘 IO 比 etcd 多一倍
2.CPU 耗费比 etcd 多
3.基于 channel 的 notify 是事务级别的概念,对同一类资源进行更新,就会将更新发往同一个 channel,更新请求之间会抢夺互斥锁,导致请求串行化,也就是说,通过 channel 实现 watch,会影响 put 的并行化
从这里也可以看到,为了实现同样的需求,我们对 PostgreSQL 需要更多的学习成本和优化成本。
存储
底层存储决定了性能,数据如何落地决定了数据库对内存、磁盘等资源的需求。
etcd
etcd 存储架构图:
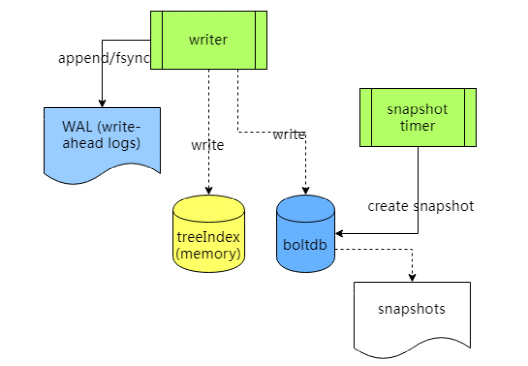
etcd 首先将更新写入日志(WAL,write-ahead log),并且刷到磁盘,以保证这笔更新不会丢失,一旦日志成功写入且经过大多数节点确认,就可以返回结果给客户端了。etcd 还会异步更新 treeIndex 和 boltdb。
为了避免日志的无限增长,etcd 定期对存储做快照,快照之前的日志可以被删掉。
etcd 对所有的 key 都在内存里面做索引(treeIndex),在其中记录每个 key 的版本信息,但是 value 只是保留对 boltdb 的指针(revision)。
而 key 对应的 value 则是保存在磁盘里面,使用 boltdb 来维护。
treeIndex 和 boltdb 都使用 btree 数据结构,众所周知,btree 对于查找和范围查找是高效的。
treeIndex 的结构图:
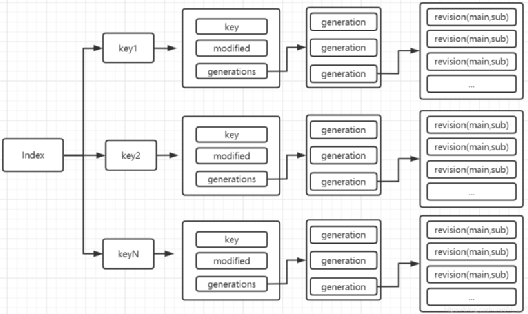
*图片来源(遵循 CC 4.0 BY-SA 版权协议):https://blog.csdn.net/H_L_S/article/details/112691481*
每个 key 被分为不同的 generation,每次删除结束一个 generation。
value 的指针由两个整数构成,第一个整数 main 是 etcd 的事务 ID,而第二个整数 sub 表示在该事务里对这个 key 的更新 ID。
boltdb 支持事务和快照,里面保存的是 revision 对应的值。
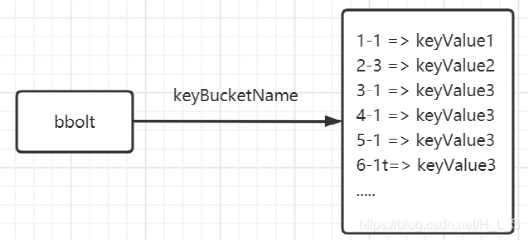
*图片来源(遵循 CC 4.0 BY-SA 版权协议)
写入数据示例:
写入 key="key1", revision=(12,1),value="keyvalue5",注意 treeIndex 和 boltdb 的红色部分变化:

*图片来源(遵循 CC 4.0 BY-SA 版权协议):https://blog.csdn.net/H_L_S/article/details/112691481*
删除 key="key",revision=(13,1),treeIndex 产生新的空的 generation,在 boltdb 生成一个空值,key="13_1t",
这里的 t 表示 tombstone(墓碑)。
这也暗含了你无法读取墓碑,因为 treeIndex 里面的指针是 (13,1),但 boltdb 里是 13_1t,无法匹配。

*图片来源(遵循 CC 4.0 BY-SA 版权协议)
值得注意的是,etcd 对 boltdb 的读写都由一个单独的 goroutine 来调度,以减少对磁盘的随机读写,提高 IO 性能。
PostgreSQL
PostgreSQL 的存储架构图:
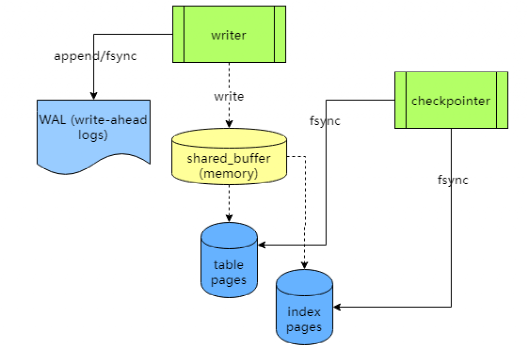
与 etcd 类似,PostgreSQL 首先将更新追加到日志文件,日志刷盘成功才表示事务完成,同时将更新写入 shared_buffer 内存。
shared_buffer 由所有表共享,它映射了表和索引。
PostgreSQL 里面每张表都由多个表页(page)文件组成,每个表页 8 KB,一个表页包含多个行。
除了表,索引(例如 btree 索引)也是由同样格式的表页文件组成,只不过这些表页文件比较特殊,互相关联形成树结构。
PostgreSQL 有一个 checkpointer 进程,会定时将所有表和索引的被更改的表页文件刷进磁盘,每个 checkpoint 之前的日志文件可以被删掉回收,避免日志无限增长。
表页结构:
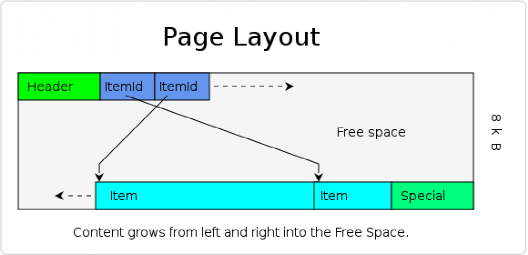
*图片来源(遵循 CC 3.0 BY-SA 版权协议)
索引的表页结构:
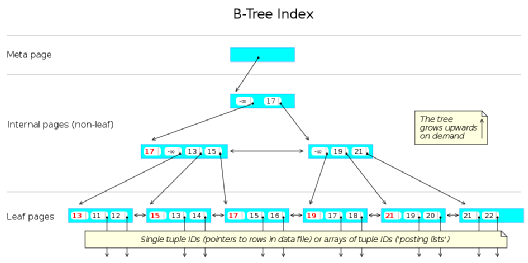
*图片来源(遵循 CC 3.0 BY-SA 版权协议)
由于表页文件的分散,为了提高读性能,某些 SQL 语句的查询计划会考虑通过位图使得表页读取被顺序化,提高 IO 性能:
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100;
QUERY PLAN
------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=5.07..229.20 rows=101 width=244)
Recheck Cond: (unique1 < 100)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0)
Index Cond: (unique1 < 100)
结论
PostgreSQL 和 etcd 的存储充分考虑了 IO 性能,而 etcd 更是将所有 key 的索引置于内存,它们也都考虑了磁盘顺序读写的批量操作优化。
所以你可以看到在上面的性能对比里面,PostgreSQL 和 etcd 的读写性能相差无几。
但是相比 PostgreSQL,etcd 要求更大的内存容量和更快的磁盘。
分布式
去中心化和数据一致性是 etcd 的特色,也是云原生的需求,而传统数据库如何满足这点?
etcd
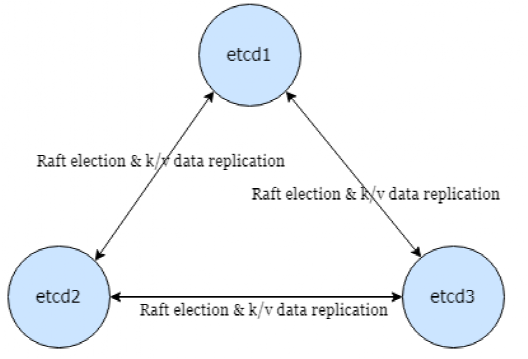
Raft是很流行的分布式协议,etcd 通过 raft 分发更新到多个节点,保证已提交数据被大多数节点确认过。
raft 有严谨正确的角色定义,角色切换图如下:
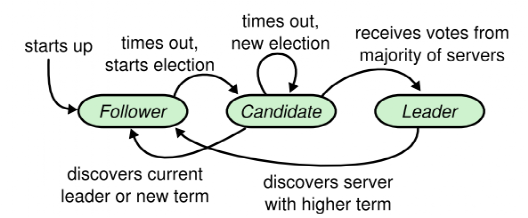
*图片来源(遵循 CC 3.0 BY-SA 版权协议)
默认情况下,所有读写都在 master 节点执行。
写要一致性这个好理解,但这里值得说明的是一致性读,它确保了读来自已提交数据,并且是数据的最新版本,每次读到的版本都等于或大于上一次读的版本。
一致性读的实现简单来说,就是 slave 节点从 master 节点获取最新版本,如果 slave 节点版本比 master 节点旧,则等待同步。
可见,etcd 的读写负担都落在 master 节点上,分布式只是保证可用副本和数据一致性,但是没有负载均衡。
PostgreSQL
PostgreSQL 是传统数据库出身,没有自带 raft 等分布式协议的实现,
但是它具备了集群化所需的数据复制特性,并且结合第三方的 raft 组件,
可以实现和 etcd 一模一样的分布式系统。
原生的 PostgreSQL 已经包含了以下基础特性:
1.synchronous commit
2.quorum replication
3.failover trigger
4.hot-standby
在主节点上的事务提交可配置为需要多个节点都确认才算提交成功,并且确认节点数可配置为大多数节点(quorum)。
数据复制的角色可以被切换(failover trigger),也有 pg_rewind 等工具可截除未被大多数节点确认的数据,以便重新加入集群。
hot-standby 则提供类似 etcd 那样的 serializable read,也就是能在从节点上读取已提交数据,但不保证是最新版本。
相关配置示例:
-- set quorum sync replication in postgresql.conf -- assume you have 5 nodes, then at least 2 standbys must be committed -- then you could tolerate 2 nodes failures synchronous_commit on synchronous_standby_names ="ANY 2 (*)" -- if master fails, check flushed lsn of each standby -- promote a standby with max lsn to master select flushed_lsn from pg_stat_wal_receiver;
PostgreSQL 在数据面上已经全面支持集群化,只需要在控制面提供 raft 组件即可实现去中心化的集群。笔者曾为多个商业客户提供 pg_raft 组件,该组件作为 PostgreSQL 的 worker process 运行,基于 raft 协议为 PostgreSQL 提供选主等集群管理功能。
维护
etcd 是为特定需求而设计的数据库,所以本身不需要怎么维护,这也是它的卖点之一。
另一方面,由于优秀的设计,PostgreSQL 相比其他关系数据库,
需要 DBA 维护的点比较少,而且类似 etcd,很多维护工作都是 PostgreSQL 内置和自动进行的。
数据库有很多维护的例行任务,这里只关注两点,compaction 和快照备份。
compaction
数据多版本化会使得数据库变得臃肿,读写效率变低,很多旧版本的数据当没有读取需要的时候应该要删除,并且要将删除后的空洞部分合并,这就是 compaction。
etcd 在 API 上提供了 compact 和 defrag 两个操作。
compact 用于删除某个 revision 之前的所有旧版本数据,注意如果覆盖了某些 key 的最新版本,则会保留最新版本,例如 compact 100,但是前面有一个 key=foo, revision=87 的 key-value,那么会保留它,但是会删除 key=foo, revision=65 的 key-value,说白了,compact 不会丢每个 key 的当前数据版本。
etcd 提供了 Auto Compaction 功能,例如可以指定每隔多少小时 compact 一次。
compact 会在 boltdb 留下空洞,所以需要 defrag 来整合它们,但是 defrag 会涉及大量 IO 和阻塞读写,需要谨慎进行。
另一方面,PostgreSQL 的 compact 也很简单,例如使用以下 SQL 删除 revision 为100之前的旧数据:
with alive as (
select r as revision from get_all('/routes/')
)
delete from config
where revision < 100 and not exists (
select 1 from alive where alive.revision = config.revision limit 1
);
如果需要定时执行,可使用 crontab 或者 pg_cron 来实现。
而数据库自身的 MVCC 清理,PostgreSQL 有自带的 vacuum 命令(vacuum full 对应 etcd 的 defrag),也有自动化的 autovacuum。
快照备份
快照备份可用于应急恢复,是数据库维护的刚需任务。
etcd 提供了 API 创建和恢复快照,例如:
$ etcdctl snapshot save backup.db $ etcdctl --write-out=table snapshot status backup.db +----------+----------+------------+------------+ | HASH | REVISION | TOTAL KEYS | TOTAL SIZE | +----------+----------+------------+------------+ | fe01cf57 | 10 | 7 | 2.1 MB | +----------+----------+------------+------------+ $ etcdctl snapshot restore backup.db
PostgreSQL 也有很完善的备份工具:
1.pg_basebackup 为新建 pg 从节点做数据准备
2.pgdump 在线克隆数据库实例,可选择备份哪些表
事实上,基于 WAL 和逻辑复制,PostgreSQL 还支持更高级的备份机制,
结论
PostgreSQL 是通用型的传统 SQL 数据库,etcd 是专用的分布式 KV 数据库。
相比 etcd 这类纯粹的数据存取系统,PostgreSQL 起码有如下额外好处:
1.丰富的鉴权机制,能实现完整的 RBAC 和细粒度的权限控制,支持多租户(多数据库实例),能过滤 IP,无需额外代理
2.SQL 自带 schema,支持外键,无需提供额外的控制面逻辑去保证数据的完备性
3.支持 JSON 类型的字段,支持基于 JSON 的索引和各类 JSON 操作,例如对路由配置进行索引以便做路由匹配
4.支持数据加密,也支持通过 fdw 访问 hashicorp vault 获取 secret
5.逻辑复制可实现多套独立集群之间的数据同步
6.有存储过程加持,可实现额外的功能,例如实现上游的慢启动
从功能上看,PostgreSQL 是 etcd 的超集,所以 PostgreSQL 可以通过其自带的丰富的基础功能和第三方组件来重现 etcd 的功能,也可以云化。
用 PostgreSQL 来实现 etcd 的功能,相当于将航母改造为巡航舰,技术上完全没问题,但如果没有超出 etcd 能力范围的需求,那么这种做法的性价比很低,因为开发成本和维护成本是不可忽视的事实。
etcd 最大的好处是开箱即用,满足了云原生时代对配置分发的需求,etcd 还可以用作应用选主、分布式锁、任务调度等功能的核心组件。
编辑:黄飞
- 相关推荐
- 数据存储
- 数据库
- postgresql
-
深入浅出谈多层面板布线技巧(1)——双面板2015-01-15 0
-
深入浅出谈多层面板布线技巧(3)——四层板2015-01-15 0
-
深入浅出谈多层面板布线技巧(4)——四层板2015-01-15 0
-
postgreSQL命令的词法分析和语法分析2019-05-16 0
-
云栖干货回顾 | 更强大的实时数仓构建能力!分析型数据库PostgreSQL 6.0新特性解读2019-10-23 0
-
RDS for PostgreSQL的插件的创建/删除和使用方法2022-04-25 0
-
ARM Neoverse IP的AWS实例上etcd分布式键对值存储性能提升2022-07-06 0
-
深入浅出谈多层面板布线技巧2016-12-13 564
-
PostgreSQL与MySQL在技术层面的比较2017-09-28 562
-
百度与重庆市政府共推进大数据融合创新发展,将展开多层面合作2019-08-28 1866
-
多层面认识SRAM2020-09-19 2432
-
基于卷积神经网络多层面二阶特征融合模型2021-04-12 611
-
如何快速完成PostgreSQL数据迁移?2023-08-14 2535
-
etcd的原理和应用2023-11-10 718
-
SQLite、MySQL和PostgreSQL的差异与应用场景2023-11-24 2344
全部0条评论

快来发表一下你的评论吧 !
