

日志结构存储下数据放置的方法浅析
存储技术
描述
日志结构存储在当今存储系统中被广泛使用,然而其中的垃圾回收会将有效数据重新写入导致写放大现象。现有最佳的数据放置策略是通过知道未来每个块的无效时间进行数据放置,然而无法在现实中实现。本篇工作提出一个新型的数据放置策略SepBIT,通过推测每个块的无效时间,来将无效时间相似的块放在一起,从而减少写放大并提高了I/O带宽。SepBIT目前已经被部署在了阿里云上。
01 背景
在基于日志结构存储中,数据被分为很多个段,而段中含有很多个块。当向其中写入数据时,会以块的粒度进行追加。当其中的数据进行更新的时候,也将会通过往后追加块的方式写入数据来实现异地更新。当一个段中数据写满的时候,数据将会写到下一个段中。由于采用了异地更新,因此当存储中的段都写满的时候,需要选择其中一个段,将其中的有效数据重新写入并进行擦除,通过这个方式来回收无效数据所占用的空间,这个过程就叫做垃圾回收(GC)。在这个过程中重新写入的有效页就是造成写放大的原因。为了降低写放大,现在最优的数据放置策略是通过预先知道所有数据的失效信息,从而将失效时间相似的数据放到一起。然而这个策略在现实中无法实现,这是因为1. 需要预先知道所有数据的失效时间是无法做到的;2. 同时需要维护很多可供写入的段地址,因此会带来很高的内存和存储开销。同时此时的随机写会带来性能下降。
02 动机
本文根据对阿里云和腾讯云真实负载的分析,探索其中有关于数据无效时间的发现。本文中的数据无效时间(寿命)定义为在两次数据写入中写入的数据量。其中选取了腾讯云的4995个负载,以及从阿里云1000个负载中筛选的186个以写为主的负载。本文得到了3个发现:
1. 用户写入的数据通常寿命较短。
据统计,超过一半的负载中超过79.5%的数据寿命低于负载集大小的80%,同时47.6%的数据寿命低于负载集大小的10%。其中负载集大小的定义为数据逻辑地址的范围。而通过GC重新写入的数据往往寿命较长。
2. 频繁更新的数据之间寿命差异较大。
发现2中统计了每个负载中更新频率最高的20%的数据,并分为四个区间1%,1-5%,5-10%和10-20%。据统计,有25%的负载中四个区间的变异系数(CV)分别为4.34,3.20,2.14和1.82,即他们之间寿命的差异性较大。其中变异系数的定义为(标准差/平均值)。这个发现也论证了现在有些根据数据更新频繁程度进行数据放置的策略并不能够很好的将具有相似失效时间的数据放到一起。
3. 很少更新的数据占主流,并且其中寿命的差距也很大。
发现3中将很少更新的数据定义为更新次数小于4次的数据。据统计,超过一半的负载中有超过72.4%的数据很少被更新。同时将很少更新数据通过无效时间划分为五个区间,小于0.5倍的负载集大小,0.5-1倍的负载集大小,1-1.5倍的负载集大小,1.5-2倍的负载集大小和大于2倍的负载集大小。据统计其中25%的工作负载中,超过71.5%的数据的寿命低于0.5倍的负载集大小。位于其余四个区间寿命数据量的均值为24.9%,8.1%,3.3%和2.2%。这就表示对于很少更新的数据,他们之间的寿命差异也较大。同样证明了以数据更新频繁度进行数据放置策略并不是十分有效的。
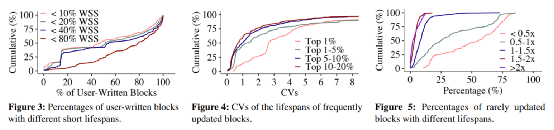
图1:SepBIT的三个发现
03 SepBIT设计
SepBIT是一个推测数据的无效时间来对数据进行放置的策略。根据发现1,SepBIT首先将数据分为用户数据和GC写入数据,因为它们之间的寿命差异较大。SepBIT将段分为六类,其中1类和2类用于分别存放寿命短和寿命长的用户数据,3类-6类用于存放GC写入的数据。其中3类存放的是通过GC写入的1类中的数据,而4-6类则存放的是通过GC写入的2类中的数据。
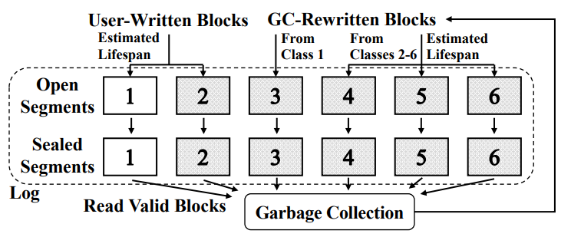
图2:SepBIT工作流程图
SepBIT通过对用户数据上一次写入与这一次写入之间的寿命,来推测这一次数据写入到下一次数据写入的寿命。同时通过对GC重写入数据与上一次用户写入数据的寿命,来推测下一次用户写入与这次GC重写入数据之间的寿命。以下分别通过数学模型和实验真实负载运行的结果来进行论证推测方法的有效性。
1. 推测用户数据的数据无效时间
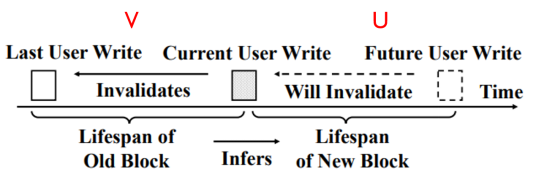
图3:推测用户数据的数据无效时间
数学分析: V为上一次和这次用户写入之间的寿命,U为这一次和下一次用户写入之间的寿命。通过计算条件概率公式,当V<=V0时,U<=U0时的概率,证明当V小的时候U也较小。则条件概率公式为:
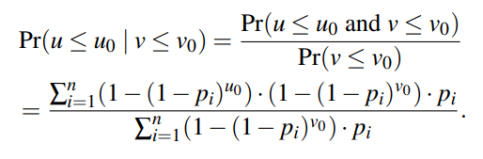
其中Pi为页面满足Zipf分布,即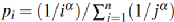 ,其中α越大,则表示工作负载越倾斜。通过调整U0,V0和α观察结果得出结论。
,其中α越大,则表示工作负载越倾斜。通过调整U0,V0和α观察结果得出结论。
1)设定α为1时,将U0和V0的阈值在短寿命范围内进行波动,即0.25-4GB之间,发现得到的条件概率最低为77.1%。即证明了V小的时候,U大概率也是较小的。
2)设定U0为1GB时,调整α和V0,发现当负载越倾斜时,条件概率越大,结论才越成立。
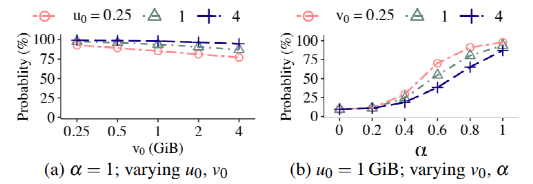
图4:通过数学分析推测用户数据写入无效时间的条件概率
负载分析:通过对真实负载进行运行,并对不同的V0和U0进行统计。发现在大多数的情况下条件概率都比较高。

图5:通过负载分析推测用户数据写入无效时间的条件概率
2. 推测GC重写入数据的数据无效时间
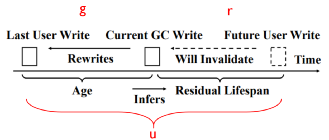
图6:推测GC重写入数据的数据无效时间
数学分析: g为上一次用户写入和这次GC重写入之间的寿命,r为这一次GC重写入和下一次用户写入之间的寿命,u为数据在上一次用户写入和下一次用户写入之间的寿命。通过计算条件概率公式,当u>=g=g0时,u<=g0+r0时的概率,证明寿命大于g0的数据剩余寿命(r)小于r0的概率。则条件概率公式为:
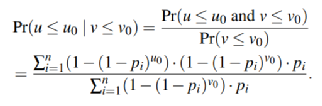
其中Pi也同样满足Zipf分布。通过调整g0,r0和α,得出结论如下。
1)设定α为1时,对于每一个r0来说,g0越小,条件概率越大。即不同年龄(g)的数据,其剩余寿命(r)的概率不同,即证明可以通过g来推测r的大小。
2)设定r0为8GB时,调整α和g0。发现,当负载越倾斜的时候,不同g0之间的条件概率差距越大,即越能够根据g来推测r的大小。
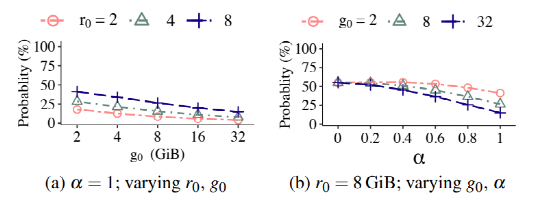
图7:通过数学分析推测GC数据写入无效时间的条件概率
负载分析:通过对真实负载进行运行,并对不同的g0和r0进行统计。发现固定r0时,对于不同的g0,条件概率差距较大。故而可以证明推论,可以根据g来推测r的大小。
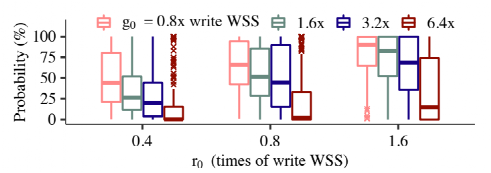
图8:通过负载分析推测GC数据写入无效时间的条件概率
最后,简单介绍下SepBIT的工作流程。
1. 垃圾回收:当剩余空间达到阈值的时候,垃圾回收将被触发。对于每个回收的1类段将计算该段的无效时间,每16个段计算一次平均段的无效时间作为阈值L。段中的有效数据将进行GC重写入。
2. 用户写入:对于用户写入数据,判断其上一次的寿命是否低于阈值L,若低于则写入1类段,否则写入2类段。
3. GC重写入:如果该数据是1类段中的数据,则写入3类段中。否则判断该数据的寿命。若其介于0-4L之间,则写入4类段;若介于4L-16L之间,则写入5类段;否则写入6类段中。
04 实验效果
论文作者团队将SepBIT实现在了基于ZenFS的zoned storage模拟平台上。其中后端使用的存储介质为Intel傲腾持久内存。并在其中使用真实的阿里云和腾讯云负载进行测试。其中段的大小和垃圾回收阈值设置为512MB和15%。
在实验中,本文与8个基于温度的数据放置策略进行比较,同时与无数据放置策略,本文的SepBIT和理想化的基于每个数据无效时间的FK进行比较。
通过最后的实验结果可以得出以下结论:
1.SepBIT对于不同GC策略、不同段大小下以及不同GC阈值下,均可以达到除FK以外最低的写放大。
2.SepBIT对于数据无效时间的推测较为精准。
3.通过消融实验,证明了SepBIT对于用户数据和GC数据分类的有效性。
4.SepBIT在腾讯云负载下的表现也是最好的。
5.SepBIT在高倾斜度负载下降低了较多的写放大。
6.SepBIT在大多数负载下对于内存的开销较低。
7.SepBIT对于大多数负载达到了较高的带宽。
基于空间限制,以下展示对于不同GC策略下,各个数据放置策略的写放大比较,如图9所示;以及SepBIT对于数据无效时间推测的准确性,如图10所示,其中纵坐标为累计分布,横坐标为垃圾回收时无效数据的比例,对于相同累计分布时,其无效数据比例越大说明预测越准确。
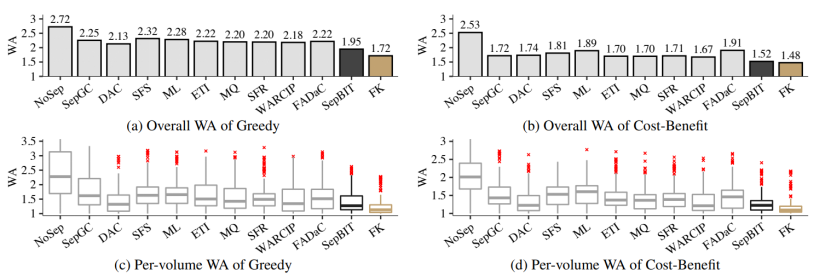
图9:不同GC策略下,各数据放置策略的写放大
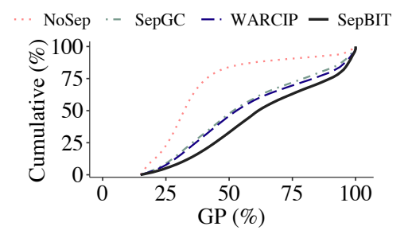
图10:不同策略对于数据无效时间推测的准确性
05 总结
SepBIT通过对真实负载的分析发现了用户写数据和GC重写入数据寿命的差异性,同时发现发现并验证了根据数据过去寿命推测数据接下来寿命的有效性。进而通过将具有相似寿命的数据放在一起从而降低写放大并提升I/O带宽。
审核编辑:刘清
- 相关推荐
- 存储器
-
万亿级日志与行为数据存储查询技术的两大步骤介绍2019-07-18 0
-
FlashDB如何解决存储数据后扩展数据结构的问题2022-11-14 0
-
用户自定义结构数据怎么存储成VARIANT类型2019-08-02 0
-
ARM存储器是如何存储数据的?2019-09-27 0
-
浅析51单片机存储器结构2021-12-01 0
-
有什么方法可以为SPIFF节省存储日志数据的空间吗?2023-03-01 0
-
信源定位方案中基于Bloom Filter存储的概率日志记录2010-02-10 513
-
浅析嵌入式存储系统设计方法2010-01-26 1107
-
云存储中动态副本放置机制研究2017-11-17 841
-
数据库课件教程之物理存储结构的详细资料说明2019-01-24 1086
-
一种基于区块链的日志安全存储方法2021-04-25 1009
-
NUMA架构下的内存数据库命令日志故障恢复2021-06-24 602
-
简易的嵌入式系统日志记录方法2022-10-31 1193
-
oracle数据库alert日志作用2023-12-06 1239
-
西门子博途数据日志的使用2023-12-20 4078
全部0条评论

快来发表一下你的评论吧 !
