

探索闪存内存如何应对“内存墙”的可行性
存储技术
描述
Source: Shao-Peng Yang, Minjae Kim, Sanghyun Nam, Juhyung Park, Jin-yong Choi, Eyee Hyun Nam, Eunji Lee, Sungjin Lee, Bryan S. Kim, Overcoming the MemoryWall with CXL-Enabled SSDs, July 10, 2023
本文探讨了使用廉价闪存内存(flash memory)在新型互连技术(如CXL)上以应对“内存墙”的可行性。我们探索了CXL启用的闪存设备的设计空间,并展示了缓存和预取等技术可以帮助缓解有关闪存性能和寿命的担忧。我们通过使用真实世界的应用程序跟踪数据展示,这些技术使得CXL设备的估计寿命至少为3.1年,并能在微秒级内满足68-91%的内存请求。我们分析了现有技术的局限性,并提出了系统层面的变更来实现使用闪存的DRAM级性能。
01. 引言
在计算系统中,计算能力和内存容量需求之间的日益不平衡发展成为一个称为“内存墙”的挑战[23,34,52]。图1基于Gholami等人的数据[34],并扩展了更多的最新数据[11,30,43],展示了自然语言处理(NLP)模型的快速增长(每年14.1倍),远远超过了内存容量的增长(每年1.3倍)。“内存墙”迫使现代数据密集型应用,如数据库[8,10,14,20]、数据分析[1,35]和机器学习(ML)[45,48,66],要么意识到它们的内存使用情况[61],要么实现用户级内存管理[66]以避免昂贵的页面交换[37,53]。因此,在透明处理应用程序的情况下突破“内存墙”是一个活跃的研究领域;已经积极探索了一些方法,如创建面向ML系统[45,48,61],构建内存解耦合框架[36,37,52,69]和设计新的内存架构[23,42]。
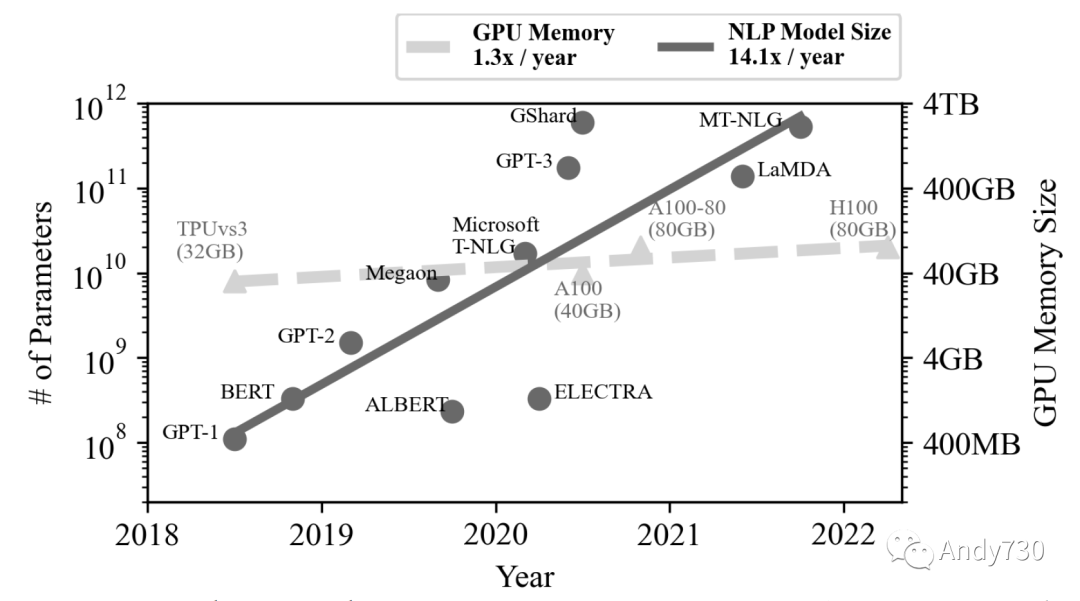
图1: NLP应用程序内存需求的趋势 [11,30,34,43]。每年参数数量增加了14.1倍,而GPU的内存容量每年只增长了1.3倍
我们探讨了是否可以使用闪存内存来突破“内存墙”——这是一种通常用于存储的内存技术,因为其具有高密度和容量扩展性[59]。虽然DRAM只能扩展到几GB的容量,但基于闪存的固态硬盘(SSD)可达到TB级的容量[23],足够大以应对“内存墙”的挑战。闪存内存作为主内存的使用得益于最近出现的诸如CXL[3]、Gen-Z[7]、CCIX[2]和OpenCAPI[12]的互连技术,它们允许通过load/store指令直接由CPU访问PCIe(Peripheral Component Interconnect Express)设备。此外,这些技术承诺具有出色的可扩展性,因为可以通过交换机连接更多的PCIe设备[13],而不像用于DRAM的DIMM(双列直插式内存模块)。
然而,将闪存内存作为CPU可访问的主内存面临着三个主要挑战。
首先,内存请求与闪存内存之间存在颗粒度不匹配。这导致了在闪存上需要存在明显的流量放大,除了已有的闪存间接性需求[23,33]之外:例如,将64B的缓存行刷新到CXL启用的闪存,将导致16KiB的闪存内存页面读取、64B更新和16KiB的闪存程序写入到另一个位置(假设16KiB的页面级映射)。
其次,闪存内存的速度仍然比DRAM慢几个数量级(几微秒对比几纳秒)[5,24]。因此,虽然两种技术之间的峰值数据传输速率相似[4,15],但长时间的闪存内存延迟阻碍了持续性性能,因为数据密集型应用最多只能容忍微秒级的延迟[53]。
最后,闪存内存具有有限的耐久性,在经过多次写入后会磨损[24,44]。这限制了内存技术的可用性,因为超过耐久性限制的闪存内存块会表现出不可靠的行为和高错误率[44]。
我们通过探索设计选择来解决上述闪存内存的挑战,特别是与缓存和预取相关的选项,从而使得CXL启用的闪存设备(或称为CXL-flash)能够克服“内存墙”。尽管之前的研究已经探讨了多个CXL设备的可扩展性方面 [36,42],并且已经证明了CXL-flash的可行性 [9,42],但据我们所知,我们是第一个对CXL-flash设备的设计选择以及现有优化技术的有效性进行深入开源研究的工作。由于设计空间很大,我们首先在第4节中探索了CXL-flash硬件设计,然后在第5节中对详细策略和算法进行评估和分析。我们发现可以使用真实应用程序的内存跟踪数据设计CXL-flash,使得68-91%的请求可以在微秒级内实现延迟,并具有至少3.1年的估计寿命。在探索各种设计和策略的同时,我们进行了七项观察,这些观察共同表明现代预取算法不适合预测CXL-flash的内存访问模式。更具体地说,虚拟地址到物理地址的转换使得现有的预取器无法足够有效地执行。为了解决这个问题,我们探索了从内核向CXL-flash传递内存访问提示来进一步提高性能。本工作的贡献如下:
我们开发了一种新型工具,用于收集应用程序的物理内存访问轨迹,并用这些轨迹模拟了CXL-flash的行为。内存跟踪工具和CXL-flash模拟器的代码都可以在(https://github.com/spypaul/MQSim_CXL.git)上获取。
通过使用合成工作负载,我们展示了将各种系统威廉希尔官方网站 (如缓存和预取)集成到CXL-flash中,有潜力显著减少延迟,同时突显了优化的机会。(第4节)
使用真实世界的工作负载,我们分析了当前预取器的局限性,并提出了用于未来CXL-flash的系统级变更,以实现接近DRAM的性能,特别是设备的子微秒级延迟。(第5节)
02. 背景
在本节中,我们首先描述了CXL(Compute Express Link)[3]作为基于PCIe的内存一致性互连技术(包括Gen-Z [7]、CCIX [2]和OpenCAPI [12])所带来的机遇。然后,我们讨论了在CXL中使用闪存内存的挑战。 2.1 CXL带来的机遇 CXL是一种建立在PCIe之上的新型互连协议,将CPU、加速器和内存设备集成到单一计算域中 [42]。这种集成的主要好处有两个。
首先,它允许CPU和PCIe设备之间进行一致的内存访问。这减少了通常需要在CPU和设备之间进行数据传输时所需的同步开销。
其次,CXL设备的数量可以很容易地进行扩展:通过CXL交换机,可以连接另一组CXL设备到CPU。
在CXL支持的三种类型的设备中,对于内存扩展的Type 3设备对本工作是感兴趣的。Type 3设备公开了主机管理的设备内存(HDM,host-managed device memory),CXL协议允许主机CPU通过load/store指令直接操作设备内存 [3]。虽然CXL目前只考虑DRAM和PMEM作为主要的内存扩展设备,但由于CXL的一致性内存访问特性[42],使用SSD也是可能的。 此外,基于闪存的SSD的高容量和更好的扩展性,通过3D堆叠[59]和在一个单元中存储多位[24],可以有效地解决现代数据密集型应用所面临的“内存墙”问题。受之前关于CXL的工作的启发[36,42],本文研究了使用闪存内存作为CXL内存扩展设备的可行性。 2.2 闪存的挑战 我们讨论以下三个闪存的特点,这使得将其用作系统的主内存具有挑战性。 粒度不匹配。闪存不是随机访问的:其数据以页粒度写入和读取,每个页的大小约为几千字节[33],导致大量的流量放大。此外,页不能被覆盖写入。相反,必须首先擦除一个包含数百个页的块,然后才能写入数据到已擦除的页[33]。这种受限的接口导致任何64B缓存行刷新通过读取-修改-写入操作产生大量的写放大。作为一个块设备,其访问粒度要大得多(4KiB)的SSD拥有更少的开销。 微秒级延迟。闪存的速度比DRAM慢几个数量级,其读取速度仍在几十微秒范围内,而较慢的编程和擦除操作则在几百微秒到几千微秒之间[5,24]。此外,闪存的延迟还取决于其单元技术[24]。例如,表1中所示,随着每个单元存储的位数增加,从SLC(单级单元)到TLC(三级单元),延迟也会增加。超低延迟(ULL)闪存是SLC的一种变体,以性能为代价提高了密度[46,76]。然而,即使是ULL技术,其速度仍比DRAM慢几个数量级。作为一个块设备,微秒级的延迟是可以容忍的,因为存储栈中存在软件开销。然而,对于直接使用load/store指令访问的内存设备来说,微秒级延迟是一个挑战。

表1: 内存技术特性概述
有限的耐久性。编程和擦除操作期间施加在闪存上的高电压会慢慢使单元失效,使它们随着时间的推移无法使用[44,72]。存储器制造商规定了耐久性极限作为一个指导,表示闪存块可以被擦除的次数。这个限制也取决于闪存技术,如表1所示。虽然这仍然是一个软限制,闪存超过限制后仍然可以继续使用[72],但是磨损的块表现出不可靠的行为,并且不能保证正确存储数据[44]。由于应用程序级和内核级的缓存和缓冲,SSD的块接口的写入量减少,因此当前的耐久性限制在SSD的寿命内通常是足够的。然而,作为内存设备,频繁的内存写入会使闪存内存快速变得无法使用。 我们注意到,虽然这些闪存的挑战在存储领域中也存在,但是它们由SSD的内部固件处理。然而,对于CXL-flash,由于时间尺度更细,这些挑战应该由硬件来解决,这使得实现灵活和优化的算法变得困难。因此,我们预期将闪存内存从存储领域移动到内存领域时,这些挑战会加剧。
03. 工具和方法
为了理解CPU到CXL设备的物理内存访问行为,我们使用页面错误事件构建了一个物理内存跟踪工具(第3.1节)。然后,我们通过与一组虚拟内存跟踪(第3.2节)进行比较,展示了这个工具的必要性。本工作中生成的工具和数据可供公众使用。 3.1 跟踪内存访问 主内存和CXL-flash通过物理内存地址进行访问。不幸的是,据我们所知,没有公开可用的工具能够在没有硬件修改的情况下跟踪最后一级缓存(LLC)和内存控制器之间的物理内存事务。跟踪CPU中的load/store指令是不够的,因为(1)它只收集虚拟地址访问,(2)最终对CXL-flash的访问被缓存层次结构过滤掉。
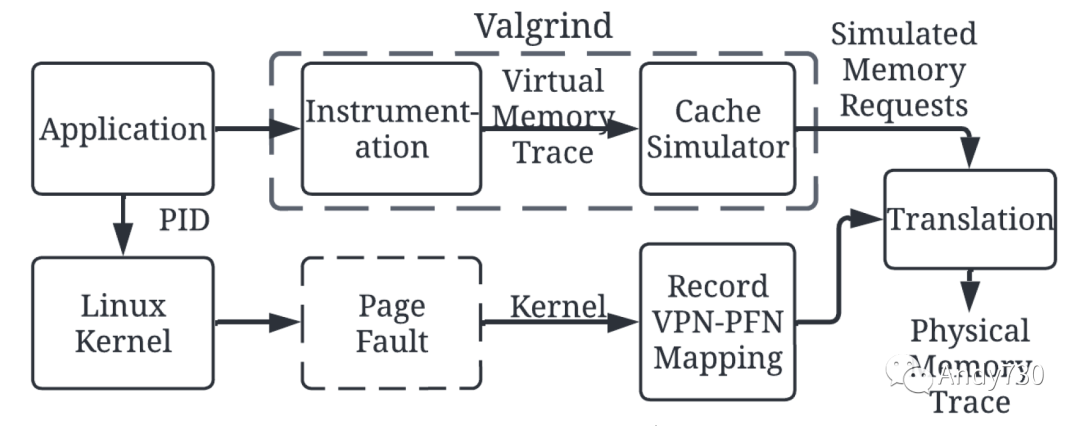
图2: 收集物理内存跟踪的工作流程。我们使用Valgrind收集虚拟内存跟踪,并在缓存中模拟其行为。同时,我们捕获页面故障事件以跟踪页面表的更新,并用此生成物理内存跟踪 我们通过结合来自Valgrind [19,57]的内存跟踪和页面错误事件信息来跟踪物理内存访问。图2说明了这个工作流程。如图顶部路径所示,我们使用 Valgrind 对应用程序进行load/store指令的工具化,并使用其缓存模拟器 (Cachegrind) 来过滤对内存的访问。更具体地说,我们修改了Cachegrind以收集由LLC缺失或替换引起的内存访问。然而,Cachegrind产生的这些内存访问仍然是虚拟地址,因此需要虚拟到物理(V2P)映射信息来生成物理内存跟踪。为此,如图2底部路径所示,我们收集应用程序运行时由页面错误引起的页表更新。我们修改安装页面表项的内核函数(do_anonymous_page()和do_set_pte()),并将目标应用程序的PID的V2P转换存储在/proc文件系统中。这捕获了应用程序执行过程中页面表更新的动态特性,并且开销很小。我们将来自Valgrind的虚拟访问和页面表更新结合起来生成物理内存跟踪。 3.2 虚拟内存与物理内存访问 我们使用基于预取技术的前期工作[25, 56]中的五个合成应用程序来展示我们的物理内存跟踪工具。所收集的跟踪特性总结如表2所示。我们收集了前2000万次内存访问:请注意这些不是load/store指令,而是LLC和内存之间的内存事务。

表2: 合成工作负载特性概述
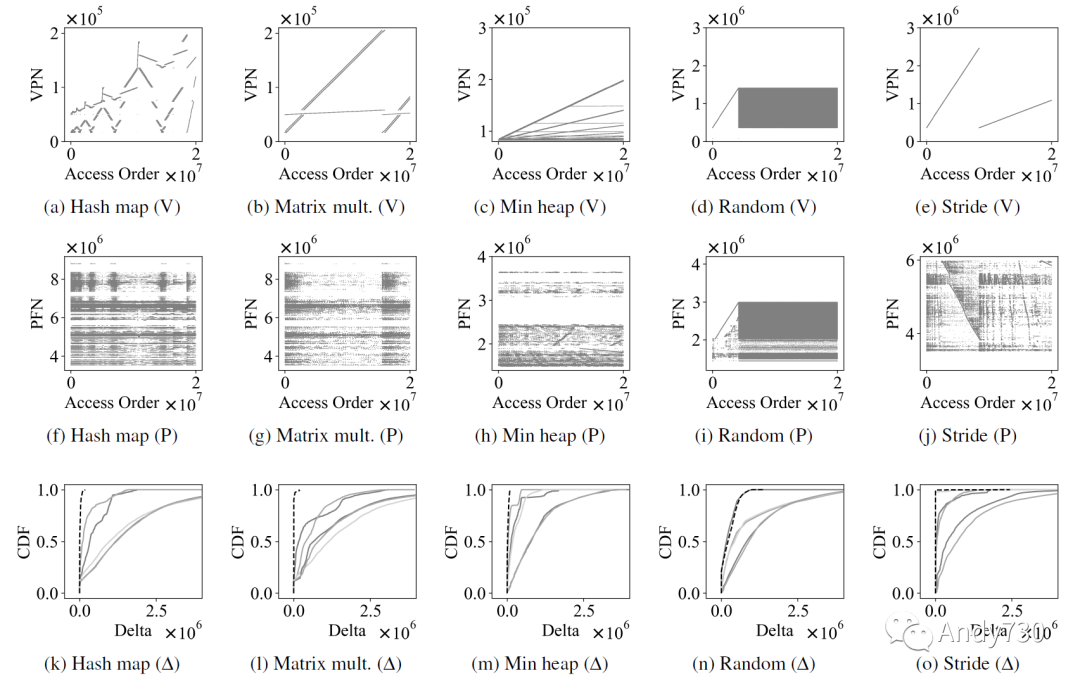
图3: 显示五个合成应用程序(哈希映射、矩阵乘法、最小堆、随机访问和步幅访问)的访问模式的散点图。顶行(图3a–3e)显示虚拟地址访问,第二行(图3f–3j)显示物理访问。最后一行(图3k–3o)显示连续访问之间差异的累积分布函数。我们观察到由于地址转换,物理内存访问与虚拟内存访问不同 图3a-3e(图3的第一行)绘制了这五个合成跟踪的虚拟页号(VPN,virtual page number)。我们可以观察到虚拟地址访问模式与我们对应用程序的期望相匹配。然而,如图3f-3j(图3的第二行)所示,相应的物理帧号(PFN)并不类似于VPN。我们在图3k-3o(图3的最后一行)中显示了连续访问之间的差异(∆,delta)。黑色虚线是虚拟地址的delta,而灰色实线是五次迭代的物理地址的delta,其中两次迭代是在运行其他应用程序时运行的,以增加内存利用率。我们做出两个观察。 首先,虚拟访问模式(黑色虚线)平均具有较小的delta值。然而,物理访问模式(灰色实线)可能具有非常大的delta值,这是由于虚拟到物理地址转换所致。 其次,灰色实线很少彼此重叠,突显物理内存模式是动态的,并取决于影响内存分配的各种运行时因素。因此,物理和虚拟地址之间的观察到的不匹配可能受到动态因素的影响,如系统的内存利用率。 为了证明捕获物理内存跟踪的必要性,我们通过使用虚拟地址和物理地址跟踪作为输入来测量CXL-flash的性能。CXL-flash的配置是具有8个通道和每个通道8个路的闪存后端以及512MiB DRAM缓存,并实现Next-N-line预取器[41](更多详细信息见第4节)。我们测量了五个合成应用程序的内存请求在小于1微秒的延迟下的百分比,并在表3中报告了结果。使用虚拟内存跟踪生成了一个过于乐观的结果,相较于运行物理内存跟踪的结果,更多的请求在1微秒以下完成。虚拟地址和物理地址之间的误差显著较高:所有的矩阵乘法实验的误差都超过了25%。随机和步幅访问负载的误差率较低,使得无论是虚拟还是物理寻址,都很难或者太容易预测访问模式。

表3: 使用虚拟和物理地址跟踪的合成应用程序在CXL闪存中的亚微秒延迟百分比。我们重复五次物理跟踪生成,其中第4和第5次具有更高的系统内存利用率(因此,内存布局更加碎片化)。我们计算虚拟跟踪性能相对于物理跟踪的误差,并用黄色(黄色)标记超过10%的错误,用红色(红色 )标记超过25%的错误。 减轻地址转换过程中信息的变化的一种技术是利用大页面,这可以显著减少地址转换的数量[54, 58]以保留内存访问模式。然而,这种方法只能部分减少对系统的影响,并且地址转换是不可避免的。随着应用程序内存需求的快速增长(如图1所示,年均增长率为14.1倍),在几年内,大页面将面临与较小页面相同的挑战。因此,我们决定保持配置的通用性,以探索CXL-flash的设计选项。
04. CXL-flash 的设计空间
我们探索构建CXL-flash的设计空间,特别是其中的硬件模块;我们稍后在第5节中评估算法和策略。为了模拟硬件,我们基于MQSim [68]及其扩展MQSim-E [49]构建了一个CXL-flash模拟器,并使用五个合成应用程序的物理内存跟踪(表2)来评估设计选项的效果。我们的CXL-flash的整体架构如图4所示,并在表4中展示了初始配置。 本节中,我们回答以下研究问题。
缓存在提高性能方面的效果如何?(第4.1节)
如何有效地减少闪存内存流量?(第4.2节)
预取在隐藏长闪存内存延迟方面的效果如何?(第4.3节)
CXL-flash的合适闪存技术和并行性是什么?(第4.4节)
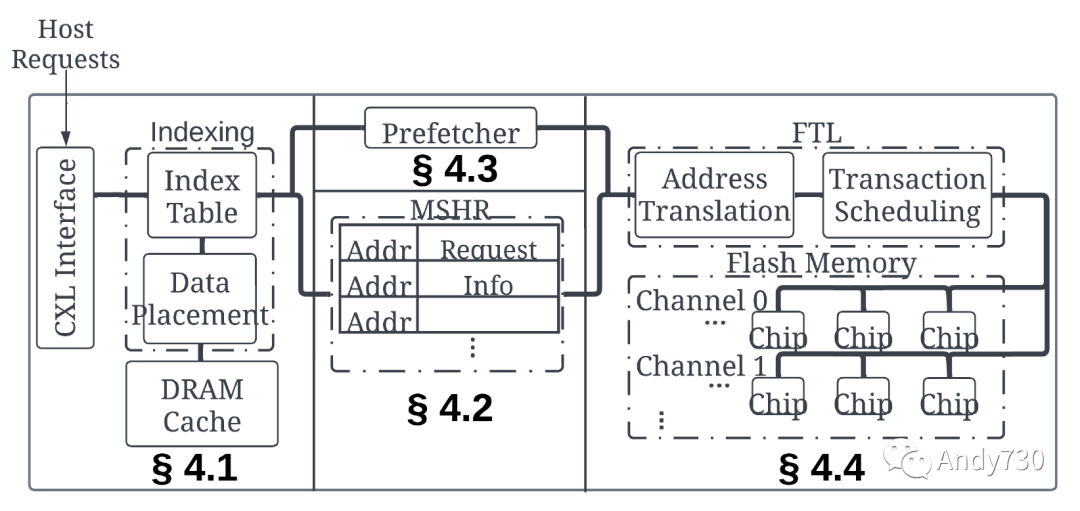
图4: CXL闪存的体系结构。

表4: §4中CXL闪存的初始配置。
4.1 缓存对性能的影响
我们首先探索在闪存前添加DRAM缓存的效果。缓存主要有两个作用。
首先,它通过从更快的DRAM中提供频繁访问的数据来提高CXL-flash的性能。
其次,它在缓存命中时减少对闪存的整体流量。
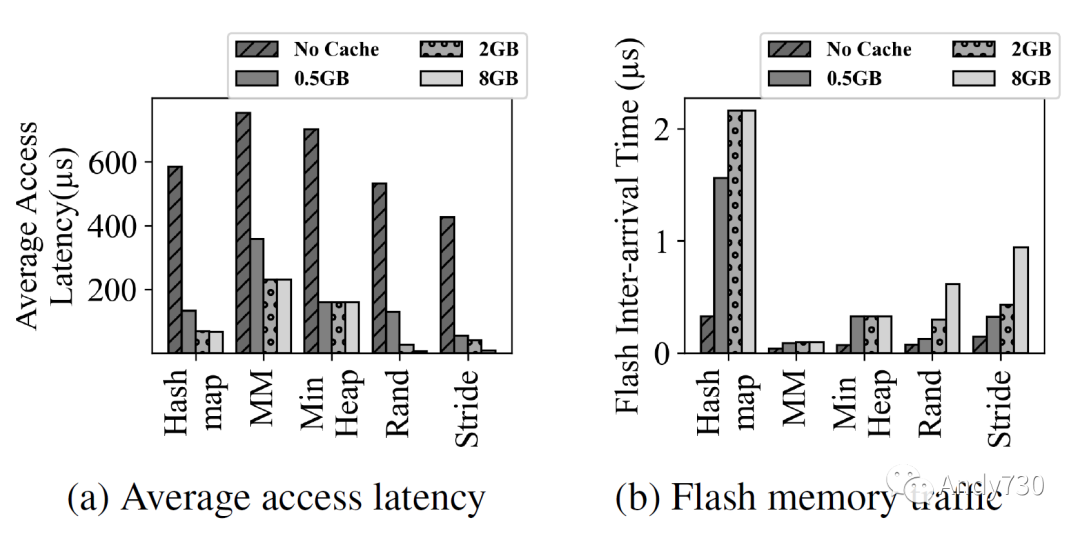
图5: 随着DRAM缓存大小变化的64B读写请求的平均访问延迟(图5a)和闪存内存流量(图5b)。通常情况下,缓存可以提高性能并减少对闪存的流量。然而,即使有足够大的缓存,平均延迟仍然远高于DRAM,这是由于内存访问的高强度造成的。 图5定量展示了使用缓存的好处。我们将缓存大小从0变化到8GiB,并测量物理内存访问的平均延迟(图5a)和发送给后端的闪存内存请求的间隔时间(图5b)。当没有缓存时,由于排队延迟,平均延迟远高于闪存的读取和编程延迟。即使闪存后端的配置是每个通道32个通道和每个通道32个路的丰富并行性,但它仍不足以处理具有短间隔时间的内存请求。添加缓存显著减少了对闪存后端的流量,并改善了整体性能。然而,我们观察到图5a中,矩阵乘法和最小堆的平均延迟仍远高于DRAM的延迟,尽管这些工作负载的内存占用小于缓存。这是由于短间隔时间的请求导致了超负荷的闪存后端获取数据(图5b)。这个实验表明,仅仅使用缓存是不足以降低CXL-flash的延迟的,我们需要额外的辅助结构来减少对闪存的流量。
4.2 减少闪存内存流量
内存访问以64B的粒度进行,而闪存后端以4KiB为单位进行寻址。因此,在缓存未命中时,将从闪存中获取4KiB的数据,并且属于同一4KiB的后续64B缓存未命中将在闪存读取正在进行时产生额外的闪存内存读取请求。这种情况在具有高空间局部性的内存访问中非常常见,并且由于更长的闪存延迟而加剧。我们将其称为重复读取,图6说明了哈希图,矩阵乘法和堆工作负载中重复读取的严重性:超过90%的闪存读取是重复读取!
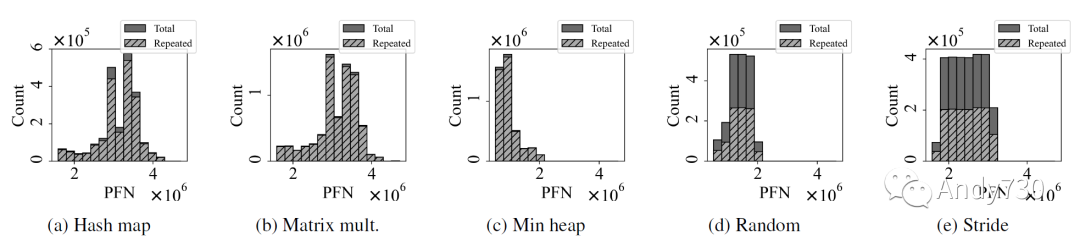
图6: 物理内存帧的闪存读取次数。实心条表示总的读取次数,而阴影条表示重复读取次数。重复读取是对尚未完成的读取请求的读取请求。

图7: 使用(实线)和不使用(虚线)MSHR的延迟分布。 受到CPU缓存的启发,我们向CXL-flash中添加了一组MSHR(miss status holding registers)[29, 47],如图4所示。MSHR跟踪当前未完成的闪存内存请求,并从单个闪存内存读取服务多个64B内存访问。我们注意到,在SSD中MSHR很少见:在存储领域中,软件栈合并具有重叠地址的块I/O,因此不需要底层设备实现MSHR。然而,对于CXL-flash,没有软件层来执行此任务,因为它直接从LLC接收内存事务。我们观察到,图7中的MSHR显著降低了长尾延迟,特别是对于具有大量重复读取的三个工作负载。我们还观察到,通过添加MSHR,对于其他两个工作负载(随机和步幅),也会有轻微的改进。然而,MSHR只能减少闪存内存流量,并不能通过在需要数据之前将数据带入缓存来主动提高缓存命中率。
4.3 从闪存预取数据
预取(Prefetching)是一种隐藏较慢技术长延迟的有效技术。通常,预取器在需要未命中或预取命中时获取额外的数据。为了了解这种技术的有效性,我们在CXL-flash中实现了一个简单的Next-N-line预取器[41],如图4所示。该预取器有两个可配置的参数:度和偏移量。度控制获取的额外数据量,而偏移量决定了触发地址的预取地址。换句话说,度参数表示预取器的侵略性,偏移量控制预取器提前获取数据的距离。
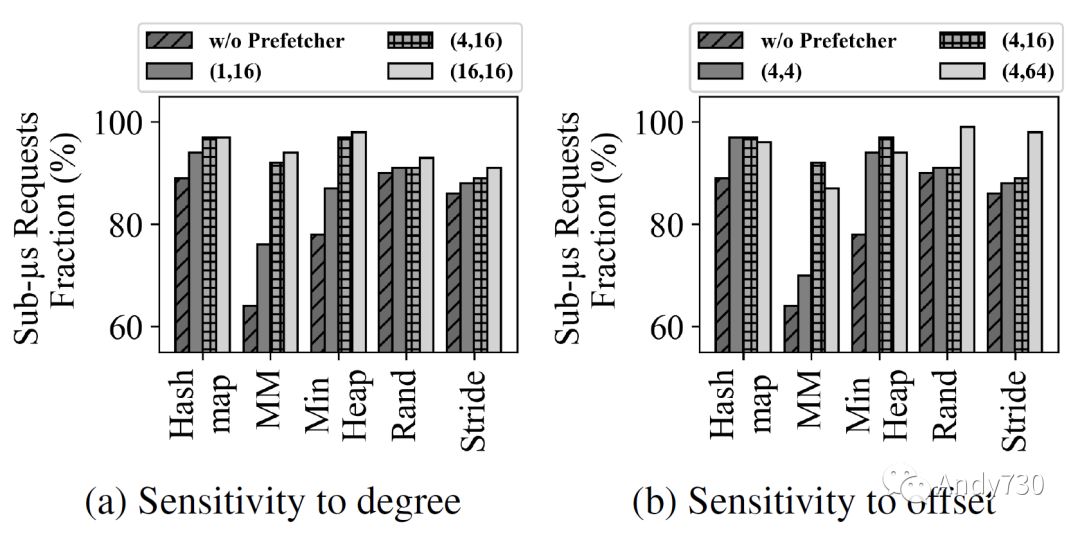
图8: 具有不同预取器配置的CXL闪存的性能。
(X, Y)表示Next-N-line预取器的度和偏移。 图8显示了不同度和偏移量对预取器的影响。在一个以4KiB页数为单位的(X,Y)符号中,X表示度,Y表示偏移量。如图8a所示,增加度或者预取器的侵略性通常会提高性能。即使是小的度数1,也会将矩阵乘法工作负载中的小于一微秒请求的比例从64%提高到76%,凸显了CXL-flash的预取的必要性。然而,改进效果会达到平台,进一步增加度数可能只会污染缓存。另一方面,增加偏移量会导致两种不同的行为,这取决于工作负载。对于哈希图,矩阵乘法和最小堆工作负载,增加偏移量从4增加到16时性能首先会有所改善。然而,偏移量为64时性能下降,因为它预取了太远的数据。随机工作负载对偏移量不敏感,除非它足够大,而步幅工作负载则随着偏移量的增加逐渐改善。
4.4 探索闪存技术和并行性
在之前的子章节中,我们使用SLC闪存技术和丰富的闪存并行性(每个通道32个通道和每个通道32个路,32×32)检验了CXL-flash的性能。在本节中,我们研究技术(ULL,SLC,MLC和TLC)和并行性(8×4,8×8,16×16和32×32)对整体CXL-flash性能的敏感性。 首先,我们通过使用步幅工作负载(如图9所示)来研究闪存技术和缓存大小的影响。我们选择这个工作负载是因为它在默认配置下表现良好,因此我们期望它代表了具有最小改进空间的工作负载。图9a说明了不同内存技术的平均延迟。我们观察到,即使ULL和SLC闪存的延迟存在显著差异(3微秒对25微秒),在存在缓存的情况下,两者之间的性能差异是可以忽略的。只有当没有DRAM缓存时,ULL闪存的性能明显更好。我们还观察到使用MLC和TLC技术会显著降低性能。图9b显示了基于闪存写入流量估算的CXL-flash的预计寿命。这个估算考虑了耐用性限制、容量和数据写入量;它乐观地假设闪存后端的写放大可以忽略。我们观察到,通过使用ULL和SLC技术以及一些缓存,CXL-flash的寿命可以达到4年以上。增加缓存大小进一步提高寿命,因为闪存写入流量减少。对于基于MLC和TLC的CXL-flash来说,只有使用足够大的缓存才是可行的:只有1GiB的缓存,其寿命不会超过一年。
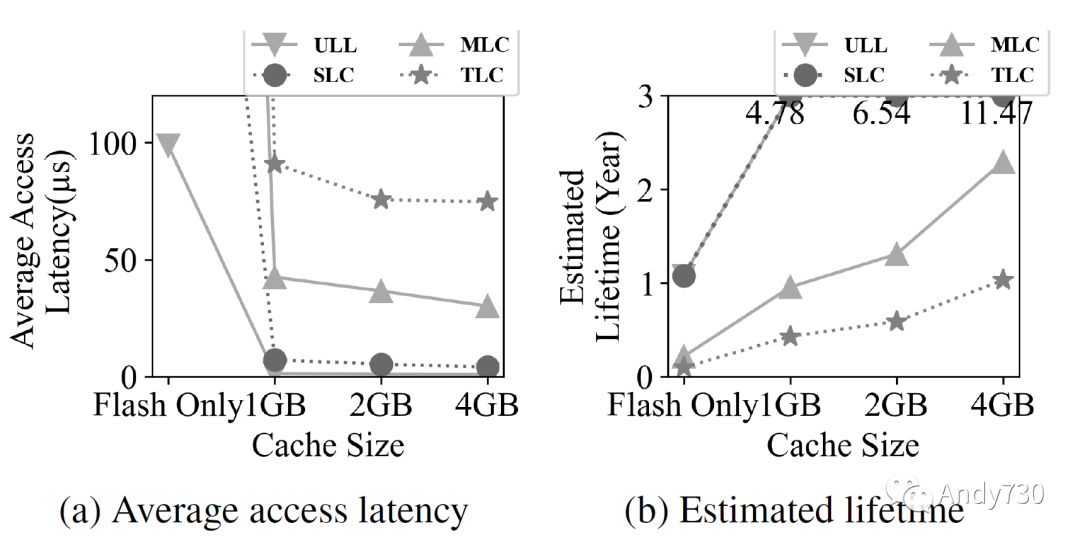
图9: 对CXL闪存性能和寿命的闪存技术和缓存大小敏感性测试。
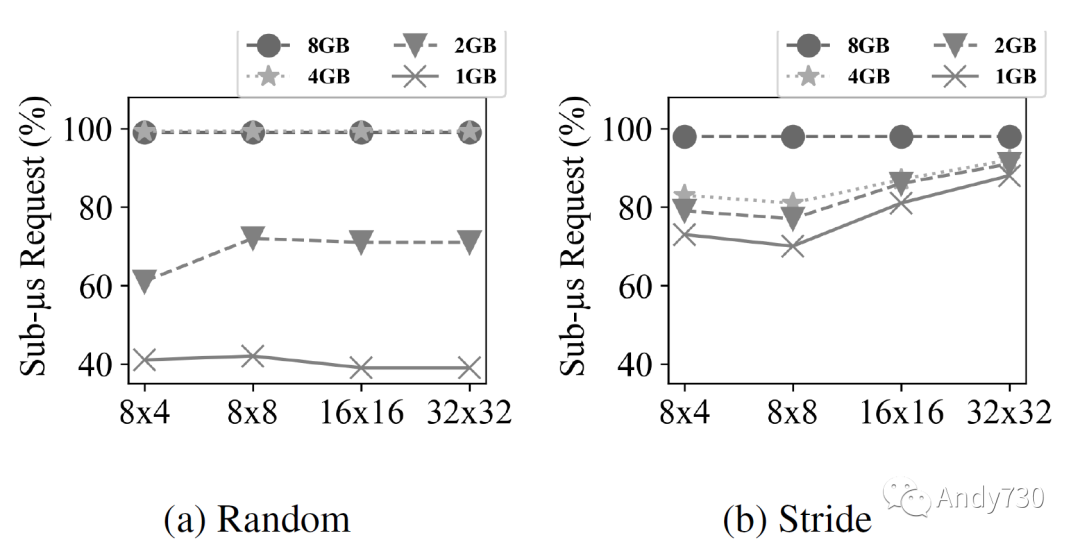
图10: 不同闪存并行性和缓存大小的亚微秒请求百分比。x轴表示闪存内存并行性(通道数×路数)。线表示不同缓存大小的值。 接下来,我们通过使用随机(图10a)和步幅(图10b)工作负载来研究不同闪存并行性和缓存大小对整体性能的影响。我们选择这两个工作负载,因为它们具有最大的内存占用(分别为8GiB和4GiB)。这里闪存技术是SLC。我们观察到,对于足够大的缓存,减少并行性为(8×4)并不会对性能产生不利影响。然而,对于较小的缓存,闪存并行性很重要。有趣的是,这两个工作负载表现出略微不同的行为。随机工作负载对缓存大小非常敏感。另一方面,步幅工作负载对缓存大小不敏感,但对并行性更敏感。这是由于步幅工作负载中的预取器的有效性。
4.5 结论摘要
我们简要总结以下研究结果:
仅仅使用缓存无法隐藏较长的闪存内存延迟(§4.1),我们需要辅助结构来减少闪存内存流量(§4.2)。
预取数据可以提高CXL-flash的性能,但最佳配置(甚至算法)取决于工作负载(§4.3)。
在性能和寿命方面,使用ULL和SLC之间的性能差距仅微不足道,而利用MLC和TLC闪存具有挑战性(§4.4)。
05. 策略评估
在上一节(§4)对CXL-flash架构的设计空间进行探索的基础上,本节中我们评估了高级缓存和预取策略。我们选择了五个来自各个领域的内存密集型真实应用程序:自然语言处理[18,70]、图处理[6,27]、高性能计算[17,62]、SPEC CPU[16,21]和KV存储[22,31]。我们使用我们的工具(§3)收集物理内存访问追踪,并在表5中总结了工作负载特性。

表5: 实际应用程序的工作负载特性。空间和时间局部性值的范围在0到1之间,并使用栈和块亲和性度量[32]计算:较高的值表示较高的局部性。 然而,真实应用程序的内存占用比我们预期的要小,尽管它们是在64GiB内存的计算机上收集的。因此,我们故意将缓存配置为较小(64MiB),以便实验结果能够扩展到更大的工作负载。我们还将闪存并行性缩小到更现实的设置,并使用ULL闪存。本节中CXL-flash的默认参数在表6中总结。
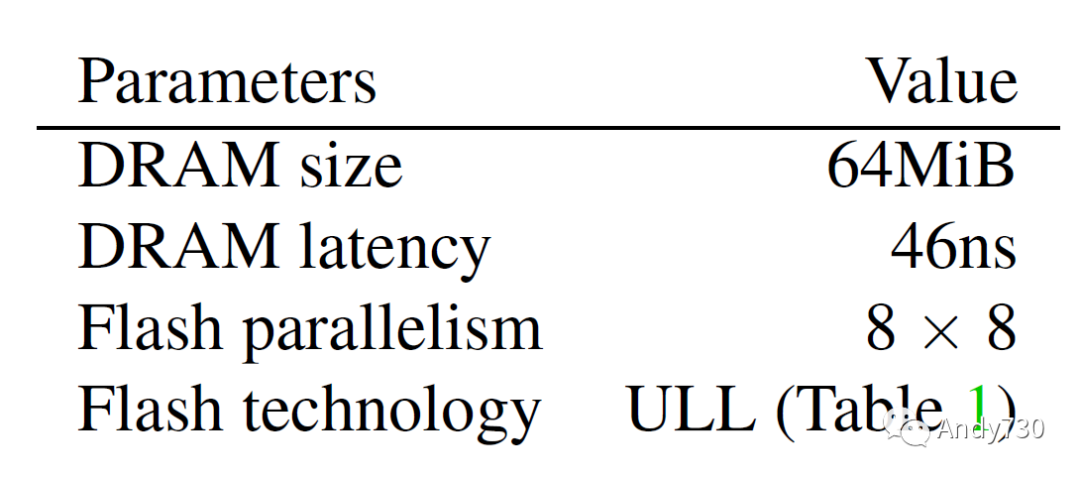
表6: §5中CXL闪存的默认参数。
5.1 缓存替换策略
与先前对性能的缓存大小检查(§4.1)不同,这里我们固定缓存大小,评估不同缓存替换策略在不同的集合关联性下的影响。特别地,我们实现了以下四种策略。
FIFO:剔除最旧的数据。
随机:随机选择数据剔除。
LRU:剔除最近最少使用的数据。
CFLRU [60]:优先剔除干净数据而不是已修改的数据。
我们选择随机作为基准线,FIFO和LRU是两种可以在硬件中实现的标准CPU缓存策略。为了进一步减少流量并延长设备的寿命,我们实现了CFLRU,以探索优先选择剔除干净缓存行以减少闪存写入活动的好处。 图11衡量了具有小于一微秒延迟的CXL-flash内存请求的百分比,图12显示了闪存内存写入次数。从这些图表中我们得出五个观察结果。 首先,增加关联性会提高性能,因为它会增加缓存命中率。对于缓存系统,其失效开销很高,增加命中率比减少命中时间对性能影响更大。 其次,CFLRU的表现优于其他替换策略,特别是在BERT,XZ和YCSB中(图11a,图11d和图11e)。这得到了图12a,图12d和图12e中显示的写流量的显著减少的支持。 第三,具有高局部性的工作负载,如Radiosity,对缓存替换策略不敏感(图11c和图12c):至少有83%的请求具有小于一微秒的延迟,无论采用何种策略。 第四,以读为主的工作负载通常比以写为主的工作负载表现更好,因为闪存内存编程延迟相对于读取延迟偏大。BERT和Radiosity只产生了0.7M和1.0M闪存写入次数(图12a和图12c),因此其小于一微秒延迟的占比分别达到了84%和85%(图11a和图11c)。 最后,局部性较低的工作负载不仅性能较差,而且对缓存策略的敏感性较低。特别是,如图11b所示,仅有最多65%的请求在页面排名工作负载中实现小于一微秒的延迟,因为其局部性较低且内存占用较大。图11d中的XZ跟踪也表现出较低的局部性,但对于CFLRU的敏感性比页面排名工作负载高,因为工作负载具有较高的写入比例。
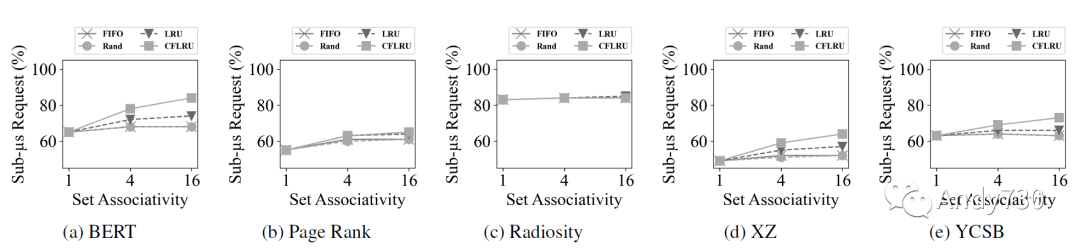
图11: 基于缓存替换策略和关联性的CXL闪存亚微秒延迟百分比。通常情况下,增加关联性可以减少延迟,而CFLRU表现比其他策略更好。
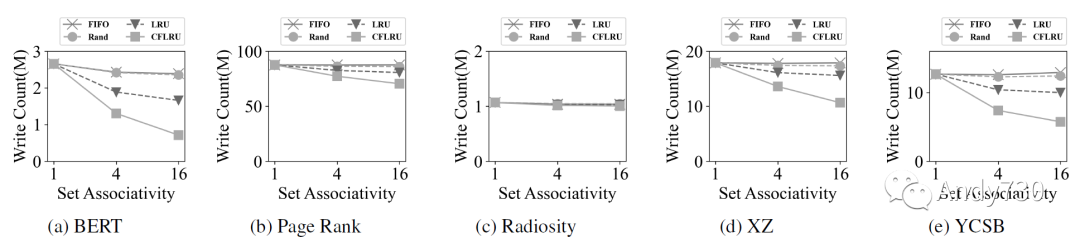
图12: 基于缓存替换策略和关联性的闪存写请求数量。随着关联性的增加,CFLRU显著减少写入次数。 在存储领域,通过各种软件层面的技术,包括操作系统级别的页缓存,可以减少写入SSD的数据量。然而,CXL-flash的缓存管理行为类似于CPU缓存,并且可能存在其接近最优状态的限制。
5.2 预取策略
在 §4.3 中,我们测量了一个简单的Next-N-line预取器在大型8GiB缓存下的有效性。在本节中,我们将缓存缩小为64MiB,并将其关联性设置为16,并使用CFLRU算法进行管理,并测量以下五种预取器设置的性能。
NP(无预取)不预取任何数据。
NL(Next-N-line)[41]在需要缺失或预取命中时带来下N个数据。
FD(反馈导向)[65]通过跟踪预取器的准确性,及时性和污染来动态调整预取器的攻击性。
BO(最佳偏移)[55]通过跟踪最近请求历史记录中的连续访问之间的差异来学习。它还具有禁用预取的置信度概念。
LP(Leap)[53]实施基于多数的预取,并具有动态窗口大小调整。它还根据预取器的准确性逐渐调整攻击性。
我们选择这些算法是因为它们已被证明是有效的,可以在硬件中实现,并且适用于CXL-flash的设计空间。特别是,NL,FD和BO是用于CPU缓存的预取器,其中BO是NL的改进版本,而FD利用我们将在后面讨论的性能指标。LP主要用于从远程内存预取数据,其中缓存命中和缓存缺失之间的延迟差异与我们的设计空间相似。
观察1:尽管68-91%的请求延迟小于一微秒,但使用预取器可能会对真实世界的应用性能产生不利影响。如图13a所示,最先进的预取器对BERT、XZ和YCSB工作负载的性能产生了负面影响,而对另外两个工作负载则有所帮助。特别是,在使用最佳偏移预取器时,Radiosity显示出36%的子微秒延迟增加。为了理解其中原因,我们检查了缓存命中率、缓存命中-未命中(HUM)率和缺失率(图13b)。缓存命中-未命中指的是MSHR中的命中,在此之前由于先前的缺失而正在获取数据的情况。我们观察到在Radiosity上,BO将25%的缓存命中-未命中转换为命中,表明预取对局部性因子高的工作负载(参见表5)具有很高的有效性。我们的观察结果表明,预取器的性能取决于工作负载的特性,并且它们可能对应用产生不利影响。
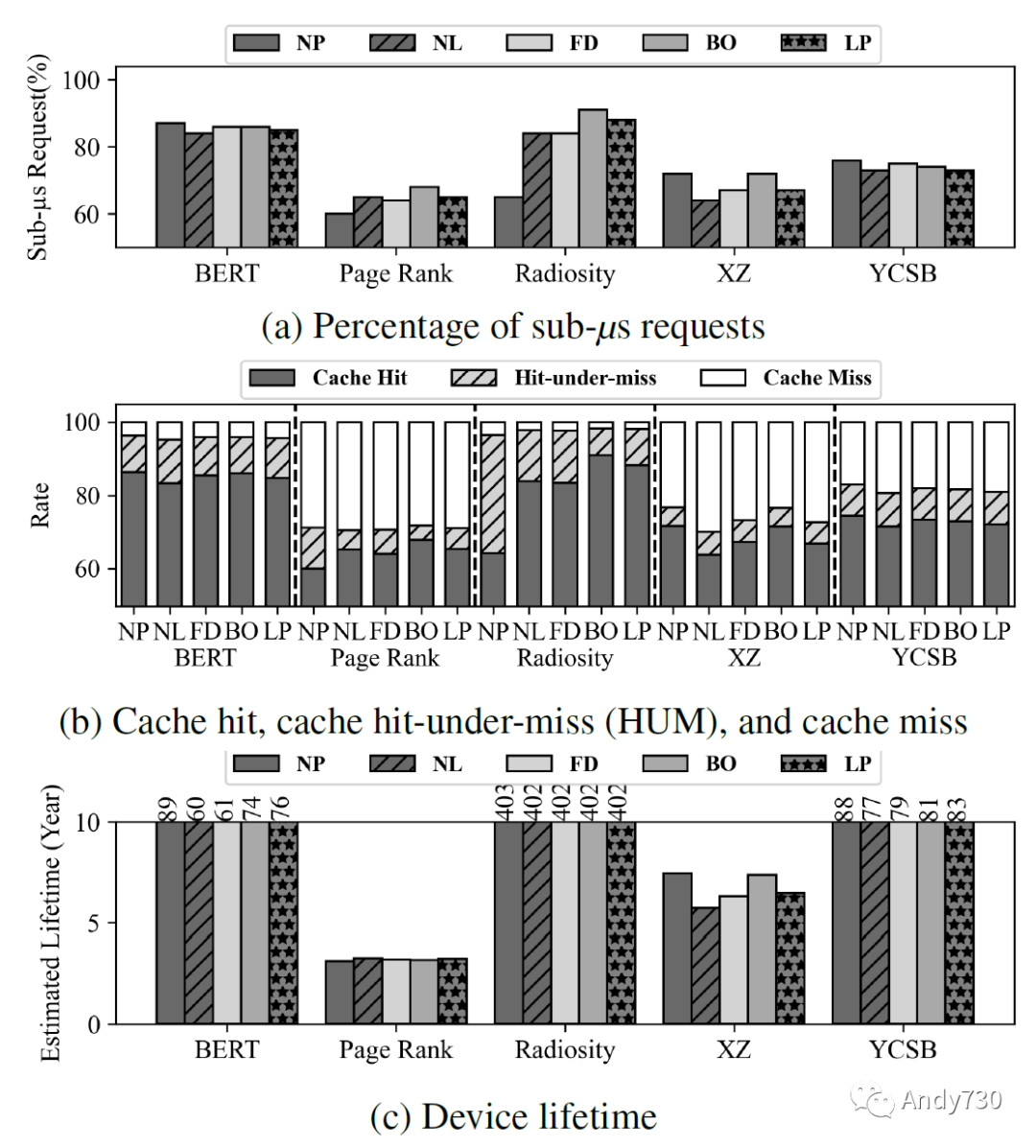
图13: 具有不同预取器的CXL闪存性能和寿命。图13a显示延迟小于一微秒的请求占比。图13b显示CXL闪存内64MiB缓存的命中、命中下未命中和未命中率。图13c绘制了估计的寿命。
观察2:即使在高强度的工作负载下,CXL-flash的寿命至少为3.1年。我们根据写入闪存的数据量、耐用限制和1TiB容量估计了CXL-flash在真实工作负载下的寿命,如图13c所示。我们观察到,在最坏的情况下,设备在Page Rank下可持续使用3.1年,但在Radiosity等工作负载下可达403年。寿命取决于三个因素:工作负载强度、读写比例和局部性;Page Rank具有最高的工作负载强度、高写入比例和低局部性。即使在这种不利条件下,CXL-flash提供了合理的寿命;因此,CXL-flash的耐久性可以满足内存请求的强度。
观察3:CXL-flash比纯DRAM设备具有更好的性能成本比。尽管CXL-flash在子微秒请求方面稍逊于DRAM,但我们的分析显示它有潜力为内存密集型应用程序提供优势。由于CXL-flash可以在小于一微秒的延迟下为68-91%的内存请求提供服务,而最近DRAM的价格点比NAND闪存高17-100倍[39,64,77],我们预计CXL-flash比纯DRAM设备具有11-91倍的性能成本效益,如图14所示。虽然在某些情况下,当需要最佳性能时,仍然可能更喜欢纯DRAM设备,但根据工作负载的不同,CXL-flash可能是一种具有成本效益的内存扩展选项。 有趣的是,我们观察到,虽然预取器对Page Rank有益,但其性能总体上是最差的,只有最多68%的请求在一微秒内完成。为了进一步了解预取器的性能,我们测量了以下四个指标。
准确性衡量预取器实际使用的预取数据比例。较高的准确性越好。
覆盖度是内存请求中预取数据缓存命中的部分。较高的覆盖度意味着缓存命中归功于预取器,而较低的覆盖度则表示预取器没有发挥作用。
延迟是所有预取数据中迟到的比例。较低的延迟越好。
污染是由预取器引起的缓存缺失中的缓存缺失次数。较低的污染越好。
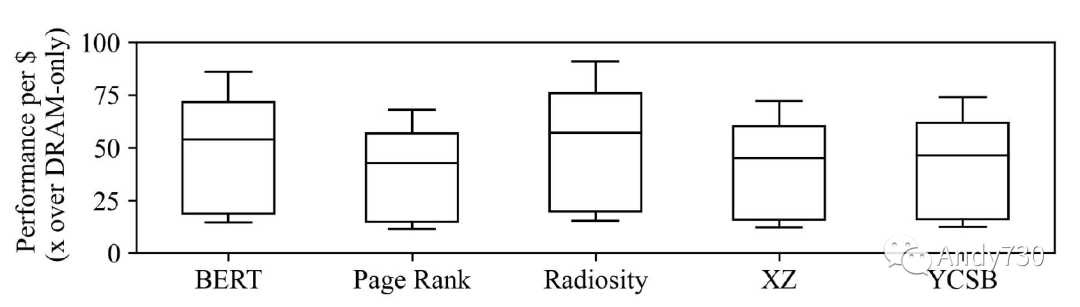
图14: 使用BO预取器的CXL闪存相对于仅DRAM设备的性能-成本收益。估计是根据图13a的性能结果、DRAM的最新价格点为5 $/GB [77],NAND闪存的价格范围从0.05到0.30 $/GB [39, 64]得出的。 观察4:在预取器改进性能的情况下,其成功归功于实现高准确性。我们在图15中绘制了评估的预取器的四个指标。延迟和污染是负指标(越低越好),因此我们倒置了它们的条形图,以使所有指标都越高越好。我们观察到,预取器对预取器有所帮助的工作负载(Page Rank和Radiosity)的定义特征是准确性高。例如,Leap(LP)预取器在Radiosity下达到85%的准确性,而在BERT下只达到27%。此外,最佳偏移(BO)预取器在XZ下实现了48%的准确性;但是,它仅有4%的覆盖度,表明尽管准确性相对较高,但预取器并未主动获取数据以改善性能。 我们进一步分析了Page Rank,以了解为什么预取器能够实现相对较高的准确性,即使工作负载具有最低的局部性(使用堆栈和块亲和性指标[32]计算)。如图16所示,Page Rank在其工作负载中呈现出明显的阶段。在第一阶段,Page Rank加载图信息并表现出很高的局部性(图16a)。最佳偏移预取器也能够实现很高的覆盖度和准确性(图16b)。然而,在第二阶段,Page Rank构建图,并且此处的访问模式具有非常低的局部性。因此,最佳偏移预取器变得更不活跃(覆盖率低),因为其准确性下降。在最后阶段,Page Rank计算每个顶点的分数。虽然其访问局部性不高,但预取器表现良好,并且大部分访问都在缓存中命中。请注意,虽然污染很严重,但缓存失效率非常低,因此对性能的影响可以忽略不计。该分析表明,虽然预取器对第一阶段和最后阶段有益,但第二阶段的低局部性限制了性能。
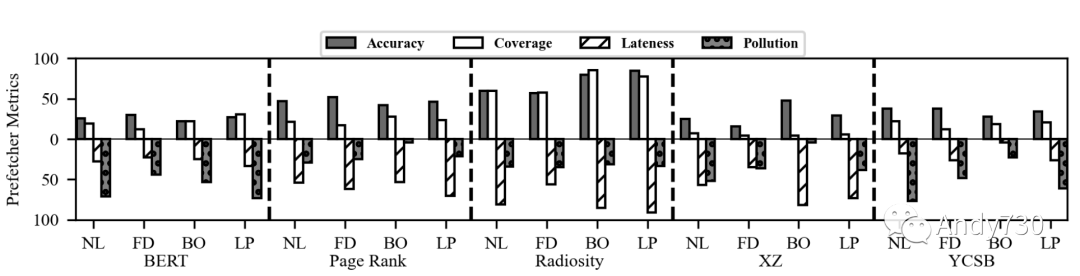
图15: 预取器的准确率、覆盖率、延迟和污染度指标。
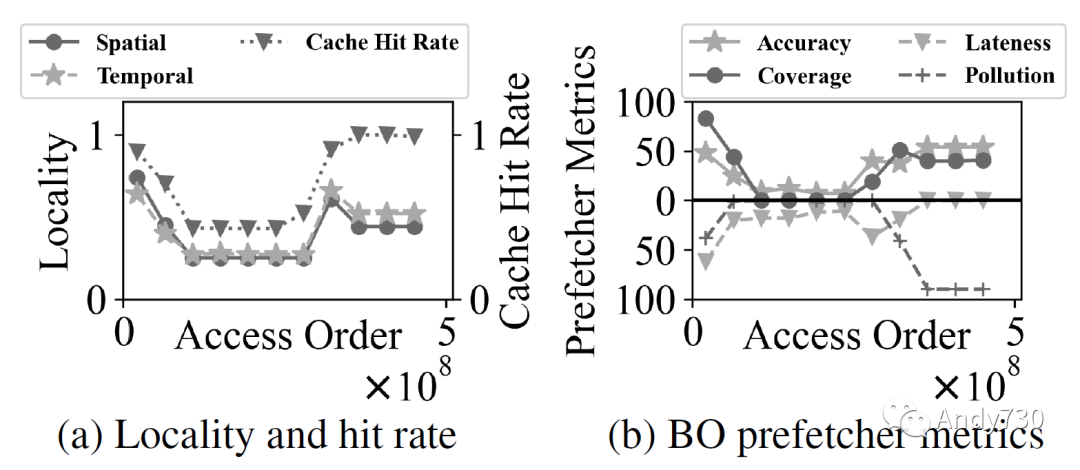
图16: Page Rank随时间的行为。
观察5:当准确性低时,缓存污染是性能下降的主要原因。如图15所示,BERT和YCSB具有较低的准确性,而它们的污染率很高,导致预取器的启用会降低性能(图13a)。对于XZ,尽管最佳偏移(BO)预取器的准确性较低,但它与没有预取器一样,因为它几乎没有污染。我们将这归因于BO根据其准确性的能力禁用预取。对于Page Rank和Radiosity,预取器污染率较低,尽管它们的延迟很高。缓存污染降低了CXL-flash的性能,预取器应该注意这种影响,以避免对设备产生不利影响。
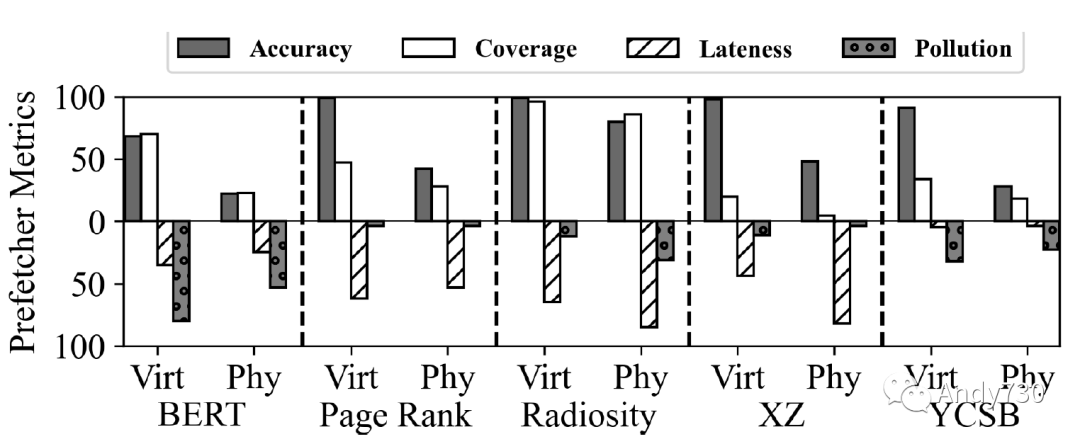
图17: BO预取器虚拟与物理指标比较。 观察6:虚拟到物理地址转换使CXL-flash难以预取数据。为了了解虚拟内存地址转换的影响,我们使用最佳偏移预取器模拟CXL-flash,使用5个应用程序工作负载的虚拟内存跟踪数据,图17比较了虚拟和物理跟踪之间的四个预取器指标。我们得出两个观察结果。首先,除了Radiosity之外,我们观察到从虚拟跟踪到物理跟踪的准确性显著下降。最佳偏移预取器在Page Rank的虚拟内存跟踪下的准确性为99%,但在物理跟踪下,准确性下降到42%。其次,覆盖率也降低,表明预取器在物理内存访问下变得不太活跃:例如,在BERT下,覆盖率从76%降至26%。对于物理跟踪,准确性和覆盖率的下降显示CXL-flash在虚拟寻址下的性能将更好。
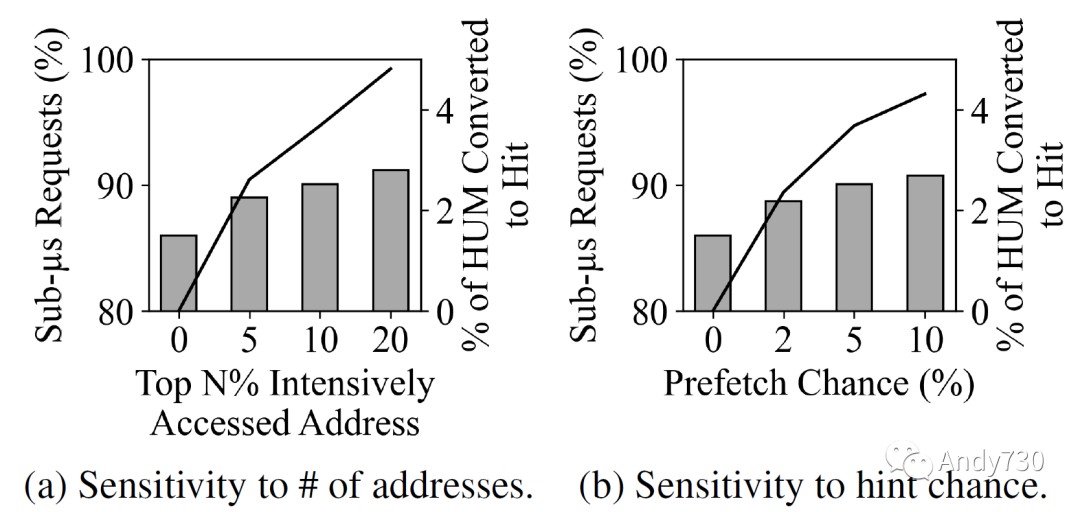
图18: 使用内存访问模式提示提高BERT性能。图18a是对提供提示的地址数量敏感性测试。图18b显示随着添加更多提示的性能改进。在两个图中,线表示使用提示前的命中下未命中转换为使用提示后的命中次数。
观察7:如果内核能够为设备提供内存访问模式提示,则CXL-flash的性能将通过将命中-未命中转换为缓存命中而得到改善。我们考虑了一个假设的具有洞察力的内核,它知道物理内存访问模式。这不是太牵强,因为数据密集型应用程序通常进行多次迭代,它们的行为可以进行分析。更具体地说,我们假设内核具有有关顶部密集访问的物理帧的信息,并可以在实际访问之前向设备传递提示。为了限制内核参与的开销,我们模拟了对访问提示的概率性生成。图18a显示了在前N%的密集访问地址的10%处生成提示时,BERT的性能改进情况。我们观察到,通过将命中-未命中(HUM)转换为缓存命中,随着对更多地址生成访问提示,子微秒延迟的百分比从86%增加到91%。图18b考虑了变量的提示生成概率,从前10%的密集访问地址的0%到10%。同样,我们看到整体性能有所改善,但在91%处平稳。我们的实验表明,利用主机的知识来生成访问模式提示,可能会提高CXL-flash的性能。
06. 相关工作
评估的缓存策略和预取算法在之前的研究中得到了深入探讨。然而,大多数研究都是针对管理和优化CPU缓存的,其中缓存命中和缓存未命中之间的延迟差异要小得多,而在CXL-flash中则要大得多。CFLRU [60] 和 Leap [53] 与我们的设备共享类似的设计空间,但它们所面临的内存访问强度并不像CXL-flash需要处理的那样极端。因此,必须在CXL-flash的设计空间下评估这些策略和算法的有效性。 先前的研究探索了缓解地址转换和闪存限制导致性能下降的技术。利用大页面可以减少地址转换次数 [54,58]。
FlashMap [40] 和 FlatFlash [23] 将SSD的地址转换与页表结合以减少开销。eNVY [73] 采用写入缓冲、页面重映射和清理策略,实现直接内存寻址并保持性能。CXL主机系统的未来研究应进一步探索利用主机生成提示的潜在好处,并结合先前的工作来减少开销。 内存解聚将内存资源组织在服务器之间作为网络附加的内存池,满足数据密集型应用的高内存需求 [37,38,52,69]。虽然我们的工作不直接研究内存解聚系统,但使用CXL-flash作为解聚内存有助于克服内存墙的问题。 先前的研究探索了利用非DRAM扩展内存的方法 [28,40,63,74]。HAMS [75] 通过以OS透明的方式管理主机和内存硬件之间的数据路径,将持久性内存和ULL闪存聚合成内存扩展。
Suzuki等人 [67] 提出了一种基于轻量级DMA的接口,绕过NVMe协议,实现与DRAM类似性能的闪存读取访问。SSDAlloc [26] 是一个内存管理器和运行时库,允许应用程序通过操作系统分页机制将闪存用作内存设备,但访问SSD中的数据可能导致开销。FlatFlash [23] 则通过整合操作系统分页机制和SSD的内部映射表,将DRAM和闪存内存暴露为一个平坦的内存空间。虽然这些先前的工作主要关注操作系统级管理和主机设备交互,但我们的工作在此基础上,研究了内存扩展设备内部的设计决策。
使用CXL Type 3设备进行内存扩展是一个活跃的研究领域 [36, 42, 50, 71]。Pond [50] 利用CXL来改进云环境中的DRAM内存池,并提出了机器学习模型来管理本地和池化内存。虽然该工作研究了如何在云环境中使用CXL Type 3设备,但我们的工作研究了如何使用闪存内存实现CXL Type 3设备。
DirectCXL [36] 成功地在实际硬件中通过CXL将主机处理器与外部DRAM连接,并开发了软件运行时库来直接访问资源。最后,CXL-SSD [42] 倡导将CXL和SSD结合起来扩展主机内存。虽然我们与该工作有着相同的目标,但它主要讨论了CXL互联和CXL-SSD的可扩展性潜力。 专为机器学习设计的系统致力于解决内存墙挑战 [45,48,51]。MC-DLA [48] 提出了一种架构,聚合内存模块以扩展加速器的训练ML模型的内存容量。Behemoth [45] 发现许多NLP模型需要大量内存,但不需要大量带宽,并提出了一个以闪存为中心的训练框架,管理内存和SSD之间的数据移动,以克服内存墙。
07. 结论
本文探索了CXL-flash设备的设计空间,并评估了现有的优化技术。通过使用物理内存跟踪,我们发现68-91%的内存访问可以在CXL-flash设备上实现亚微秒的延迟,而且该设备的寿命至少可以达到3.1年。我们发现,对于虚拟内存的地址转换使得CXL-flash的预取器特别难以发挥作用,建议通过传递内核级别的访问模式提示来进一步提高性能。 虽然我们试图通过测试多种工作负载和设计参数来概括结果,但还需要承认一些限制。本文所探索的CXL-flash的当前设计并未考虑闪存的内部任务,如垃圾收集和磨损均衡。此外,所考虑的主机系统可能并未完全反映CXL引入的新系统特性。因此,我们认为在CXL-flash研究领域还需要做更多的工作,而我们的工作可以为未来的研究提供一个平台。
编辑:黄飞
-
[5.1.7]--5.7内存计算的可行性jf_75936199 2023-03-07
-
在商业可行性上取得突破的能量收集2019-05-29 0
-
运放并联的可行性看了就知道2021-03-18 0
-
如何去测试微波电磁环境测试系统的可行性?2021-05-25 0
-
内存与闪存之间有什么不同?2021-06-18 0
-
动态Flash的可行性2021-07-26 0
-
投资项目可行性研究视频教程2009-07-15 607
-
AGVS路径规划可行性判断的研究2010-02-22 931
-
如何避免内存泄漏的方法和原则2020-10-21 5911
-
AN-807: 多载波WCDMA的可行性2021-03-21 602
-
多载波cdma2000可行性研究2021-04-19 562
-
AI算力发展如何解决内存墙和功耗墙问题2023-04-12 1841
-
ufs是内存还是闪存 手机ufs闪存有什么作用2023-07-18 20716
-
三星半导体谈应对内存墙限制的解决方案2023-08-10 940
-
车用LED照明的可行性和先进性2023-11-15 196
全部0条评论

快来发表一下你的评论吧 !
