

目标检测:Faster RCNN算法详解
电子说
描述
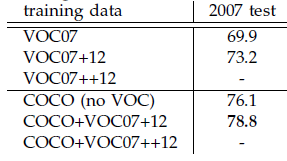
本文是继RCNN[1],fast RCNN[2]之后,目标检测界的领军人物Ross Girshick团队在2015年的又一力作。简单网络目标检测速度达到17fps,在PASCAL VOC上准确率为59.9%;复杂网络达到5fps,准确率78.8%。
作者在github上给出了基于matlab和python的源码。对Region CNN算法不了解的同学,请先参看这两篇文章:《RCNN算法详解》,《fast RCNN算法详解》。
思想
从RCNN到fast RCNN,再到本文的faster RCNN,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。所有计算没有重复,完全在GPU中完成,大大提高了运行速度。
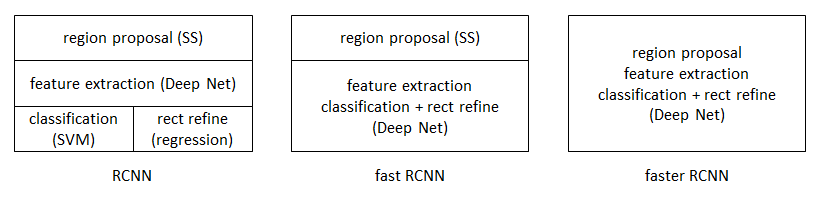
faster RCNN可以简单地看做“区域生成网络+fast RCNN“的系统,用区域生成网络代替fast RCNN中的Selective Search方法。本篇论文着重解决了这个系统中的三个问题:
如何设计区域生成网络
如何训练区域生成网络
如何让区域生成网络和fast RCNN网络共享特征提取网络
区域生成网络:结构
基本设想是:在提取好的特征图上,对所有可能的候选框进行判别。由于后续还有位置精修步骤,所以候选框实际比较稀疏。
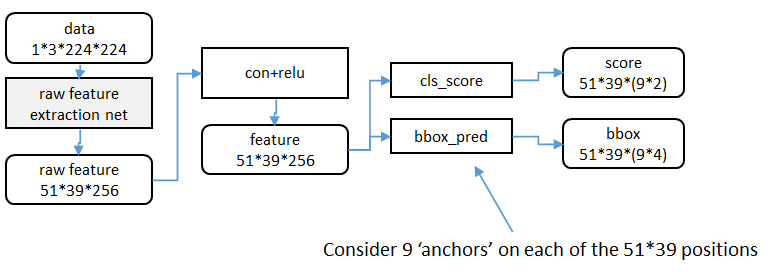
特征提取
原始特征提取(上图灰色方框)包含若干层conv+relu,直接套用ImageNet上常见的分类网络即可。本文试验了两种网络:5层的ZF[3],16层的VGG-16[[^-4]],具体结构不再赘述。
额外添加一个conv+relu层,输出5139256维特征(feature)。
候选区域(anchor)
特征可以看做一个尺度5139的256通道图像,对于该图像的每一个位置,考虑9个可能的候选窗口:三种面积{ 12 8 2 , 25 6 2 , 51 2 2 } × \{128^2, 256^2, 512^2 \}\times{1282,2562,5122}×三种比例{ 1 : 1 , 1 : 2 , 2 : 1 } \{ 1:1, 1:2, 2:1\}{1:1,1:2,2:1}。这些候选窗口称为anchors。下图示出5139个anchor中心,以及9种anchor示例。
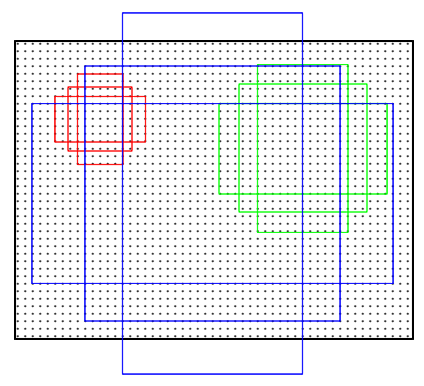
在整个faster RCNN算法中,有三种尺度。
原图尺度:原始输入的大小。不受任何限制,不影响性能。
归一化尺度:输入特征提取网络的大小,在测试时设置,源码中opts.test_scale=600。anchor在这个尺度上设定。这个参数和anchor的相对大小决定了想要检测的目标范围。
网络输入尺度:输入特征检测网络的大小,在训练时设置,源码中为224*224。
窗口分类和位置精修
分类层(cls_score)输出每一个位置上,9个anchor属于前景和背景的概率;窗口回归层(bbox_pred)输出每一个位置上,9个anchor对应窗口应该平移缩放的参数。
对于每一个位置来说,分类层从256维特征中输出属于前景和背景的概率;窗口回归层从256维特征中输出4个平移缩放参数。
就局部来说,这两层是全连接网络;就全局来说,由于网络在所有位置(共51*39个)的参数相同,所以实际用尺寸为1×1的卷积网络实现。
实际代码中,将51399个候选位置根据得分排序,选择最高的一部分,再经过Non-Maximum Suppression获得2000个候选结果。之后才送入分类器和回归器。
所以Faster-RCNN和RCNN, Fast-RCNN一样,属于2-stage的检测算法。
区域生成网络:训练
样本
考察训练集中的每张图像:
a. 对每个标定的真值候选区域,与其重叠比例最大的anchor记为前景样本
b. 对a)剩余的anchor,如果其与某个标定重叠比例大于0.7,记为前景样本;如果其与任意一个标定的重叠比例都小于0.3,记为背景样本
c. 对a),b)剩余的anchor,弃去不用。
d. 跨越图像边界的anchor弃去不用
代价函数
同时最小化两种代价:
a. 分类误差
b. 前景样本的窗口位置偏差
具体参看fast RCNN中的“分类与位置调整”段落。
超参数
原始特征提取网络使用ImageNet的分类样本初始化,其余新增层随机初始化。
每个mini-batch包含从一张图像中提取的256个anchor,前景背景样本1:1.
前60K迭代,学习率0.001,后20K迭代,学习率0.0001。
momentum设置为0.9,weight decay设置为0.0005。[4]
共享特征
区域生成网络(RPN)和fast RCNN都需要一个原始特征提取网络(下图灰色方框)。这个网络使用ImageNet的分类库得到初始参数W 0 W_0W0,但要如何精调参数,使其同时满足两方的需求呢?本文讲解了三种方法。
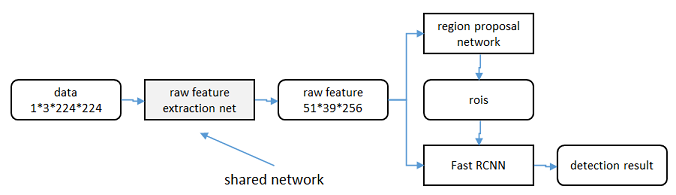
轮流训练
a. 从W 0 W_0W0开始,训练RPN。用RPN提取训练集上的候选区域
b. 从W 0 W_0W0开始,用候选区域训练Fast RCNN,参数记为W 1 W_1W1
c. 从W 1 W_1W1开始,训练RPN…
具体操作时,仅执行两次迭代,并在训练时冻结了部分层。论文中的实验使用此方法。
如Ross Girshick在ICCV 15年的讲座Training R-CNNs of various velocities中所述,采用此方法没有什么根本原因,主要是因为”实现问题,以及截稿日期“。
近似联合训练
直接在上图结构上训练。在backward计算梯度时,把提取的ROI区域当做固定值看待;在backward更新参数时,来自RPN和来自Fast RCNN的增量合并输入原始特征提取层。
此方法和前方法效果类似,但能将训练时间减少20%-25%。公布的python代码中包含此方法。
联合训练
直接在上图结构上训练。但在backward计算梯度时,要考虑ROI区域的变化的影响。推导超出本文范畴,请参看15年NIP论文[5]。
实验
除了开篇提到的基本性能外,还有一些值得注意的结论
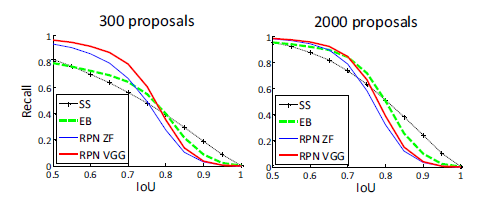
与Selective Search方法(黑)相比,当每张图生成的候选区域从2000减少到300时,本文RPN方法(红蓝)的召回率下降不大。说明RPN方法的目的性更明确。
使用更大的Microsoft COCO库[6]训练,直接在PASCAL VOC上测试,准确率提升6%。说明faster RCNN迁移性良好,没有over fitting。
Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014. ↩︎
Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2015. ↩︎
M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional neural networks,” in European Conference on Computer Vision (ECCV), 2014. ↩︎
learning rate-控制增量和梯度之间的关系;momentum-保持前次迭代的增量;weight decay-每次迭代缩小参数,相当于正则化。 ↩︎
Jaderberg et al. “Spatial Transformer Networks”
NIPS 2015 ↩︎
30万+图像,80类检测库。
责任编辑:xj
-
【PYNQ-Z2申请】图像目标识别FPGA硬件加速2019-01-09 0
-
深度学习RCNN算法2019-08-29 0
-
目标检测实战2019-08-29 0
-
怎么运行Faster RCNN的tensorflow代码2020-06-15 0
-
RK3399 PRO npu支持faster RCNN做全图检测吗2022-04-15 0
-
基于YOLOX目标检测算法的改进2023-03-06 0
-
[目标检测]Faster RCNN算法详解2017-12-06 747
-
人工智能深度学习目标检测的详细资料免费下载2018-08-08 1488
-
一种新的带有不确定性的边界框回归损失,可用于学习更准确的目标定位2019-04-23 6455
-
机器视觉图像处理之目标检测入门总结2020-11-27 4043
-
如何深入了解目标检测,掌握模型框架的基本操作?2020-12-28 1799
-
解读目标检测中的框位置优化2021-06-21 2553
-
基于深度学习的目标检测算法解析2023-01-09 1164
-
无Anchor的目标检测算法边框回归策略2023-07-17 1082
-
都2023年了,Faster-RCNN还能用吗?2023-10-11 674
全部0条评论

快来发表一下你的评论吧 !
