

智慧病房手势识别解决方案
描述
新一年的集创赛已如火如荼的展开~
为了让大家更多的了解该赛事,小编整理了2021年的优秀作品供学习分享
在每周一为大家分享获奖作品,记得来看连载哟 ~
团队介绍
参赛单位:上海交通大学
队伍名称:芯灵手巧
指导老师:王琴、景乃锋
参赛队员:林圣凯、林新源、莫志文
总决赛奖项:二等奖
1.项目概述
1.1 选题背景
我们的选题背景是考虑到很多卧床病人不便于独自向医护人员提出护理请求,因此我们想到在FPGA上部署智能SOC,实现手势识别功能,从而使病人可以使用手势来发出护理请求。
1.2 方案设计
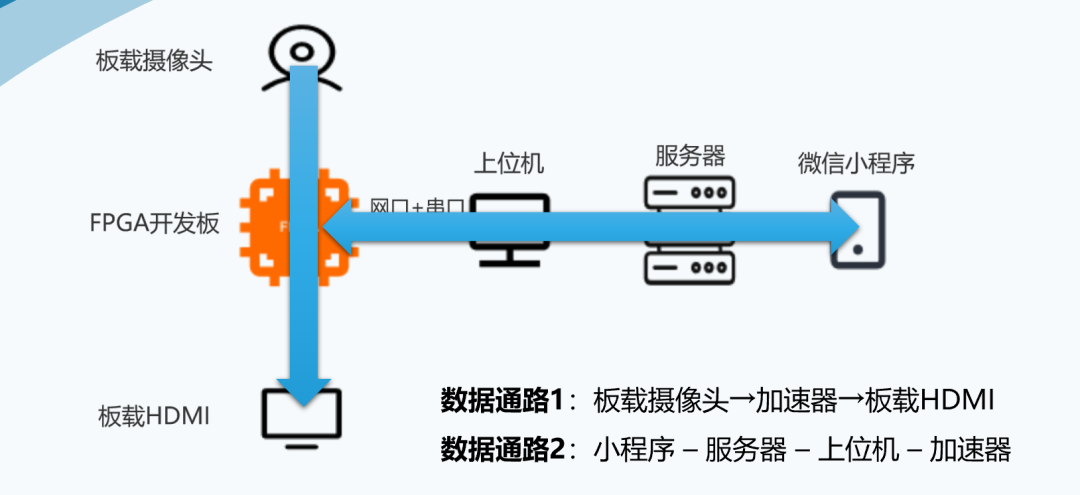
我们共实现了两套方案,其中一套数据通路是从板载摄像头输入,HDMI显示图像,加速器处理后将结果上传上位机
另一套是由小程序采集图像,经服务器、上位机传至加速器,再经由原路返回小程序
1.3 项目工作
我们完成了赛方要求实现的所有基本功能,如表所示。
另外,我们超额完成了网口输入视频流功能、针对医疗应用场景的上位机与小程序设计,同时我们的系统支持不同权重用于不同应用,使得系统应用拓展性进一步提升。

1.4 性能参数
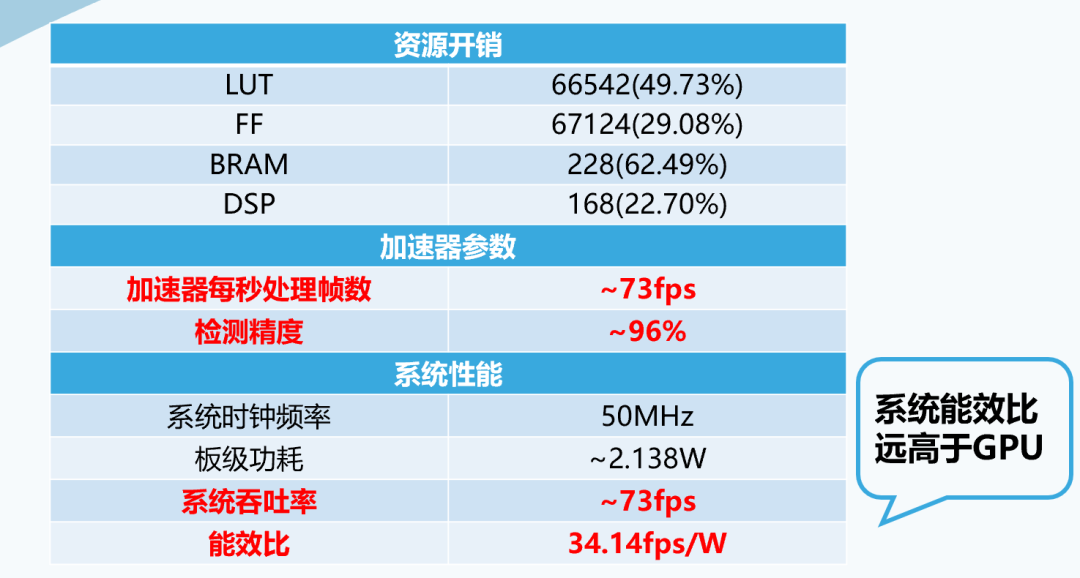
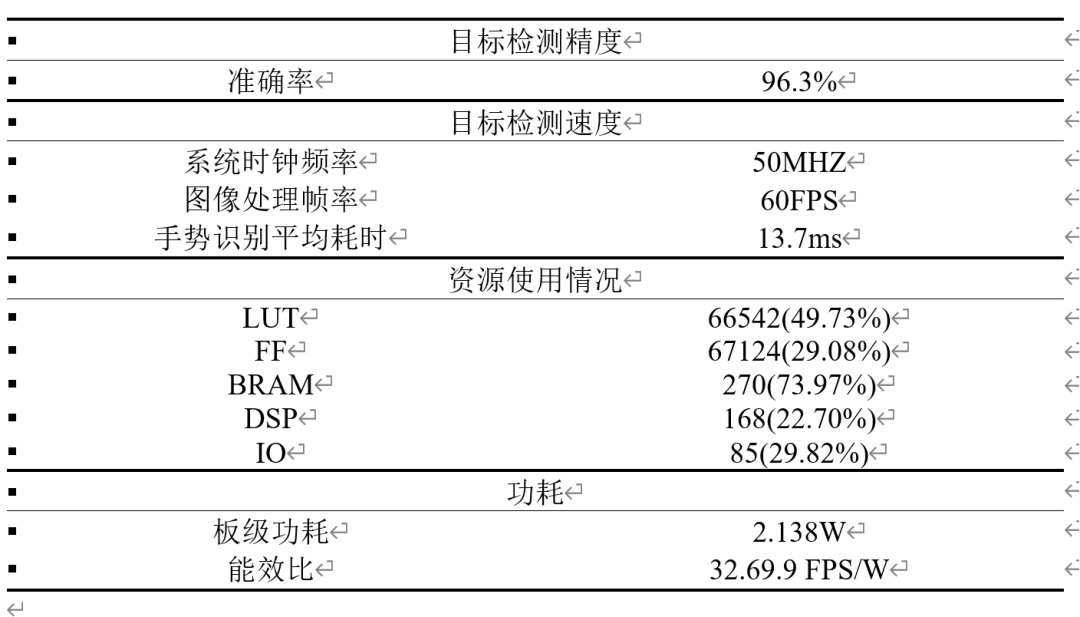
我们的项目已经在Artix-7 200T开发板上实现,在资源开销方面,我们使用了200t开发板三成以下的寄存器和DSP,大约一半的查找表,以及约六成的BRAM。我们的加速器可以每秒处理73帧左右,在测试集上的检测精度达到了约96%。我们的系统工作在50MHz的时钟频率,vivado实现之后显示其板级功耗为2.138W,可计算出能效比为34.14fps/W,经过测试,该能效比远远高于使用GPU或CPU推理时的能效比。
2.硬件介绍
2.1 整体架构
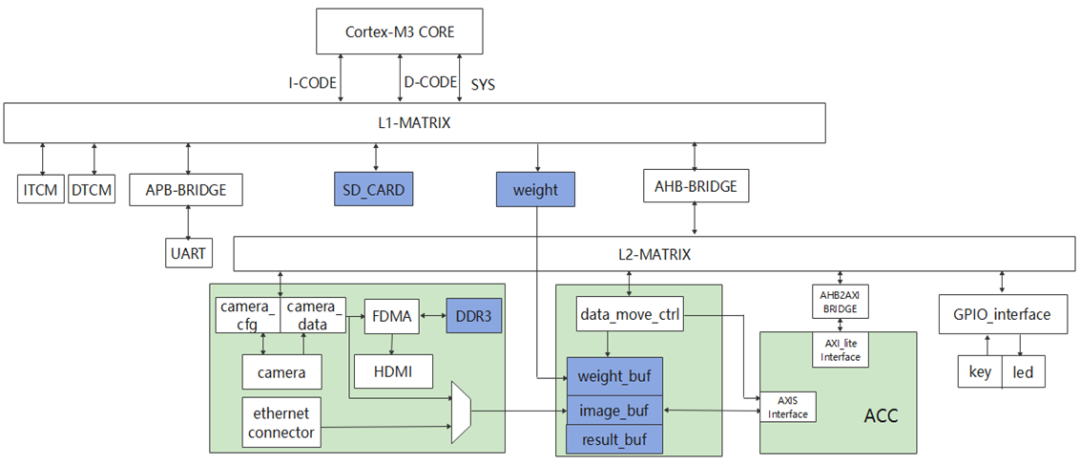
我们的整体系统包括图像采集与显示子系统以及加速器子系统两大部分。
2.2 图像输入与显示子系统
我们的图像采集与显示子系统 可以经由摄像头或网口输入图像,经过MUX选择之后送入加速器。由此我们实现了多数据通路功能。
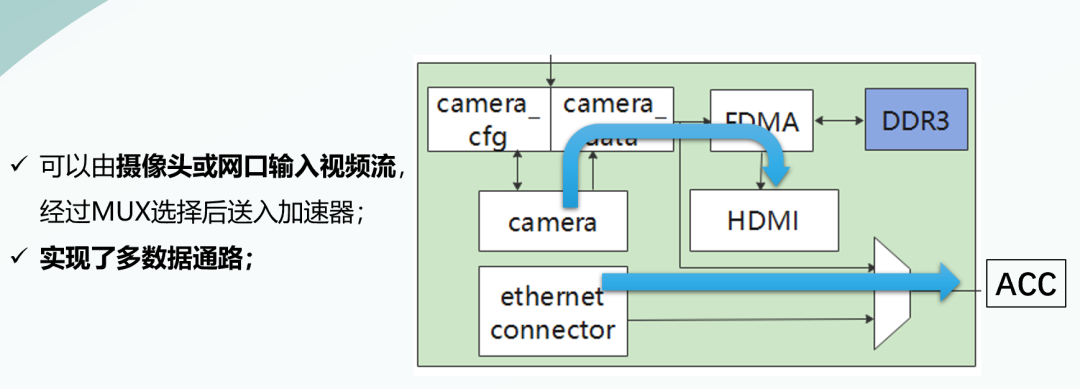
特别地,我们的网口支持360Mbps的网口速率,并在板上实现了UDP、IP、MAC层的接收功能,该部分威廉希尔官方网站 与板载的PHY芯片配合实现了完整以太网接收功能。

2.3 加速器子系统
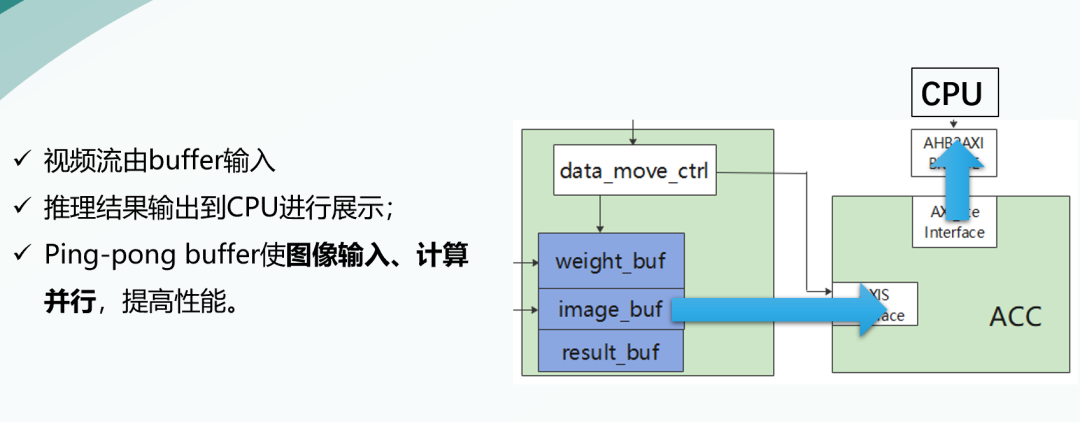
加速器子系统包括加速器及外围缓存。
视频流由buffer输入,推理结果输出到CPU进行展示。
我们使用了Ping-pong buffer使图像输入、计算并行,提高性能。
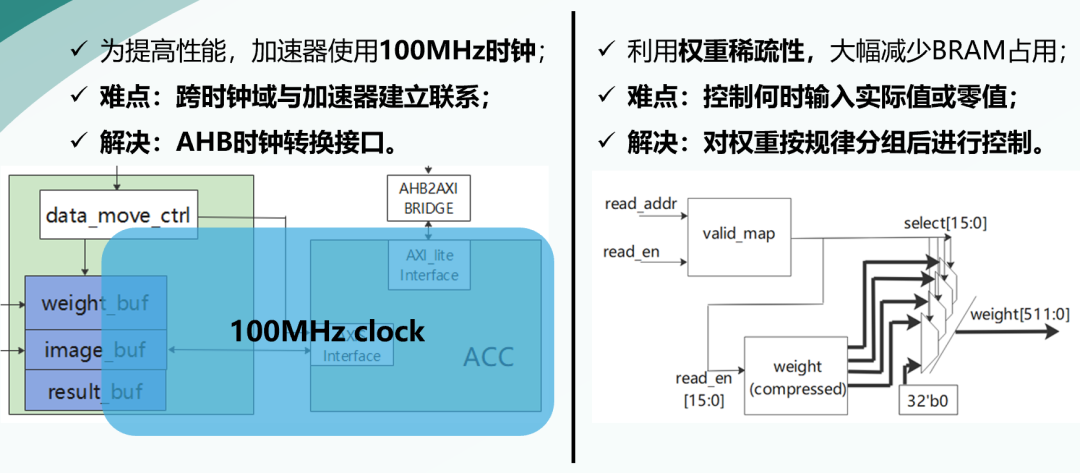
2.4 加速器子系统的优化
在复赛之后,我们团队对系统进行了优化。为提高性能,加速器使用100MHz的时钟,为了解决跨时钟域与加速器通信的问题,我们使用AHB时钟转换接口控制加速器。我们利用加速器权重稀疏性,大幅减少BRAM占用。
为解决权重输入的控制问题,我们对权重按规律分组之后,降低了控制难度。
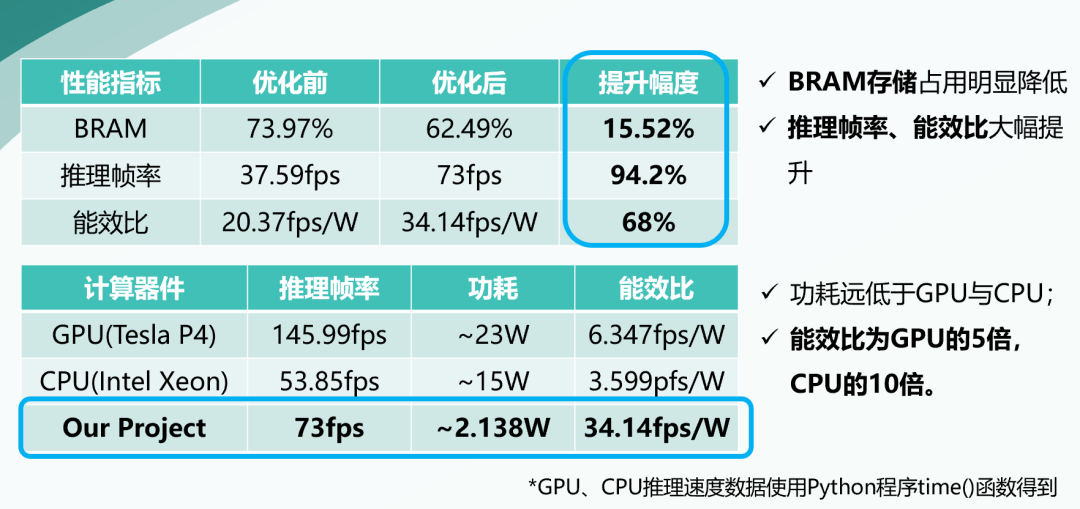
经过了上述优化,我们通过划分时钟域提升了推理帧率,提升幅度达94.2%,同时我们的能效比相比之前提升达68%;我们利用权重稀疏性减少了15.52%的BRAM占用。由此我们的加速器子系统在板上资源占用和性能等方面均取得了明显的改善。最终,经过我们的实际对GPU与CPU的能效比进行测试,我们的SoC系统的能效比远高于GPU和CPU的能效比,是GPU的5倍,CPU的十倍。我们SoC的优化效果显著。
3.软件工作介绍
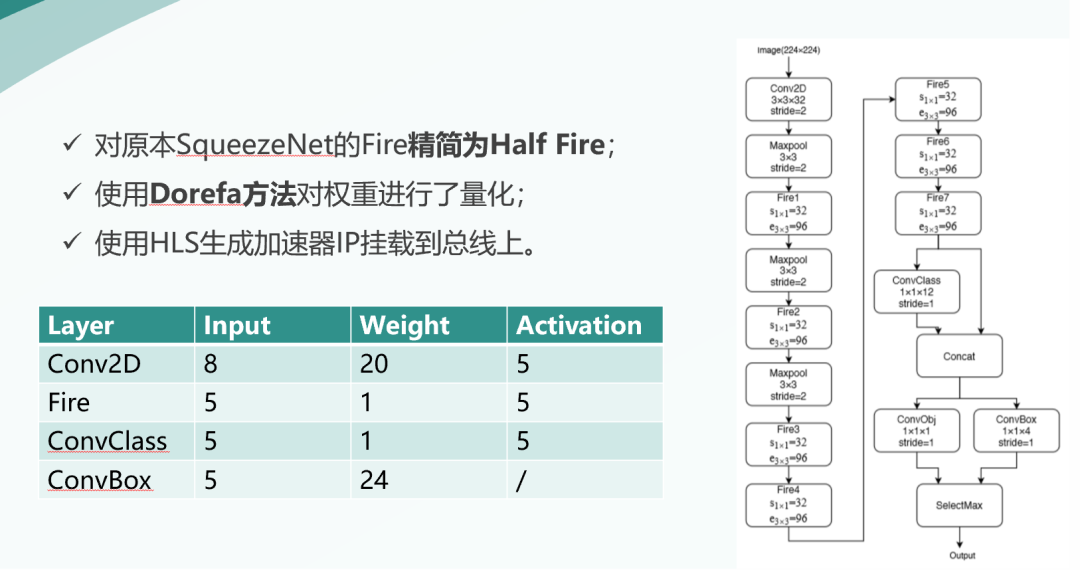
3.1 加速器结构
我们的加速器是基于SqueezeNet设计,将原本的Fire模块进行了一定程度的精简,去除了原本Fire模块中的一些卷积核。
同时我们使用Dorefa方法对网络参数进行低比特量化,我们将大多数权重量化至1bit,输入和输出量化为5bit。
加速器使用HLS编写,并综合之后生成IP,挂载到了总线上。
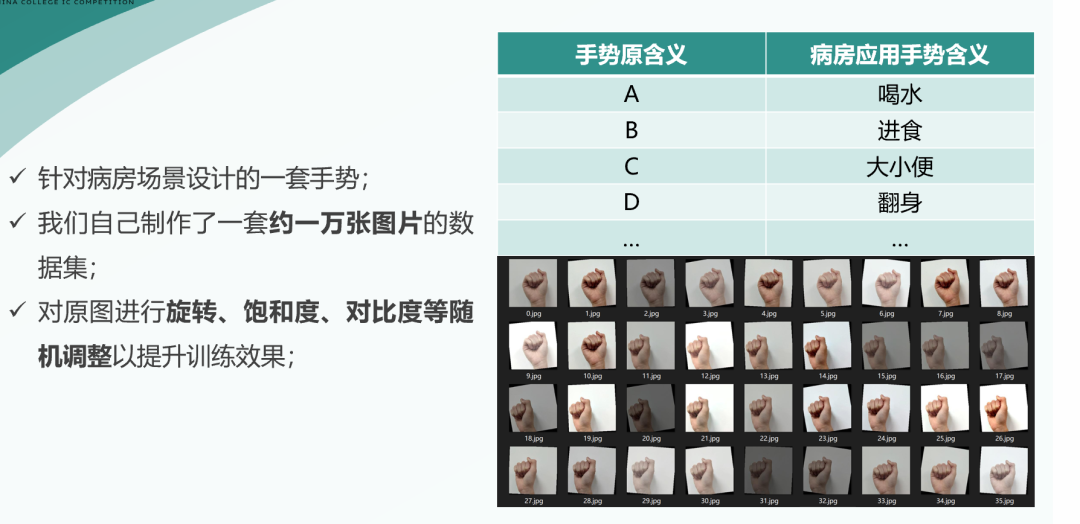
3.2 数据集准备
我们设计了基于美国手语字母的一套手势,我们将原本的字母的含义映射到病房场景下的各种具体含义,如右表所示。
为了训练神经网络,我们自己制作了一套大约一万张图片的数据集,之后随机进行旋转、饱和度、对比度等调整以提升训练效果,最终效果如右下图所示。
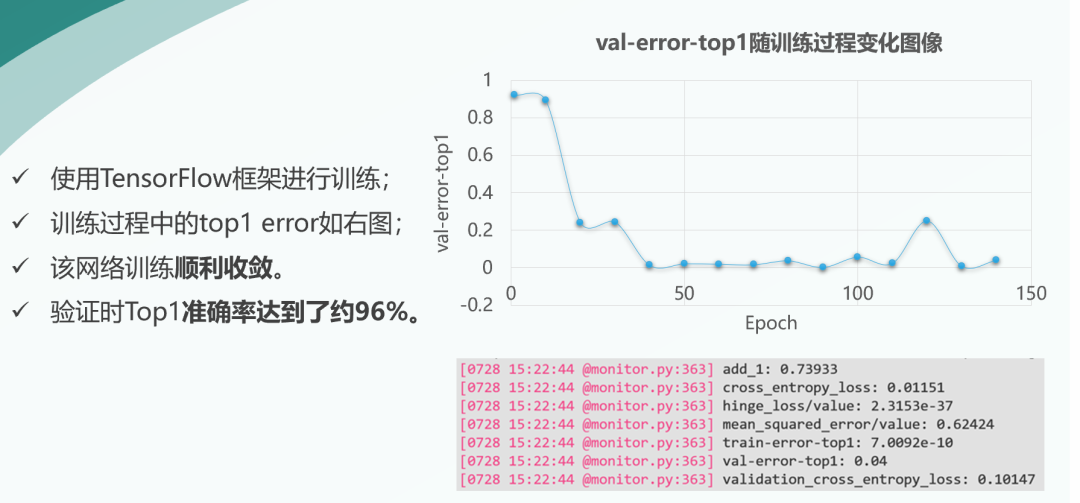
3.3 加速器训练结果
之后我们使用TensorFlow框架进行训练,训练过程中,Top1错误率如右图所示,由图可见,训练过程顺利收敛。最终我们训练Top1准确率达到了约96%
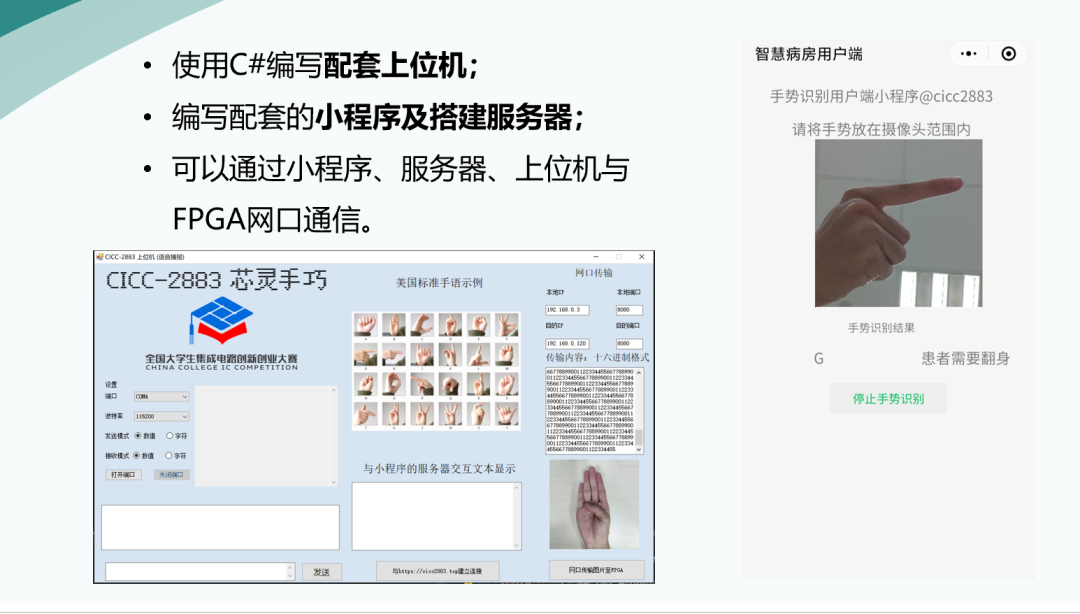
3.4 上位机与小程序
为了提升系统的实际应用效果,我们使用C#编写了配套的上位机,编写了配套的小程序并搭建了服务器。最终我们实现了可以通过小程序、服务器、上位机与FPGA网口通信。
4.仿真与上板测试
我们分别对SoC、DDR、DATA\_CACHE、加速器模块、SD卡、网口模块的进行了modelsim 仿真与上板测试结果或是上板之后利用 Vivado 下的集成逻辑
分析仪(ILA) 对于关键信号线的抓取与验证。在通过以下各个模块的仿真与验证之后, 我们认为相应模块的配置与运行结果都是符合预期的。
4.1 SoC基本功能仿真
在整个项目开始之初,我们在modelsim对SoC基本系统进行了RTL仿真,结果如图4-1所示,在上电复位后,系统总线有相应变化,说明SoC基本系统已正常运行。

4.2 DDR模块
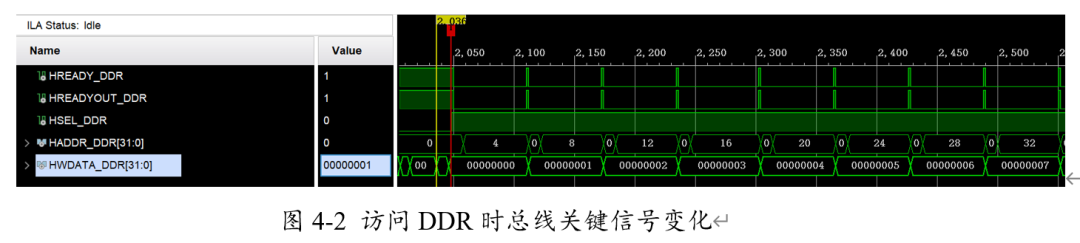
通过使用AHBlite-AXI转接桥,我们将DDR挂载在L1总线矩阵上,并用ila对关键信号进行抓取。如图4-2所示:当总线向DDR连续写入数据时,总线的READY和READYOUT的实现正确握手,数据也正确传递到DDR的相应地址。
4.3 SD卡模块
SD卡在上电后自动进行初始化,在一定时间后可以抓到sd_init_done信号变为高电平,表示SD卡正常初始化完成。
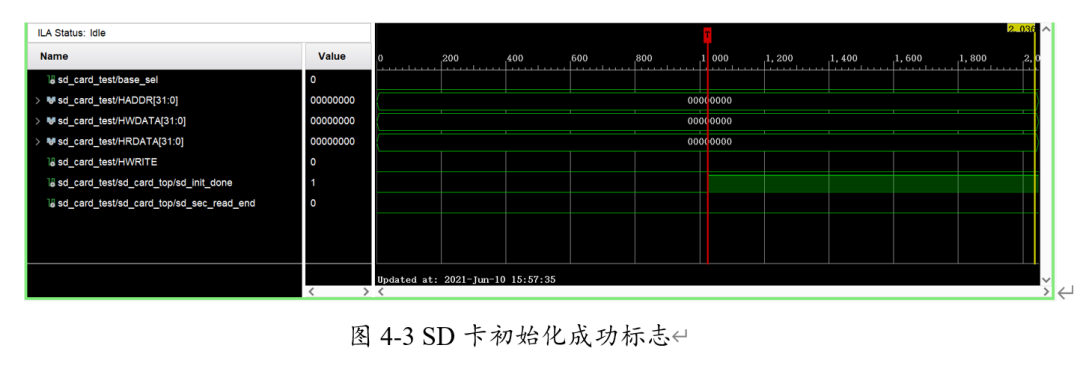
随后,依次配置SD卡的读扇区地址并开始设置开始读取到片上BRAM。该过程总线信号如下。

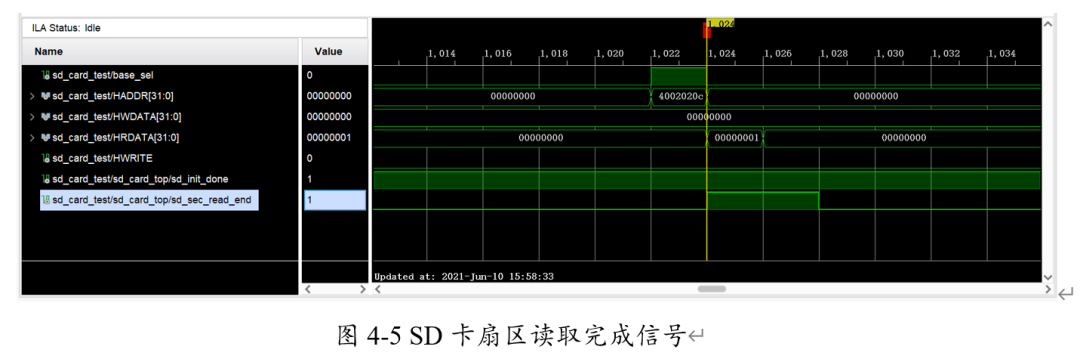
当SD卡一个扇区读取到片上完成时,会拉高sd_sec_read_end,表示当前扇区已经读取完成,如图4-5。
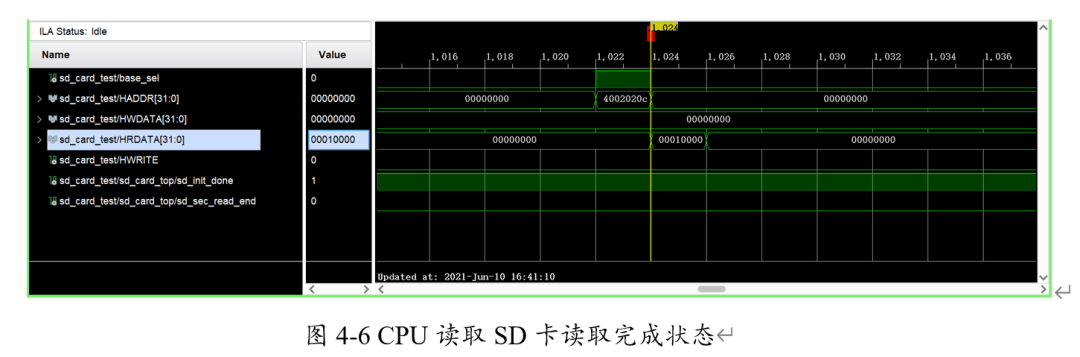
之后CPU便可以查询到SD卡模块相应寄存器的变化为0x00010000,此即读取完成状态,如图4-6。
在之后,CPU就可以直接读取暂存有扇区数据的BRAM,如图4-7。这样SD卡一个读取过程已经完成,此后循环此过程即可。至此SD卡正常工作状态已经得到验证。

4.4 加速器模块
对于加速器模块,我们进行了从TensorFlow平台测试,HLS C仿真,HLS C/RTL协同仿真,加速器搭载在最小系统仿真等非常规范的设计流程。
首先是TensorFlow平台测试,如下图所示:
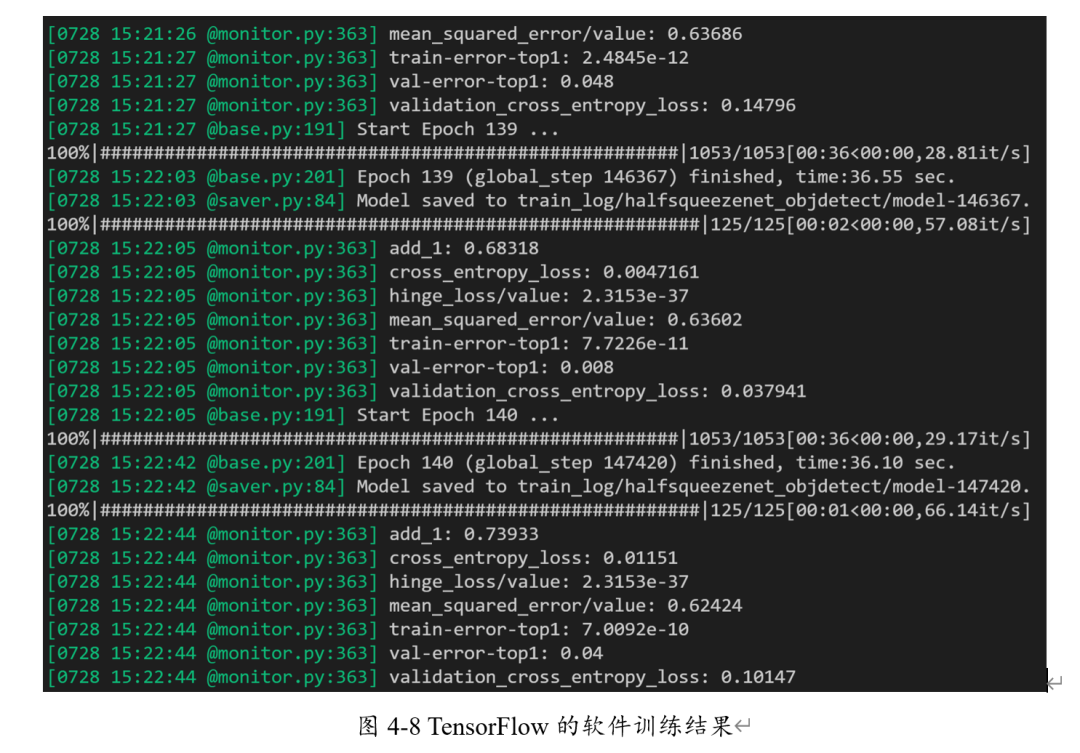
如上图所示,几次测试的Top1-错误率分别为4.8%, 0.8%与4.0%,平均为4.73%。
接着,我们编写了HalfSqueezeNet的HLS C代码,并对其进行了多轮C仿真验证其正确性。下图为举例说明。
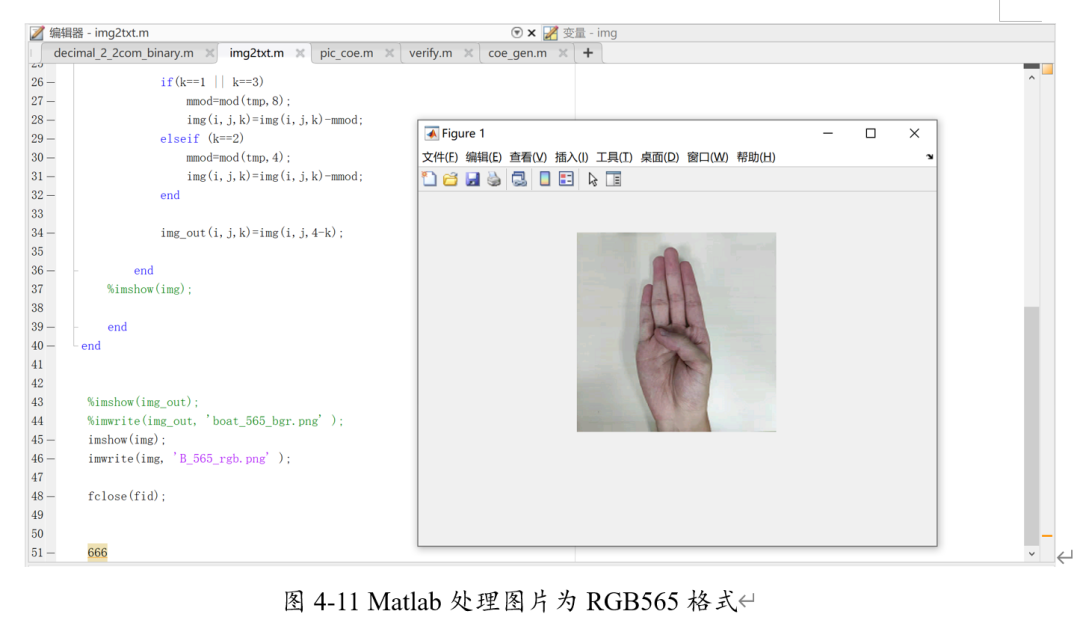
送入的图像为如下所示。

美国标准手语如下:American Sign Language。

对比可知,这是手势B。将其通过matlab转化为565RGB图像,使其与实际摄像头送入的图片格式相同。
对其进行C仿真。(console中的红框表示是C仿真)
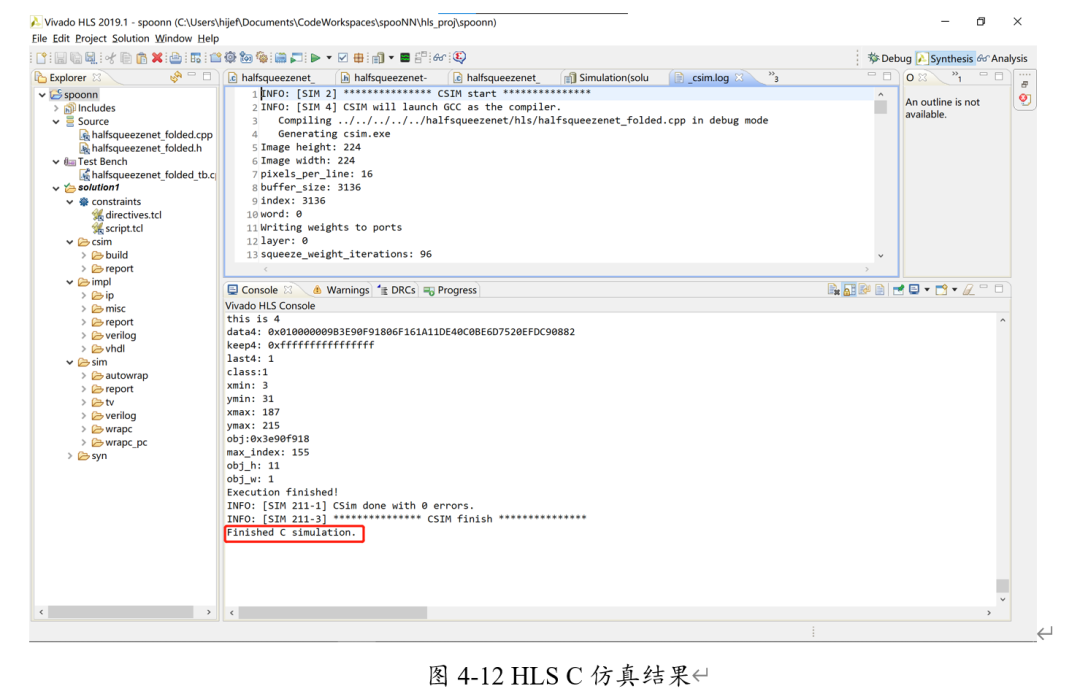
可以看出,C仿真的所得到结果为class=1,由于我们设置class=0为A,class=1为B……以此类推。对比美国标准手势图,可以得知手势的分类结果是正确的。
接下来进行C/RTL协同仿真。(console中的红框表示是协同仿真)
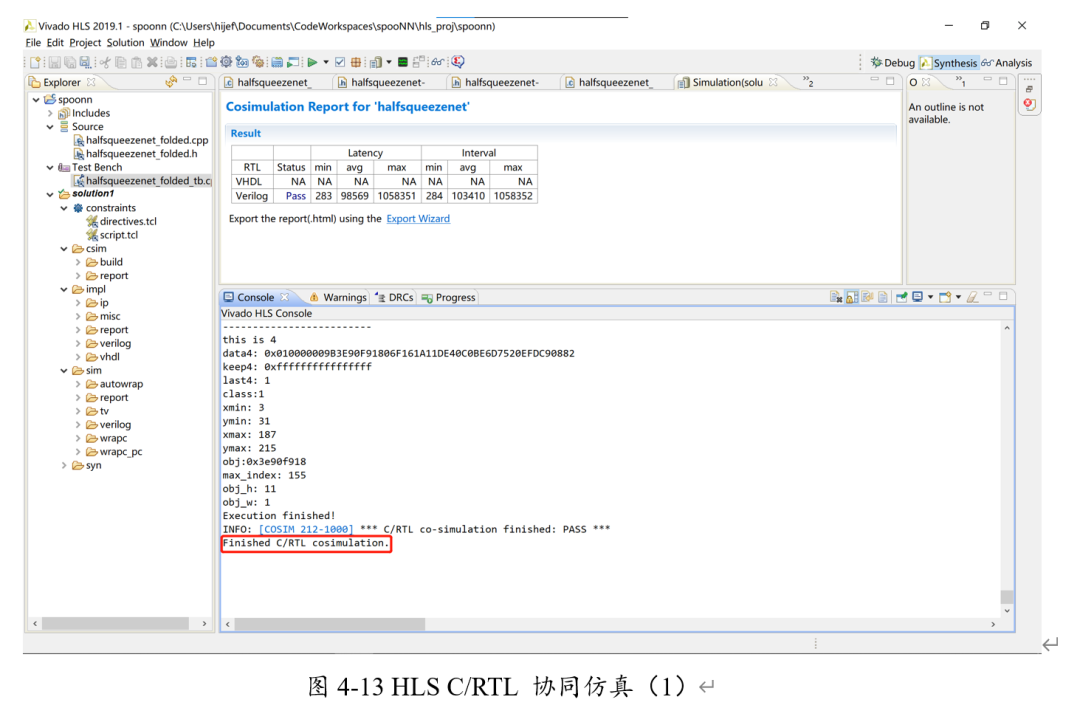
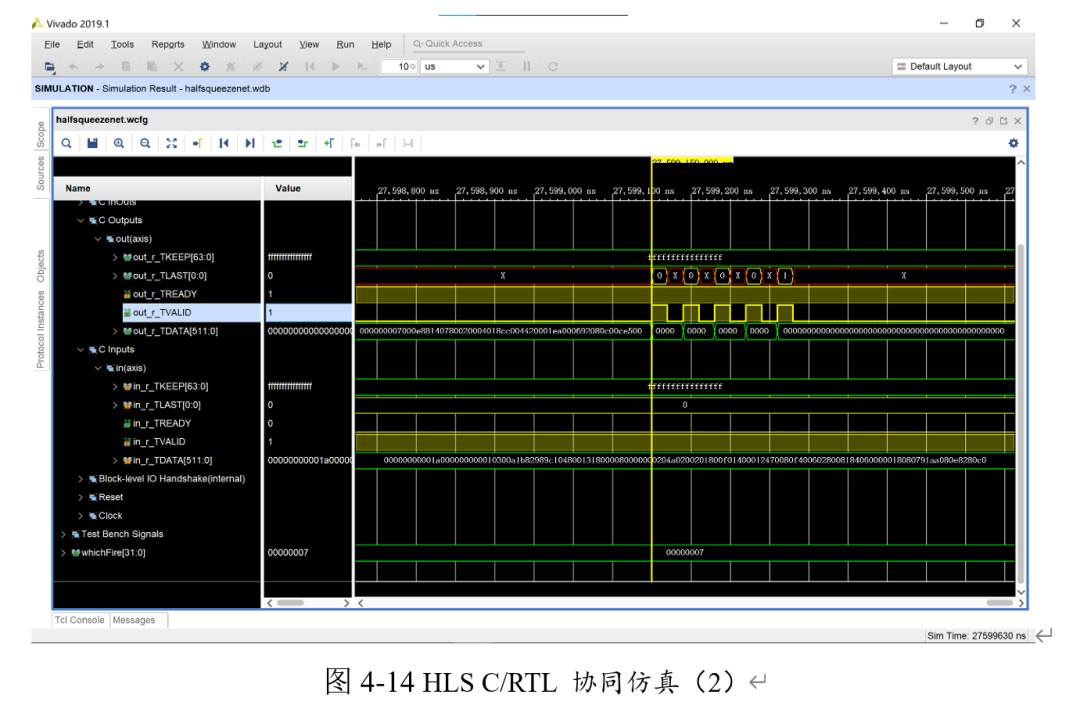
可以看出,分类所得的class=1,即手势B,结果正确。
最后进行最小系统仿真。在搭建完最小系统之后,我们HLS生成的AXI lite与AXI Stream规范进行配置,并将图片和权重转化为COE格式送入BRAM例化。最终所得的结果如下。
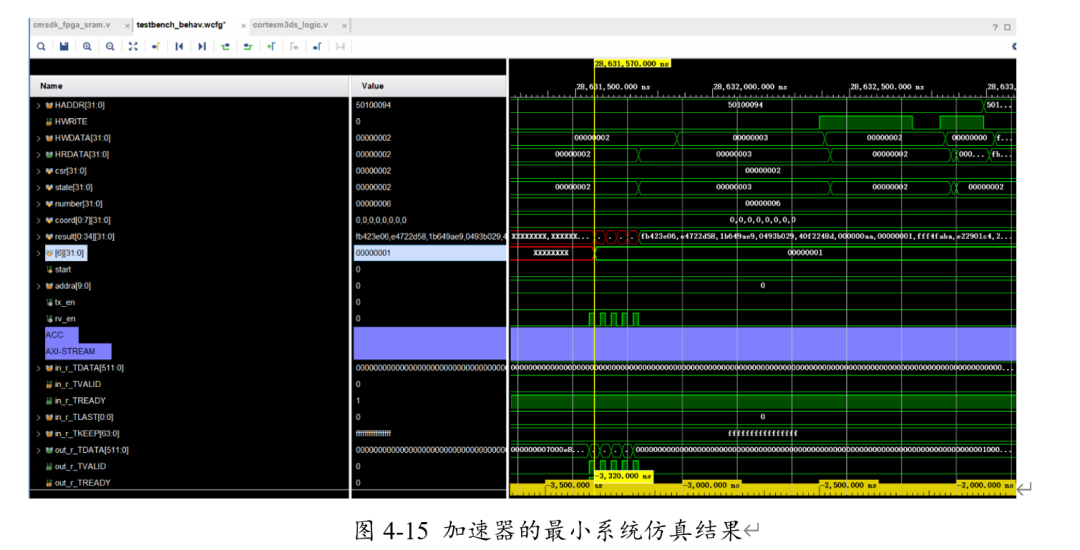
可以看出,最终result[6]的结果为1,即表明最终所得的分类结果为B。
以上,HalfSqueezeNet的TensorFlow测试、C仿真、C/RTL协同仿真、最小系统仿真全部完成,我们有充分的理由相信加速器是可信可靠的。
4.5 网口模块
对于网口模块,我们对网口的最小系统通过抓市面上已有的网口调试助手向FPGA发送数据时抓ILA信号验证了FPGA网口模块的正确性;接着我们自己用C#编写了带网口传输功能的上位机,并通过抓ILA来验证上位机功能的正确性。
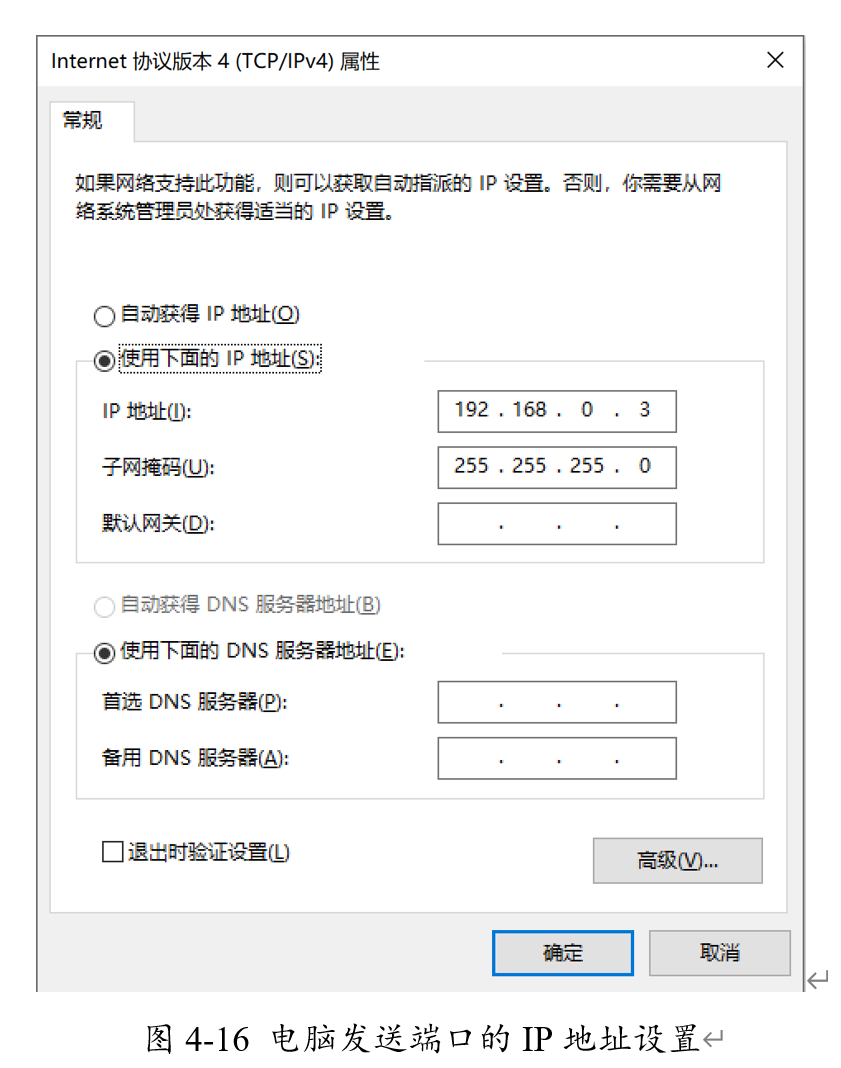
首先在系统中将电脑的网口发送端口设置IP为与FPGA中相同的IP地址,从而使得能顺利通过FPGA中我们编写的UDP协议校验。
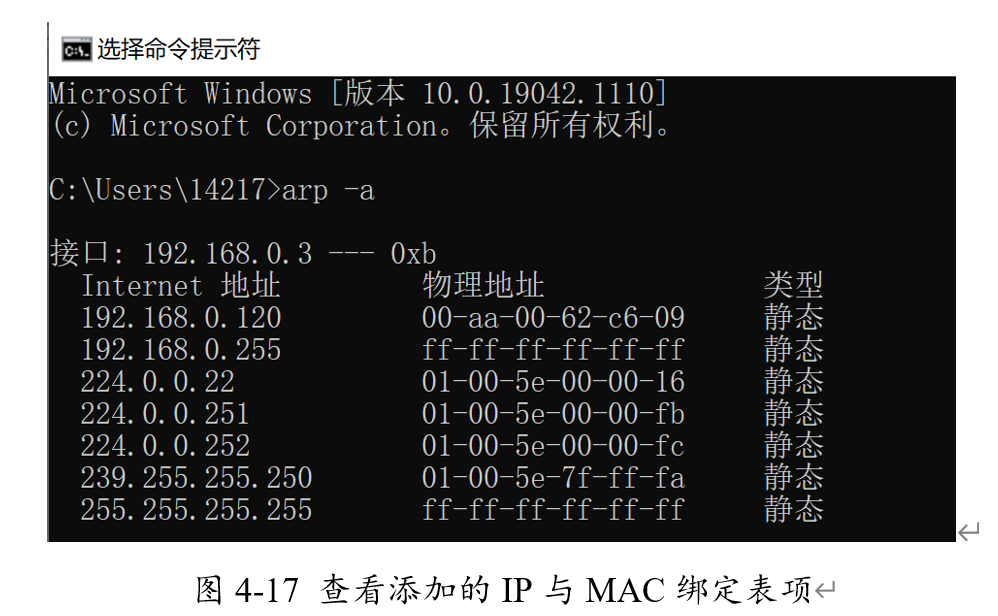
接着,我们在cmd命令行中添加新的静态表项,将FPGA的IP地址192.168.0.120设置为对应的MAC地址设置为00-AA-00-62-C6-09。
利用arp -a命令查看绑定的IP与MAC地址,可以看到对应的表项已成功添加。
下载并打开网口调试助手,设置发送端口与目的端口。发现可以成功打开端口。

点击数据发送,在wireshark上可以抓到对应的长度为22422bytes的udp数据包,其源IP地址为192.168.0.3,目的IP地址为192.168.0.120,信息与之前所设置的可以完全匹配。(下图No.5)
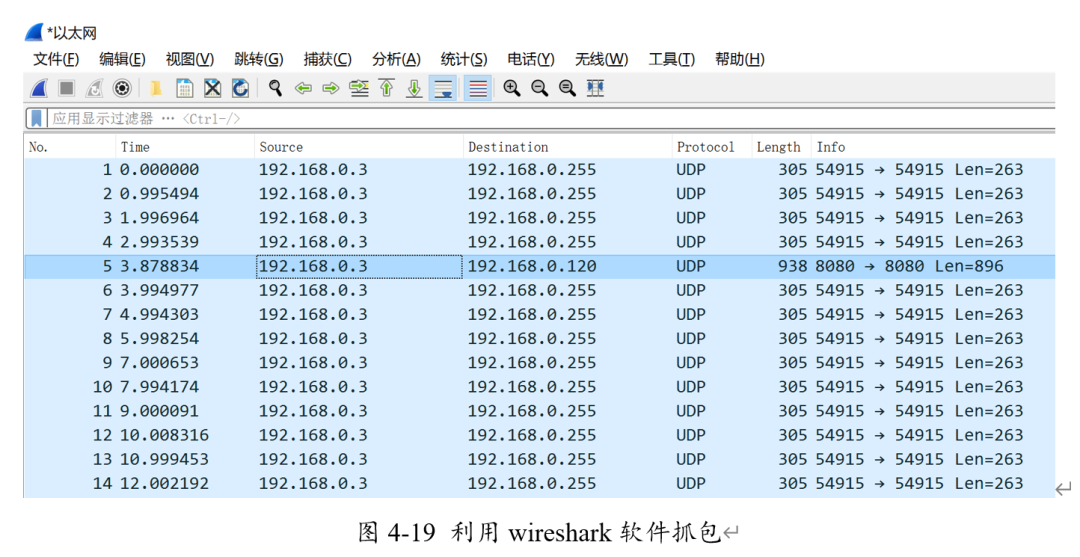
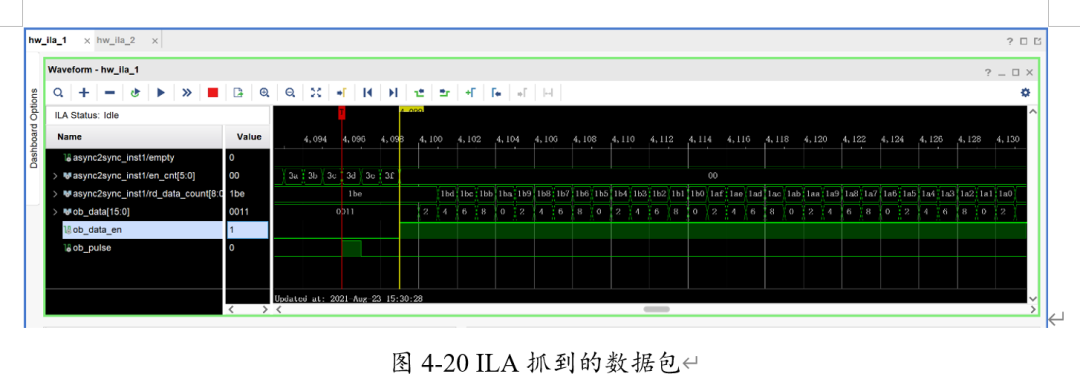
此时向FPGA烧入带有ILA的最小系统比特流,观察数据。发现可以收到电脑发出的UDP包,且数据与长度匹配。
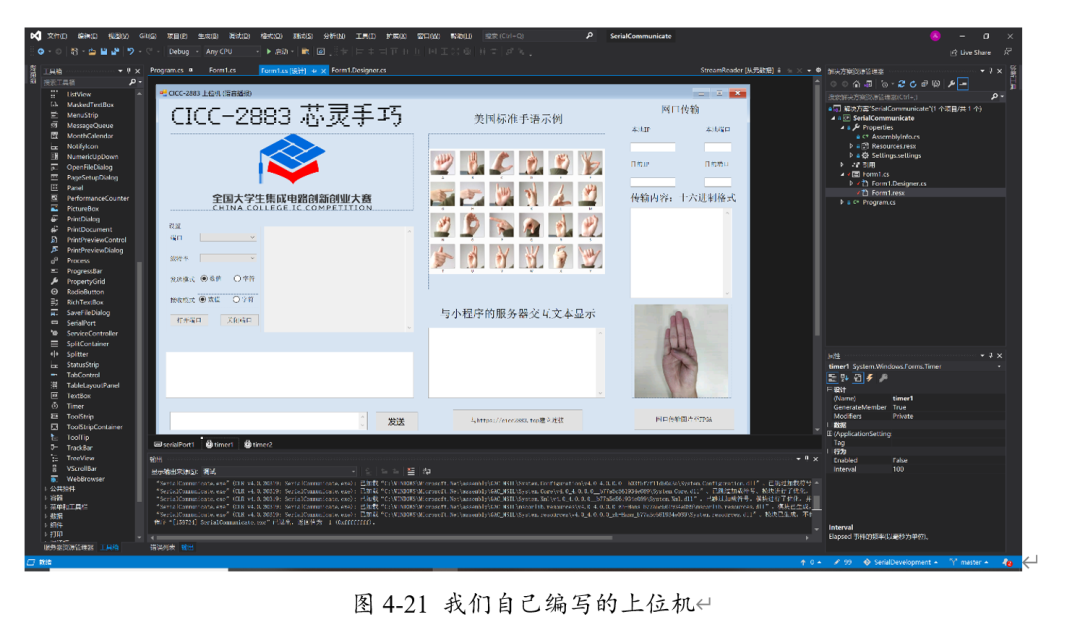
至此,已经可以验证FPGA上的网口是正确无误的;接着需要编写上位机程序。我们利用Visual Studio的C#作为开发环境,编写了带有网口传输、串口打印、与服务器进行HTTP协议通信的上位机。其界面如下:
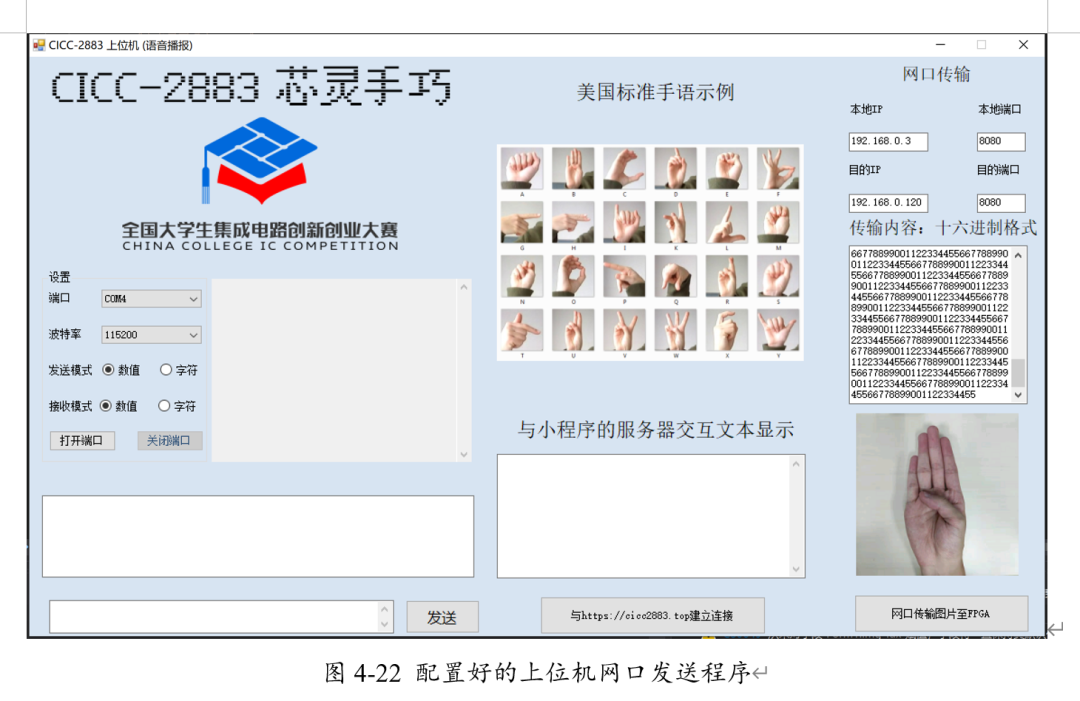
设置对应的源IP、端口号与目的IP、端口号,并生成需要发送的byte流。点击发送。
此时,在ILA中再次抓取数据。
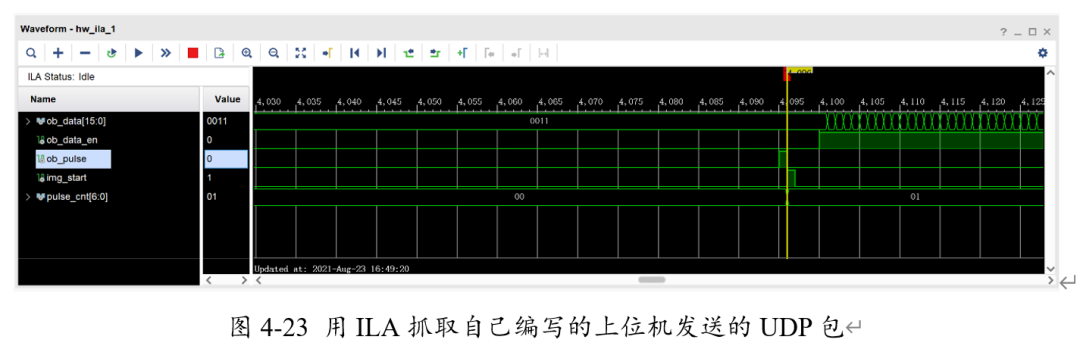
可以看到,数据能够被正确读取。考虑到一个UDP包能传输的字节数有限,我们最终设置每次传输224X2个RGB565数据,即每次传输896个bytes,共计传输112次来完成一张图片传输的协议。其中,Img_start信号为FPGA中每张图片开始传输的信号。
至此,网口部分的验证已经全部完成。
4.5 整体测试结果
5.项目总结
目前该项目在FPGA平台上实现了基于Arm Cortex-M3 DesignStart处理器的面向无人值守的信号处理SoC,可以应用于智慧病房检测等各种无人系统的应用,非常契合赛题的要求,且由于系统的通用性,有着广大的潜在应用场景。
该目标检测SoC基于Arm处理器,采用了两级AHB总线结构,系统中挂载了图像采集与显示模块,SD卡模块,DDR模块,加速器模块等,系统使用摄像头采集图像送入加速器与HDMI模块分别进行目标检测与显示,在我们的设计之下,在系统工作过程中软硬件得以良好协同。我们的系统可以实现对视频流实时、稳定地检测与显示。
由于FPGA的资源十分有限,我们选用了伯克利&斯坦福团队提出的SqueezeNet网络,该网络专为移动或嵌入式场景开发,在保持一定精度的前提下降低了网络大小。同时,为了使该网络可以做成硬件加速器,对该网络又进一步采用了融合BN层,参数归一化和网络结构精简(删除Fire模块中的1X1卷积)等手段使得真正上板的网络进一步减小而精度的下降尚可接受。另外,由于不同网络层之间大多结构相同,我们在HLS的网络中采取了折叠结构实现,使用软硬件协同控制加速器工作时的数据流向,进一步大大节省了有限的板上资源。我们利用数据增强的 DAC SDC 数据集对网络进行了训练,并对权重进行量化。该数据集面向无人机场景,均为无人机拍摄的图片,待识别物体被分为 12 类。
在实际部署中,为进一步节省片上资源,我们对 SqueezeNet 网络进行了简化, 并采用折叠架构。SqueezeNet 主要由若干个 Fire 模块构成,我们仅设计一个简化的、参数可配置的 Fire 模块,称之为 HalfFire 模块。通过对加速器的配置来控制 HalfFire 模块的例化和数据流的走向。数据通过若干次加速器(每次的配置参数均不同)处理后,即可得到检测结果。折叠架构节省了大量的片上资源,便于目标检测与分类 SoC 系统在边缘端的部署。
通过实验测试,该加速器可实现软件平均准确率 96.27%的检测精度; 完成一帧图像的处理平均耗时 28.6 ms,系统吞吐率 34.97 FPS;系统的板级动态 功耗为 1.697 W,完成一帧图像的处理耗能 0.0468 J,能效比为 21.35 FPS/W。同时,系统性能相比于 CPU 加速比显著,相比于 GPU 能效比提升显著。综合来看,系统的性能指标优势显著,达到了2017年IEEE国际一流会议/期刊发表论文相当水平。
该项目在 FPGA 平台上实现了目标检测 SoC 的部署,结合上位机的串口与语音播报,可实现对病房实时、稳定的检测,满足患者的各项需求。该项目实际作为一套通用的加速器平台系统可部署于边缘端,除用于智慧病房检测外,还可通过在SD卡存入训练好的各套权重,最终用于智能视频监控、聋哑人友好的无接触智慧电梯等各个场景,具备较高的通用性,市场前景广阔。
6.参赛体会
参加集创赛作为一段宝贵的实践经验,我们收获颇丰。我们团队大致可以总结出如下几条参赛经验:
1. 扎扎实实一步步仿真、验证每部分威廉希尔官方网站 ,再尝试整合。SoC设计是一个很严谨细致的工程,有任何一个地方有再小的一个bug都会导致系统整体的错误表现。就像我们在复赛前,因为给一些子系统加了新特性之后,比较急切想整合验证效果,便跳过了子系统的仿真验证,直接全都挂到总线上就开始验证,结果出现了问题。团队一起检查了一段时间之后最终还是决定先给各个子系统分别仿真验证,确定子系统没问题之后再整合。最后果然在这个过程中发现是一个子系统存在bug。这次经历让我们得到了深刻的教训:心急吃不了热豆腐,凡事还是要踏踏实实一步一步走。
2. 一切以上板结果正确为最终标准。在本次竞赛的制作过程中,同样是复赛前,我们有几个子系统通过了小系统仿真,之后我们都觉得这部分应该已经没问题了,当时觉得既然是同样的代码仿真过了上板应该也没问题。但是我们团队就遇到了一次尽管仿真正确但上板结果不对的情况,最终只能根据ILA抓信号的结果来debug,而且打乱了我们原本的项目计划。在这之后我们更深刻地理解了指导老师经常催促我们赶紧上板验证的原因。我们懂得了仿真永远只是理论验证,功能验证,而硬件即使做得再完美也有不理想的现象,就完全可能导致与仿真结果对不上的问题。
3. 多学多看多思考,多看看厂商给出的技术文档,以及留出充足的时间来对硬件进行debug。以网口的学习作为经验,首先是要学习最基础的RGMII协议以及UDP协议,然后根据开发板的说明文档查到网口的PHY芯片型号RTL8211EL,然后再根据相应的文档学习芯片的引脚配置。中间也遇到了许多问题,例如开始没有发现PHY芯片的reset需要至少1ms的时间,或是有一个引脚约束xdc文件分配错了却迟迟没有发现,这些都是需要预留充足的时间来debug的。其他模块的编写我想也大致如此,都需要首先对协议本身进行学习,然后根据开发板的不同型号对相应引脚进行配置,最后通过仿真测试以及上板抓ILA进行测试验证,通过后就可以整合进整个系统了。
7.参赛队员介绍
林圣凯
本人2018年进入上海交通大学开始大学本科学业,所学专业为微电子科学与工程。本人成绩优异,曾获何宜慈博士纪念奖学金以及多次校级B类奖学金;并且在本科期间积极参加科研工作,从事过网络系统、量子身份认证以及集成威廉希尔官方网站 SoC设计等方向的科研工作。
在本次集创赛中,我自己对于SoC的基础知识与认识有了大幅度提升,真正做到了学以致用。我觉得这个过程就是一个解决问题与挑战自己的过程。我相信我会以此为起点,在未来的科研工作中继续对自己提出更高的挑战,并将其一一击破。
林新源
我是芯灵手巧组的林新源,是一枚对集成威廉希尔官方网站 设计尤其是系统级设计感兴趣的大三学生。这是最坏的时代,也是最好的时代,我希望自己能够在国家需要的,且自己喜欢的集成威廉希尔官方网站 设计领域做一些有意义的事情。于我而言,集创赛是个起点,在这过程中学到的知识还有完成过程中的态度心境将让我未来受益匪浅。将来,我将去清华大学电子系攻读博士,继续攀登新的高峰。
莫志文
我是CICC2883芯灵手巧组的莫志文,是一名上海交大微电子学院的大三学生,曾获国家级奖学金、校A级奖学金、三好学生等荣誉,成绩位列专业第一。我平日里课业之外喜欢音乐、足球与骑行。我对数字芯片设计颇有兴趣,并即将保研至本系直博继续攻读数字芯片设计。我期待着未来在本领域深耕并作出一些属于自己的贡献。以此次集创赛作为契机,我学到了许多知识,也在管中窥豹——可见一斑中感受到了数字IC设计智慧的博大精深。
恰逢如此的历史时机,我坚信我们这一代人可以扛起这份责任。长风破浪会有时,直挂云帆济沧海!
原文标题:【2021集创赛作品分享】第四期 | 基于Arm核的智慧病房手势识别方案
文章出处:【微信公众号:安芯教育科技】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
基于ToF传感器的3D手势识别解决方案2022-01-17 3437
-
手势识别技术及其应用2023-06-14 2022
-
立体智慧仓储解决方案.#云计算学习电子知识 2022-10-06
-
红外手势识别方案 红外手势感应模块 红外识别红外手势识别2014-08-27 0
-
红外手势识别方案 红外手势感应模块 红外识别2014-09-17 0
-
智慧物业解决方案2017-05-25 0
-
ELMOS用于手势识别的光电传感器E527.162018-11-13 0
-
手势识别PCBA-手势控制零接触抗菌水龙头开发方案2021-12-03 0
-
智慧水利整体解决方案2022-08-25 0
-
基于Microchip的手势识别耳机解决方案2015-08-04 1686
-
手势识别技术原理及解决方案2016-12-22 74946
-
史上最牛高速手势识别系统解决方案2018-09-28 649
-
医院智慧病房的整体解决方案解析2020-03-21 5675
-
智能手势化妆镜手势识别模组芯片底部填充胶应用案例2023-04-07 735
-
POL全光医院解决方案 光纤到病房解决方案 光纤到诊室解决方案(最新版)2023-05-05 377
全部0条评论

快来发表一下你的评论吧 !
