 利用NVIDIA Triton推理服务器加速语音识别的速度
利用NVIDIA Triton推理服务器加速语音识别的速度
网易互娱 AI Lab 的研发人员,基于 Wenet 语音识别工具进行优化和创新,利用 NVIDIA Triton 推理服务器的 GPU Batch Inference 机制加速了语音识别的速度,并且降低了成本。
2001 年正式成立的网易游戏·互动娱乐事业群在经历了近 20 年的发展历程后,以“创新无边界,匠心造精品”为文化基石,创造了一系列大家耳熟能详的代表作品,如梦幻西游系列、大话西游系列、《阴阳师》、《第五人格》、《荒野行动》、《率土之滨》、《哈利波特:魔法觉醒》等。在 data.ai 公布的 2021 全球发行商 52 强榜单中,网易排名第二。
语音识别 AI 算法服务目前已经成为各个领域不可或缺的基础算法服务。网易互娱 AI Lab 为所有互娱游戏的玩家,CC 直播平台用户等提供完善的语音识别服务。语音识别服务每天都有大量的调用量,AI 推理的计算量繁重。
在网易游戏中,语音识别是一个调用量庞大的基础算法服务,如果在语音识别算法服务这里出现时耗或吞吐瓶颈的话,会因为语音内容识别过慢,使得用户使用体验大幅下降。
服务是基于开源框架 Wenet 优化开发,但是 Wenet 框架中非流式部署方案是基于 libtorch 和 C++ 的,并且热词和语言模型部分均采用了 Openfst,速度较慢,也不太方便使用。经过测试 CPU Float32 模式下解码,onnxruntime 要比 libtorch 快了近 20%。在 GPU 部署时还需要有拼接 Batch 的机制,batch inference 虽然在使用 CPU 做推理时没有太大的提升,但是能大大提升 GPU 的利用率。
基于以上的挑战,网易互娱 AI Lab 选择了采用 NVIDIA 在 Wenet 中开源的 Triton 部署方案来改进优化后进行 GPU 部署,使得语音识别速度提高,大幅降低时延和运营成本。
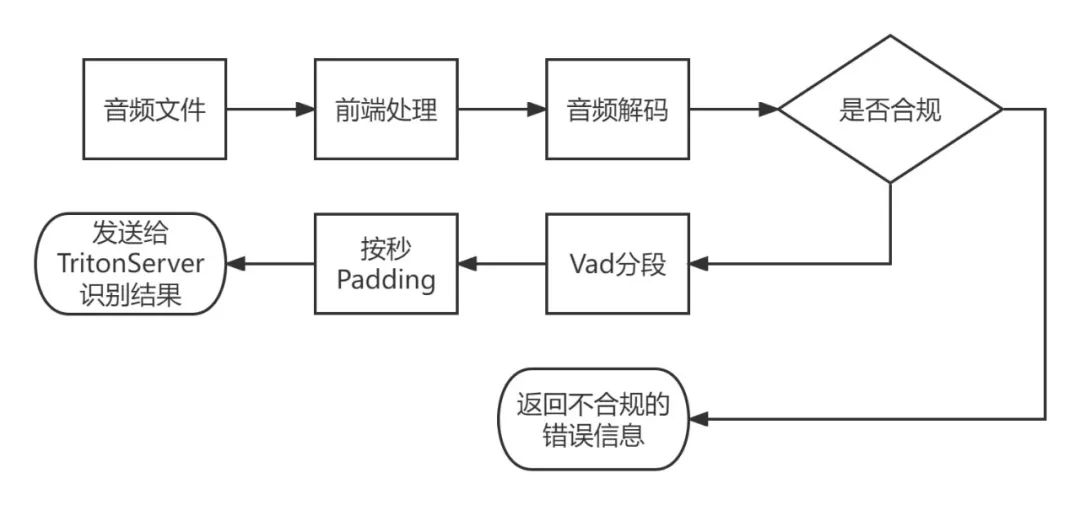
由于 Wenet 开源框架下的 Triton 推理服务器并没有考虑音频解码,显存溢出等问题,所以需要有个前端逻辑做音频解码处理和音频分段处理。并且因为 Triton 推理服务器组 batch 的机制是相同音频长度才会自动组成 batch 做推理,所以前端处理逻辑这块还加上了按秒 padding 的操作。整体流程如图所示。

其中前端处理流程如图所示:
NVIDIA Triton 推理服务器处理流程:
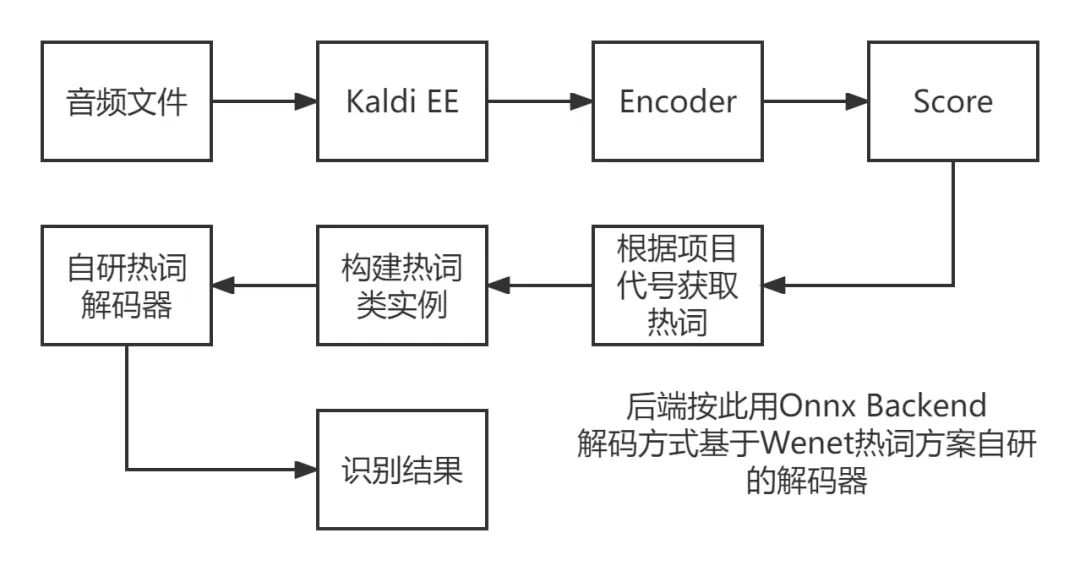
(图片来源于网易互娱授权)
其中 Triton 推理服务器中解码器部分是基于 Wenet 的热词方案而自研实现的热词解码器方案。
QPS,RTF 在 5 秒音频下,CPU 设备和 GPU 设备对比,CPU 为 36 核机器, GPU 为单卡 T4:
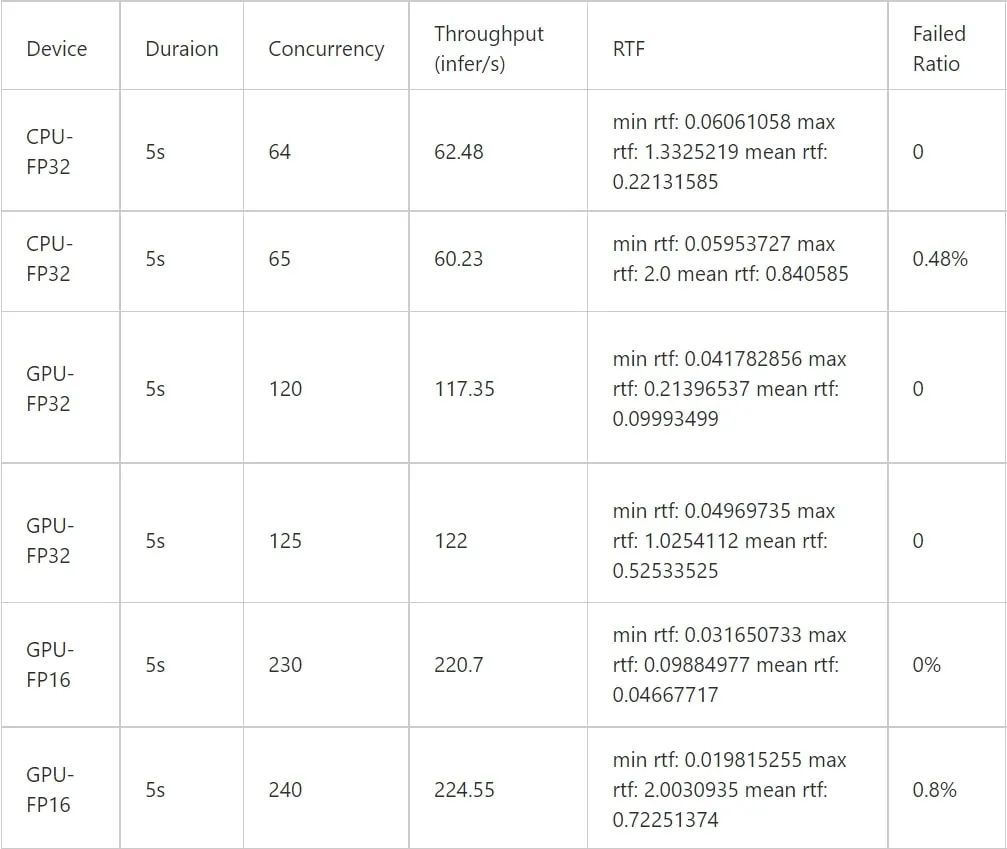
(图片来源于网易互娱授权)
由表格可知,对比 CPU-FP32 与 GPU-FP16,单卡 T4 的推理能力基本相当于 36 核 CPU(Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz)机器的 4 倍。并且实验测试可以得知 FP16 与 FP32 的 WER 基本无损。
自研热词解码器的方法结果展示:
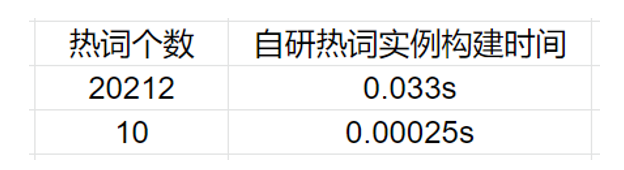
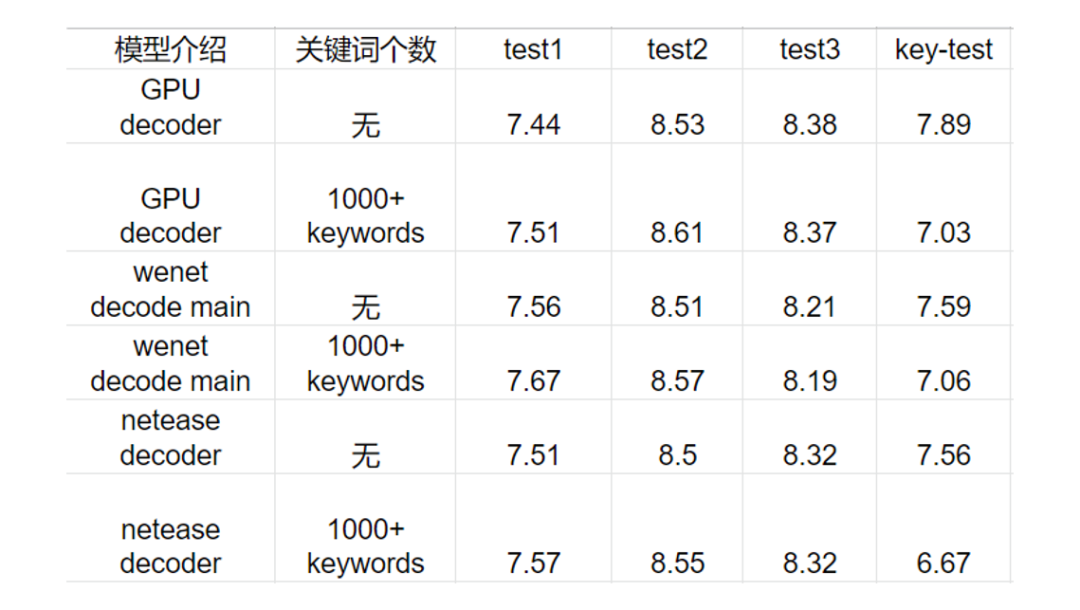
(图片来源于网易互娱授权)
这里 GPU 的效果采用自研的热词增强的方法,识别率在热词这块能有绝对 0.8% 的性能提升,而 Wenet 开源的方法大概是 0.5%。并且自研热词实例的构建耗时基本可以忽略不计。
整体来看 GPU 的方案在识别率基本无损的情况下,单卡 T4 比 36 核 CPU 机器提高近 4 倍的 QPS,单个音频 RTF 测试下,包含音频解码等损耗情况下也能提高近 3 倍,并且也能够支持热词增强功能,让机器成本和识别速度都得到了很好的优化。
网易互娱广州 AI Lab 资深 AI 算法工程师丁涵宇表示:“目前该方案已在网易互娱 AI Lab 语音识别服务落地,大大的降低了识别时延和机器成本。后续,我们还将与英伟达一起研究将热词增强的方法在 GPU 中实现,探索的极致的语音识别推理性能。”
原文标题:NVIDIA Triton 助力网易互娱 AI Lab,改善语音识别效率及成本
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
NVIDIA
+关注
关注
14文章
4994浏览量
103162 -
AI
+关注
关注
87文章
30996浏览量
269297 -
语音识别
+关注
关注
38文章
1742浏览量
112691
原文标题:NVIDIA Triton 助力网易互娱 AI Lab,改善语音识别效率及成本
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
GPU加速云服务器怎么用的
新加坡服务器的速度测试方法有哪些
什么是AI服务器?AI服务器的优势是什么?
AMD助力HyperAccel开发全新AI推理服务器

NVIDIA助力提供多样、灵活的模型选择
英伟达推出全新NVIDIA AI Foundry服务和NVIDIA NIM推理微服务
AI服务器的特点和关键技术
利用NVIDIA组件提升GPU推理的吞吐
语音识别的技术历程及工作原理





 工商网监
工商网监
评论