

Cortex-M0处理器内核异常中断简介
描述
1. Cortex-M0 处理器内核异常中断简介
在Cortex‐M0内核上搭载了一个异常响应系统,支持众多的系统异常和外部中断。其中,编号为1-15的对应系统异常,大于等于16的则全是外部中断,优先级的数值越小,则优先级越高。除了个别异常的优先级被定死外,其它异常的优先级都是可编程的。
因为芯片设计可以修改内核的硬件描述源代码,所以做成芯片后,支持的中断源数目常常不到240 个,并且优先级的位数也由芯片厂商最终决定。
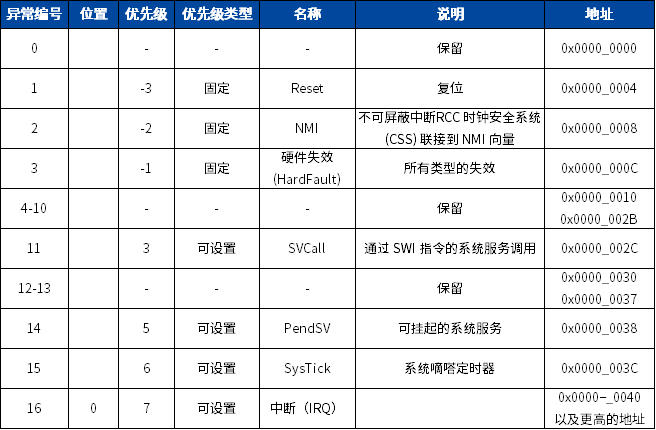
类型编号为 1-15 对应系统异常,在《ARM Cortex-M0权威指南》一书中的第12章节<错误处理>章节中有描述:对于ARM处理器,架构采用错误异常的机制来检测问题,当一个程序产生了错误并且被处理器检测到时,异常中断会被触发,并且核心会跳转到相应的异常终端处理函数执行,错误异常的中断有如下:
Reset
在上下电、NRST拉低、看门狗复位或软复位时启动复位。当复位产生时,处理器停止一切操作,并将复位当做一种特殊形式的异常来执行,进入到对应的中断函数。当复位撤销时,从向量表中复位项提供的地址处重新启动执行,芯片重新开始执行。
NMI
不可屏蔽中断(NMI),可以由外设产生,也可以由软件来触发。这是除复位之外优先级最高的异常中断,NMI永远使能,优先级固定为-2,CSS的时钟安全机制使能判定时钟失效后就会进入到该中断。NMI 不能:
1、被屏蔽,它的执行也不能被其他任何异常中止;
2、被除复位之外的任何异常抢占。
HardFault
HardFault 是由于在正常操作过程中或在异常处理过程中出现错误而出现的一个异常。HardFault的优先级固定为-1,表明它的优先级要高于任何优先级可配置的异常。
SVCall
管理程序调用(SVC)异常是一个由SVC指令触发的异常。在OS环境下,应用程序可以使用 SVC指令来访问OS内核函数和器件驱动。
PendSV
PendSV是一个中断驱动的系统级服务请求。在OS环境下,当没有其它异常有效时,使用 PendSV 来进行任务切换。
SysTick
SysTick是一个系统定时器到达零时产生的异常,软件也可以产生一个SysTick异常。在OS环境下,处理器可以将这个异常用作系统节拍。
中断(IRQ)
中断(或 IRQ)是外设发出的一个异常,或者由软件请求产生的一个异常。在系统中,外设使用中断来与处理器通信,在中断函数中可以查询和清除标志操作。
2. HardFault异常
HardFault (硬件错误,也有译为硬错误)是在MCU上编写程序中所产生的错误,硬件错误处理几乎是最高优先级,它的优先级为-1,只有复位和不可屏蔽中断(NMI)可以对其进行抢占。当它发生时,表示处理器出现了问题,需要采取紧急修复措施。
造成HardFault错误的可能原因较多,如何在代码量较大的情况下,快速定位造成的HardFault的问题代码,就成为比较关键的问题。
本文将以MM32F0130系列MCU为例,Keil-MDK开发环境,总结HardFault的调试、定位方法。在其它Cortex-M0 (M3,M4)内核处理器,和其它开发环境下,也可作为参考。
2.1 可能的原因
《ARM Cortex-M0权威指南》中提到,关于 Cortex M0内核主要有以下几点引起HardFault的原因:
-
非法存储器访问
-
非对齐数据访问
-
从总线返回错误
-
异常处理中的栈被破坏
-
程序在某些 C 函数中崩溃
-
意外地试图切换至 ARM 状态
-
在错误的优先级上执行系统服务调用指令(SVC)
-
数组越界
-
野指针
-
未初始化硬件却开始操作,或无中断服务函数等
-
任务堆栈溢出
-
中断服务函数设置错误
-
时钟异常
2.2 可能出现的异常
如果在执行NMI或HardFault处理程序时,或者在一个使用MSP的异常返回时出栈的却是PSR的时候系统产生一个总线错误,处理器进入一个锁定状态。当处理器处于锁定状态时,它不执行任何指令。处理器保持处于锁定状态,直到下面任何一种情况出现:
-
出现复位
-
调试器将锁定状态终止,出现中止仿真的现象
-
出现一个NMI,以及当前的锁定处于HardFault处理程序中
void HardFault_Handler(void)
{ /* Go to infinite loop when Hard Fault exception occurs */
while (1)
{
}
}下面将在MM32F0130上运行的数组越界代码为例,具体阐述定位步骤:
void StackTest(void)
{ int data[3],i;
for(i=0; i<10000; i++)
{
data[i]=1;
}
}3. 查找HardFault方法和步骤
实际环境中,由于测试高压等产品常常无法连接调试器,故需要代码来定位目标语句地址,并通过一定手段保存:
在MM32F0130中,需先修改启动文件startup\_mm32f013x.s:
HardFault_Handler
PROC
IMPORT hard_fault_handler_c;函数声明
MOVS r0, #4 ;判断主栈指针还是进程栈指针
MOV r1, LR
TST r0, r1
BEQ stacking_used_MSP ;如果是主栈指针
MRS R0, PSP ;否则是进程栈指针,把进程栈指针地址付给 R0
B get_LR_and_branch ;跳转到 HardFault 中断程序
stacking_used_MSP
MRS R0, MSP ;把主栈指针地址赋给 R0
get_LR_and_branch
MOV R1, LR
BL hard_fault_handler_c
ENDP该段代码会判断当前堆栈使用的是MSP或PSP,然后将堆栈参数传递给hard\_fault\_handler\_c函数,该函数定义如下:
void hard_fault_handler_c(unsigned int * hardfault_args, unsigned lr_value)
{ unsigned int stacked_r0; //压栈的 r0
unsigned int stacked_r1; //压栈的 r1
unsigned int stacked_r2; //压栈的 r2
unsigned int stacked_r3; //压栈的 r3
unsigned int stacked_r12; //压栈的 r12
unsigned int stacked_lr; //压栈的 lr
unsigned int stacked_pc; //压栈的 pc
unsigned int stacked_psr; //压栈的 psr
stacked_r0 = ((unsigned int) hardfault_args[0]);
stacked_r1 = ((unsigned int) hardfault_args[1]);
stacked_r2 = ((unsigned int) hardfault_args[2]);
stacked_r3 = ((unsigned int) hardfault_args[3]);
stacked_r12 = ((unsigned int)hardfault_args[4]);
stacked_lr = ((unsigned int) hardfault_args[5]);
stacked_pc = ((unsigned int) hardfault_args[6]);
stacked_psr = ((unsigned int) hardfault_args[7]);
while(1)
{
printf("[Hard fault handler]
");
printf("R0 = %x
", stacked_r0);
printf("R1 = %x
", stacked_r1);
printf("R2 = %x
", stacked_r2);
printf("R3 = %x
", stacked_r3);
printf("R12 = %x
", stacked_r12);
printf("Stacked LR = %x
", stacked_lr);
printf("Stacked PC = %x
", stacked_pc);
printf("Stacked PSR = %x
", stacked_psr);
printf("SCB_SHCSR=%x
",SCB->SHCSR);
printf("Current LR = %x
", lr_value);
}
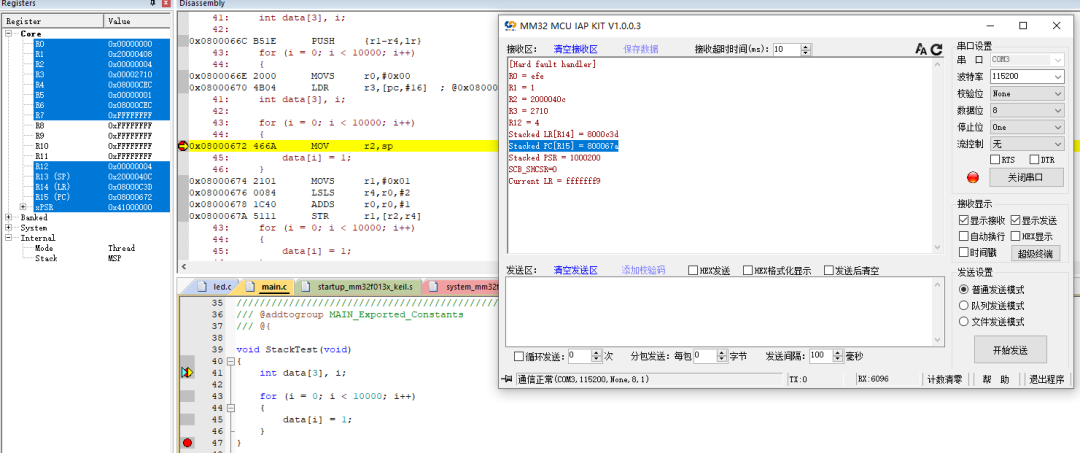
}处理器进入到HardFault,将R0~R3、R12、LR、PC信息通过串口打印,根据寄存器信息排查问题代码。
当处理器处理异常时,除非异常是一个末尾连锁异常或迟来的异常,否则,处理器把信息都压入到当前堆栈中入栈(stacking),8个数据字的结构被称为栈帧(stack frame),栈按照双字地址对齐方式。
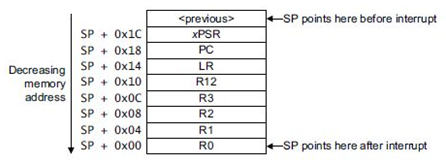
入栈后,堆栈指针立刻指向栈帧的最低地址单元。栈包含返回地址,这是被中止的程序中下条指令的地址。这个值在异常返回时返还给 PC,使被中止的程序恢复执行。
如下图连接仿真器查看汇编的地址可以找到是程序问题,根据PC指针地址,在程序生成的.map中查找出问题函数。
4. 处理建议
根据上述的定位手段可以查找是哪一种情况造成的异常,在编程过程中需要避免出现上述异常情况,但是在恶劣复杂的环境下,可能会小概率触发HardFault中断,可以在函数中添加复位或者跳转指令,具体的实现方式需根据应用和使用环境来评估。
原文标题:HardFault定位方法和步骤
文章出处:【微信公众号:安芯教育科技】欢迎添加关注!文章转载请注明出处。
-
Cortex-M0处理器的故障处理和功耗管理资料下载2021-04-08 949
-
Cortex-M0处理器的基础知识2021-02-26 0
-
Cortex-M3处理器是什么2021-07-16 0
-
中断事件的异常处理是什么意思2021-12-21 0
-
制造一种基于Cortex-M0和Cortex-M3处理器的SoC2022-07-27 0
-
ARM Cortex-M0处理器内核LPC1100系列微控制2010-08-31 3521
-
基于ARM Cortex-M0处理器的LPC1200工业控制系列2011-02-24 1320
-
ARM为主流嵌入式SoC设计提供免费的Cortex-M0处理器IP2015-10-15 2629
-
采用ARM Cortex-M0处理器内核 英飞凌XMC1302马达控制解决方案2017-08-04 9561
-
ARM异常中断的原因及处理措施2020-06-17 8089
-
Cortex-M0处理器的存储模型资料下载2021-04-08 802
-
Cortex-M0处理器的异常处理模型资料下载2021-04-08 776
-
Cortex-M0处理器的编程模型资料下载2021-04-11 806
-
Cortex-M0处理器及其特性资料下载2021-04-13 998
-
Cortex-M0处理器的中断请求形式:电平触发和脉冲输入2022-05-13 1729
全部0条评论

快来发表一下你的评论吧 !
