

关于内存缓存的那些事
描述
内存中的数据被划分成若干个缓存块,每个缓存块的大小正好对应着一整个三级缓存的大小。如此一来,数据在内存中缓存块里的偏移量正好就对应着该数据应该存在于缓存中的位置。举个例子,假设内存中一共有四个缓存块,记为00,01,10,11四块。每个缓存块又可以划分成四个缓存行,记为00,01,10,11四行。结合起来,最上面缓存块的最上面的缓存行就可以写成0000,则这个部分的数据应该存在于缓存中的第一个缓存行的位置即00位置。如果1000号缓存行需要写入,那么就要把0000号缓存行擦除再写入,不能存储在缓存中别的地方即使还有空间存放。
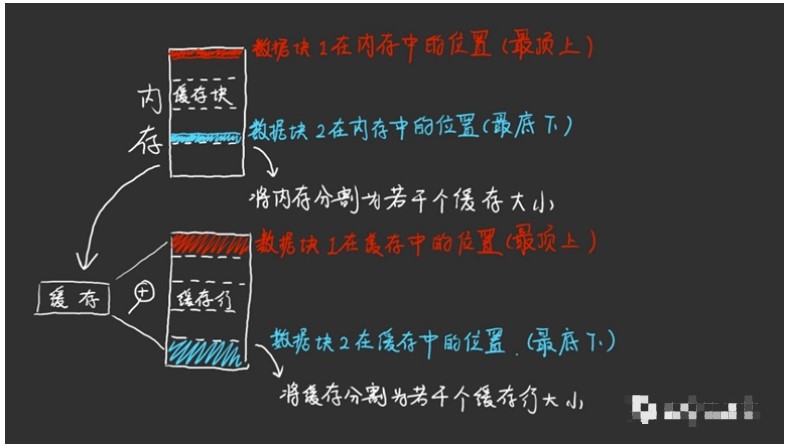
从内存到缓存的分类规则
我们会发现一个问题,就是如果我们持续需要0000号缓存行和1000号缓存行中的数据,那么这俩缓存行会被互相擦除写入,就像打乒乓球一样,擦了又写,写了又擦,而缓存中可能别的位置还空着,造成浪费资源,效率低下的乒乓效应。
解决的办法之一就是加大缓存容量。很好理解,缓存变大了,取一个极限,假设缓存和内存一样大了,那肯定就不存在乒乓效应了,但是这几乎不可能。
还有一个有意思的思路是,设置一个受害者缓存,(哈哈,这个英文名是我自己乱翻译的)。这个受害者缓存会暂时保留一下不久前刚被擦除的数据,缓存控制器在读取缓存时就捎带看看这个受害者缓存里有没有想要的数据,如果真的碰到了,那这个数据真就是受害了,冤的很。这个威廉希尔官方网站 实现也很简单,没啥难度,就是效果可能有点玄学。
有没有什么不那么玄学的方法呢?于是前人提出了多路组关联。既然前文如此粗暴的分割方式会造成乒乓效应,那么我们干脆多来几个可替换的位置。还是以上面的例子,假设内存中一共有四个缓存块,记为00,01,10,11四块。每个缓存块又可以划分成四个缓存行,记为00,01,10,11四行。现在不同的是我们把缓存划分成两路,暂且叫做A路和B路吧。保持和上文中的缓存容量大小一致,那么每路缓存中现在只够存储两个缓存行了,记为0号和1号缓存行。总结一下,现在缓存方面有AB两路,每路有01两行。内存方面则一共有四个缓存块,每个缓存块有四个缓存行。现在规定内存中缓存行编号最后一位是0的可以存在缓存的A或B路的0号缓存行中,内存中缓存行编号最后一位是1的可以存在缓存的A或B路的1号缓存行中。发现问题没有?因为末尾为同一编号的缓存行可以同时存在于A或者B中,因此乒乓效应会有所改善。
上述例子展示的是两路组关联,目前主流使用的是四路组关联,但实际上路的个数要结合缓存与内存的比例来综合判断,例如上述例子,两路组关联就不太合适,单路的容量被压缩得太小了。
另外,上文所讲的是内存和三级缓存之间的关联情况,该情况可以推广至三级缓存和二级缓存之间以及二级缓存和一级缓存之间。在此就不再赘述了。
这里还是要注意一个之前说过的细节,CPU并不会主动控制缓存写入内存中的数据的,也就是说缓存对于CPU来讲是透明的(这个词不是很容易理解,但是这就是之前人们翻译的,我建议翻译成无感知)。CPU只是说我要读这块内存里的数据,它甚至不知道这个内存数据在哪里,它只负责宣布这件事,而缓存和内存则负责把它要的数据喂给它而已。缓存在喂给它之后留了个“心眼”——“咱家主子(CPU)最近偏爱000110100这块内存数据,我就把这块数据留在我这里,到时候要的时候拿着方便“。看懂了吗?一切都是奴才自作主张。
再打个比方,CPU和缓存的关系就像我和我的胃。我不用控制我的胃蠕动消化,我不用控制神经元突触释放神经递质,我只负责做最高级,最抽象的工作,比如控制我的手写下这篇文章。我不知道我有胃这种东西,也不知道什么神经递质、细胞、组织啥的,就像CPU不知道缓存一样,我之所以知道这些是因为有人做了人体解剖等生物研究,CPU想了解这些可能得等人工智能解剖另一个人工智能的时候,或者——用它的意识来读读我这篇文章。
话说回来,各级缓存之间有两种不太相同的缓存策略,分别是Inclusive和Exclusive。
前者意思是包含,后者意思是不包含。包含的意思是,三级缓存中一定会存在着二级缓存和一级缓存里的数据,二级缓存一定会存在着一级缓存的数据,其实质就是数据从三级往一级走的过程中用的是“复制”。
而不包含的意思是,三级缓存中必不存在二级缓存和一级缓存里的数据,二级缓存中必不存在一级缓存的数据,其实质就是数据从三级往一级走的过程中用的是“剪切”。这两种缓存策略的优劣应该一眼能看出:包含策略会造成缓存空间浪费,并且各级之间的数据更新需要保持同步,优点则是数据的废除很直接,还有一个优点这里先挖个坑吧。而不包含策略则不会造成缓存浪费,并且具有很好的缓存一致性(即不需要同步),但是数据交换量会变得很大。
这里分别用缓存写入数据的例子说说包含和不包含两种缓存策略。一开始,CPU首先发出一个读内存指令,该指令会附带着该内存地址从CPU内核转发至一级缓存控制器,假设一级缓存没有在本级缓存找到想要的数据,那么就会将读内存指令的请求往二级缓存控制器转发,以此类推,如果都没能找到数据,那么最后内存控制器会得到这条读内存指令,并将数据返回至CPU内核,同时该条数据会在CPU的一级缓存上得到保存(如果是使用Inclusive缓存策略,那么该数据也同时会在二级和三级缓存上得到保存),以便于下次再次使用。然而缓存在电脑开机之后不久肯定就被填满了,这时候要有新的数据要写入缓存那么肯定需要把一些过时的数据给替换出去。那么具体是怎么个替换策略呢?这就考验奴才们对于主子心思的把控了。这时候有个聪明的奴才在总结了多次经验后,提出了LRU替换策略,中文名译为最近最少使用替换策略,很容易理解,就是最近最少使用的数据将会被新数据替换掉。
而包含和不包含的区别在这里就会有所体现。如果是包含策略,那么新数据直接覆盖旧数据即可,旧数据等于直接作废,除非这个数据最近在CPU中被改写过,需要返回到内存中进行保存,那么才需要将该缓存行刷回内存(那么如何确定该缓存行是否被改写过呢?可以用一个名为dirty的标志位注明)。而如果是不包含策略,那么一级缓存淘汰下来的数据就要放置到二级缓存,如果不巧二级缓存也满了,那么仍需淘汰一个缓存下来。当然,你也可以选择如果二级缓存或者三级缓存没空位,那么就直接把淘汰下来的数据扔回内存,但是这样命中率就会严重下降(等于整个缓存体系的容量和一级缓存是一样大的)。并且如果是二级缓存或者三级缓存中的数据要写入到一级缓存中,那么需要把该二级或者三级缓存的缓存行与一级缓存做一个交换,而不是覆盖。
那究竟是用Inclusive还是Exclusive呢?各大CPU厂商给出了答案,Exclusive成为目前主流使用的缓存策略。Intel前几年还在用Inclusive来着,最近这几年也转而使用了Exclusive,说明Exclusive的优势比我们想象的大。
审核编辑:刘清
-
HVM的缓存控制与内存管理2018-09-20 0
-
半导体材料那些事2019-07-29 0
-
关于内存可缓存性的疑问怎么解释2020-05-21 0
-
【原创】堆内存的那些事2021-07-12 0
-
关于GPS定位的那些事不看肯定后悔2021-09-26 0
-
深入了解威廉希尔官方网站 噪声的那些事2016-09-27 934
-
给大伙科普关于语音芯片运行内存那些事2021-05-27 1887
-
关于虚拟内核和物理内存的那些事2021-05-28 1811
-
一文读懂缓存和内存有何区别2021-11-13 33176
-
舵机控制那些事(附STM32代码!!!)2021-12-08 859
-
关于CPU缓存的作用2022-03-30 4516
-
Linux内存的那些事儿2022-09-08 759
-
CPU缓存那些事儿2023-09-10 695
-
有关于MLCC(多层陶瓷电容)替代Film Cap (薄膜电容)的那些事2023-12-04 2109
-
京准时钟科普:关于北斗卫星同步时钟的那些事?2024-10-29 291
全部0条评论

快来发表一下你的评论吧 !
