

如何应用Anomalib在数据集不平衡的情况下检测缺陷 ?
描述
质量控制和质量保证是任何企业保持卓越声誉、提升客户体验的关键环节。例如,在制造业中,通过检测生产线上的异常情况,企业可以确保只有最优质的产品能够出厂。而在医疗行业,通过医学成像及早发现异常有助于医生对患者进行准确诊断。
以上场景中的任何差错都会导致严重后果。正因如此,许多行业开始告别易受主观因素影响而出错的人工检查和维护,转而引入日新月异的计算机视觉和深度学习技术,实施自动化异常检测。
如要真正增强质量控制和质量保证,人工智能必须利用数据量丰富且平衡的数据集。虽然如今有大量良好的数据样本,但有时不足以帮助工业和医疗行业做出准确和有效的预测。此外,大规模制造和工业自动化的发展带来了产能的跃升,质检人员越来越难以处理数量庞大的产品。
克服数据集挑战
基于监督式学习的方法利用足够的注释异常样本,通常可用于实现令人满意的异常检测结果。但如果数据集是缺乏异常类别代表性样本的不平衡数据集,结果会怎样?当缺陷可以是任何类型的形状时,您如何定义异常的边界?
解决这些问题的一个方法是无监督异常检测,它几乎不需要标注。无监督异常检测在训练阶段完全依赖正常样本,可以通过与所学的正常数据分布进行比较来识别异常样本。
开源的端到端异常检测库 Anomalib 便是一种基于无监督异常检测算法的开源库,它提供了可根据特定用例和要求定制的先进异常检测算法。
Anomalib 在制造业中的应用
让我们看一个具有彩色立方体的生产线示例(图 1)。

图 1.使用教育机器人进行基于 Anomalib 的缺陷检测。
我们要检测出任何有缺陷的彩色立方体,并防止它们进入生产线。为此,需要安装一个摄像头来监测彩色立方体的状况,然后由监控器对机械臂进行操作(图 2)。

图 2.运行 Anomalib 模型推理的教育机器人。
对于这种场景下的异常检测,我们没有可用于在边缘训练模型的硬件加速器。我们也不能假设已经为边缘训练收集了数千幅图像、尤其是有缺陷的图像。此外,预计不会像真实的制造场景一样,存在大量缺陷已知的情况。
鉴于这些初始条件,我们的一个目标是在边缘实现更快的训练速度,并进行高精确和高效的异常检测。有一点需要记住,即如果有任何外部条件变化 - 如照明、摄像头或异常情况,我们将不得不重新训练模型。因此,进行不太费事的重新训练是有必要的。最后,为了确保模型在真实的制造用例中发挥作用,我们必须保证使用异常检测模型获得精确的推理结果。
借助内容广泛的 Anomalib 库,我们可以设计、实施和部署无监督异常检测模型,覆盖从数据收集到边缘应用在内的流程,从而满足我们的所有要求。
Anomalib 的工作原理
Anomalib 库提供了能够计算图像上异常情况的算法,以及通过训练、评估、测试、基准测试和超参数优化来运行这些算法的工具。模块已经提供了可用于自定义算法的算法设计和工具。
在图 3 中,我们展示了Anomalib 是由工具、组件以及模块这几部分组成的,其中,我们把部署作为工具和模块的一部分,想表明这部分也包含在该库的范围内。
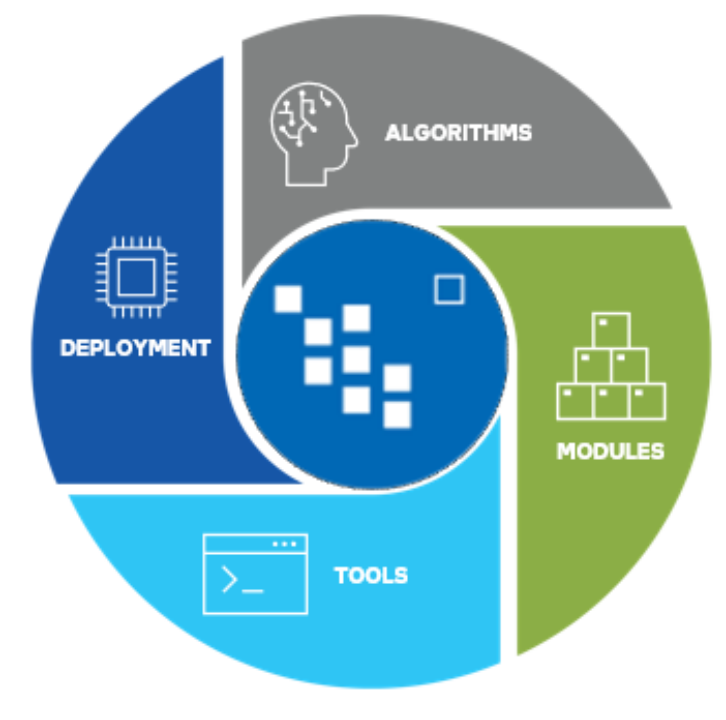
图 3.Anomalib 的工具、组件和模块。
图 4 详细展示了从训练到部署的工作流程概览图。我们已使用 PyTorch Lighting 进行训练和测试,并使用 ONNX 和 OpenVINO 进行优化;TensorFlow、PyTorch 和 OpenVINO 可用于部署。
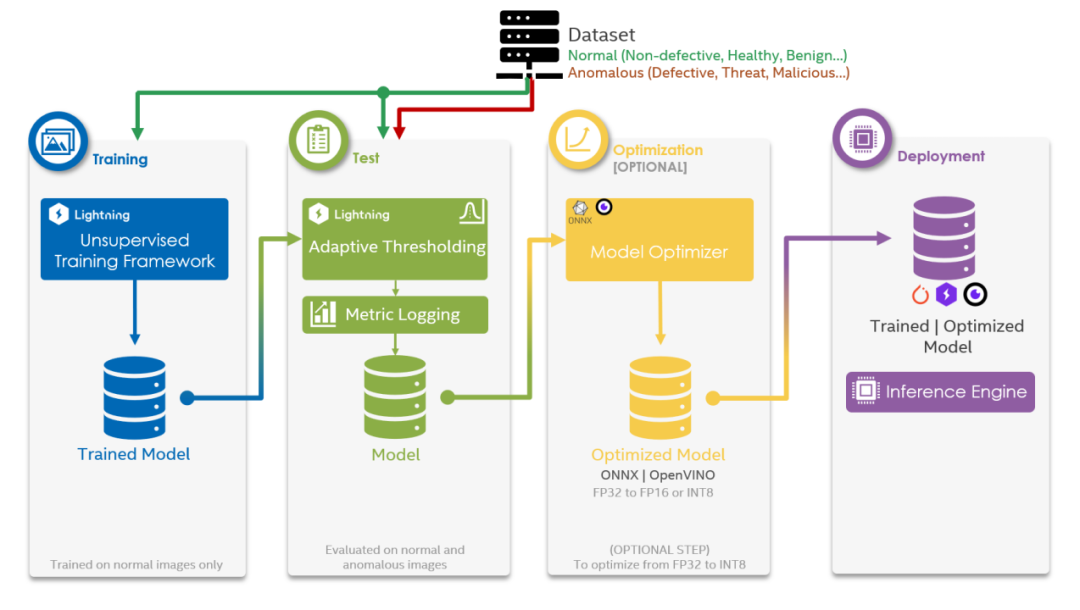
图4.从训练到部署的工作流程概览图。
审核编辑:刘清
-
如何应用Anomalib在数据集不平衡的情况下检测缺陷?2023-04-03 2538
-
三相不平衡对变压器及用电设备的影响2010-11-09 0
-
三相不平衡的原因、危害以及解决措施2017-04-22 0
-
三相不平衡治理装置的应用优势2019-02-18 0
-
怎么解决变频器电流不平衡的问题2021-01-19 0
-
不平衡数据集上的Relief特征选择算法_菅小艳2017-01-08 770
-
当机器学习中遇到类不平衡,该怎么办?2019-03-27 813
-
教你如何处理不平衡数据集2019-06-07 4841
-
如何理解矢量测量中“平衡”与“不平衡2020-03-29 2800
-
三相电流不平衡是什么原因引起的?三相电流不平衡的危害2023-08-31 6656
-
三相电压不平衡是什么原因造成的?三相不平衡会跳闸吗?2023-09-25 7305
-
I/Q不平衡的来源 IQ信道之间的不平衡会造成什么影响呢?2023-10-31 1146
-
三相电压不平衡对威廉希尔官方网站 的影响2023-12-11 2603
-
三相不平衡最佳解决办法 三相不平衡多少范围内是合理的2024-02-06 3203
-
三相不平衡调节装置 三相不平衡会造成什么后果2024-02-06 1872
全部0条评论

快来发表一下你的评论吧 !
