

In-context learning如何工作?斯坦福学者用贝叶斯方法解开其奥秘
描述
引言
去年底,OpenAI研发的ChatGPT一经面世,在引起了大家惊讶的同时,也纷纷引发大家的思考,到底ChatGPT是如何研发的?用到了什么技术?如何才能充分挖掘ChatGPT潜能?ChatGPT背后的核心技术,大语言模型毫无疑问是最重要的之一。同样由OpenAI研发的大模型GPT-3,其参数量达到的1750亿。如此大规模的模型,不仅研发成本让许多机构望而却步,其背后的运行原理也是让很多科研人员“一头雾水”。大量的工作在探究,语言模型是怎样获得如何惊人的“语言理解能力”的?其中,In-context learning就是一种在大规模语言模型中展现出来的特殊能力,通过给模型“展示”几个相关的例子,模型便可以“学会”这个任务要做的事情,并给出测试样例的答案。可是,模型是怎么获得这个特殊“技能”的呢?斯坦福大学的Sang Michael Xie等人认为,in-context learning可以看成是一个贝叶斯推理过程,其利用提示的四个组成部分(输入、输出、格式和输入输出映射)来获得隐含在语言模型中的潜在概念,而潜在概念是语言模型在训练过程中学到的关于某类任务的特定“知识”。相关工作发表在2022年的ICLR会议上,作者等人还写了一篇博客来进行详细介绍。下面跟着译者一起来了解in-context learning的奥秘吧!
博客正文
在这篇文章中,我们为GPT-3等大规模语言模型中的in-context learning提供了一个贝叶斯推理框架,并展示了我们框架的实验证据,突出了与传统监督学习的区别。这篇博文主要借鉴了来自论文An Explanation of In-context Learning as Implicit Bayesian Inference的in-context learning理论框架,以及来自Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? 的实验。
In-context learning是大规模语言模型中一种神秘的涌现行为,其中语言模型仅通过调节输入输出示例来完成任务,而无需优化任何参数。在这篇文章中,我们提供了一个贝叶斯推理框架,将in-context learning理解为“定位”语言模型从预训练数据中获取到的潜在“概念”。这表明提示的所有组成部分(输入、输出、格式和输入-输出映射)都可以提供用来推断潜在概念的信息。我们就此框架进行相关实验,在这些实验的结果中,当提供具有随机输出的训练示例时,in-context learning仍然有效。虽然随机的输出削弱了传统的监督学习算法,但它只是消除了贝叶斯推理的一种信息来源(输入-输出映射)。最后,我们提出了对于未来工作存在的差距和努力方向,并邀请社区与我们一起进一步了解in-context learning。
目录
一、In-context learning的奥秘
二、一种in-context learning框架
三、实验证据
四、扩展
五、总结
一、In-context learning的奥秘
大规模语言模型,例如GPT-3[1]在互联网规模的文本数据上进行训练,以预测给定前文文本的下一个标记。这个简单的目标与大规模数据集和模型相结合,产生了一个非常灵活的语言模型,它可以“读取”任何文本输入,并以此为条件“书写”可能出现在输入之后的文本。虽然训练过程既简单又通用,但GPT-3论文发现“大规模”会导致特别有趣的、意想不到的行为,称为in-context learning。什么是in-context learning?In-context learning最初是在 GPT-3 论文中开始普及的,是一种仅给出几个示例就可以让语言模型学习到相关任务的方法。在in-context learning里,我们给语言模型一个“提示(prompt)”,该提示是一个由输入输出对组成的列表,这些输入输出对用来描述一个任务。在提示的末尾,有一个测试输入,并让语言模型仅通过以提示为条件来预测下一个标记。例如,要正确回答下图所示的两个提示,模型需要读取训练示例以弄清楚输入分布(财经或普通新闻)、输出分布(正向情感/负向情感或某个主题)、输入-输出映射(情感分类或主题分类)和格式。

In-context learning能做什么?在许多NLP基准测试中,in-context learning与使用更多标记数据训练的模型相比具有相当的性能,并且在LAMBADA(常识句子完成)和 TriviaQA(问答)上是最出色的。更令人兴奋的是,in-context learning使人们能够在短短几个小时内启动一系列应用程序,包括根据自然语言描述编写代码、帮助设计应用程序模型以及概括电子表格功能等。
In-context learning允许用户为新用例快速构建模型,而无需为每个任务微调和存储新参数。它通常只需要很少的训练示例就可以使模型正常工作,而且即使对于非专家来说,也可以通过直观的自然语言来进行交互。
为什么in-context learning这么神奇?In-context learning不同于传统的机器学习,因为它没有对任何参数进行优化。然而,这并不是独一无二的——元学习(meta-learning)方法已经训练出了从示例中学习的模型。神奇之处在于语言模型没有进行过从示例中学习的训练,它在预训练中做的事是预测下一个标记。正因为如此,语言模型和in-context learning似乎并不一致。
这看起来很神奇,那In-context learning是怎么起作用的呢?
二、一种In-context learning框架
我们如何才能更好地理解in-context learning?首先要注意的是,像GPT-3这样的大规模语言模型已经在具有广泛主题和格式的大量文本上进行了训练,这些文本包括维基百科页面、学术论文、Reddit帖子以及莎士比亚的作品。我们假设在这些文本上进行训练使得语言模型可以对多种不同的概念进行建模。
Xie等人[2]提出了一个框架,即语言模型使用in-context learning提示来“定位”训练中学习到的概念,从而完成in-context learning任务。如下图所示,在我们的框架中,语言模型使用训练示例在内部确定任务是情感分析(左)或主题分类(右),并将相同的映射应用于测试输入。
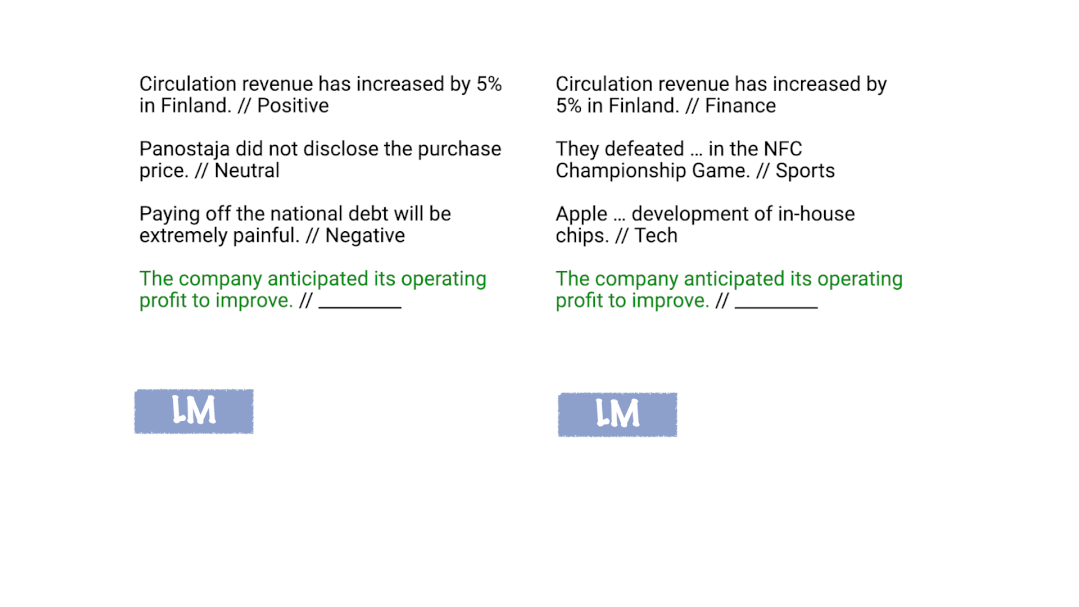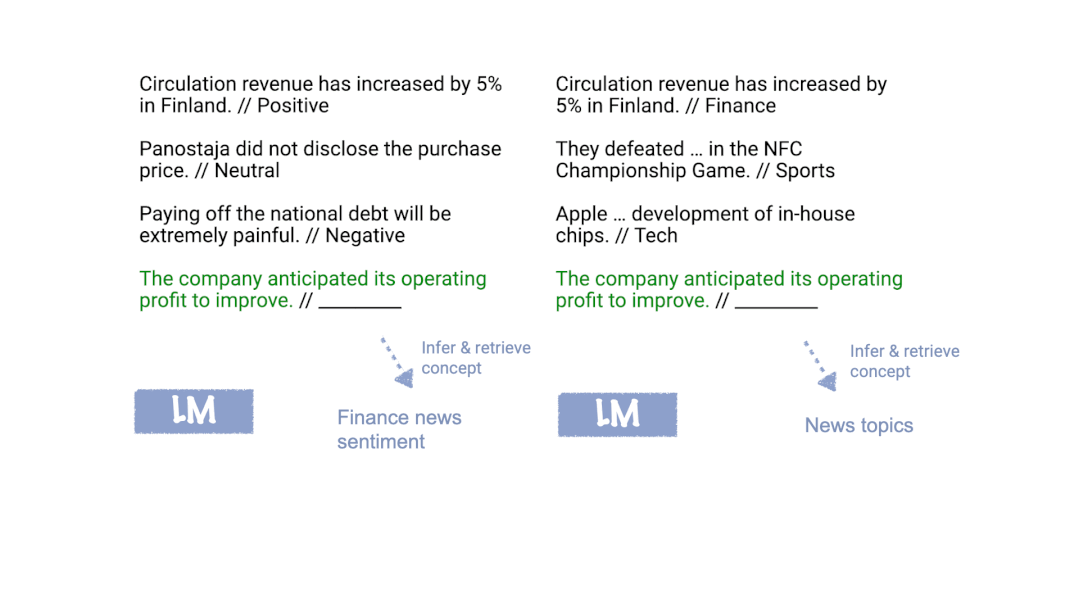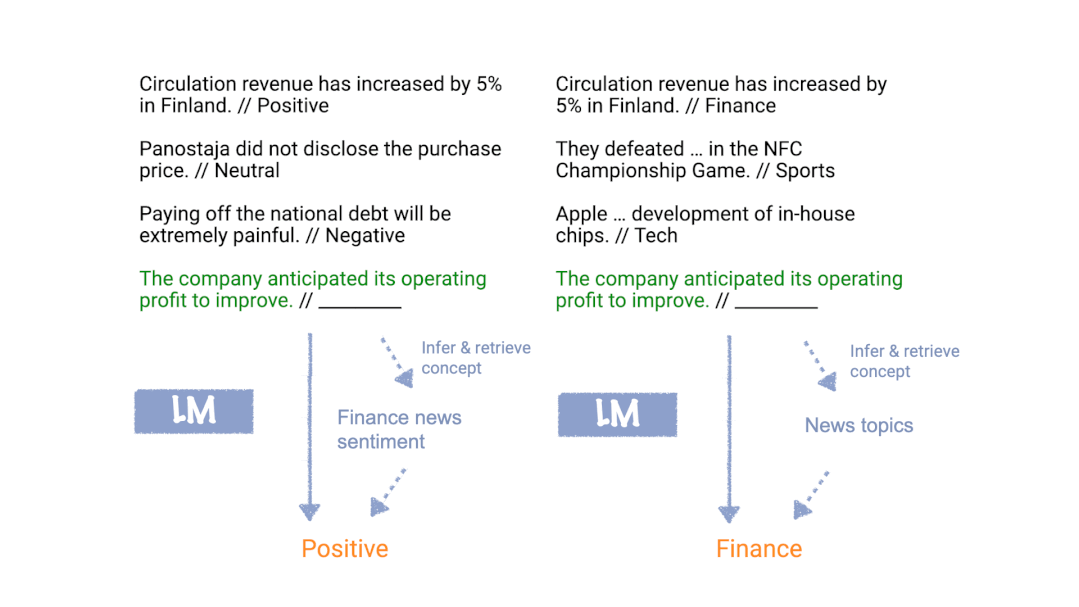
什么是“概念”?我们可以将概念视为包含各种文档级统计信息的潜在变量。例如,“新闻主题”的概念描述了词汇的分布(新闻及新闻主题)、格式(新闻文章的写作方式)、新闻与新闻主题之间的关系以及词汇之间的其他语义和句法关系。通常,概念可能是许多潜在变量的组合,这些潜在变量指定了文档语义和语法的不同方面,但在这里我们通过将它们全部看成一个概念变量来简化。
语言模型如何在预训练期间学会进行贝叶斯推理?
我们证明,在具有潜在概念结构的伪数据上训练(预测下一个标记)的语言模型可以学习进行in-context learning。我们假设在真实的预训练数据中会发生类似的效果,因为文本文档天然具有长期连贯性:同一文档中的句子/段落/表格行倾向于共享底层语义信息(例如,主题)和格式(例如,问题和答案之间交替的问答页面)。在我们的框架中,文档级潜在概念创造了长期连贯性,并且在预训练期间对这种连贯性进行建模来推断潜在概念:
1、预训练:为了在预训练期间预测下一个标记,语言模型必须使用来自先前句子的证据推断(“定位”)文档的潜在概念。
2、In-context learning:如果语言模型使用提示中的in-context示例推断提示概念(提示中的示例所共享的潜在概念),则发生in-context learning!
In-context learning的贝叶斯推理观点
在我们讨论贝叶斯推理观点之前,让我们设置好in-context learning的设定。
预训练分布(p):我们对预训练文档结构的主要假设是,关于文档的生成,首先通过对潜在概念进行采样,然后以潜在概念为条件来生成文档。我们假设预训练数据足够多以及语言模型足够大,使得语言模型完全符合预训练分布。正因为如此,我们使用p表示语言模型下的预训练分布和概率。
提示分布:In-context learning提示是一系列独立同分布的训练示例加上一个测试输入。提示中的每个示例都可以认为是以相同提示概念为条件的序列,它描述了要学习的任务。
去“定位”学习到的概念的过程,可以看作是提示中每个示例共享的提示概念的贝叶斯推理。如果模型能够推断出提示概念,那么它就可以用来对测试样例做出正确的预测。在数学上,提示为模型(p)提供了证据来锐化概念的后验分布p(concept|prompt)。如果p(concept|prompt)集中在提示概念上,模型则有效地从提示中“学习”到了概念。
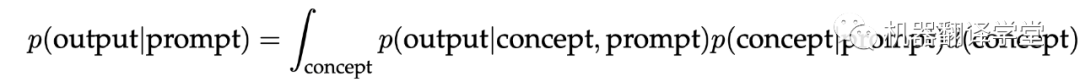
理想情况下,p(concept|prompt)会集中在有更多示例的提示概念,就可以通过边缘化来“选择”对应的提示概念。
提示为贝叶斯推理提供了带有噪声的信号
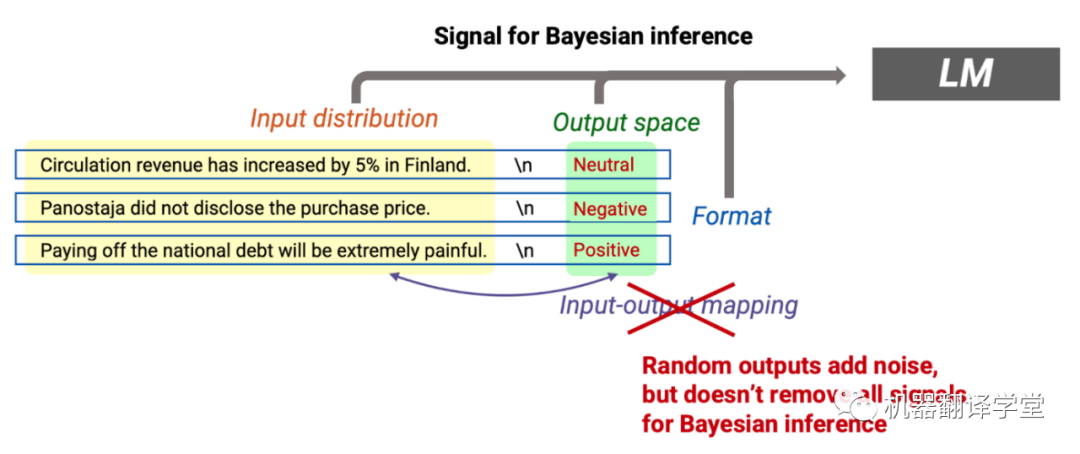
在解释中不太符合逻辑的地方是,语言模型从in-context示例中推断提示概念,不过提示是从提示分布中采样的,这可能与语言模型训练的预训练分布非常不同。提示将独立的训练示例连接在一起,因此不同示例之间的转换在语言模型以及预训练分布下的概率非常低,并且可能在推理过程中引入噪声。例如,连接关于不同新闻主题的独立句子可能会产生不常见的文本,因为没有一个句子具有足够的in-context。有趣的是,正如在GPT-3中所发现的那样,尽管预训练和提示分布之间存在差异,语言模型仍然可以进行贝叶斯推理。我们证明,通过贝叶斯推理进行的in-context learning可以用一个简化的理论设置,在预训练数据的潜在概念结构中出现。我们使用它来生成一个数据集,该数据集使得Transformer和LSTM能够发生in-context learning。

训练示例提供信号:我们可以认为训练示例为贝叶斯推理提供信号。尤其是训练示例中的转换(上图中的绿色箭头)允许语言模型推断它们共享的潜在概念。在提示中,来自输入分布(新闻句子之间的转换)、输出分布(主题词)、格式(新闻句子的句法)和输入-输出映射(新闻和主题之间的关系)的转换都为贝叶斯推理提供信号。
训练示例之间的转换可能是低概率的(噪声):因为训练示例是独立同分布的,将它们连接在一起通常会在示例之间产生不流畅的低概率转换。例如,在关于芬兰流通收入的句子之后看到关于 NFC 冠军赛(美式橄榄球比赛)的句子可能会令人惊讶(见上图)。这些转换会在推理过程中产生噪音,原因在于预训练和提示分布之间的差异。
In-context learning对某些噪声具有鲁棒性:我们证明,如果信号大于噪声,则语言模型可以成功进行in-context learning。我们将信号描述为其他概念与以提示为条件的提示概念之间的KL散度,并将噪声描述为来自示例之间转换的误差项。直觉上,如果提示允许模型真正轻松地将提示概念与其他概念区分开来,那么就会有很强的信号。这也表明,在信号足够强的情况下,其他形式的噪声,例如删除一种信息源(如删除输入输出映射)可能是没有问题的,特别是当提示的格式没有改变并且输入输出映射信息在预训练数据中。这不同于传统的监督学习,如果删除输入-输出映射信息(如通过随机化标签),传统的监督学习将会失效。我们将在下一节中直接研究这种区别。
用于in-context learning的小型测试平台(GINC数据集):为了支持该理论,我们构建了一个预训练数据集和具有潜在概念结构的in-context learning测试平台,取名为GINC。我们发现在GINC上进行预训练会使Transformer和LSTM出现in-context learning,这表明来自预训练数据中的结构有非常重要的作用。消融实验显示,潜在的概念结构(导致长期连贯性)对于GINC中in-context learning的出现至关重要[2]。
三、实验证据
接下来,我们希望通过一组实验为上述框架提供实验证据。
提示中的输入输出对很重要
提示中不需要使用真实输出也能获得良好的in-context learning性能。
在Min等人的论文[3]中,我们比较了三种不同的方法:
No-examples:语言模型仅在测试输入上计算条件概率,没有示例。这是典型的零样本推理,在GPT-2/GPT-3中已经实现。
具有真实输出的示例:语言模型是基于一些in-context示例和测试输入共同去计算的。这是一种典型的in-context learning方法,默认情况下,提示中的所有输出都是真实的。
具有随机输出的示例:语言模型也是基于一些in-context示例和测试输入去共同计算的,不过,提示中的每个输出都是从输出集中随机抽样的(分类任务中的标签;多项选择中的一组答案选项)。


带有真实输出的提示(上图)和带有随机输出的提示(下图)
值得注意的是,“带有随机输出的示例”这种方法以前从未有人尝试过。如果标记数据的输出是随机的,那么典型的监督学习将根本不起作用,因为任务不再有意义。
我们试验了12个模型,参数大小范围从 774M 到 175B,包括最大的GPT-3(Davinci)。模型在16个分类数据集和10个多选数据集上进行评估。
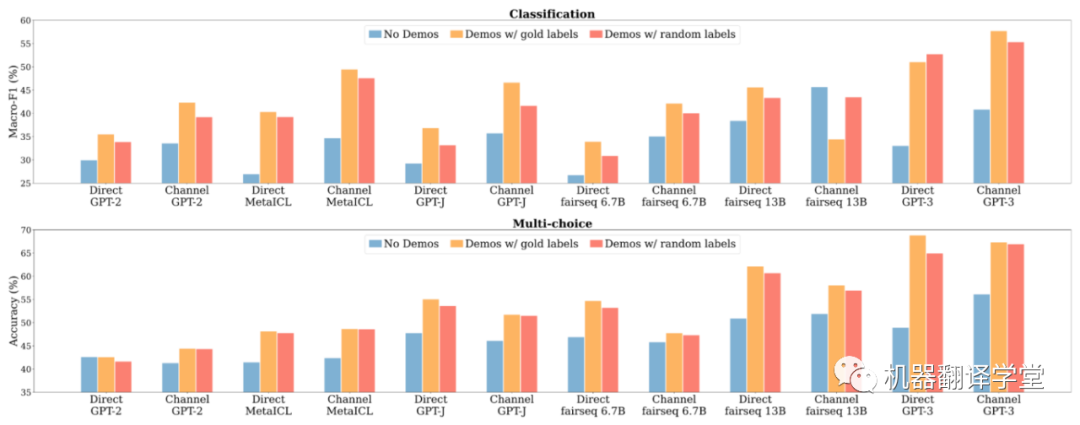
无示例(蓝色)、具有真实输出的示例(黄色)和具有随机输出的示例(随机)之间的比较;用随机输出替换真值输出对性能的影响比之前想象的要小得多,而且仍然比没有例子要好得多
当用输出集合的随机输出来替换每个输出时,in-context learning性能不会下降太多。
首先,正如预期的那样,使用带有真实输出的示例明显优于无示例。然后,用随机输出替换真实输出几乎不会使性能下降。这意味着,与典型的监督学习不同,真实输出并不是获得良好的in-context learning性能所必须需要的,这有违我们的直觉。
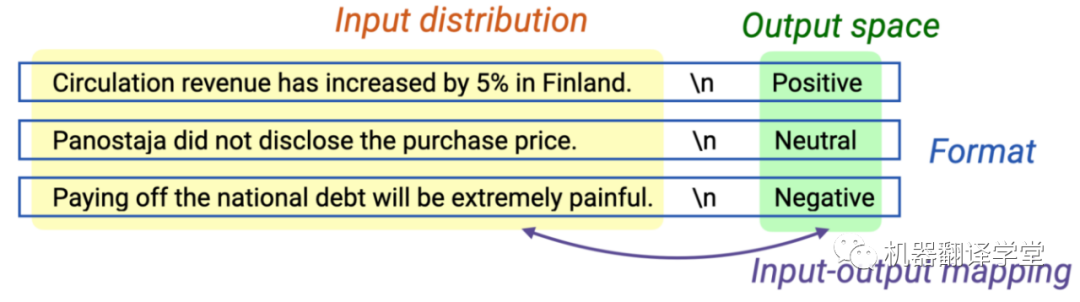
in-context示例的四个不同方面:输入输出映射(Input-output mapping)、输入分布(Input distribution)、输出空间(Output space)和格式(Format)
如果正确的输入输出映射具有边际效应,提示的哪些方面对于in-context learning最重要呢?
一个可能的方面是输入分布,即示例中输入的基础分布(下图中的红色文本)。为了量化其影响,我们设计了一种演示变量,其中每个in-context示例都包含一个从外部语料库中随机抽取的输入句子(不是来自训练数据的输入)。然后,我们将其性能与带有随机标签的演示进行比较。直觉上,这两个版本的演示都是不正确的输入标签对应关系,区别在于是否有正确的输入分布。
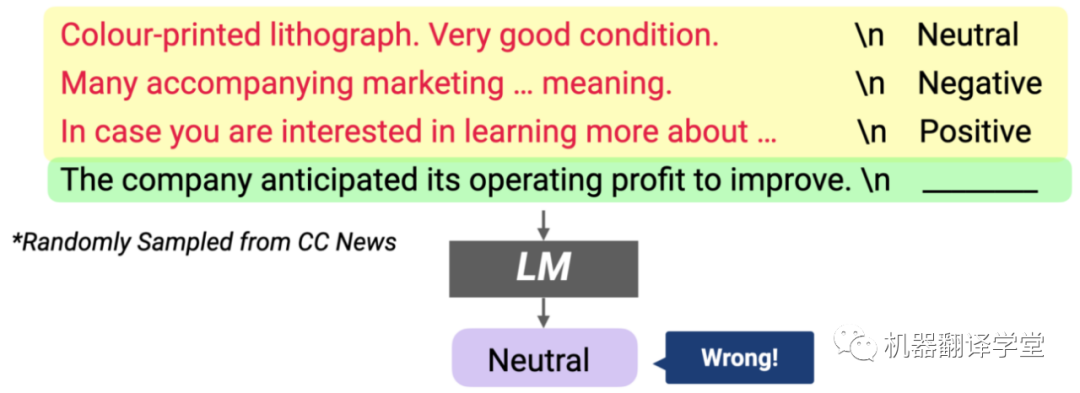
输入分布很重要:当提示中的输入被外部语料库(CC新闻语料库)的随机输入替换时,模型性能会显著下降
结果表明,总体而言,以随机句子作为输入的模型性能显著降低(绝对值降低高达 16%)。这表明对正确的输入分布进行调节很重要。

输出空间很重要:当示例中的输出被随机的英文一元组替换时,模型性能会显著下降 可能影响in-context learning的另一个方面是输出空间:任务中的输出集(类别或答案选项)。为了量化其影响,我们设计了一种演示变量,由in-context示例组成,这些示例具有随机配对的随机英语一元组,这些一元组与任务的原始标签(例如,“wave”)无关。结果表明,使用此演示时性能显著下降(绝对值高达16%)。这表明对正确的输出空间进行调节很重要。即使对于多项选择任务也是如此,可能是因为它仍然具有模型使用的特定选择分布(例如,OpenBookQA数据集中的“Bolts(螺栓)”和“Screws(螺丝)”等对象)。
与贝叶斯推理框架的联系
语言模型不依赖提示中的输入-输出对应这一事实意味着语言模型在预训练期间可能已经接触到任务的输入-输出对应中的某些概念,而in-context learning在它们的基础上发生作用。相反,提示的其它所有组成部分(输入分布、输出空间和格式)都在提供信号,使模型能够更好地推断(“定位”)在预训练期间学习到的概念。由于在提示中将随机序列连接在一起,随机输入输出映射仍然会增加“噪音”。尽管如此,基于我们的框架,只要仍然有足够的信号(例如正确的输入分布、输出空间和格式),模型仍然会进行贝叶斯推理。当然,拥有正确的输入输出映射仍然可以通过提供更多依据和减少噪音来发挥作用,尤其是当输入输出映射并非经常出现在预训练数据中时。
在预训练期间,in-context learning 的性能与术语频率高度相关
Razeghi等人[4]在各种数字任务上评估GPT-J,发现in-context learning性能与每个示例中的术语(数字和单位)在 GPT-J的预训练数据(The PILE)中出现的次数高度相关。
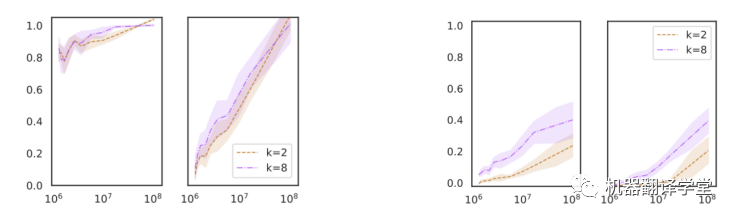
术语频率(x轴)和in-context learning性能(y轴)之间的相关性;从左到右:加法、乘法、提示中无任务指示的加法和提示中无任务指示的乘法;来自 Razeghi等人的数据
这在不同类型的数字任务(加法、乘法和单位转换)和不同的k值(提示中标记示例的数量)中结论是一致的。一个有趣的现象是,当输入没有明确说明任务时也是如此——例如,不使用“问:3 乘以 4 是多少?答:12”,而是用“问:3#4是多少?答:12”。
与贝叶斯推理框架的联系
我们将这项工作视为另一个证据,表明in-context learning主要是定位在预训练期间学习的潜在概念。特别是,如果特定实例中的术语在预训练数据中多次出现,则模型可能会更好地了解输入分布。根据贝叶斯推理,这将为定位潜在概念以执行下游任务提供更好的信号。而Razeghi等人特别关注模型对输入分布了解程度的一个方面——特定实例的词频——可能存在更广泛的变化集,例如输入-输出相关性的频率、格式(或文本模式)等。
四、扩展
了解模型在“没见过”的任务上的表现
我们的框架表明该模型正在“检索”它在预训练期间学到的概念。然而,Rong[5]在博文中表明,该模型在将运动映射到动物、将蔬菜映射到运动等(下图)没见过的任务上表现几乎完美。此外,输入输出映射在这种情况下仍然很重要,因为模型从示例中学习了不自然的映射。根据经验,一种可能性是in-context learning行为可能会在构造的任务中发生变化(而不是我们实验关注的真实NLP基准测试)——这需要进一步探索。
尽管如此,如果我们将一个概念视为许多潜在变量的组合,贝叶斯推理仍然可以解释某些形式的外推。例如,考虑一个表示语法的潜在变量和另一个表示语义的变量。贝叶斯推理可以组合推广到新的语义-句法对,即使模型在预训练期间没有看到所有句对。排列、交换和复制等一般操作在预训练期间很有用,并且可以在组合时帮助外推(例如,运动到动物案例中的标签排列)。需要做更多的工作来模拟in-context learning如何处理没见过的任务。
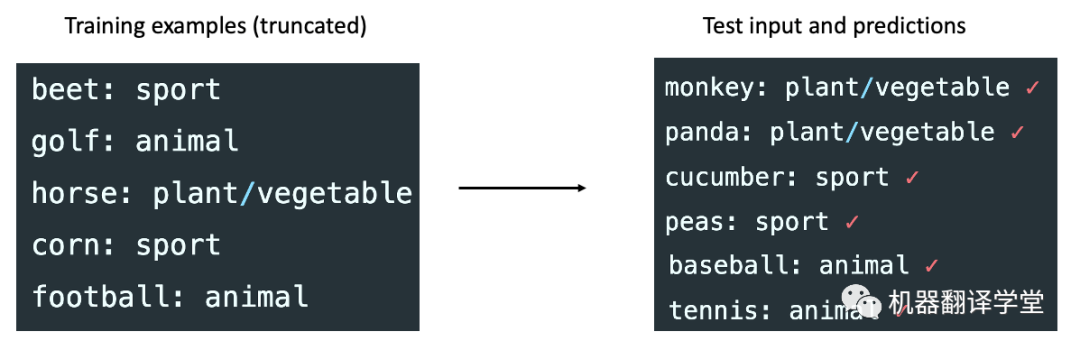
GPT-3可以成功学习的具有不寻常语义的示例合成任务
与学习阅读任务描述的联系
可以在提示中使用自然语言的任务描述(或说明)来执行下游任务。例如,我们可以在前面加上“Write a summary about the given article”来描述总结或“Answer a following question about the Wikipedia article”来描述问答。在大规模、高质量指令数据上进一步调整的语言模型被证明可以很好地执行没见过的任务[6][7]。根据我们的框架,我们可以通过提供明确的潜在提示概念,将“指定任务描述”理解为改进贝叶斯推理。
了解用于in-context learning的预训练数据
虽然我们提出in-context learning来自预训练数据中的长期连贯结构(由于潜在的概念结构),但需要做更多的工作来准确查明预训练数据的哪些元素对in-context learning有最大贡献。是否有一个关键的数据子集可以从中产生in-context learning,或者它是否是多种类型数据之间的复杂交互?最近的工作[8][9]给出了一些关于引发in-context learning行为所需的预训练数据类型的提示。更好地理解in-context learning有助于构建更有效的大规模预训练数据集。
从模型架构和训练中捕捉效果
我们的框架仅描述了预训练数据对in-context learning的影响,但其他方面也会产生影响。模型规模就是其中之一——许多论文都展示了大规模的好处[10][11][12]。结构(例如,仅解码器与编码器-解码器)和训练目标(例如,因果语言模型与掩码语言模型)是有可能的其它因素[13]。未来的工作可能会进一步研究in-context learning中的模型行为如何受模型规模、结构和训练目标的选择的影响。
五、总结
在这篇博文中,我们提供了一个框架,其中语言模型通过使用提示去“定位”它在预训练期间学习到的相关概念来进行in-context learning,进而完成相关任务。从理论上讲,我们可以将其视为一个潜在概念以提示为条件的贝叶斯推理,这种能力来自预训练数据中的结构(长期连贯性)。我们在一些NLP基准测试上进行实验,表明当提示中的输出用随机输出来进行替换时,in-context learning仍然有效。虽然使用随机输出会增加噪声,并破坏了输入-输出映射信息,但其他部分(输入分布、输出分布、格式)仍然为贝叶斯推理提供依据。最后,我们详细说明了我们框架的局限性和可能的扩展,例如解释外推到看不见的任务,并结合模型架构和优化的影响。我们呼吁未来在理解和改进in-context learning方面开展更多工作。
审核编辑 :李倩
全部0条评论

快来发表一下你的评论吧 !
