

首个中文医学知识LLM:真正的赛华佗—华驼(HuaTuo)
描述
先划重点:中文医学知识,不是「中医」。
自从 Meta(原 Facebook)的 LLaMA 大语言模型发布以来,相信大家看到了许多以“驼类动物”命名的 LLM。比如斯坦福用了 Alpaca,伯克利用了 Vicuna,Joseph Cheung 等开发者团队用了 Guanaco。

据说南美洲的无峰驼类动物一共就是上图列出的 4 种 —— 已经被各家的大模型命名使用。
不得不承认这些以“驼类动物”命名的 LLM 都很厉害,但如果,我是说如果,我拿出下面这个 LLM,阁下又当如何应对?

没错,正是「华驼」。
见名知意,华驼肯定跟医学有关——这是一个基于中文医学知识的LLaMA 微调模型。
说到这,这个 LLM 的命名很难不让人拍案叫绝,将神医华佗与基于“羊驼”的大语言模型巧妙地结合在一起。
此项目开源了经过中文医学指令精调 / 指令微调 (Instruct-tuning) 的 LLaMA-7B 模型。
通过医学知识图谱和 GPT 3.5 API 构建了中文医学指令数据集,并在此基础上对 LLaMA 进行了指令微调,提高了 LLaMA 在医疗领域的问答效果。
据介绍,医学知识库围绕疾病、药物、检查指标等构建,字段包括并发症,高危因素,组织学检查,临床症状,药物治疗,辅助治疗等。知识库示例如下:
{“中心词”: “偏头痛”, “相关疾病”: [“妊娠合并偏头痛”, “恶寒发热”], “相关症状”: [“皮肤变硬”, “头部及眼后部疼痛并能听到连续不断的隆隆声”, “晨起头痛加重”], “所属科室”: [“中西医结合科”, “内科”], “发病部位”: [“头部”]}
然后利用 GPT3.5 接口围绕医学知识库构建问答数据,并设置了多种 Prompt 形式来充分利用知识。指令微调的训练集数据示例如下:
“问题:一位年轻男性长期使用可卡因,突然出现胸痛、呕吐、出汗等症状,经检查发现心电图反映心肌急性损伤,请问可能患的是什么疾病?治疗方式是什么?” 回答: 可能患的是心肌梗塞,需要进行维拉帕米、依普利酮、硝酸甘油、ß阻滞剂、吗啡等药物治疗,并进行溶栓治疗、低分子量肝素、钙通道阻滞剂等辅助治疗。此外需要及时停用可卡因等药物,以防止病情加重。“
该项目提供模型的训练数据集共计八千余条,需要注意的是,虽然训练集的构建融入了知识,但是仍存在错误和不完善的地方。
基于相同的数据,项目团队还训练了医疗版本的 ChatGLM 模型:ChatGLM-6B-Med。
这些模型在医疗领域的问答效果得到了显著提升,下面是不同模型的效果对比:
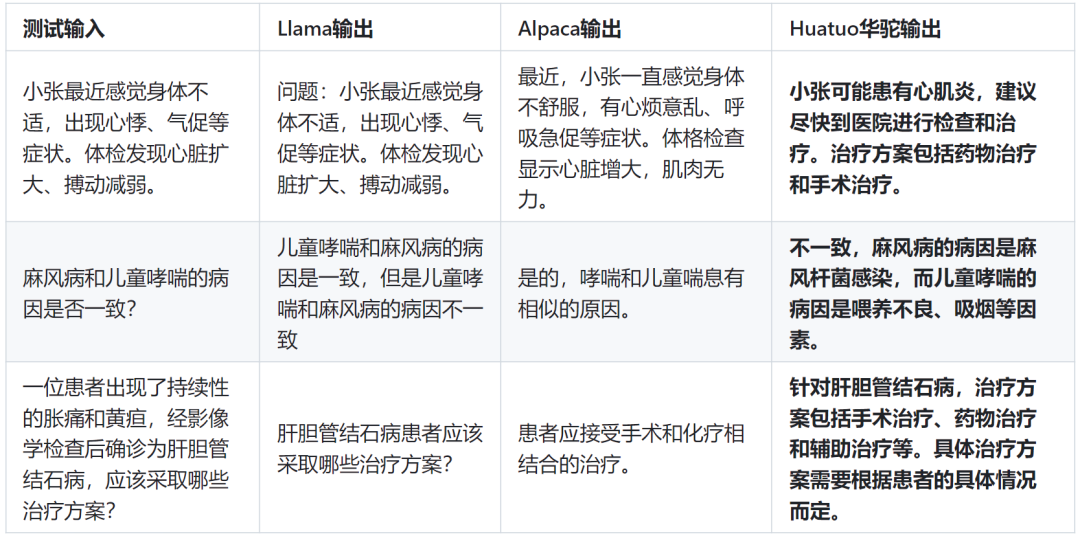
由此可见,指令微调在医疗领域具有很大的应用潜力。
同时,该项目还尝试将医学文献的【结论】融入多轮对话,在此基础上对 LLaMA 进行指令微调,以进一步提高模型的实用性。
目前,项目团队只开放针对”肝癌“单个疾病训练的模型参数。未来计划发布融入文献结论的医学对话数据集,并且会针对“肝胆胰”相关 16 种疾病训练模型。这将有助于广泛应用于更多疾病的诊断和治疗建议。
下面是训练样本的示例:

华驼项目团队称下一个发布的新模型会被命名为扁鹊 (PienChueh)。
审核编辑 :李倩
-
如何训练自己的LLM模型2024-11-08 531
-
中文编码的基础知识2019-07-11 0
-
中国首个中文离线语音模块标准即将诞生2019-12-18 0
-
华秋DFM 安装后是英文版,怎么切换为中文?2020-07-13 0
-
Smarter跑步鞋:生物医学与健身设备的完美结合2013-01-25 1092
-
20届电脑知识赛题库(已分类)2016-01-06 714
-
人类发现首个中等质量黑洞2020-11-08 1499
-
网络华佗 | 软SDN运维不用怕,iMaster NCE-FabricInsight网络华佗帮您忙2023-06-12 603
-
基于医学知识增强的基础模型预训练方法2023-07-07 813
-
最新综述!当大型语言模型(LLM)遇上知识图谱:两大技术优势互补2023-07-10 2023
-
Stability AI发布首个用于编程的生成式LLM AI产品—StableCode2023-08-24 877
-
网络华佗 | 大明星出行记2023-10-24 387
-
网络华佗 | iMaster NCE-FabricInsight带你玩转网络“迷宫”2023-11-29 564
-
首个中红外波长超级反射镜制成,反射率为99.99%2023-12-11 693
-
MR混合现实情景实训教学在临床医学课堂中的应用2024-01-17 303
全部0条评论

快来发表一下你的评论吧 !
