

从分层架构到微服务架构介绍(三)
电子说
描述
前言
管道架构 (Pipeline Architecture),通常也被称为 管道-过滤器架构 (Pipes and Filter Architecture),是最常用的架构模式之一。大部分软件工程师都是通过Unix终端初次接触到该架构模式,Unix终端的Shell语言,对管道-过滤器有着原生的支持。
比如,现在需要实现这样的一个功能: 读取一个文本文件的内容,找到使用频率最高的5个单词,并按照使用频率的大小顺序打印出单词及其使用频率 。
那么,使用Shell可以这样来实现:
cat content.txt | # step1: 读取文件内容
tr -cs A-Za-z '\\n' | # step2: 将单词按行输出
tr A-Z a-z | # step3: 将所有单词转换为
sort | # step4: 对单词进行排序
uniq -c | # step5: 计算出单词的频率
sort -rn | # step6: 按照频率对单词进行排序
head -n 5 # step7: 获取排序前5的单词
# 输出结果示例:
4 to
4 and
3 the
3 networks
3 linux
这段Shell代码就是一个简单的管道架构实现,其中|表示管道pipe,每一个step就相当于一个过滤器filter。每个filter都将上一个filter的输出结果作为输入数据,对数据进行处理后再将结果输出到管道中。
除了Shell语言之外,MapReduce也是基于管道架构搭建,其中的map和reduce可以看成是过滤器,只是它们通信的管道为HDFS。
Shell语言和MapReduce编程模型都可以看成是管道架构的low-level实现,当然,它也能应用于higher-level的系统应用上,下面我们来介绍管道架构模式的架构视图。
架构视图
管道架构由管道pipe和过滤器filter组成:
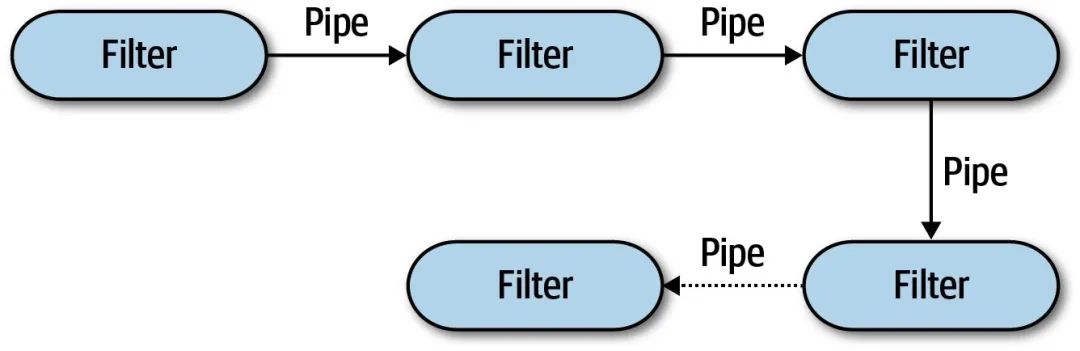
管道架构架构视图
pipe作为filter之间的数据传输通道,通常都是单向、点对点通信的 ,这样的设计不仅实现简单,在性能上也能取得较好的效果。另外,pipe上传输的数据并没有统一的格式,每个系统都可以根据自身的特点选择合适的数据结构。
filter作为数据处理的组件,通常是无状态的 。每个filter都应当只完成一项工作,满足 单一职责原则 ,复杂的工作流应该由多个filter组合而成。一般地,我们将filter分成以下几种类型:
- Producer : 有时候也称为 Source ,是整个pipeline的start point,负责从数据源中接收数据,并将数据输出到pipe中。
- Transformer : 从pipe中接收输入数据,然后对部分或全部数据进按照一定的规则行转换,并将结果输出到pipe中。在函数式编程里,该步骤通常被称为
map。 - Tester : 从pipe中接收数据,然后对数据进行一些条件判断,并根据判断结果选择是否将数据传递到下游的pipe中。需要注意的是, tester并未对数据进行任何修改 。
- Consumer : 是整个pipeline的end point,通常将从pipe中读取到的数据持久化到数据库或呈现到用户界面上。
一个系统中可以有多个producer和consumer,比如我们可以同时通过Kafka和REST接口接收输入数据,经过系统的处理后,将结果数据存储到MySQL中,同时也传递一份到数据仓库上用作数据分析。总之, 管道架构模式有着很大的灵活性 。
应用例子
管道架构模式被广泛应用在很多应用上,下面我们以一个ETL系统作为例子来理解该模式的运作方式。
ETL (Extract, Transform, Load)是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
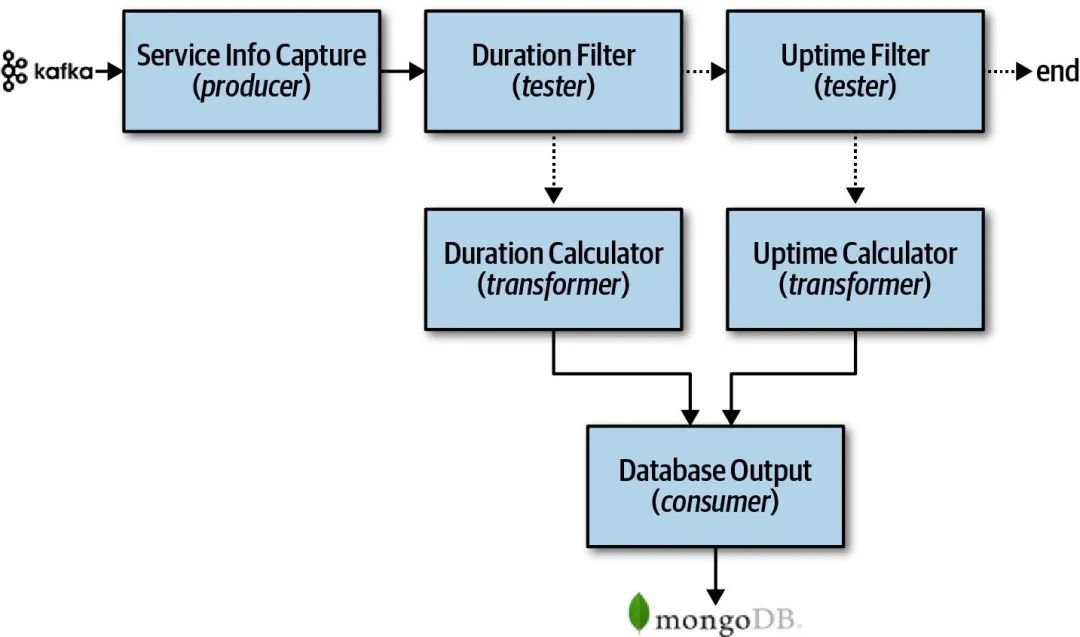
管道架构模式应用例子
业务应用系统在运行过程中会产生各种各样的数据输出到kafka中,ETL系统会消费相关数据,并在经过处理后将结果存储到数据库上。在上图的ETL系统里,各个过滤器的作用如下所述:
- Service Info Capture : 订阅kafka的topic,从中消费业务系统产生的数据,然后通过pipe传送到下游filter。
- Duration Filter : 判断数据是否与计算 服务请求的处理时长 (duration)指标相关,是则将数据传递给Duration Calculator,否则传递给Uptime Filter。
- Duration Calculator : 计算服务请求的处理时长,并将计算结果传递给Database Output。
- Uptime Filter : 判断数据是否与计算 系统正常运行时长 (uptime)指标相关,是则将数据传递给Uptime Calculator,否则认为数据并非本ETL系统所关系,结束数据流程。
- Uptime Calculator : 计算系统正常运行时长,并将结果传递给Database Output。
- Database Output : 将数据持久化到MongoDB中。
上述的ETL系统由1个producer filter,2个tester filter,2个transform filter和1个consumer filter组成,主要的数据处理逻辑是计算系统的遥测指标。系统在架构上具有很高的可扩展性,比如后续想要新增一个指标计算,我们可以在Uptime Filter之后加上新的tester和transform,系统原有的指标计算无需改动;又比如系统后续打算用HBase替换MongoDB,那么我们可以新开发一个HBase Output替换掉原有的Database Output,系统的其他流程同样无需改动。
架构评分
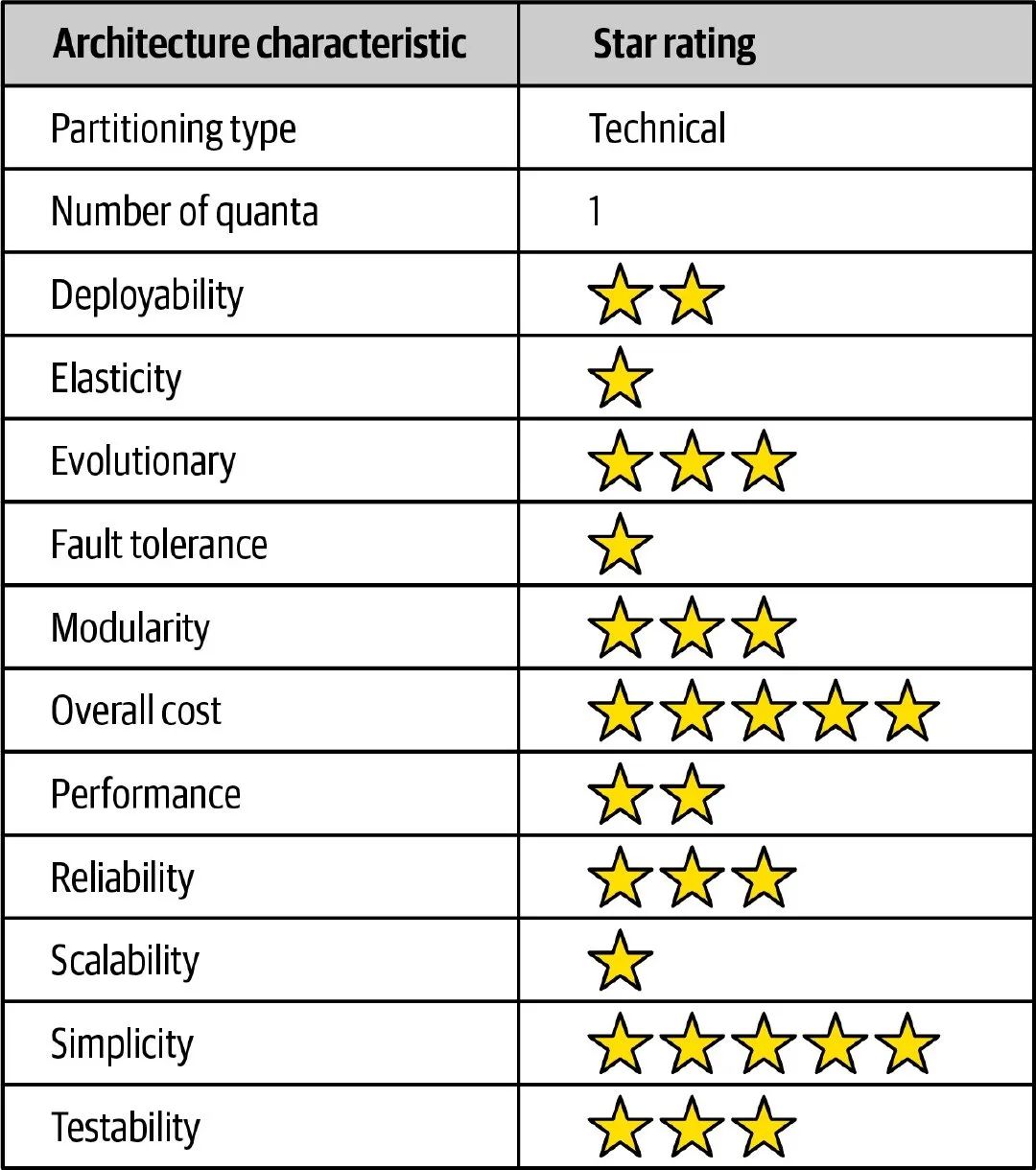
管道架构模式的架构评分
管道架构模式通常被实现为单体架构,同分层架构模式一样,因为单体架构本身的劣势,其在Elasticity、Fault tolerance、Scalability方面都具有很低的评分。Simplicity是管道架构模式的主要优点之一,filter和pipe实现简单,可以快速构建起一个基于管道架构风格的系统,因此也具有很高的Overall cost评分。
另外,相比于分层架构模式,管道架构模式在Modularity、Evolutionary和Testability上都有着较高的评分, 这得益于filter之间的松耦合,我们可以很容易扩展系统的filter,以及对单个filter进行测试 。
总结
本文主要介绍了管道架构模式,它由管道pipe和过滤器filter组成。根据具体的数据处理逻辑,它将filter划分为producer、transformer、tester和consumer四种类型,是一种典型的technical partition软件架构风格。管道架构模式因为其可扩展性很高的特点而被广泛应用,其中不乏有Shell语言这种low-level的实现,也有ETL系统这种high-level的实现。
虽说该模式通常被实现为单体架构,但也有像MapReduce这种基于分布式系统的编程模式实现,总之,如果你需要为一个数据处理型的系统选型,那么可以认真地考虑是否采用管道架构模式。
每种架构模式都有其合适的应用场景,只有熟悉常用的几种架构模式,才能设计出更好的软件系统。下一篇文章,我们将继续介绍 微内核架构 。
-
微服务架构和CQRS架构基本概念介绍2019-05-22 0
-
微服务优势_微服务架构的好处与不足2018-02-23 4394
-
什么是微服务架构_微服务架构的优缺点及应用2019-06-02 17434
-
SOA架构和微服务架构的主要区别2020-05-04 5863
-
微服务架构有哪些_微服务架构设计模式2021-05-17 28882
-
微服务架构的特点_微服务架构适用场景2021-05-17 5144
-
微服务软件架构应用研究综述2021-05-26 665
-
从分层架构到微服务架构介绍(一)2023-05-10 1121
-
从分层架构到微服务架构介绍(二)2023-05-10 731
-
从分层架构到微服务架构介绍(四)2023-05-10 773
-
从分层架构到微服务架构介绍(五)2023-05-10 846
-
springcloud微服务架构2023-11-23 1341
-
docker微服务架构实战2023-11-23 650
-
设计微服务架构的原则2023-11-26 594
-
架构与设计 常见微服务分层架构的区别和落地实践2024-10-22 231
全部0条评论

快来发表一下你的评论吧 !
