

机器学习步骤详解,一文了解全过程
描述
引言
部署机器学习的过程涉及多个步骤。首先选择一个模型,针对特定任务加以训练,用测试数据进行验证,然后,将该模型部署到实际系统中并进行监控。在本文中,我们将讨论这些步骤,将每个步骤拆分讲解来介绍机器学习。
机器学习是指在没有明确指令的情况下能够学习和加以改进的系统。这些系统从数据中学习,用于执行特定的任务或功能。在某些情况下,学习,或者更具体地说,训练,是在受监督的方式下进行,当输出不正确时对模型加以调整,使其生成正确的输出。在其他情况下,则实行无监督学习,由系统负责梳理数据来发现以前未知的模式。大多数机器学习模型都是遵循这两种范式(监督学习与无监督学习)。
现在,让我们深入研究“模型”的含义,然后探究数据如何成为机器学习的燃料。
机器学习模型
模型是机器学习解决方案的抽象化表述。模型定义架构,架构经过训练变成产品实现。所以,我们不是部署模型,而是部署经过数据训练的模型的实现(在下一节中有更加详细的介绍)。模型 + 数据 + 训练=机器学习解决方案的实例(图1)。
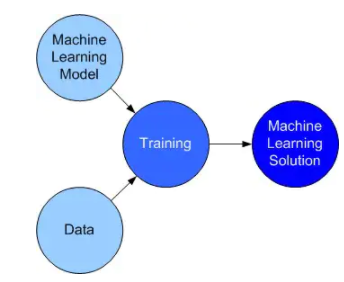
图1:从机器学习模型到解决方案。(图源:作者)
机器学习解决方案代表一个系统。它们接受输入,在网络中执行不同类型的计算,然后提供输出。输入和输出代表数值型数据,这意味着,在某些情况下,需要转译。例如,将文本数据输入深度学习网络需要将单词编码成数字形式,考虑到可以使用的单词的多样性,该数字形式通常是高维向量。同样,输出可能需要从数字形式转译回文本形式。
机器学习模型有多种类型,如神经网络模型、贝叶斯 (Bayesian) 模型、回归模型、聚类模型等。您选择的模型是基于着手解决的问题。
对于神经网络来说,模型从浅多层网络到深度神经网络,类型丰富,而深度神经网络还包括多层特化神经元(处理单元)。深度神经网络还有一系列基于目标应用的可用模型。例如:
如果您的应用侧重于识别图像中的对象,那么卷积神经网络 (CNN) 就是理想的模型。CNN已被应用于皮肤癌检测,效果优于皮肤科医生的平均水平。
如果您的应用涉及预测或生成复杂序列(如人类语言句子),那么递归神经网络 (RNN) 或长短期记忆网络 (LSTM) 是理想模型。LSTM也已经应用到人类语言的机器翻译中。
如果您的应用涉及用人类语言描述图像内容,可以使用CNN和LSTM的组合(图像输入CNN,CNN的输出代表LSTM的输入,后者发出词汇序列)。
如果您的应用涉及生成现实图像(如风景或人脸),那么生成对抗网络 (GAN) 是当前最先进的模型。
这些模型代表了当今常用的部分深层神经网络架构。深度神经网络深受欢迎,因为它们可以接受非结构化数据,如图像、视频或音频信息。网络中的各层构成一个特征层次结构,使它们能够对非常复杂的信息进行分类。深度神经网络已经在许多问题领域展示出先进的性能。但是像其他机器学习模型一样,它们的准确性依赖于数据。接下来我们就探讨一下这个方面。
数据和训练
无论在运算中,还是在通过模型训练构建机器学习解决方案的过程中,数据皆为驱动机器学习的燃料。对于深度神经网络的训练数据,探索数量和质量前提下的必要数据至关重要。
深度神经网络需要大量数据进行训练;按经验来说,图像分类中每类需要1,000张图像。但具体答案显然取决于模型的复杂度和容错度。实际机器学习解决方案中的一些示例表明,数据集有各种大小。一个面部检测和识别系统需要45万张图像,一个问答聊天机器人需要接受20万个问题和200万个匹配答案的训练。根据要解决的问题,有时较小的数据集也足够。一个情感分析解决方案(根据书面文本确定观点的极性)只需要数万个样本。
数据的质量和数量同等重要。鉴于训练需要大数据集,即使少量的错误训练数据也会导致糟糕的解决方案。根据所需的数据类型,数据可能会经历一个清洗过程。此过程确保数据集一致、没有重复数据且准确、完整(没有无效或不完整数据)。有可以支持此过程的工具。验证数据的偏差也很重要,确保数据不会导致有偏差的机器学习解决方案。
机器学习训练对数值型数据进行运算,因此,根据您的解决方案,可能需要预处理步骤。例如,如果数据是人类语言,其必须首先转译为数字形式才能处理。可以对图像进行预处理以保持一致性。例如,除了其他运算外,输入深度神经网络的图像还需要调整大小和平滑处理,以去除噪声。
机器学习中最大的问题之一是获取数据集来训练机器学习解决方案。根据您的具体问题,这个工作量可能非常大,因为可能没有现成的数据,需要您另外设法获取。
最后,应该分割数据集,分别用作训练数据和测试数据。训练数据用于训练模型,在训练完成后,测试数据用于验证解决方案的准确性(图2)。
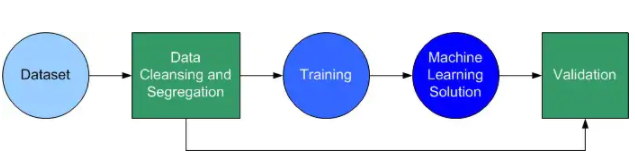
图2:分割数据集分别用于训练和验证。(图源:作者)
有工具来帮助完成这个过程,大多数框架都拥有“分割”功能,用于分割训练和测试数据。现在我们来看一些简化机器学习解决方案构造的框架。
框架
现在,不再需要从头开始构建机器学习模型。您可以使用包含这些模型和其他工具的框架来准备数据和验证您的解决方案。这些框架还提供用于部署解决方案的环境。选择哪个框架通常取决于您的熟悉程度,但在刚开始的时候可以选择一个适合您要使用的应用与模型的框架。
TensorFlow是最好的深度学习框架。它支持所有流行的模型(CNN、RNN、LSTM等),并允许您使用Python或C++进行开发。从高端服务器到移动设备,均可部署TensorFlow解决方案。如果您刚刚上手,TensorFlow是一个不错的起点,它有教程和丰富的文档。
CAFFE最初是一个学术项目,但在发布到开源后,已经发展成为一个流行的深度学习框架。CAFFE采用C++编写,但也支持Python模型开发。同TensorFlow一样,它也支持广泛的深度学习模型。
PyTorch的框架中。PyTorch是另一个很好的选择,它基于丰富的可用信息,包括构建不同类型解决方案的实践教程。
R语言和环境是机器学习和数据科学的流行工具。其为交互式工具,可帮助您逐步构建解决方案的原型,同时分阶段查看结果。有了Keras(一个开源的神经网络库),您可以用极少量的开发投入来构建CNN和RNN。
模型审核
一旦模型经过训练并满足了准确性要求,即可部署到生产系统中。但是到了这一步就需要审核解决方案,以确保其符合要求。考虑到决策是由模型来做以及对人们的影响,这一点尤为重要。
有些机器学习模型是透明的,可以理解(例如,决策树)。但深度神经网络等其他模型被认为是“黑箱”,决策是由数百万个无法用模型本身解释的计算做出的。因此,过去一度可以接受定期审核,但是,连续审核正在迅速成为这些暗箱情况下的标配,因为错误是不可避免的。一旦发现错误,这些信息可以用作调整模型的数据。
另一个考虑是解决方案的生命周期。模型会衰退,输入数据会发生变化,从而导致模型性能的变化。因此,必须接受解决方案随着时间的推移会变得羸弱,机器学习解决方案必须随着周围世界的变化而不断做出改变。
总结
为了部署机器学习解决方案,我们从一个问题开始,然后考虑可能的解决模型。接下来是获取数据,经过正确清理和分割,就可以使用机器学习框架训练和验证模型。并非所有的框架都是相同的,您可以根据您的模型和经验来选择和应用。然后,使用该框架部署机器学习解决方案,通过适当的审核,解决方案可以在真实世界中使用实时数据进行运算。
审核编辑:郭婷
-
电流镜设计步骤详解【全过程】2011-11-04 0
-
热转印威廉希尔官方网站 板制作全过程2012-06-24 0
-
PCB 制作全过程2012-08-05 0
-
图文详解2000元电动汽车DIY全过程2012-08-15 0
-
音箱制作全过程2012-08-16 0
-
有人分享制作蓝牙耳机的全过程吗?2014-06-02 0
-
分享一个串口实现全过程好资料2015-02-05 0
-
CPU制造全过程2009-09-22 934
-
组装电脑全过程视频教程2010-09-14 2046
-
深入大规模芯片设计全过程2021-04-10 1131
-
用C语言开发DSP系统的全过程的讲解2021-05-26 918
-
手工制作pcb全过程2021-06-19 2127
-
芯片制造全过程2021-12-08 11755
-
探究芯片制作的全过程2022-01-01 8486
-
电磁炉的维修全过程分享2022-01-10 1408
全部0条评论

快来发表一下你的评论吧 !
