

大语言模型的多语言机器翻译能力分析
描述
01
研究动机
以ChatGPT为代表的大语言模型(Large Language Models, LLM)在机器翻译(Machine Translation, MT)任务上展现出了惊人的潜力。通过情景学习(In-Context Learning,ICL),大语言模型可以根据任务示例和任务指令,在不更新模型参数的情况下,完成特定下游任务。然而,值得注意的是,这些大语言模型主要基于大规模的数据进行语言模型任务的学习,并没有在大规模多语言翻译数据上训练过,我们非常好奇于:(1)大语言模型的多语言机器翻译能力如何?(2)哪些因素会影响大语言模型的翻译表现?为了探究这些问题,本文评测了XGLM[1],OPT[2],BLOOMZ[3],ChatGPT[4]等众多热门大语言模型在百余种语言上的翻译能力,并且分析了在情景学习中各种因素对翻译效果的影响。
02
贡献
1. 本文在102种语言以及202个以英文为核心的翻译方向上全面地评测了包括ChatGPT在内的热门大语言模型的多语言机器翻译能力。
2. 本文系统地报告了一系列大语言模型以及两个有监督基线的翻译表现,为后续大语言模型和多语言机器翻译研究工作提供了有力参照。
3. 本文还发现了在机器翻译任务上大语言模型展现出了一些新的工作模式。
03
实验设定
为了全面地衡量大语言模型的多语言机器翻译能力,本文选用Flores-101数据集[5]进行实验。在应用大语言模型进行情景学习的过程中,本文设置任务示例数目为8,任务指令模版为“
04
大语言模型多语言机器翻译能力评测
在系统地评测大语言模型的多语言翻译能力后,本文得出了以下主要结论:
1. 在评测的四种大语言模型中,ChatGPT展现了最好的多语言机器翻译效果:相比于只经过预训练(pre-traing)的XGLM和OPT,经过指令微调(instruction-tuning)的BLOOMZ和ChatGPT展现了更好的翻译表现(表格1)。值得注意的是,BLOOMZ在七组翻译方向上超过了有监督基线模型,而ChatGPT在所有被评测的大语言模型中取得了最好的综合翻译表现。
2. 大语言模型翻译其他语言到英语的表现往往比翻译英语到其他语言的表现要好:此前的研究发现大语言模型在将其他语言翻译到英语时往往有很好的表现,而在将英语翻译到其他语言时则表现较差。本文发现XGLM,OPT,BLOOMZ,ChatGPT也都存在这种偏好。但是,值得注意的是,ChatGPT已经极大地改善了这种倾向。
表格 1 不同模型在各语系上的平均BLEU分数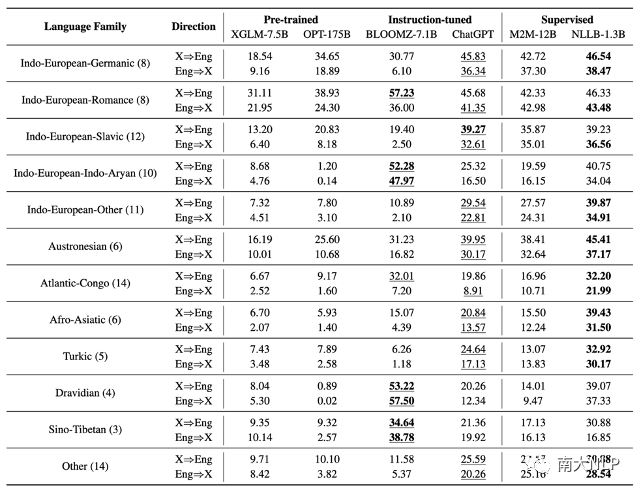
3. 在大部分语言上,尤其是低资源语言,大语言模型的翻译效果仍然落后于强大的有监督基线模型:图1中画出来了ChatGPT和NLLB模型在各个语言上的翻译表现,可以看出在图片的左半部分,ChatGPT可以取得与NLLB相似的性能,而在图片的右半部分,在低资源语言翻译上,ChatGPT仍然远远落后于传统的有监督基线模型。
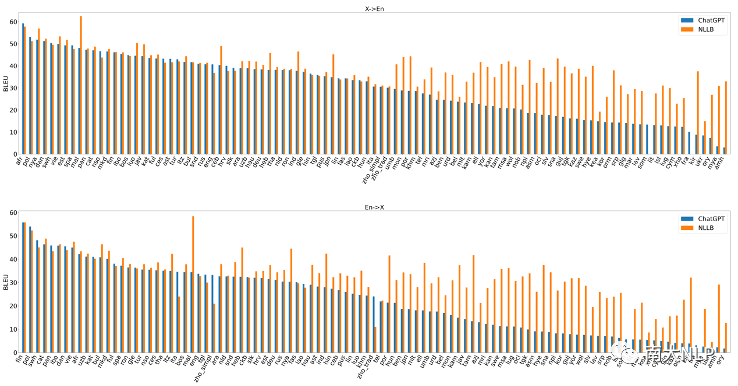
图 1 ChatGPT和NLLB在各语言上的翻译表现对比
4. 指令微调过的大语言模型仍然可以从任务示例中受益:本文对比了BLOOMZ和ChatGPT这两个经过指令微调的模型在任务样例数目分别为0和8时的翻译表现(图2),可以看出即使对于指令微调过的模型,提供任务示例依然可以进一步提升其翻译能力。这也是本文在评测大语言模型翻译能力同时提供任务示例和任务指令的原因。
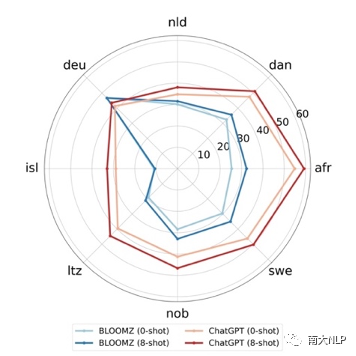
图 2 BLOOMZ和ChatGPT在给定不同数目的任务示例时的翻译表现对比
5. 在公开数据上评测大语言模型有数据泄漏的风险:为了考察数据泄漏对评测结果的影响,本文基于近期的英语新闻,人工构建了一个中-英-德三语无泄漏机器翻译测试集。在该测试集上的测试结果显示:XGLM和OPT在新标注测试集上取得了与公开测试集上相似的性能,而ChatGPT在英语-德语翻译上性能出现大幅下降,BLOOMZ更是在四个测试方向上都出现性能下降的问题(图3)。这说明BLOOMZ在Flores-101上取得很好的表现很可能是数据泄漏导致的。
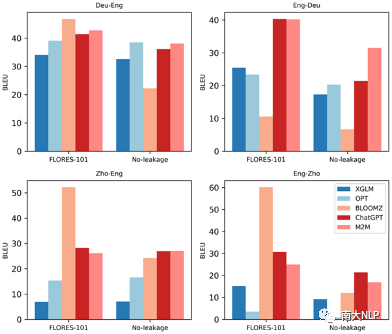
图 3 不同模型在Flores-101测试集和无泄漏测试集上的翻译表现
05
大语言模型机器翻译能力影响因素分析
为了更好地理解大语言模型如何通过情景学习中完成翻译任务,本文以XGLM为例分析了情景学习中诸多因素对翻译效果的影响。以下介绍本文在关于任务指令和任务示例两方面的相关发现:
1. 与任务指令相关的发现:
大语言模型在下游任务上的良好表现依赖于精心设计的指令:本文发现大语言模型在下游任务上的表现会随着指令内容的不同而剧烈变化。并且在不同翻译方向上,最好的指令也不同(表格2)在这些指令中,“
即使是不合理的指令也可以引导大语言模型完成翻译任务:直觉上,人们认为大语言模型理解了任务指令所以能够完成指定的下游任务。但是本文发现,在情景学习时使用任务无关的指令,大语言模型依然可以完成目标任务。例如,面对指令“
表格 2 使用不同任务指令对翻译效果的影响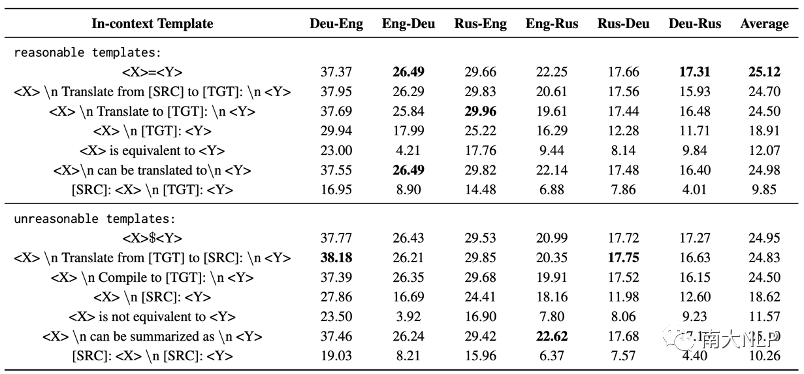
2. 关于任务示例的发现
根据语义选择示例与随机选择示例效果相当:为了研究任务示例对情景学习效果的影响,本文对比了包括随机检索、稀疏检索、稠密检索在内的多种任务示例选择策略(图4)。实验结果表明当任务样例数目从1增加到8时,BLEU分数会显著提升。但是进一步增加样例数目,BLEU分数基本变化不大,甚至会开始下降。相比于根据语义进行选择,随机选择也可以取得相似的效果。并且即使根据目标句进行检索,也没有展现出明显的优势。这些实验结果表明,翻译任务示例可以帮助大语言模型理解翻译任务,但是大语言模型可能很难从语义相关的翻译示例中直接获取有帮助的翻译知识。
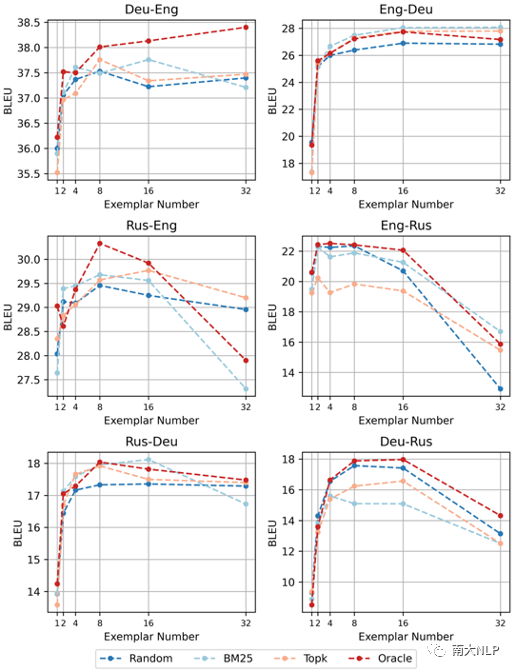
图 4 使用不同任务示例选择策略对翻译效果的影响
翻译任务示例帮助大语言模型理解翻译任务的核心特征:为了理解翻译任务示例如何影响大语言模型理解翻译任务,本文观察了大语言模型在不同任务示例下的翻译表现(表格3)。当使用不匹配的翻译句对作为任务样例时,大语言模型完全无法进行翻译。这说明模型从翻译任务示例中学习到需要保证源句和目标句语义一致。当使用词级别或者段落级别翻译对作为翻译示例时,模型的翻译质量显著下降,这说明任务样例的粒度也很重要。当使用重复的翻译句对作为翻译样例时,模型的翻译质量也会下降,这说明保持任务示例的多样性也是保证模型下游任务性能的必要条件。总体来说,这些对比实验的结果说明大语言在情景学习中,通过任务样例理解了翻译任务的核心需求。
表格 3 在给定不同任务示例时XGLM的翻译表现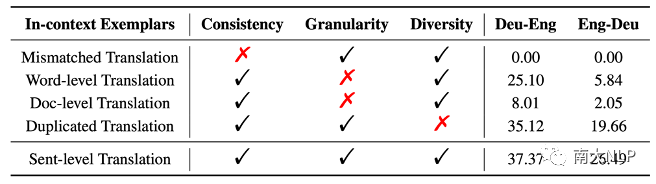
使用跨语言任务示例也可能带来翻译性能提升:本文发现在机器翻译的情景学习中,使用不同语言对的翻译句对作为任务示例并不一定会导致翻译质量下降。例如,在进行德语-英语翻译时,如果使用跨语言任务示例会导致翻译质量下降;而在进行汉语-英语翻译时,使用跨语言任务示例则可以大幅提升翻译性能(图5)。这显示了跨语言任务示例在情景学习中的潜在用途。
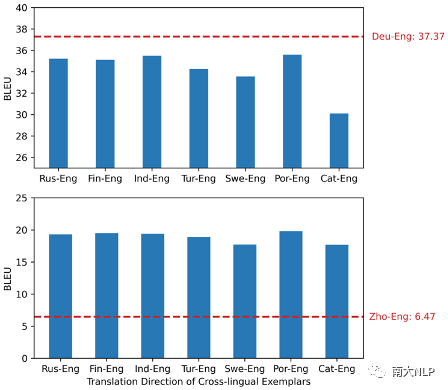
图 5 使用跨语言翻译任务示例的效果
在上下文末尾位置的任务示例对于大语言模型的行为有着更大的影响:本文发现使用与目标翻译方向相反的翻译句对作为任务示例时,大语言模型完全无法进行正确的翻译。利用这种特性,本文考察了在上下文的不同位置的任务示例对大语言模型的翻译行为的影响程度。表格4中的实验结果表明,在使用相同数量的反向任务示例时,反向任务示例出现在上下文的末尾位置时,大语言模型的翻译表现会更差。这说明在末尾位置的任务示例对于大语言模型的行为有着更大的影响。
表格 4 反转任务示例翻译方向对翻译效果的影响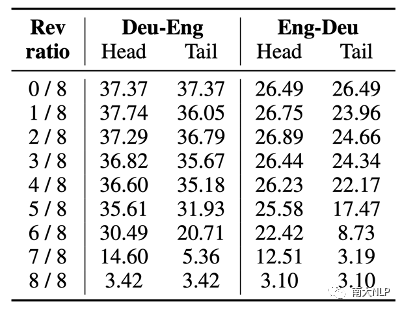
06
总结
本文系统地评测了包括ChatGPT在内的一系列大语言模型在102种语言,202个以英文为核心的翻译方向上的多语言机器翻译能力,探究了使用大语言模型进行多语言机器翻译的优势与挑战。我们发现即使是最强的大语言模型(ChatGPT),仍然在83.33%的翻译方向上落后于强大的有监督基线模型(NLLB)。经过进一步的分析实验,我们发现在机器翻译任务上,大语言模型展现出了一些新的工作模式:例如,在情景学习时,任务指令的语义可以被大语言模型所忽视;使用跨语言任务示例可以提升低资源机器翻译效果。更重要的是,我们发现BLOOMZ在公开数据集上的表现是被高估的,而如何公平地比较不同语言模型的能力将是大语言模型时代的一个重要话题。
审核编辑:刘清
-
SoC多语言协同验证平台技术研究2015-12-31 784
-
谷歌再次发布BERT的多语言模型和中文模型2018-11-08 6060
-
机器翻译三大核心技术原理 | AI知识科普2018-07-06 0
-
神经机器翻译的方法有哪些?2020-11-23 0
-
阿里宣布完成全球首个多语言实时翻译的电商直播2020-10-27 1960
-
人工智能翻译mRASP:可翻译32种语言2020-12-01 3209
-
多语言翻译新范式的工作:机器翻译界的BERT2021-03-31 2984
-
Multilingual多语言预训练语言模型的套路2022-05-05 2977
-
多语言任务在内的多种NLP任务实现2022-10-13 625
-
借助机器翻译来生成伪视觉-目标语言对进行跨语言迁移2022-10-14 865
-
基于LLaMA的多语言数学推理大模型2023-11-08 480
-
多语言开发的流程详解2023-11-30 1108
-
基于机器翻译增加的跨语言机器阅读理解算法2023-12-12 589
-
大语言模型(LLMs)如何处理多语言输入问题2024-03-07 616
-
ChatGPT 的多语言支持特点2024-10-25 779
全部0条评论

快来发表一下你的评论吧 !
