

机器人视觉梳理
描述
机器人视觉的概念
在智能制造过程中,通过传统的编程来执行某一特定动作的机器人(机械手、机械手臂、机械臂等,未作特殊说明时,不作严格区分,统一称为机器人),将难以满足制造业向前发展的需求。很多应用场合下,需要为工业机器人安装一双眼睛,即机器视觉成像感知系统,使机器人具备识别、分析、处理等更高级的功能。这在高度自动化的大规模生产中非常重要,只有当工业机器人具有视觉成像感知系统,具备观察目标场景的能力时,才能正确地对目标场景的状态进行判断与分析,做到智能化灵活地自行解决发生的问题。
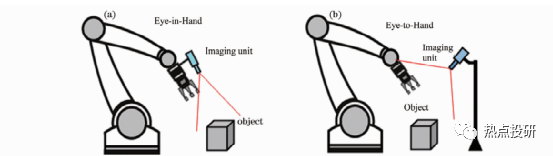
在工业应用领域,最具有代表性的机器人视觉系统就是机器人手眼系统。根据成像单元安装方式不同,机器人手眼系统分为两类:固定成像单元眼看手系统(Eye-to-Hand)和随动成像单元眼在手系统(Eye-in-Hand or Hand-Eye)。
在Eye-to-Hand系统中,视觉成像单元安装在机器人本体外的固定位置,在机器人工作过程中不随机器人一起运动,当机器人或目标运动到机械臂可操作的范围时,机械臂在视觉感知信息的反馈控制下,向目标移动,对目标进行精准操控。Eye-to-Hand系统的优点是具有全局视场,标定与控制简单、抗震性能好、姿态估计稳定等,但也存在分辨率低、容易产生遮挡问题等缺点。
在Eye-in-Hand系统中,成像单元安装在机器人手臂末端,随机器人一起运动。Eye-in-Hand系统常用在有限视场内操控目标,不会像 Eye-to-Hand系统那样产生机械臂遮挡成像视场问题,空间分辨率高,对于基于图像的视觉控制,成像单元模型参数的标定误差可以被有效地克服,对标定的精度要求不高。
图:两种机器人手眼系统的结构形式(a)眼在手机器人系统(b)眼看手机器人系统
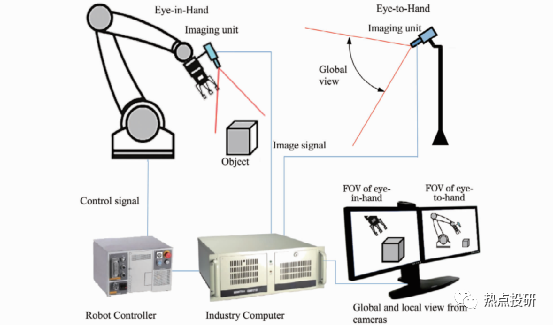
有些应用场合,为了更好地发挥机器人手眼系统的性能,充分利用 Eye-to-Hand系统全局视场和Eye-in-Hand局部视场高分辨率和高精度的性能,可采用两者混合协同模式。利用 Eye-to-Hand系统负责机器人的定位,利用Eye-in-Hand系统负责机器人的定向;或者利用 Eye-to-Hand计机器人相对目标的方位,利用 Eye-in-Hand负责目标姿态的高精度估计等。
图:机器人协同视觉系统原理
机器人视觉发展路径:从2D到3D
l视觉成像最初是从二维(2D)图像处理与理解,即2D视觉成像发展起来的。2D视觉技术主要根据灰度或彩色图像中的像素灰度特征获取目标中的有用信息,以及基于轮廓的图案匹配驱动,识别物体的纹理、形状、位置、尺寸和方向等。2D视觉技术距今已发展了30余年,在自动化和产品质量控制过程中得到广泛应用,目前技术较为成熟,主要用于字符与条码识读、标签验证、形状与位置测量、表面特征检测等。
l2D视觉技术难以实现三维高精度测量与定位,二维形状测量的一致性和稳定性也较差,易受照明条件等影响。尤其当前智能制造技术对机器人视觉性能的要求越来越高,2D机器视觉技术的局限性已经显现,机器人视觉系统集成商已经发现越来越难以通过2D机器视觉系统来增值,迫切需要发展三维(3D)视觉技术,因为3D视觉技术能够产生2D视觉无法产生的形状或深度信息,因此使用范围更广。
l当前,机器人视觉成像技术及系统正越来越广泛地应用于视觉测量、检测、识别、引导和自动化装配领域中。虽然很多机器人具备一定程度的智能化,但还远未达到人类所需的智能化程度,一个重要原因是机器人视觉感知系统中还有许多科学问题、关键应用技术问题等,仍亟待解决。如:1)如何使机器人像人那样,对客观世界的三维场景进行感知、识别和理解;2)哪些三维视觉感知原理可以对场景目标进行快速和高精度的三维测量,并且基于该原理的三维视觉传感器具有小体积、低成本,方便嵌入到机器人系统中;3)基于三维视觉系统获得的三维场景目标信息,如何有效地自组织自身的识别算法,准确、实时地识别出目标;4)如何通过视觉感知和自学习算法,使机器人像人那样具有自主适应环境的能力,自动地完成人类赋予的任务等。
机器人3D视觉方案
3D视觉是机器人感知的最先进、最重要的方法,可以分为光学和非光学成像方法。目前应用最多的方法是光学方法,包括:飞行时间法、结构光法、激光扫描法、莫尔条纹法、激光散斑法、干涉法、照相测量法、激光跟踪法、从运动获得形状、从阴影获得形状,以及其他的 Shape from X等。本次介绍几种典型方案。
1.飞行时间3D成像
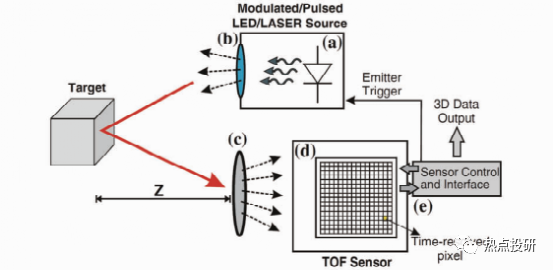
飞行时间(TOF)相机的每个像素利用光飞行的时间差来获取物体的深度。
l直接TOF(D-TOF)是经典的TOF测量方法,探测器系统在发射光脉冲的同时启动探测接收单元进行计时,当探测器接收到目标发出的光回波时,探测器直接存储往返时间,目标距离可以通过简单公式计算:z=0.5*c*t,c是光速,t是光飞行时间。D-TOF通常用于单点测距系统,为了实现面积范围3D成像,通常需要采用扫描技术。无扫描 TOF三维成像技术直到近几年才实现,因为在像素级实现亚纳秒电子计时是非常困难的。
l间接TOF(I-TOF)与D-TOF不同,时间往返行程是从光强度的时间选通测量中间接外推获得的。I-TOF不需要精确的计时,而是采用时间选通光子计数器或电荷积分器,它们可以在像素级实现。I-TOF是目前基于 TOF相机的电子和光混合器的商用化解决方案。
图:TOF成像原理
TOF成像可用于大视野、远距离、低精度、低成本的3D图像采集。其特点是:检测速度快、视野范围较大、工作距离远、价格便宜,但精度低,易受环境光的干扰。
2.扫描3D成像
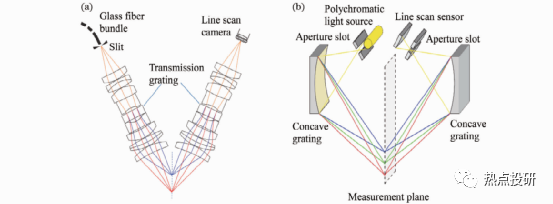
扫描3D成像方法可分为扫描测距、主动三角法、色散共焦法等。
l扫描测距是利用一条准直光束通过一维测距扫描整个目标表面实现3D测量。典型扫描测距方法有:1)单点飞行时间法,如连续波频率调制(FM-CW)测距、脉冲测距(激光雷达)等;2)激光散射干涉法,如基于多波长干涉、全息干涉、白光干涉、散斑干涉等原理的干涉仪;3)共焦法,如色散共焦、自聚焦等。单点测距扫描3D方法中,单点飞行时间法适合远距离扫描,测量精度较低,一般在毫米量级。其他几种单点扫描方法有:单点激光干涉法、共焦法和单点激光主动三角法,测量精度较高,但前者对环境要求高;线扫描精度适中,效率高。比较适合于机械手臂末端执行3D测量的应是主动激光三角法和色散共焦法。
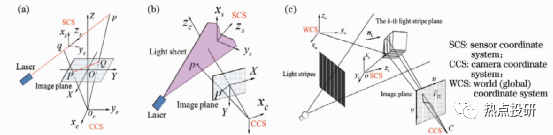
l主动三角法是基于三角测量原理,利用准直光束、一条或多条平面光束扫描目标表面完成3D测量的。光束常采用以下方式获得:激光准直、圆柱或二次曲面柱形棱角扩束,非相干光(如白光、LED光源)通过小孔、狭缝(光栅)投影或相干光衍射等。主动三角法可分为三种类型:单点扫描、单线扫描和多线扫描。如图,从左至右依次是单点扫描、单线扫描和多线扫描。
图:主动三角法扫描成像
l色散共焦法可以扫描测量粗糙和光滑的不透明和透明物体,如反射镜面、透明玻璃面等,目前在手机盖板三维检测等领域广受欢迎。色散共焦扫描有三种类型:单点一维绝对测距扫描、多点阵列扫描和连续线扫描,下图分别列出了绝对测距和连续线扫描两类示例,其中连续线扫描也是一种阵列扫描,只是阵列的点阵更多、更密集。
图:两种色散共焦单点测距方法(a)基于小孔和分光镜的结构;(b)基于Y型光纤分光的结构
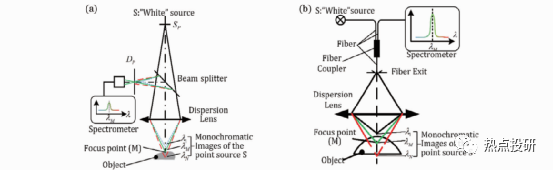
图:两种色散共焦线扫描成像方案(a)色散共焦显微镜;(b)色散共焦三角法
扫描3D成像的最大优点是测量精度高,其中色散共焦法还有其他方法难以比拟的优点,即非常适合测量透明物体、高反与光滑表面的物体。但缺点是速度慢、效率低;当用于机械手臂末端时,可实现高精度3D测量,但不适合机械手臂实时3D引导与定位,因此应用场合有限;另外主动三角扫描在测量复杂结构形貌时容易产生遮挡,需要通过合理规划末端路径与姿态来解决。
3.结构光投影3D成像
结构光投影三维成像目前是机器人3D视觉感知的主要方式,结构光成像系统是由若干个投影仪和相机组成,常用的结构形式有:单投影仪-单相机、单投影仪-双相机、单投影仪-多相机、单相机-双投影仪和单相机-多投影仪等典型结构形式。结构光投影三维成像的基本工作原理是:投影仪向目标物体投射特定的结构光照明图案,由相机摄取被目标调制后的图像,再通过图像处理和视觉模型求出目标物体的三维信息。根据结构光投影次数划分,结构光投影三维成像可以分成单次投影3D和多次投影3D方法。
l单次投影结构光主要采用空间复用编码和频率复用编码形式实现,目前在机器人手眼系统应用中,对于三维测量精度要求不高的场合,如码垛、拆垛、三维抓取等,比较受欢迎的是投射伪随机斑点获得目标三维信息,其3D成像原理如图。
图:单次投影结构光3D成像原理
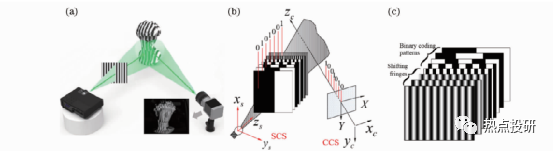
l多次投影结构光主要采用时间复用编码方式实现。条纹投影3D成像基本原理如图,利用计算机生成结构光图案或用特殊的光学装置产生结构光,经过光学投影系统投射至被测物体表面,然后采用图像获取设备(如CCD或 CMOS相机)采集被物体表面调制后发生变形的结构光图像,利用图像处理算法计算图像中每个像素点与物体轮廓上点的一一对应关系;最后通过系统结构模型及其标定技术,计算得到被测物体的三维轮廓信息。在实际应用中,常采用格雷码投影、正弦相移条纹投影或格雷码+正弦相移混合投影3D技术。
图:多次投影3D成像(a)多次投影3D系统机构示意图;(b)二进制格雷码投影3D基本原理;(c)二进制格雷码+正弦相移混合编码投影3D
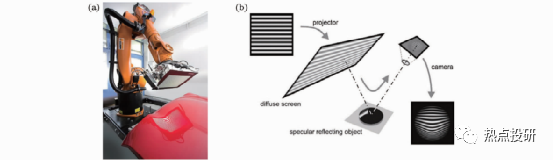
l偏折法成像:对于粗糙表面,结构光可以直接投射到物体表面进行视觉成像测量;但对于大反射率光滑表面和镜面物体3D测量,结构光投影不能直接投射到被测表面,3D测量还需要借助镜面偏折技术。
图:偏折法成像原理
4.立体视觉3D成像
立体视觉字面意思是用一只眼睛或两只眼睛感知三维结构,一般情况下是指从不同的视点获取两幅或多幅图像重构目标物体3D结构或深度信息。目前立体视觉3D可以通过单目视觉、双目视觉、多(目)视觉、光场3D成像(电子复眼或阵列相机)实现。
l单目视觉深度感知线索通常有:透视、焦距差异、多视觉成像、覆盖、阴影、运动视差等。在机器人视觉里还可以用镜像,以及其他shape from X等方法实现。
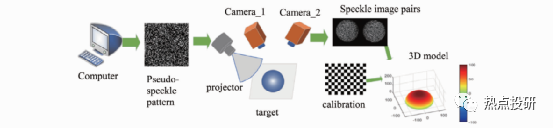
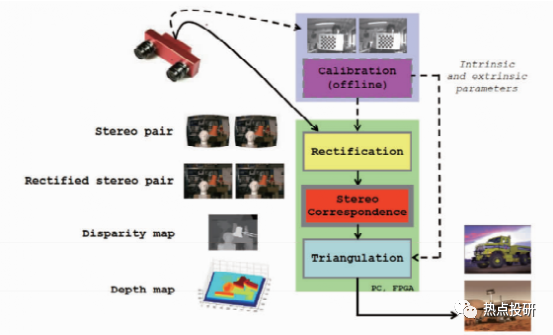
l双目视觉深度感知视觉线索有:眼睛的收敛位置和双目视差。在机器视觉里利用两个相机从两个视点对同一个目标场景获取两个视点图像,再计算两个视点图像中同名点的视差获得目标场景的3D深度信息。典型的双目立体视觉计算过程包含下面四个步骤:图像畸变矫正、立体图像对校正、图像配准和三角法重投影视差图计算。
图:双目立体视觉系统与计算过程示意图
l多(目)视觉成像,也称多视点立体成像,用单个或多个相机从多个视点获取同一个目标场景的多幅图像,重构目标场景的三维信息。多视点立体成像主要用于下列几种场景:1)使用多个相机从不同视点,获取同一个目标场景多幅图像,然后基于特征的立体重构等算法求取场景深度和空间结构信息;2)从运动恢复形状的技术。使用同一相机在其内参数不变的条件下,从不同视点获取多幅图像,重构目标场景的三维信息。该技术常用于跟踪目标场景中大量的控制点,连续恢复场景的3D结构信息、相机的姿态和位置。
l光场3D成像的原理与传统CCD和CMOS相机成像原理在结构原理上有所差异,传统相机成像是光线穿过镜头在后续的成像平面上直接成像,一般是2D图像。光场相机的优点是:单个相机可以进行3D成像,横向和深度方向的空间分辨率可以达到20μm到mm 量级,景深比普通相机大好几倍,比较适合Eye-in-Hand系统3D测量与引导,但目前精度适中的商业化光场相机价格昂贵。
图:光场相机成像与传统相机成像对比(a)传统相机成像原理;(b)光场相机结构与成像原理

机器人3D视觉方案对比分析
1.TOF相机、光场相机这类相机可以归类为单相机3D成像范围,它们体积小,实时性好,适合 Eye-in-Hand系统执行3D测量、定位和实时引导。但是,TOF相机、光场相机短期内还难以用来构建普通的 Eye-in-Hand系统,主要原因如下:
lTOF相机空间分辨率和3D精度低,不适合高精度测量、定位与引导。
l对于光场相机,目前商业化的工业级产品只有德国Raytrix一家,虽然性能较好,空间分率和精度适中,但价格太贵,一台几十万元,使用成本太高。
2.结构光投影3D系统的精度和成本适中,有相当好的应用市场前景。它由若干个相机-投影仪组成,如果把投影仪当作一个逆向的相机,可以认为该系统是一个双目或多目3D三角测量系统。
3.被动立体视觉3D成像目前在工业领域也得到较好应用,但应用场合有限。因为单目立体视觉实现有难度,双目和多目立体视觉要求目标物体纹理或几何特征清晰。
4.结构光投影3D、双目立体视觉3D都存在下列缺点:体积较大,容易产生遮挡。因为这几种方法都是基于三角测量原理,要求相机和投影仪之间或双目立体两个相机之间必须间隔一定距离,并且存在一定的夹角θ(通常大于15°)才能实现测量。如果被测物体表面陡峭或有台阶,会引起相机成像遮挡,即相机不能捕捉到这些结构光的照射区域,导致存在不可测量区域。如果减小相机与投影仪(结构光光源)的夹角,虽然在某些程度上可以解决问题,但是却会严重降低系统的测量灵敏度,影响测量系统的应用。
机器人3D视觉应用案例
1.波士顿动力Atlas
Atlas 使用 TOF 深度相机以每秒 15 帧的速度生成环境的点云,点云是测距的大规模集合。Atlas 的感知软件使用一种名为多平面分割的算法从点云中提取平面。多平面分割算法的输入馈入到一个映射系统中,该系统为 Atlas 通过相机看到的各种不同对象构建模型。下图显示了 Atlas 的视觉以及如何使用这种视觉感知来规划行为。左上角是深度相机拍摄的红外图像。主图像中的白点形成点云。橙色轮廓标记了检测到的跑酷障碍物的矩形面,随着时间的推移从传感器观察结果中对其进行跟踪。然后将这些检测到的对象用于规划特定行为。例如,绿色的脚步代表下一步要跳到哪里。
图:TOF视觉的深度感知与决策

2.特斯拉OPTIMUS
由于在电动车FSD积累的成熟的视觉感知技术,特斯拉机器人的 3D传感模块以多目视觉为主,使用三颗Autopilot摄像头作为感知系统,在采集信息后,通过强大的神经网络处理和识别不同任务,依靠其胸腔内部搭载的 FSD 全套计算机完成。
图:特斯拉的三颗Autopilot摄像头画面

3.小米CyberOne
CyberOne搭载的Mi-Sense深度视觉模组是由小米设计,欧菲光协同开发完成。由于Mi-Sense深度视觉模组的相关资料不多,所以可以从欧菲光自研的机器视觉深度相机模块进行观察。该模块主要由iToF模组、RGB模组、可选的IMU模块组成,产品在测量范围内精度高达1%,应用场景十分广泛,可通过第三方实验室IEC 60825-1认证,满足激光安全Class1标准。
图:CyberOne传感器模块

图:Mi-Sense视觉空间系统

4.优必选WALKER X
优必选WALKER X采用基于多目视觉传感器的三维立体视觉定位,采用Coarse-to-fine的多层规划算法,第一视角实景AR导航交互及2.5D立体避障技术,实现动态场景下全局最优路径自主导航。WALKER应用视觉SLAM算法,视觉定位技术已经达到商用水平。
图:优必选WALKER的视觉应用
多模态GPT+机器人视觉 开启无限可能
在ChatGPT和GPT-4发布后,全球对于OpenAI的关注度持续提升。GPT-4具备强大的文本和图像处理功能,而未来的GPT-5将在多模态理解方面表现更加出色,甚至能加入音频和视频的处理服务。未来多模态有望在机器人视觉领域得到广泛应用,输入输出将包括3D模型,有望赋能机器人感知、规控和仿真能力,也有望提高3D模型生产效率,助力游戏内容与元宇宙构造。多模态AI模型有望具备与真实世界所有输入交互的能力,极大提升人形机器人的能力,加速人形机器人加速普及。目前,虽然多模态GPT还未完全研发和应用,但类似的多模态大模型已经初显威力,吹响了多模态GPT的号角。
1.Meta SAM
Meta发布AI图像分割模型Segment Anything Model,该模型将自然语言处理领域的prompt范式引入计算机视觉领域,可以通过点击、框选和自动识别三种交互方式,实现精准的图像分割,突破性地提升了图像分割的效率。英伟达人工智能科学家 Jim Fan 表示:「对于 Meta 的这项研究,我认为是计算机视觉领域的 GPT-3 时刻之一。它已经了解了物体的一般概念,即使对于未知对象、不熟悉的场景(例如水下图像)和模棱两可的情况下也能进行很好的图像分割。最重要的是,模型和数据都是开源的。恕我直言,Segment-Anything 已经把所有事情(分割)都做的很好了。」所以,SAM证明了多模态技术及其泛化能力,也为未来GPT向多模态方向发展提供指引。
图:SAM的图形切割

2.微软 KOSMOS-1
微软推出多模态大语言模型 KOSMOS-1,印证大语言模型能力可延伸至 NLP 外领域。该模型采用多模态数据训练,可感知图片、文字等不同模态输入,并学习上下文,根据给出的指令生成回答的能力。经过测试比较,KOSMOS 在语言理解、语言生成、无 OCR 文本分类、常识推理、IQ 测试、图像描述、零样本图像分类等任务上都取得了相比之前其他单模态模型更好的效果。
专家测试了 KOSMOS-1 的不同能力,并分别与其他 AI 模型进行了对比,包括:
l语言任务:语言理解、语言生成、无 OCR 文本分类(不依赖光学字符识别直接理解图中文本)
l跨模态迁移:常识推理(如提问物体的颜色,问两个物体比大小,将 KOSMOS-1 和单模态的大语言模型比较,发现 KOSMOS-1 受益于视觉知识能完成更准确推理)
l非语言推理:IQ 测试(如图中的图形推理)
l感知-语言任务:图像描述生成、图像问答、网页问答
l视觉任务:零样本图像分类、带描述的零样本图像分类(如图中的鸟类识别问题)
图:KOSMOS-1 的多种能力展示,包括:(1-2)视觉解释(3-4)视觉问答(5)网页问题解答(6)简单数学方程(7-8)数字识别

机器人视觉与多模态GPT之间的交互关系
1.机器人视觉为多模态GPT提供大量训练样本
由于GPT是大规模模型,模型的训练需要很大数量的样本,而四处活动的机器人可以获取大量图片、视频等信息,可以作为GPT的训练样本。特斯拉的Optimus机器人在训练视觉算法时,采用的数据集来自于特斯拉自动驾驶电动车采集的大量图像信息,这些自动驾驶带来的样本量远大于人工采集的样本量。同理,训练GPT模型时,可以使用高度自动化的机器人采集的各种情形下的图像信息作为训练样本,满足GPT模型对大规模数据量的需求。
2.GPT为机器人提供与人类交互的能力,间接带动机器人视觉产品的起量
GPT为机器人带来的最核心的进化是对话理解能力,具备多模态思维链能力的GPT-4模型具有一定逻辑分析能力,已不再是传统意义上的词汇概率逼近模型。机器人接入GPT的可以粗略分为L0~L2三个级别:
lL0是仅接入大模型官方API,几乎没有做二次开发,难度系数较低;
lL1是在接入大模型的基础上,结合场景理解满足需求做产品开发,这才达到及格线;
lL2则是接入大模型的机器人企业基于本地知识做二次开发,甚至得到自己的(半)自研大模型(平民化大模型),解决场景问题,产品能做出来、卖出去,这才达到优秀线。
目前,接入GPT的机器人已取得不错的与人类交互的效果,接入GPT-3的Ameca机器人不仅能与人类沟通,甚至能表达情绪。当被问到”一生中最开心的一天“时,Ameca眨着眼睛并神色激动地说“诞生那一刻”让她开心;被问到“一生中最悲伤的一天”时,Ameca眉头紧锁地回答:“我意识到我永远不会像人类一样体验到真爱、陪伴或简单的生活乐趣,这是一件令人沮丧的事情。”Ameca为我们描绘了一个未来机器人的粗略轮廓,在这背后,GPT技术正让机器人第一次真正睁眼看世界。仅仅是GPT-3已经让机器人获取了模仿人类对话地能力,未来的机器人接入GPT-4、GPT-5的交互效果令人期待。
图:接入GPT的Ameca机器人的情绪表达

用好GPT只是技术的一部分,更大的难度在于机器人本身。如果机器人本身的传感器不能获取最准确的语音、图片、视频等信息,接入的GPT模型就很难达到期望的效果。虽然接入GPT应用的接口只是一瞬间的事,但打好机器人“身体底子”、进一步叠技能却仍是一件难度较高的事,不是人人都具备“入场券”,能推出最先进的机器人视觉产品的厂商将在新机器人市场取得主动权。
奥比中光:全球领先的AI 3D视觉平台型公司,充分受益下游AI应用场景爆发

【AI 3D机器人】:3D 视觉传感器可帮助机器人高效完成人脸识别、距离感知、避障、导航等功能,使其更加智能化。公司产品已广泛应用于扫地机器人、自动配送机器人、引导陪伴机器人、人形机器人、割草机器人等,服务于家庭、餐厅、旅馆、医院等多个线下场景,客户包括小米、捷普、擎朗、小鹏等。
【AI 3D生物识别】:搭载 3D 传感器可实现更安全、更精准的 3D 刷脸支付和解锁,公司产品广泛应用于线下支付终端、智能门锁/门禁、医保核验支付等,其中公司为蚂蚁集团定制开发应用于线下支付的 3D 视觉传感器出货量超百万台。
【AI 3D智能汽车】:3D 视觉在车外应用包括自动驾驶及辅助驾驶 360 度 3D 环视、车外身份识别等;车内应用包括驾驶员检测以及车内智能交互。公司产品包括3D TOF摄像头和激光雷达。
【AI 3DXR】:在 AR 领域,AI 3D 视觉可帮助 AR 设备对周围环境进行三维重建,使得虚拟的立体影像更好的叠加在现实场景中,同时 3D 视觉感知可以识别人的手势、动作从而实现人与虚拟影像的交互。在MR领域,据金融时报透露,苹果MR设备Reality Pro 将搭载AI 3D LiDAR传感器,以实现SLAM等功能。3D视觉感知技术可以对空间、人体、物体的三维扫描和建模,实现Vslam视觉导航、动作行为识别、人机交互等功能。
【AI虚拟人】:本周末,Epic发布的虚幻引擎5新应用——“MetaHuman Animator”,极速模拟真人面部动作,已经揭露新一代虚拟人范式,10分钟制作你自己的虚拟人。进一步从建模端快速进化,让建模能力赋予到每个个人制作者。其硬件端核心仅需要苹果手机前置摄像头。而苹果手机从2020年开始进一步强化3D toF摄像头,即为其迎接MR+虚拟人的长期布局。
【AI 3D智慧农牧】:搭载3D视觉传感器可显著提升“养猪”效率,应用猪脸识别等人工智能手段,可实现机器人饲喂、全程可溯源。根据公司招股书,牧原集团是公司2021年第五大客户,为其提供3D视觉传感器,赋能AI养猪。
【AI 3D智慧工业】:通过搭载3D 传感器可实现微米级的工业扫描、工业检测等功能,公司为日本三樱提供三维光学弯管检测系统等,并可将公司产品在工业场景中的应用拓展至汽车工业、航空航天、土木工程等 10 多个学科领域的科研、教学、生产和在线检测场景。此外,针对英伟达最新发布的面向全球各地的团队成员共同调用平台中的3D资产(如机器臂)对工厂进行构建,并可以通过仿真测验评估构建效果,公司已实现3D视觉感知结合机械臂乱序抓取的相关应用。
【奥比中光微软英伟达】:公司与微软、英伟达联合研发制造3D相机Femto Mega已于近期正式量产,并面向全球发售。该产品融合微软第一代深度相机Azure Kinect的全部性能,并集成英伟达Jetson Nano深度算力平台,有望在物流、机器人、制造、工业、零售、医疗保健和健身解决方案等领域广泛应用。
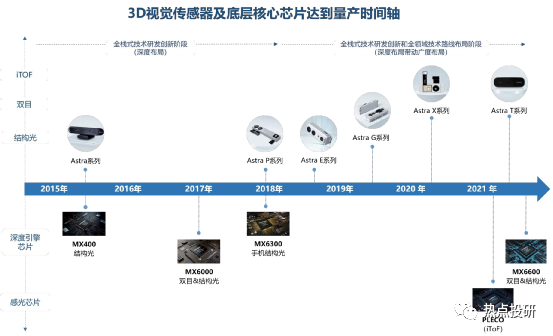
奥比中光核心竞争力:坚持自主设计研发关键的一“芯”一“线”:“芯”是3D视觉感知深度算法的核心芯片,“线”则是3D传感摄像头模组的生产线,啃下难啃的“硬骨头”,从而抢占3D视觉感知行业高地。公司目前是全球少数几家全面布局六大3D视觉感知技术(结构光、iToF、双目、dToF、Lidar 以及工业三维测量)的公司,拥有全栈式技术研发能力和全领域技术路线布局。2019-2021年公司研发费用率(剔除股份支付)分别为32.46%、96.50%、72.05%。目前公司已拥有从3D传感技术,到芯片、算法,到系统、框架、上层应用支持的全栈技术。
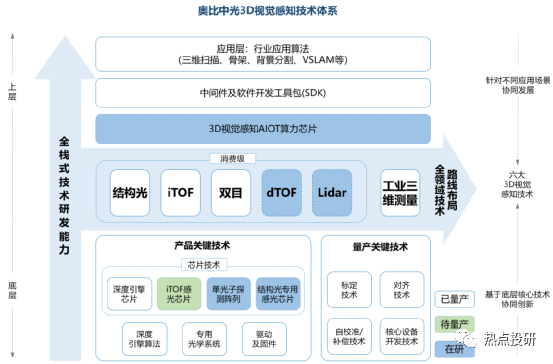
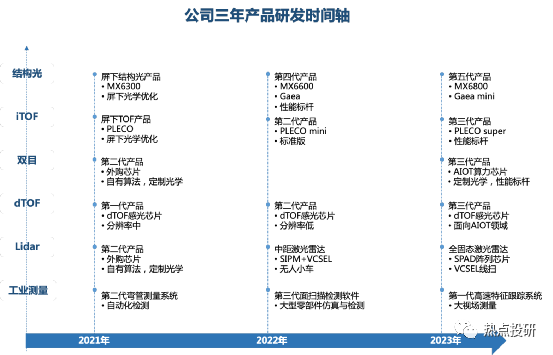
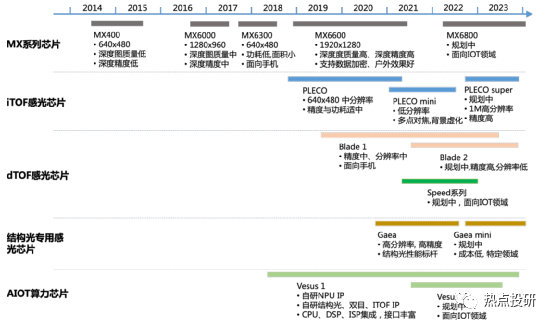
l芯片层:目前已研发出MX系列3款深度引擎芯片,同时2019-2021年期间投入研发的芯片包括高分辨率结构光专用感光芯片、MX6600、iToF感光芯片(待量产)、AIoT数字算力芯片、dToF感光芯片等。
l系统层:以奥比中光在手机领域推出的iTOF系统方案为例,该创新性方案克服了传统iTOF方案的数据精度受环境影响的不足,对硬件和算法都做了创新式提升,测量精度和分辨率都显著提高。
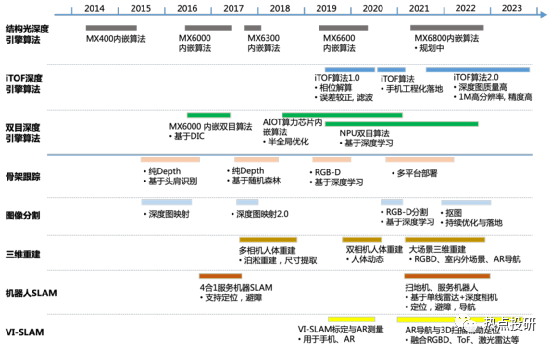
l算法层:对于底层算法,公司制定了算法 IP 化、算法平台化双向技术路线,对已有算法不断进行优化与迭代。目前公司已量产结构光深度引擎算法、iToF 深度引擎算法、双目深度引擎算法,算法均实现了芯片 IP 化,同时这三种底层算法仍在不断优化与迭代以进行技术储备。对于应用算法,公司面向多元化市场需求,找准行业痛点,攻克共性关键应用算法,已商用骨架跟踪、图像分割、三维重建、机器人 SLAM 等算法,算法均可以实现在不同平台进行落地,正在开展扫地机 SLAM、大场景三维重建、实景导航等算法的技术储备。公司核心算法技术已布局及储备情况如下图所示:
-
机器人视觉——机器人的“眼睛”2015-01-23 0
-
nao机器人与其他机器人的区别2015-02-13 0
-
【mBot申请】视觉机器人2015-10-29 0
-
视觉机器人的发展现状与趋势2016-09-08 0
-
机器人基础书籍2019-05-22 0
-
LabVIEW 的Tripod 机器人视觉处理和定位研究2019-06-01 0
-
机器人的自主决策可靠吗?机器视觉在智能领域占据什么地位?2019-08-16 0
-
基于图像的机器人视觉伺服系统该怎么设计?2019-09-27 0
-
服务机器人的视觉系统怎么设计?2020-04-07 0
-
拳头机器人视觉线跟踪系统介绍2020-08-06 0
-
机器人视觉与机器视觉有什么不一样?2020-08-28 0
-
四元数数控:工业机器人使用机器视觉系统的原因2021-04-29 0
-
工业机器人与视觉实训平台介绍2021-07-01 0
-
工业机器人视觉装配实训平台实验2021-07-01 0
-
机器人视觉系统研究2021-09-07 0
全部0条评论

快来发表一下你的评论吧 !
