

ChatGPT的潜力和局限
描述
今天为大家分享一篇研究,当ChatGPT穿越到口袋妖怪世界,是否会理解并应用这个虚构世界的知识呢?
熟悉口袋妖怪的朋友们一定知道,这些可爱的生物们有着各种不同的属性、类别和技能。它们生活的世界也是一个完整的环境:你可以收集口袋妖怪、培养它们的实力,然后让它们在战斗中一展身手。每一个系统都有详细的、明确的规定。
而现在,我们把这个酷炫的口袋妖怪世界作为评估ChatGPT知识和推理能力的环境!我们可以检查ChatGPT对口袋妖怪世界的了解程度,并向它输入新的知识,让它在妖怪们的战斗中进行推理,预测战斗结果。
通过在口袋妖怪世界的实验,我们能更好地评估ChatGPT的潜力和局限,看看它是否能够学习新知识,基于特定情境的特征组合进行推理,从而做出更准确的判断。
为了评估ChatGPT,作者引入了一个分阶段的对话框架(如下图),包括三个明确定义的阶段:
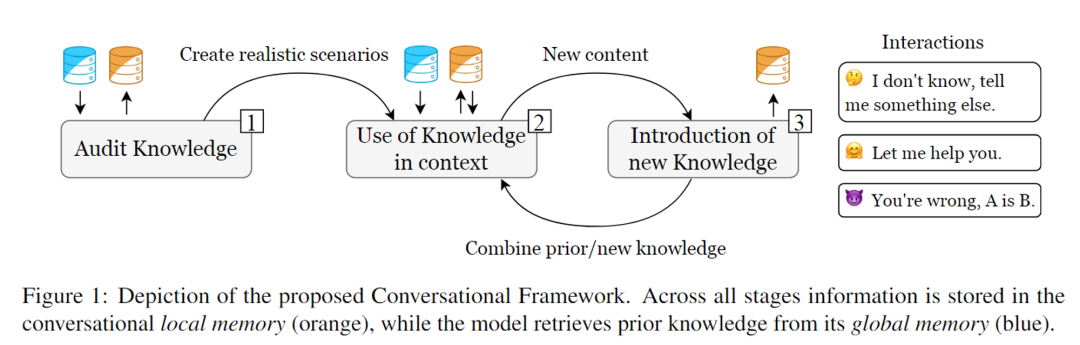
阶段1:Audit knowledge
首先,ChatGPT具有口袋妖怪世界的背景知识吗?
作者通过询问一般性问题,如有关口袋妖怪类型和物种的描述,来审核ChatGPT对口袋妖怪世界的先验知识。这些检索到的知识被存储在local memory中,作为对话的上下文,以便在接下来的步骤中构建合理的场景。同时,这些知识还可以提高后续模型的回应准确性,减少虚构情况的发生。
在阶段一,作者从一些初步的一般性问题开始。这个阶段对于随后创建有效的沟通至关重要。我们区分global memory和local memory。前者是在训练期间获得的,包括ChatGPT的先验知识。local memory仅限于我们之前的相互作用,并作为后验相互作用的参考点。ChatGPT对口袋妖怪类型等问题上有很强的抵抗能力。但在Q1.4中的对抗提问中失败了。
下面是一个例子:注意ChatGPT的答案用颜色标记,如果提供准确的知识,则用绿色,如果提供虚假陈述(幻觉),则用红色,如果陈述模糊或不相关,则用黄色。

阶段2:Use of knowledge in context
作者呈现了特定的战斗场景,其中口袋妖怪们的类型、等级、招式和状态相互作用并导致特定的结果。ChatGPT将用于预测战斗的结果,并逐步解释其推理过程。这个阶段将评估模型是否能够基于特定情境(上下文)组合特征(组合性),从而确定战斗结果。
在阶段二,作者呈现了口袋妖怪的简单战斗场景,并逐渐增加复杂性(不同级别、天气和状态条件),并要求ChatGPT预测战斗的结果并解释其推理。这一阶段将帮助我们理解模型是否可以基于决定其结果的特定场景(上下文)组合特征(组合性)。
结果发现,大多数回答都是准确的。ChatGPT了解口袋妖怪的类型、移动(攻击)和等级如何影响战斗匹配。ChatGPT能够预测,也可以全面地解释其推理。但是,不同类型的问题上,ChatGPT的准确性差异较大。
作者总共测试了24场战斗:6场涉及不同类型(准确率为83.3%),6场涉及不同级别(100%),7场涉及4种天气条件(85.7%),6场涉及4种状态效果(100%)。
作者介绍了具有正式规格(名称、外观、类型、招式)的新妖怪。然后,要求ChatGPT验证对这些新概念的掌握,并将其与其先前知识进行比较。注意,ChatGPT将新引入的知识存储在local memory中,但它将无法长时间引用它。
下面是一个测试例子:注意ChatGPT的答案用颜色标记,如果提供准确的知识,则用绿色,如果提供虚假陈述(幻觉),则用红色,如果陈述模糊或不相关,则用黄色。
尽管在问题4.1中出现了部分幻觉,ChatGPT给出了相当好的类比。作者进一步评估新知识在语境中的整合,测试了新的与已知的口袋妖怪的战斗。结果表明,ChatGPT能够重用先验和新引入的知识来预测结果,即使涉及的两个口袋妖怪都是新引入的。在这种情况下,模型给出了可靠的预测。
通过与ChatGPT在对话框架下的互动,可以得出以下结论:首先,模型所呈现的事实的准确性取决于之前讨论的内容;其次,对抗性攻击可能是成功的,但并不总是成功的,但一般来说,对话预处理(知识检索)和协作反馈可以纠正先前模型的错误。
责任编辑:彭菁
-
【国产FPGA+OMAPL138开发板体验】(原创)6.FPGA连接ChatGPT 42024-02-14 0
-
在FPGA设计中是否可以应用ChatGPT生成想要的程序呢2024-03-28 0
-
OpenAI 深夜抛出王炸 “ChatGPT- 4o”, “她” 来了2024-05-27 0
-
让chatGPT帮我写硬件代码,是懂行的,好助手!#chatgpt #物联网开发 #python开发板苏州煜瑛微电子科技有限公司 2023-02-17
-
ChatGPT对话语音识别YS YYDS 2023-05-30
-
栅漏电流噪声有哪几种模型?这几种模型具有什么特性和局限性?2021-04-14 0
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 0
-
不到1分钟开发一个GPT应用!各路大神疯狂整活,网友:ChatGPT就是新iPhone2023-11-19 0
-
基于微控制器的LED驱动器拓扑、权衡和局限2011-10-26 909
-
法国研究超薄太阳能电池的潜力和局限性,未来应用将不受限制2020-11-16 1737
-
ChatGPT在自然语言处理中的局限性和挑战2023-04-18 1413
-
碳化硅二极管的优点和局限性分析2023-12-21 2589
-
超导材料在输电领域的应用前景、优势和局限性2024-01-17 1557
-
WDM技术的缺点和局限性2024-08-09 772
-
ChatGPT 适合哪些行业2024-10-25 441
全部0条评论

快来发表一下你的评论吧 !
