

大模型如何助力AIOps以保证高可靠的服务?
电子说
描述
十多年来,微软提供了世界上最流行的超大规模生产力套件之一,Office 365,它现在是Microsoft 365的一部分。微软365包括数百种不同的服务,在全球数十个数据中心的数十万台服务器上每秒运行数十亿次事务。它为数以亿计的企业、教育和消费者用户提供日常云服务。
这些服务永远不会停止。我们的服务被医院和创伤中心、电网提供商、国家、州和地方政府、主要银行和金融服务提供商、航空公司、航运和物流提供商以及从最大到最小的企业所使用。为了满足他们的需求,我们必须持续可用,这意味着在很长一段时间内100%可用。我们的服务应该在灾难中无缝运行,因为灾难往往是我们的服务最重要的时候;协调应急工作。
这是一个巨大的挑战。我们的极端规模意味着,在我们的服务中,“十亿分之一”的事件并不罕见,而是司空见惯。同时,我们不能允许那些“十亿分之一”的事件损害我们服务的可用性。这种几乎令人难以置信的大规模和极端临界的组合要求我们不断地重新思考和改进服务架构、设计、开发和运营的各个方面。实现持续可用性和高可靠性服务的一个重要方面是全面理解事件并减轻它们对客户的影响。
除了使用人工智能(AI)和机器学习(ML)来开发新的生产特性和功能,以取悦我们的用户,我们还利用人工智能和机器学习的力量来提高服务的可用性和可靠性,这对我们的超大规模服务至关重要。本文展示了将AI应用于管理生产事件生命周期的一个示例。我们计划在以后的文章中分享更多示例。
——Jim Kleewein, Microsoft 365技术科学家
1. 介绍
微软365(“M365”)是世界上最大的生产力云。成千上万的各种规模的组织都在使用它。无论您是在召开团队会议,在Outlook中编写电子邮件还是与同事协作处理Word文档,您都可以依靠M365来支持这些生产力工具和应用程序。M365由网络规模和大规模分布式云服务提供支持,由全球几十个数据中心、每个中心数十万台服务器处理艾字节(exabytes)量级的数据。
为了确保一流的生产力体验,我们的工程基础设施在高效的同时高度可靠是至关重要的。 在M365系统创新研究小组,我们利用人工智能(AI)的力量,将云智能和AIOps集成到我们的服务和产品中。我们正在使用创新的AI/ML技术和算法来帮助设计、构建和运营复杂的云基础设施和服务,并在运营效率和可靠性方面提供逐步改进的功能,使我们能够提供一流的生产力体验。我们正在将AIOps应用于以下几个领域:
系统AI使智能成为一种内置能力,在较少人为干预的情况下实现高质量、高效率、自我控制和自适应。
客户利用AI/ML创造无与伦比的用户体验,并通过云服务实现卓越的用户满意度。
AI for DevOps将AI/ML注入到整个软件开发生命周期中,以实现高开发人员生产力。
帮助构建高度可靠的云服务一直是我们关注的重点领域之一。其中一个挑战是快速识别、分析和缓解事件。我们的研究从生产事件的基础开始:我们分析事件的生命周期,了解常见的根本原因、缓解措施和解决方案的工程效益。
2. 了解生产事故
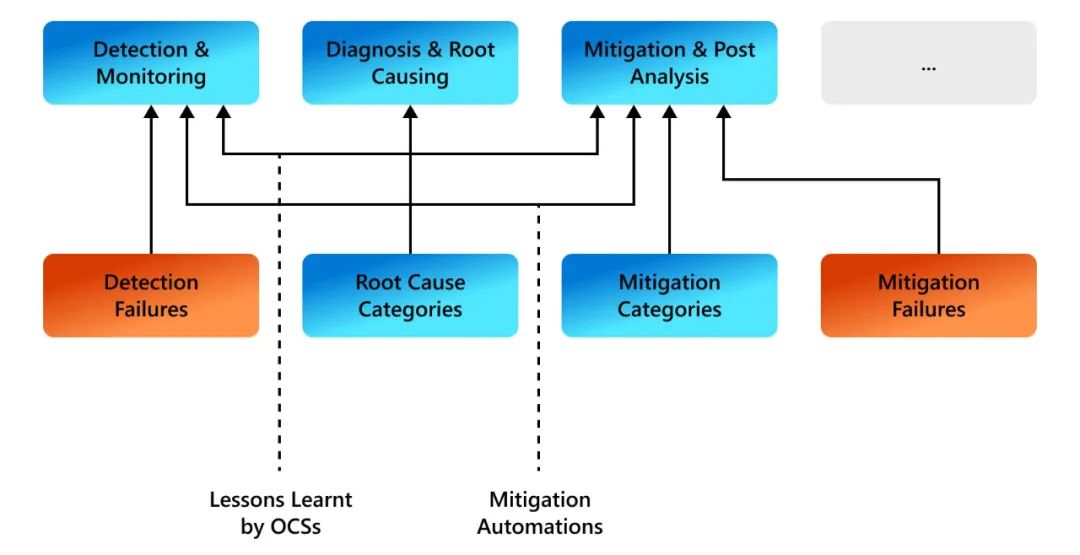
图1 大规模云服务中服务可靠性问题概述 我们的获奖论文[1]对Microsoft Teams使用的大规模M365云上的生产事件进行了全面的多维实证研究。由于Microsoft-Teams支持实时通信,因此可靠性至关重要。从检测、根因和缓解的角度理解生产事件,是构建更好的监控和自动化工具的第一步。图1显示了大规模云服务的服务可靠性问题概述,来源于我们研究论文[1]的总结。
1) 事件背后的常见根本原因和缓解措施
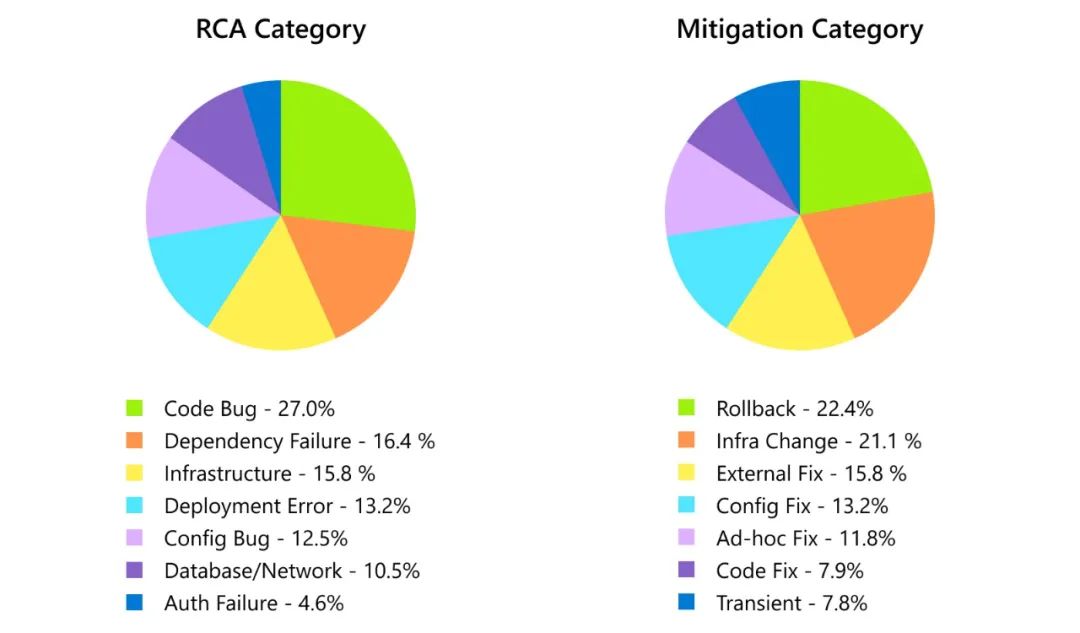
图2 根本原因分析(RCA)和风险缓解类别的细分 虽然代码错误是最常见的事件原因,但大多数事件(约60%)是由基础设施、部署和服务依赖关系中的非代码/非配置相关问题引起的。我们还观察到,在由代码/配置错误引起的40%的事件中,近80%的事件在没有代码或配置修复的情况下得到了缓解。
2)TTD和TTM的根本原因和缓解措施
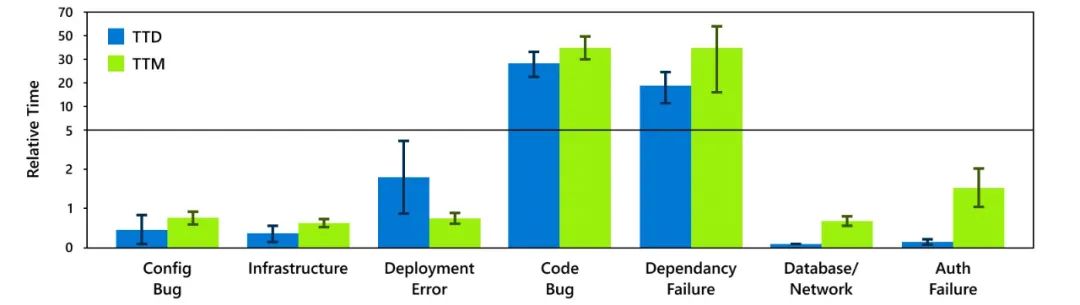
图3 不同根本原因类别的平均TTD和TTM
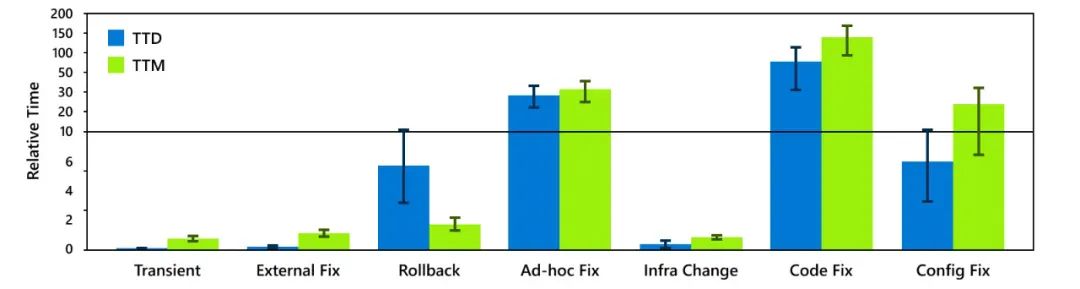
图4 不同缓解步骤的平均TTD和TTM 由代码错误和依赖失败引起的事件的TTD和TTM明显高于其他事件。此外,30%的缓解延迟是由手动缓解步骤造成的。 3)小结
由于监控不力,软件bug和外部依赖导致的事件检测时间较长。这凸显了对实用工具的需求,以实现细粒度、原位系统可观测性。
某些根本原因类别导致的事件在确定其根本原因类别后会迅速缓解。这表明,使用能够快速识别其根本原因类别的工具,可以缩短由这些类别引起的事件的总体缓解时间。
由某些根本原因引起的事件本身就难以自动监控(例如,需要监控全局状态)。这表明开发人员应该在测试中投入更多,以便在生产前发现这些根本原因类别,从而避免此类事件。
我们还设想,自动化将在未来用于进行事件诊断并确定根本原因和缓解步骤,以帮助快速解决事件并最大限度地减少客户影响。此外,我们应该利用过去的经验教训,建立应对未来事件的韧性。我们假设采用AIOps和使用最先进的ML模型,如大型语言模型(LLM)可以帮助实现这两个目标。
3. 使用LLM进行自动事件管理
最近人工智能的突破使大语言模型(LLM)对自然语言有了丰富的理解。他们已经变得善于从大量数据中理解和推理。它们还可以泛化各种任务和领域,如代码生成、翻译、问答等。考虑到事件管理的复杂性,我们有动力评估这些LLM在帮助分析根本原因和减轻生产事件方面的有效性。
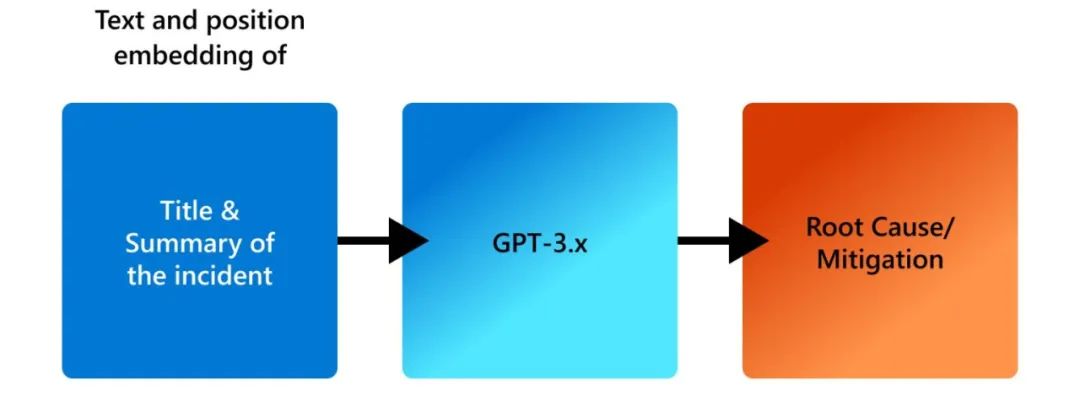
图5 根因分析和风险缓解中充分利用GPT-3.X的能力 在最近的工作中,我们在ICSE 2023会议上首次展示了LLM对生产事故诊断的有用性。当创建一个事件时,作者将为事件指定一个标题,并描述任何相关细节,如任何错误消息、异常行为和其他可能有助于解决的细节。我们使用给定事件的标题和摘要作为LLM的输入,并生成根本原因和缓解步骤。
我们对4万多起事件进行了认真的研究,并比较了几家LLM在零样本(zero-shot)、微调(fine-tuning)和多任务设置下的表现。我们发现,对GPT-3和GPT-3.5模型进行微调后,可以显著提高LLM 处理事件数据的有效性。
1)在根因分析中GPT-3.x模型的有效性
表1 不同LLM的词汇和语义性能
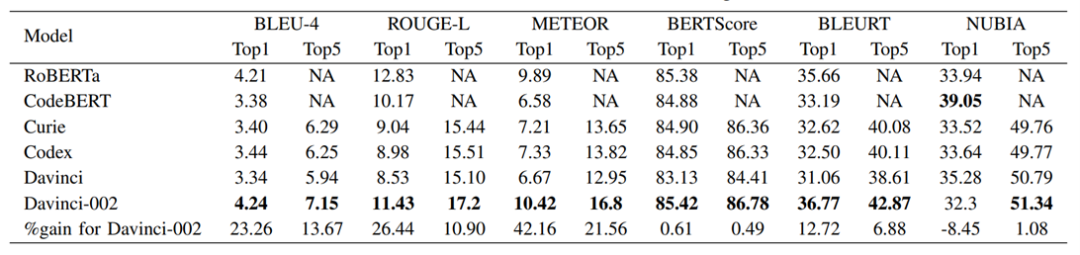
在离线评估中,我们通过计算生成的建议与事件管理(IcM)系统中提到的根本原因或缓解步骤的基本事实之间的3个词汇相似性进行度量,将GPT-3.5与三个GPT-3模型的性能进行了比较。不同任务的GPT-3.5指标的平均增益如下:
对于根本原因和缓解建议任务,davincici-002 (GPT-3.5)比所有GPT-3模型分别提供至少15.38%和11.9%的增益,如表1所示。
当我们通过将根本原因作为输入添加到模型中来生成缓解计划时,GPT-3.5模型比3个GPT-3模型至少高出11.16%。
我们观察到,由于MRI(Machine Reported Incidents,机器报告的事件)的重复性,LLM模型在MRI上比客户报告的事件(Customer Reported Incidents,CRIs)上表现更好。
使用事件数据对LLM进行微调可以显著提高性能。优化后的GPT-3.5模型在根本原因生成任务中提高了45.5%,在风险缓解生成任务中提高了131.3%(即直接在预训练的GPT-3或GPT-3.5模型上进行推理)。
2)从事件所有者的角度看问题
除了使用语义和词汇度量进行分析分析外,我们还采访了事件所有者,以评估生成的建议的有效性。总体而言,GPT-3.5在大多数指标上都优于GPT-3。在实时生产环境中,超过70%的OCEs给出了3分或以上的评分(满分5分)。
4. 展望
虽然我们正处于使用LLM来帮助自动化事件解决的初始阶段,但我们设想在这个领域有许多开放的研究问题,这些问题将大大提高LLM的有效性和准确性。例如,我们如何结合关于事件的其他上下文,如讨论条目、日志、服务度量,甚至受影响服务的依赖关系图,以改进诊断。
另一个挑战是数据过时(staleness),因为模型需要经常使用最新的事件数据进行重新训练。
为了解决这些挑战,我们正在利用最新的ChatGPT模型结合检索增强方法,通过会话界面改进事件诊断。例如,ChatGPT可以通过提出假设,并通过反馈循环回答关键问题,帮助工程师有效地确定事件的根本原因。
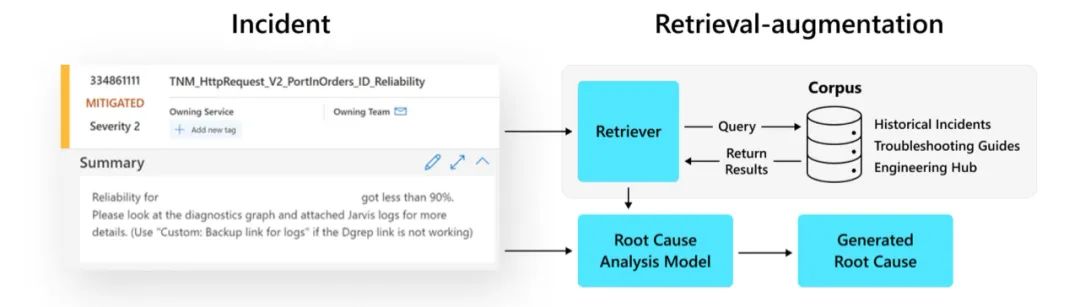
图6 检索增强RCA的工作流程
此外,ChatGPT可以积极地融入到事件诊断的“讨论”中。通过从可用的文档和日志中收集证据,该模型可以对查询生成连贯的、上下文相关的、听起来自然的响应,并提供相应的建议,从而促进讨论,并加速事件解决过程。我们相信,通过上下文和有意义的根本原因分析和风险缓解,这有可能在整个事件管理过程中实现逐步功能改进,从而减少大量人力劳动,提高我们的可靠性和客户满意度。
审核编辑:刘清
-
基于CMMI-ACQ的信息技术和服务安全采购模型2010-04-24 0
-
【可靠性分析第一步】构造可靠性模型2016-09-03 0
-
如何保证FPGA设计可靠性?2019-08-20 0
-
电动助力转向EPS——理论公式推导及simulink模型2021-06-29 0
-
如何保证PCB孔铜高可靠?水平沉铜线工艺了解下2022-12-02 0
-
高防服务器的优势2023-03-21 0
-
高可靠多层板制造服务再获认可!华秋荣获创想三维优秀质量奖2023-04-14 0
-
华秋亮相汽车电子研讨会,展出智能座舱方案、高可靠PCB板2023-06-16 0
-
基于冗余的指挥业务组合服务可靠性评价模型2017-11-16 785
-
AIOps工具在IT领域具有广阔的应用前景2020-07-17 1741
-
AIOps成电信行业智能化方向,华为AIOps服务四大核心价值2020-09-26 1500
-
对于IT操作的AIOps见解,及其10大应用方向与其目标和优势2021-03-04 2620
-
什么是AIOps及AIOps的3大好处2022-01-30 8117
-
音乐分离AI模型研发成功,浪潮信息以AI算力服务助力2023-04-25 1399
-
英特尔助力京东云用CPU加速AI推理,以大模型构建数智化供应链2024-05-27 543
全部0条评论

快来发表一下你的评论吧 !
