

NOP+:追求连续的点到点驾驶体验
描述
智能驾驶时代离不开“规控”,但对用户而言,“规控”可能是一个既陌生,却又带有很强技术感知的词语。
本期Tech Talk,由蔚来自动驾驶研发部门规控团队的Blake FAN、Eason QIN,以及全域智能驾驶体验团队的Simon WANG,为我们解读“规控”的开发逻辑,揭秘NOP+增强领航辅助是如何“开车”的。
什么是决策规划控制算法?
规控的全称——决策规划控制算法,对外简称“规控”,它是智能驾驶系统的核心组成部分之一。
Aquila蔚来超感系统,
拥有包括超远距高精度激光雷达
在内的33个高性能感知硬件
如果把Aquila蔚来超感系统比喻为智能驾驶系统的眼睛,那么规控就是智能驾驶系统大脑一般的存在。它的职责,是负责安全且平稳地驾驶车辆,让用户享受轻松、愉悦的出行体验。
简单而言,规控算法决定了自车应该何时让行切入车辆、何时变道,以及何时进出匝道;这些驾驶行为指令会传递给车辆控制端,实现细腻的、毫秒级的方向盘转角以及加减速控制。
因此,规控的聪明程度也决定了智能驾驶系统的舒适性和通行效率的平衡。
如何成为一个优秀的规控算法?
智能驾驶系统能够像人一样实现自如地开车,至少需要满足两个条件。
第一,是否能够像人一样获取周围的环境信息;第二,则是构建像人一样的思考方式和驾驶行为。
NOP+增强领航辅助功能开启状态
关于智能驾驶系统对自车周围环境的感知,可以在《蔚来眼中的世界,有多特别?》这篇文章里找到答案。不过要让其构建像人一样的思考方式,就需要投入研发精力,至少做到以下两点。
第一,理解什么是优秀的驾驶行为。
优秀的驾驶行为由诸多要素组成,其中最重要的就是安全。智能驾驶状态下的车辆,需要在复杂的环境中保持和其他交通参与者安全的交互,尽可能地平稳驾驶,并且高效的到达终点。因此,安全、平稳和高效,这三点就成为了智能驾驶规控模块的开发目标。
第二,构建类人的驾驶思考方式。
这一点尤为重要。智能驾驶系统需要模仿人类驾驶员的思维方式,比如在获知驾驶目的地信息(导航),当前所处位置(定位),和周围环境信息(地图,感知)后,要进行分层级思考。
这个思考的过程可以分为三个阶段,比如思考是否该进行超车、让行、换道的决策规划阶段;思考安全、舒适、高效的运行轨迹规划阶段;以及车辆如何执行指令的控制阶段。
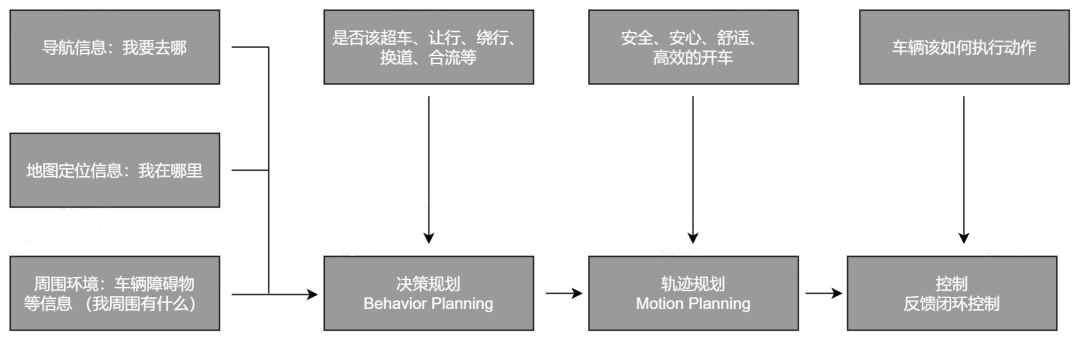
智能驾驶系统规控工作流
基于上述三个层级的思考,接下来为大家展开详细聊一聊。
首先,我们来拆解决策规划(Behavior Planning)。NOP+的决策规划不仅包含对周围其他交通参与者行为的预测,也包含自车行为对周围环境造成的影响。对所有这些自身和其他因素进行整体建模,便构成了NOP+的决策预测一体化。
好比棋手对弈,我们无法百分百精确预测对手下一步到底会怎么走,但通过对棋局当前形势的推演,优秀的棋手知道怎么出手会获得更高的胜率。因此,智能驾驶系统的决策目标就是更加细致、深入地判断“棋盘的‘势’”,即形势和收益。
为了能得到更高的胜率,智能驾驶车辆需要精确的识别与认知周围环境——类似棋盘中棋子的摆放位置;以及和障碍物之间的博弈关系——下这步棋后对手会怎么落子;在思考完成后需要在有限时间里选择合适的响应行为——下棋的策略。
在下面这个换道场景中,NOP+的算法在识别到前方慢车以及左方、右方和后方的车辆、环境信息后,会“观察形势”,推演执行不同驾驶行为可能发生的结果。

这就是“博弈推演”,权衡利弊后,最后以安全、舒适的方式完成换道。
NOP+的决策算法需要考虑环境中所有可能发生交互的障碍物,当环境发生变化时,交互决策需要考虑的因素将会以指数级别增加。
比如在当前时刻,有10个障碍物需要考虑是否避让,那么决策的复杂度是2^10=1,024;在接下来(1秒、2秒......5秒)的每一个时刻是否要进行避让时,复杂度将会变成1,024^5,大约是10^15。
优秀的司机往往能够通过预判性驾驶来降低风险,提高通行效率和舒适性。因此,思考得越深,NOP+的驾驶行为预判就越好。
一个优秀的棋手,每次落子前大约会推演5-8个回合的“博弈”,而智能驾驶需要在<0.1秒的时间内完成更复杂的推演。为了能在超过10^15量级的策略中快速找到最优解决方案,除了更强的硬件算力,更重要的是NOP+规控算法的设计与提升。
事实上,NOP+的决策算法用百万量级的自动驾驶数据进行不断的训练学习,总结出“定势”并记录下来,从而在决策树中实现快速精准的搜索。我们将这个过程称为:价值网络学习(Deep Learning Policy Network),即通过深度学习网络,去学习优秀司机对于驾驶交互的判断逻辑。
随着系统硬件能力的提升和数据的积累,在NOP+决策系统中考虑的因素也会更加的细化,从而能在千变万化的世界中寻找出最优的决策。
在拆解决策规划后,我们来看看运动轨迹规划(Motion Planning)是如何工作的。
当车辆得到最优决策后,运动轨迹规划模块需要将其转化为车辆可以执行的行驶路径。一个好的行驶路径需要在安全的条件下尽量优化路径的安全度,平滑性以及通行效率。
比如以下拥堵场景跟停的场景中,车辆在规划合理的刹车力度时,不仅需要考虑前车的距离,也要尽可能的优化减速度的变化幅度,做到安全平稳舒适的刹停和起步(如Gif图中左下方平滑的蓝色加减速曲线)。

优秀的驾驶是在安全、遵守交通规则的前提下,尽量在效率和舒适中达到平衡。但是在不同场景中,效率和舒适的平衡又是不一样的。
比如北京、上海的道路和乡村道路就很不一样。在拥堵环境下,普通的城市道路和环路、高架又有很大区别。因此需要通过数据分析更深层次地理解周围环境,在诸多因素中自适应地去调节平衡关系。
例如,在Banyan 2.0.0的拥堵跟车场景中,系统通过大量数据学习老司机开车的驾驶方式,从而获得安全、平稳、舒适的驾驶体验,随着数据的积累,体验还可以不断进化。
最后一个层级,则是对指令的控制(Control)。在系统做出运动轨迹规划后,需要控制让车辆按照预判完成相应的动作。“控制”会系统性闭环考虑车辆的运动状态,以便更好地执行指令,达到“手脑一致”。
NOP+:追求连续的点到点驾驶体验
传统的辅助驾驶研发,往往以单一功能为原点(例如大家熟悉的ACC自适应巡航,LKA车道保持辅助,LCC车道居中辅助等),实现特定场景下的辅助驾驶。
但是,做好每一个单点功能,是否就能够算智能驾驶?答案是否定的,现实远比想象的更难!
首先,现实中的场景往往更复杂,要求有多个单点功能的组合。试想一下人类的驾驶行为,变道时目标车道有前后车的情况下,不仅仅要考虑变道的空间是否足够,还需要考虑前后车未来的运动轨迹和速度变化。

除了思考复杂的道路场景,
NOP+还会根据天气因素来控制车速,
安全始终是摆在首位的
如果此时第三车道也同时有车变道汇入呢?如果变道发生在汇入口附近呢?多种场景组合在一起会让功能开发的复杂度呈现指数型的上升。
其次,场景变化存在连续性。单点开发的功能往往存在功能或状态的离散变化,在适配体验的过程中衔接并不连续。比如,单点开发上下匝道会由于状态的切换导致成功率下降。
NOP+通过整体开发统一建模的方式克服了上述痛点。就好像2000年初的手机智能化,厂商往往以某一个功能,如发短信、打电话、玩游戏、发邮件的角度进行功能开发,而今天大家显然聚焦在打造一个高效互通的平台系统上。
实际上,我们就致力于将规划控制模块打造成类似的平台。它能够覆盖更多的功能,接受不同的感知源输入,在硬件不断迭代和数据不断积累的基础上,还能让规划控制算法自主进化和学习,为适配更复杂的驾驶场景提供底层原子化的能力和操作系统。
通过解读“规控”的开发逻辑,不难发现,一套优秀的规控算法能为智能驾驶系统赋予思考逻辑,这也是NOP+能够脱颖而出的关键。
最后,再分享一组数据给大家。截至2023年8月,NOP+累计使用里程超过8,300万公里,当下它正以每周超过500万公里的速度快速“成长”。
NOP+的目标很清晰,就是为用户在日常通勤及长途出行中,提供更安全、轻松、愉悦的驾驶体验。
审核编辑:彭菁
-
点到点和端到端通讯2019-01-18 0
-
高速、多路LVDS交叉开关,减少点到点链路并节省成本2008-10-01 1124
-
基于SIP协议点到点软电话的设计2011-06-01 918
-
传祺汽车实现点对点自动驾驶,车内可打麻将?2016-12-19 1345
-
一文看懂帧中继点到点与点到多点的区别2018-03-02 12537
-
特斯拉最强自动驾驶来了!高速路全程自己开,驾驶员只用打转向2018-10-29 23571
-
基于UDP协议和FPGA的点到点数据传输方案2021-06-01 947
-
备受期待的NOP+来了2023-01-10 1788
-
蔚来正式宣布增强领航辅助NOP+将从高速进入城区2023-09-22 787
-
高精地图在自动驾驶的重要性分析2024-01-18 632
-
小鹏汽车:今年智驾实现国内全范围、点到点,明年研发全球范围XNGP2024-01-31 766
-
蔚来全域领航辅助NOP+已覆盖全国99%城市,验证里程超2024-03-08 613
-
汽车智能化发展重要环节之智能驾驶域控制器2024-04-17 2538
全部0条评论

快来发表一下你的评论吧 !
