

预训练扩散大模型取得点云-图像配准SoTA!
描述
介绍一下我们最新开源的工作:FreeReg: Image-to-Point Cloud Registration Leveraging Pretrained Diffusion Models and Monocular Depth Estimators. 给定部分重叠的图像和点云,FreeReg能够估计可靠的像素-三维点同名关系并解算图像-点云相对位姿关系。值得注意的是,FreeReg不需要任何训练/微调!
基于FreeReg估计的准确的同名关系,我们可以把图像patch投影到点云的对应位置:


主页:https://whu-usi3dv.github.io/FreeReg/
代码:github.com/WHU-USI3DV/FreeReg
论文:https://arxiv.org/abs/2310.03420
太长不看(TL,DR):
区别于现有方法利用Metric Learning直接学习跨模态(图像和点云)一直特征,FreeReg提出首先进行基于预训练大模型的模态对齐,随后进行同模态同名估计:
-
Diffusion大模型实现点云到图像模态的统一并构建跨模态数据的粗粒度鲁棒语义特征,
-
单目深度估计大模型实现图像到点云模态的统一并刻画跨模态数据的细粒度显著几何特征,
-
FreeReg通过融合两种特征,无需任何针对图像-点云配准任务的训练,实现室内外图像-点云配准SoTA表现。
任务概述:图像-点云(Image-to-point cloud, I2P)配准

-
输入:部分重叠的图像和点云
-
输出:图像相机相对于点云的位置姿态
-
典型框架:
-
Step I (关键) : 构建图像-点云跨模态一致特征
-
Step II: 基于特征一致性的 pixel(from 图像)-point(from 点云) 同名估计
-
Step III: 基于所构建同名匹配的相对姿态估计 (PnP+RANSAC)
-
-
现有方法往往是:用一个2D特征提取网络提取图像特征;用一个3D特征提取网络提取点云特征;然后根据pixel-to-point对应关系真值通过Metric Learning (Triplet/Batch hard/Circle loss/InfoCE...)的方式训练网络去提取跨模态一致的特征,这存在几个问题:
-
图像和点云存在故有的模态差异:图像-纹理、点云-几何,这给网络可靠收敛带来了困难,而影响特征的鲁棒性(Wang et al, 2021);
-
需要长时间的训练 (Pham,2020);
-
场景间泛化能力弱 (Li,2023)。
-
FreeReg:
-
通过预训练大模型实现模态对齐,消除模态差异,显著提升特征鲁棒性;
-
不需要任何针对I2P配准任务的训练/微调;
-
能够处理室内外等多类型场景。
FreeReg pipeline:

Section I: FreeReg-D
在这一部分,我们首先利用Diffusion大模型将点云对齐到图像模态,然后基于图像模态下的特征进行同名估计。Naive Solution:利用现在图像生成大杀器的ControlNet (Zhang et al, 2023; depth-to-image diffusion model)实现从点云(深度图)中渲染出一个图像,然后和query图像做match不就行了?不行!如下图,一个depth map可能对应各种各样的RGB图像,ControlNet基于点云渲染出来的图像合理,但是和query input image差异忒大,match不起来。
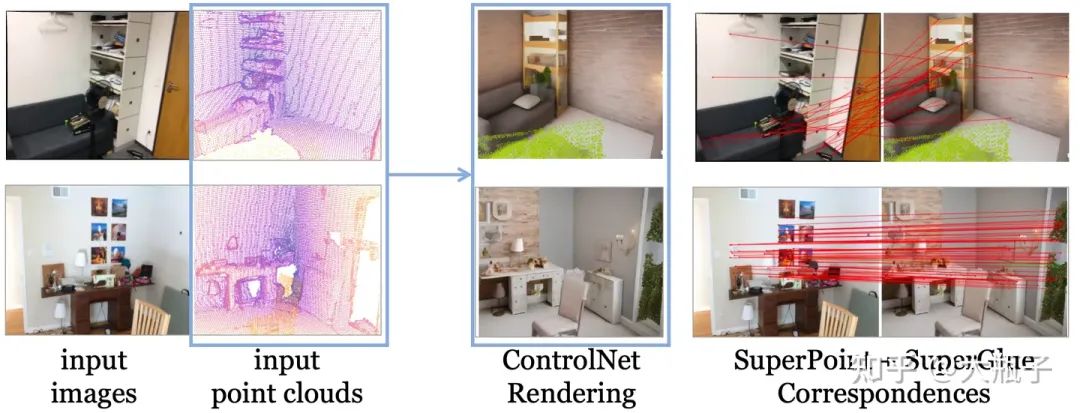
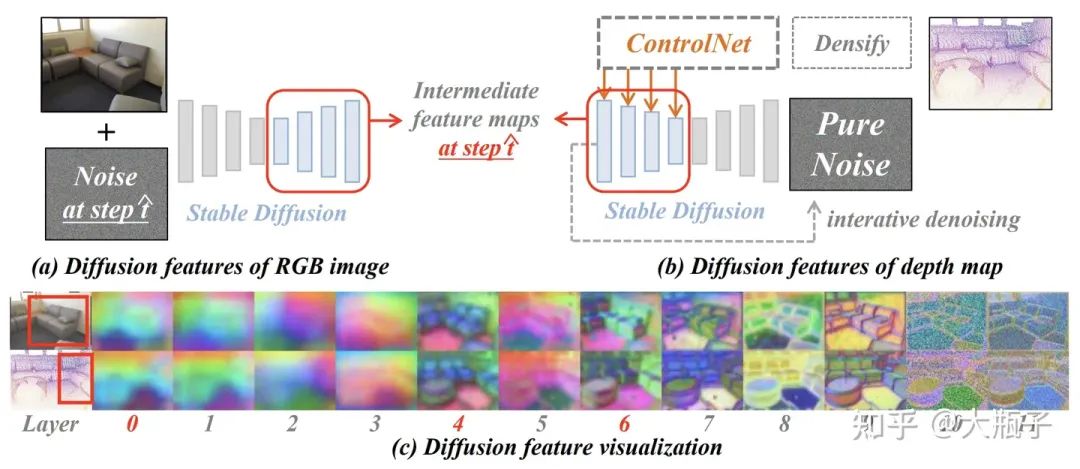
但是,我们注意到,ControlNet虽然生成的纹理和query差异很大,但是语义很正确而且和query RGB是对应的,那么我们怎么提取这种跨模态一致的语义特征呢?受到相关研究的启发(Mingi et al, 2022)一种基于Diffusion大模型的多模特Diffusion Feature
-
RGB image diffusion feature:预训练图像生成大模型Stable Diffusion (SD,Dhariwal et al,2022)能够通过迭代T步去噪的方式从纯噪声生成一张符合某种text-prompt(包含一些代表语义的名词)的图像,证明它能认识、区分和表征这些语义。而我们就把图像加上一些噪声让SD去处理,然后看看哪些SD深层特征具有语义性。
-
Depth diffusion feature:我们用预训练的ControlNet处理来自点云投影的深度图,并基于其引导SD的图像生成(迭代去噪)过程使生成的图像符合深度图,当去噪到某种程度时候我们把SD的中间层特征拿出来,看看哪些特征保证了生成图像不仅符合深度图而且语义性也是对的。
-
如上图的c,我们发现,SD的0-6层输出特征具有可靠的语义性和跨模态一致性!后面的特征才关注纹理。所以我们之用0-6层的特征(我们最终选择concate0,4,6层的特征)作为我们的语义特征就好了,叫做Diffusion Feature!
Section II: FreeReg-G
在这一部分,我们利预训练的单目深度估计网络Zoe-Depth (Bhat et al, 2023)去恢复input RGB的深度,并将其恢复到3D点云分布,然后对RGB恢复的点云和input点云分别提取几何特征(Geometric feature, Choy et al, 2019)用于match。此外,由于match得到的同名关系存在于点云空间,我们的变换估计可以采用Kabsch算法而非PnP方法,Kabsch利用Zoe-depth预测深度的约束可以仅使用3对同名关系就实现变换解算,更高效、更可靠,但是受到Zoe的影响不太精准(具体可以间我们的原文)。
Section III: FreeReg = FreeReg-D + FreeReg-G
在这一部分,我们融合前面在不同模态空间中提取的Diffusion Feature和Geometric Feature,作为我们最终的跨模特特征。如下图所示:

-
Diffusion Feature具有很强的语义相关性和跨模特一致的可靠性,但是因为语义信息关联自图像的比较大的区域,这种大感受野使得基于特征相似性和双向最近邻筛选得到的pixel-to-point同名对准确但是稀疏。
-
Geometric Feature能够关注几何细节构建更加dense的pixel-to-point correspondences,但是很容易受到zoe-depth预测误差和噪声的影响,导致得到的pixel-to-point同名对存在大量的outliers。
-
通过Fuse两种特征(L2 normalization + weighted concatenate, Zhang et al, 2023),FreeReg特征兼具语义可靠性和几何显著性,得到了更加可靠且dense的pixel-to-point correspondences!
实验结果:
定性评价:得益于大模型模态对齐,FreeReg-D/G在没有任何训练和微调的情况下,就在室内外三个数据集上取得了SoTA表现,而FreeReg进一步提升算法表现,取得了平均20%的内点比例提升和48.6%的配准成功率提升!
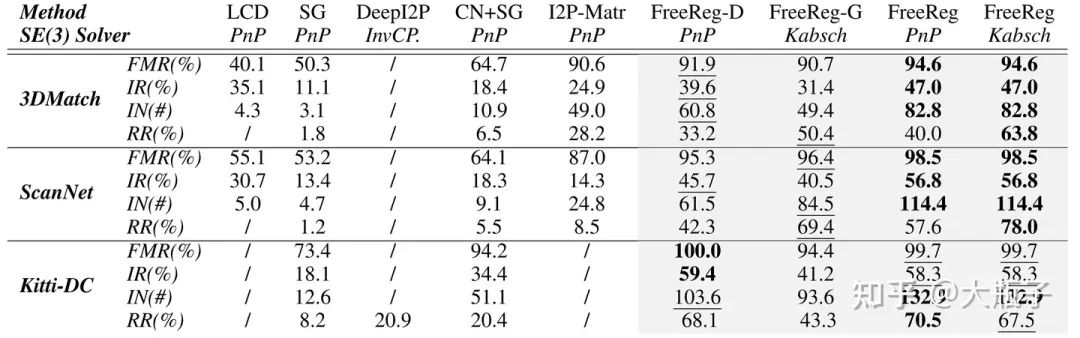
定量评价:

更多的结果:实现细节、消融实验、精度评价、同模态配准表现(也是SoTA!)、和同期工作的比较(FreeReg更优)、尚存问题请见我们的论文!
-
基于多模型表示的高分辨率遥感图像配准方法_项盛文2017-03-19 979
-
基于GPU加速的医学图像配准技术2018-01-03 1014
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 0
-
基于角点的红外与可见光图像自动配准方法2010-05-12 511
-
SAR图像自动配准性能分析2011-04-28 924
-
基于SIFT特征的图像配准(图像匹配)2018-08-06 1380
-
基于SIFT特征的图像配准(仿真图片)2018-08-06 1276
-
基于U-net分割的遥感图像配准方法2021-05-28 759
-
预训练数据大小对于预训练模型的影响2023-03-03 1430
-
什么是预训练 AI 模型?2023-04-04 1448
-
什么是预训练AI模型?2023-05-25 1037
-
基于扩散模型的图像生成过程2023-07-17 2728
-
如何在PyTorch中使用扩散模型生成图像2023-11-22 505
-
预训练模型的基本原理和应用2024-07-03 2805
-
大语言模型的预训练2024-07-11 427
全部0条评论

快来发表一下你的评论吧 !
