

利用GPU加速在Orange Pi 5上跑LLMs:人工智能爱好者High翻了!
描述
本期视频将会给人工智能爱好者们带来超级震撼!
视频中,我们将深入了解利用GPU加速在Orange Pi 5上跑LLMs的精彩世界。最近知乎上的一篇文章《利用GPU加速,在Orange Pi上跑LLMs》引起了我们的注意,这篇文章主要展示了GPU加速的LLM在嵌入式设备上以合适的速度顺利运行。具体来说,是在Orange Pi 5(8G)上,作者通过机器学习编译(MLC)技术,实现了Llama2-7b以2.5 toks/sec的速度运行,RedPajama-3b以5 toks/sec运行。此外,还在16GB版本的Orange Pi 5上以1.5 tok/sec的速度运行Llama-2 13b模型。
下面我们看看他们是如何做到的:
背景
开放语言模型的进步已经催生了跨问题回答、翻译和创意任务的创新。虽然当前的解决方案需要高端的桌面GPU甚至服务器级别的GPU来实现满意的性能。但为了使LLM日常使用,我们想了解我们如何在廉价的嵌入式设备上部署它们。
许多嵌入式设备配备了移动GPU(例如Mali GPU)可以用来加速LLM的运行速度。在这篇文章中,我们选择了Orange Pi 5,这是一个基于RK3588的开发板,与Raspberry Pi相似,但也配备了更强大的Mali-G610 GPU。这篇文章总结了我们首次尝试利用机器学习编译,并为该设备提供了开箱即用的GPU加速。
面向Mali GPU的机器学习编译
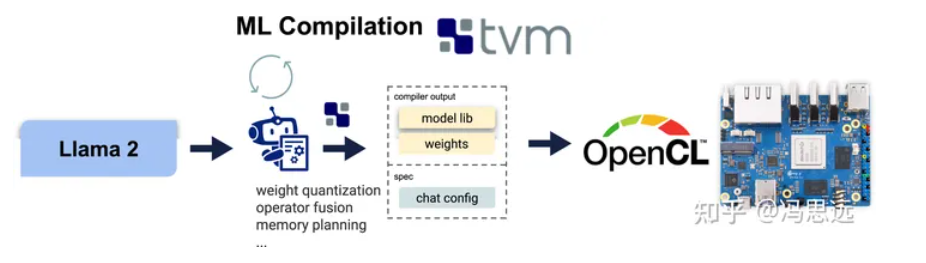
机器学习编译(MLC)是一种新兴技术,它自动编译和优化机器学习工作负载,并将编译后的工作负载部署到广泛的后端。在写作时,基于Apache TVM Unity,MLC支持的平台包括浏览器(WebGPU, WASM)、NVIDIA GPU(CUDA)、AMD GPU(ROCm, Vulkan)、Intel GPU(Vulkan)、iOS和MacBooks(Metal)、Android(OpenCL)以及Mali GPU(本文)。
基于通用机器学习编译实现Mali代码生成
MLC是建立在Apache TVM Unity之上的,这是一个用于在不同硬件和后端上编译机器学习模型的通用软件栈。为了将LLM编译到Mali GPU上,我们复用了所有现有的编译流程,没有进行任何代码优化。更具体地说,我们成功地部署了Llama-2和RedPajama模型,采取了以下步骤:
·复用了模型优化步骤,包括量化、融合、布局优化等;
· 复用了在TVM TensorIR中的定义的通用GPU内核优化空间,并将其重新运用在到Mali GPU;
·复用了基于TVM的OpenCL 代码生成后端,并将其重新运用在到Mali GPU;
·复用了现有的用户界面,包括Python API、CLI和REST API。
运行方法
本节提供了一个分步运行指南,以便您可以在自己的Orange Pi设备上尝试它。这里我们使用RedPajama-INCITE-Chat-3B-v1-q4f16_1作为运行示例。您可以用Llama-2-7b-chat-hf-q4f16_1或Llama-2-13b-chat-hf-q4f16_1(需要16GB的板)来替换它。
准备工作
请首先按照这里的指示,为RK3588板设置OpenCL驱动程序。然后从源代码克隆MLC-LLM,并下载权重和预构建的库。
# clone mlc-llm from GitHub
git clone --recursive https://github.com/mlc-ai/mlc-llm.git && cd mlc-llm
# Download prebuilt weights and libs
git lfs install
mkdir -p dist/prebuilt && cd dist/prebuilt
git clone https://github.com/mlc-ai/binary-mlc-llm-libs.git lib
git clone https://huggingface.co/mlc-ai/mlc-chat-RedPajama-INCITE-Chat-3B-v1-q4f16_1
cd ../../..
使用CLI
从源代码编译mlc_llm_cli
cd mlc-llm/
# create build directory
mkdir -p build && cd build
# generate build configuration
python3 ../cmake/gen_cmake_config.py
# build `mlc_chat_cli`
cmake .. && cmake --build . --parallel $(nproc) && cd ..
验证是否编译成功
# expected to see `mlc_chat_cli`, `libmlc_llm.so` and `libtvm_runtime.so`
ls -l ./build/
# expected to see help message
./build/mlc_chat_cli --help
使用mlc_llm_cli运行LLM
./build/mlc_chat_cli --local-id RedPajama-INCITE-Chat-3B-v1-q4f16_1 –device mali
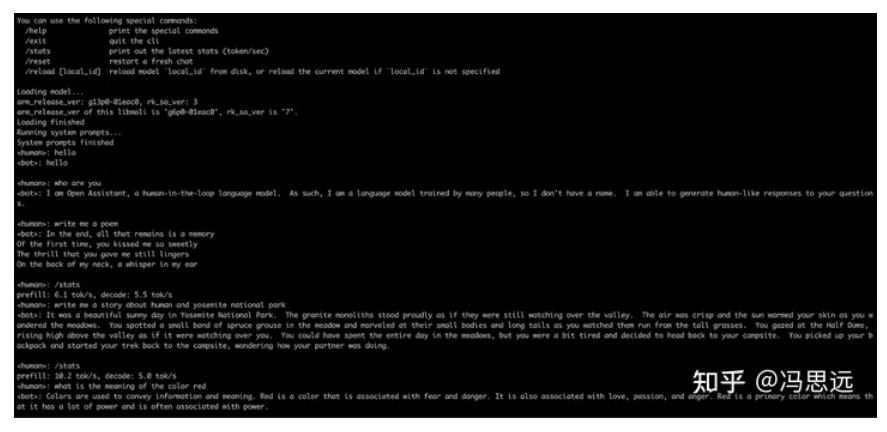
CLI 运行截图
使用Python API
编译TVM runtime(无需编译完整TVM编译器)
# clone from GitHub
git clone --recursive https://github.com/mlc-ai/relax.git tvm_unity && cd tvm_unity/
# create build directory
mkdir -p build && cd build
# generate build configuration
cp ../cmake/config.cmake . && echo "set(CMAKE_BUILD_TYPE RelWithDebInfo)\nset(USE_OPENCL ON)" >> config.cmake
# build `mlc_chat_cli`
cmake .. && cmake --build . --target runtime --parallel $(nproc) && cd ../..
设置PYTHONPATH(可按需添加到bashrc或zshrc)
export TVM_HOME=$(pwd)/tvm_unity
export MLC_LLM_HOME=$(pwd)/mlc-llm
export PYTHONPATH=$TVM_HOME/python:$MLC_LLM_HOME/python:${PYTHONPATH}
运行下列Python脚本
from mlc_chat import ChatModule
from mlc_chat.callback import StreamToStdout
cm = ChatModule(model="RedPajama-INCITE-Chat-3B-v1-q4f16_1")
# Generate a response for a given prompt
output = cm.generate(
prompt="What is the meaning of life?",
progress_callback=StreamToStdout(callback_interval=2),)
# Print prefill and decode performance statistics
print(f"Statistics: {cm.stats()}\n")
评论区Hihg翻了!
这篇文章同时发表 Hacker News。在人工智能评论区,大家的讨论热闹非凡,令人目不暇接。他们热烈地讨论Orange Pi 5的硬件选项和可扩展性,感叹如此强大的模型,如此实惠的价格,将改变游戏规则,认为这一突破将为预算有限的人工智能爱好者带来了新的可能性。
“这一功能强大的工具使得在Orange Pi 5等设备上充分发挥人工智能的潜力变得前所未有的简单。对于开发者和业余爱好者来说,这都是一个改变游戏规则的工具。”
“通过 GPU加速语言模型编译,Orange Pi 5 已被证明是一款经济实惠的人工智能利器。这款设备拥有令人惊叹的速度,能以极低的成本运行高性能模型,正在彻底改变人工智能领域。”
我们欣喜地可以看到,Orange Pi 5正在以其强大的人工智能能力让越来越多的人工智能爱好者加入到创新、创意的世界,不断进行新的实践和探索。
-
Banana Pi 携手 ArmSoM 推出人工智能加速 RK3576 CM5 计算模块2024-12-11 0
-
电子爱好者2011-12-19 0
-
人工智能是什么?2015-09-16 0
-
人工智能到底用 GPU?还是用 FPGA?2017-08-23 0
-
数据对人工智能发展的重要性2017-10-09 0
-
人工智能就业前景2018-03-29 0
-
AI开发者福音!阿里云推出国内首个基于英伟达NGC的GPU优化容器2018-04-04 0
-
“洗牌”当前 人工智能企业如何延续热度?2018-11-07 0
-
人工智能:超越炒作2019-05-29 0
-
异构计算在人工智能什么作用?2019-08-07 0
-
内置NPU的Orange Pi 4B,你怎么看2019-12-23 0
-
《无线电爱好者读本》(上)下载2008-08-26 4441
-
电脑爱好者2011年第5期2011-06-02 1468
-
人工智能爱好者如何开发自己的人工智能系统2018-11-20 12626
全部0条评论

快来发表一下你的评论吧 !
