

商汤科技董事长兼CEO徐立:AI 2.0时代的“新质生产力工具”
描述
“AI 2.0时代,生成式AI被视为推动生产力进步的重要技术,如果能在知识、推理、执行三层能力上实现突破,将真正带来整个社会生产力的跨越式发展。” 商汤科技董事长兼CEO徐立在2024 GDC上提出了这一前瞻性观点。
3月23-24日,2024全球开发者先锋大会(GDC)在上海隆重召开。商汤科技董事长兼CEO徐立受邀出席开幕式,并发表《AI 2.0时代的“新质生产力工具”》主旨演讲,分享了对AI 2.0时代生产力工具“质”变背后的思考和突破路径。
以下为徐立演讲内容梳理。
▎新生产力工具仍需持续进化
最近,“新质生产力”成为热议话题,尤其在开发者领域,生成式AI被视为引领生产力突破的技术,也标志着人工智能进入了一个新的发展阶段,我们称之为AI 2.0时代。
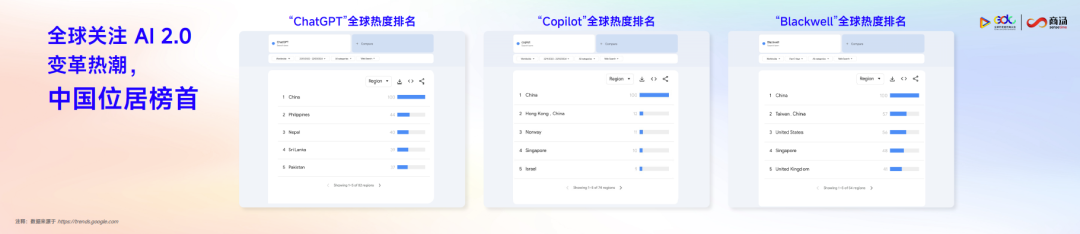
ChatGPT、Copilot、Blackwell是AI2.0时代的热度代名词。搜索数据显示,中国对于这些词的关注热度位居世界榜首,这代表着中国近千万的开发者以及普罗大众对于AI能够带来的变化热切关注。当然,这也是中国AI发展的非常好的基础。
随着AI 2.0时代的来临,GitHub上的相关项目数量呈指数级增长。生成式AI项目、大模型项目以及辅助编程、辅助开发的工具项目层出不穷。但反过来看,中国数字人才缺口也在逐年增大,且短缺比例在快速扩大。

还有一组数据值得关注。尽管中国对AI 2.0的关注极高,但在实际应用方面排名却落后于美国和印度等国家。这其中,语言是一个不容忽视的问题。以通过自然语言完成编程任务为例,英语与现有程序的匹配度相当高,而优秀的中文语言工具相对欠缺。
虽然我们已经开始使用AI 2.0时代的生产力工具,但这些工具带来的生产效率提升效果并不明显,所能解决的问题占比不足10%,给生产链路带来的突破相对有限。
众所周知,软件开发全生命周期包括需求分析、设计、开发、测试、部署和维护诸多环节。虽然目前AI能够带来很多革新,或者扩展到很多场景,但目前仅能解决其中非常小众的部分。
具体而言,AI目前能解决的是在过往基础上抽象成比较标准化、甚至以知识库的形式固化下来的内容,包括代码补全、代码增写以及部分测试用例等。如果把它分摊到整个软件或者产品设计的全流程当中,占比并不高。

当然,随着扩展能力变强,很多工具会从前端的设计、测试用例再到维护的横向拓展,一步步往前演进。
除了横向能力的拓展,从纵向来看,当前,新生产力工具的准确率和完成度也普遍较低。
根据SWE-bench评估,Claude 2 和 GPT-4在特定任务上仅不到5%的任务完成度,即使是最新的Devin完成度也仅13%,虽然整个行业在往前走,但目前还是处于相对雏形。
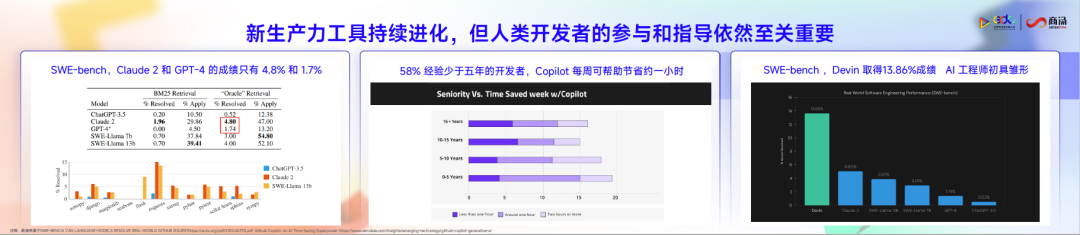
另一个有意思的现象是,编程经验越丰富,不代表就越能用好新的生产力工具。统计数据显示是相反的:工作五年以下的程序员使用新生产力工具解决问题时长超过一小时,但五年以上的程序员反而更短。这意味着越是高阶、复杂的任务,对于当前新生产力工具来说还有一定的挑战。
▎大模型能力的三层架构
大模型能力可分为三层架构,而且这三层之间互有依赖,但又相对独立。

第一层知识(Knowledge),世界知识的全面灌注。目前,许多生产力工具解决的都是知识层的问题,当用户提出问题时,其底层的逻辑都来自于“世上无新事”——你所面临的问题,前人可能已经遇到过并解决了,因此通过大模型可以很好地完成这些任务。
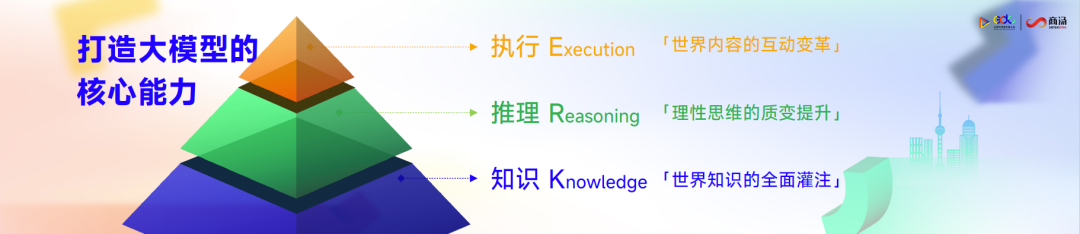
第二层推理(Reasoning),理性思维的质变提升。有了世界知识之后,再往前演进。即使不知道这件事实,也可通过AI逐步把这个事实推理出来,给出更多的可能性。
知识和推理是作为生产力工具——大模型最重要的两层,但目前在推理层,成长还相对有限,这也是今后要集中突破的能力之一。
第三层执行(Execution),世界内容的互动变革,即如何跟这个世界互动反馈。某种意义上,如今火热的具身智能,在执行上会有很大的突破。
总体来讲,这三层可以组成一个完备的对于世界提供生产力工具模型的三层能力。
▎“KRE”三层架构实践:商汤“小浣熊”快速进化
商汤结合“KRE”三层架构打造出一个办公辅助软件——“小浣熊”。
在一个已开发完成的基模型的基础上,我们从需求分析到最终完成产品开发,共需投入100人天的工作量。
如果去年用“小浣熊”代码补助工具,可节省30%的工作量。它在整个过程中主要解决的还是一些重复性的劳动,在一个很好的代码库基础上,能够做一些代码的完成任务。 在此基础上,我们进一步整合了从需求分析、需求设计到长尾应用等各个环节,推出了更为强大的“小浣熊”2.0版本。它真正意义上基于我们给出的海量数据筛选出需求,制定产品特征,在产品的特征之上完成产品的自主开发。
最终,我们期待它在获得世界知识的基础上,在真实的世界当中应用到更多的机器人场景当中。

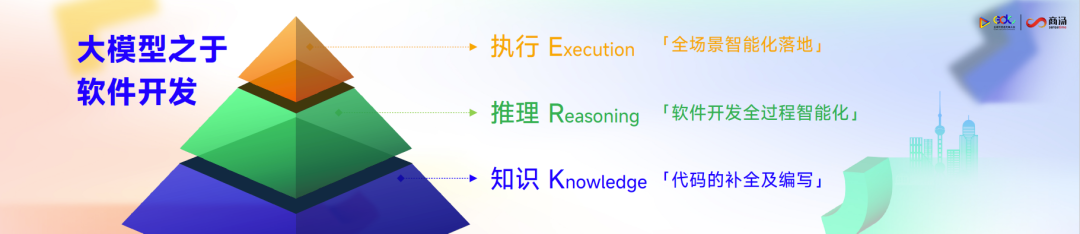
再以“KRE”三层来理解“小浣熊”。知识层是代码的补全,补全的代码来自他人写过的代码;推理层则深入到软件开发的全流程;执行层进入切分到垂直场景当中,以场景化的智能为依归。
那么知识、推理,这两层是不是相关?以GPT4为例,它拥有强大的代码解释器,能够处理各种数学问题。在面对某些特定问题时,例如“请列出一百以内所有的两个质数相乘”以及“一百以内两个质数相乘加1”, 它能够正确地列出前者,但在处理后者时却出现了错误。两个问题难度一样,为什么会出错?原因在于这类问题没有见过,它的世界知识没有办法直接给出答案,需要调用代码解释器,但生成代码正确率不可能是100%,所以会有出错的概率。
可以说,知识层主要解决高频、标准化问题,做别人做过的问题,显然准确率高。推理主要解决长尾、碎片化的问题。
举两个“小浣熊”场景化的例子。
场景一:管理智能化。在交通分析的场景中,大屏上的数据往往是固定化的,比如某个路口的流量、某个时间的流量分析等等,是一个标准化的问题。然而,当要结合天气因素、舆论因素、新闻因素,过去没有此类的分析结果,可以用软件强推理能力来完成一些长尾应用的分析。
场景二:办公智能化。当需要为产品推广制定预算时,把财务报表、账户信息、产品介绍等各类文档资源全部输入到商汤的“办公小浣熊”当中,它能够根据输入的数据和需求,给出一个既合理又科学的预算方案,展现出强大的推理能力。

总之,生产力工具如果在知识能力、推理能力、执行能力三层能力上都有突破,首先受益的是广大开发者以及场景化的核心应用,最终将真正带来整个社会生产力的跨越式发展。
审核编辑:刘清
-
首位女性董事长接任特斯拉,情况却不被分析师看好?2018-11-12 0
-
思特威董事长CEO徐辰:在联手ARM开发智能感应AI芯片2019-11-01 7646
-
重磅!Arm中国区执行董事长兼CEO吴雄昂被免职2020-06-14 2517
-
华为辟谣:否认轮值董事长徐直军离职传闻2021-02-03 3050
-
2023科创大会 | 商汤CEO徐立:生成式AI跳出思维定势,激发更多可能性2023-10-13 857
-
新质生产力哪些行业发展最好 如何提升新质生产力2024-02-22 4815
-
新质生产力是指什么2024-02-28 11439
-
新质生产力的新和质2024-02-28 2325
-
商汤科技:AI 2.0时代的“新质生产力工具”2024-03-25 626
-
商汤科技与金山办公合作打造的办公新质生产力平台WPS 3652024-04-11 464
-
IBM陈旭东:携手IBM加速 AI 规模化应用,解锁企业新质生产力2024-07-15 320
-
商汤科技发布《采用AI编程助手,发展新质生产力》白皮书2024-09-02 620
-
商汤科技大模型产业化路径的实践经验2024-09-26 414
-
商汤科技亮相2024中国人力资本发展大会2024-10-27 490
-
哈萨克斯坦总理到访商汤科技参观交流2024-11-06 278
全部0条评论

快来发表一下你的评论吧 !
