

AI时代的存储墙,哪种存算方案才能打破?
描述
电子发烧友网报道(文/周凯扬)回顾计算行业几十年的历史,芯片算力提升在几年前,还在遵循摩尔定律。可随着如今摩尔定律显著放缓,算力发展已经陷入瓶颈。而且祸不单行,陷入同样困境的还有存储。从新标准推进的角度来看,存储市场依然在朝着更高性能的方向发展。但以这些通用标准推出的产品,终究还是会被用到冯诺依曼架构的计算体系中去。或许单个产品的性能有所增加,可面对AI计算的海量数据,这点提升还是有些不够看。
以LLM这个热门AI应用而言,其数据量已经在以2年750倍的速度爆发式增长,相较之下硬件算力正在以2年3倍的速度增长。但与存储不同,硬件算力是可以靠堆规模来实现持续提升的,可存储带宽和互联带宽却没法拥有同样的拓展性,只有存储容量能够勉强跟上。所以市场上多数都在追求某种形式的存算一体方案,但实现的形式和技术路线不尽相同。
近存方案,更大的SRAM和HBM
对于我们说的存储墙而言,其实在SRAM上并不那么明显,这种最接近处理单元的存储,常被用作高速缓存,不仅读写速度极快,能效比更是远超DRAM。但SRAM相对其他存储而言,存储密度最低,成本却不低。所以尽管现如今虽然更大的SRAM设计越来越普遍,但容量离DRAM还差得很远。
但这并不代表这样的设计没有人尝试,对于愿意花大成本的厂商而言,还是很高效的一条技术路线。以特斯拉为例,其Tesla Dojo超算系统的自研芯片D1就采用了超大SRAM的技术路线。Dojo在其网格设计中采用了超快且平均分布的SRAM。
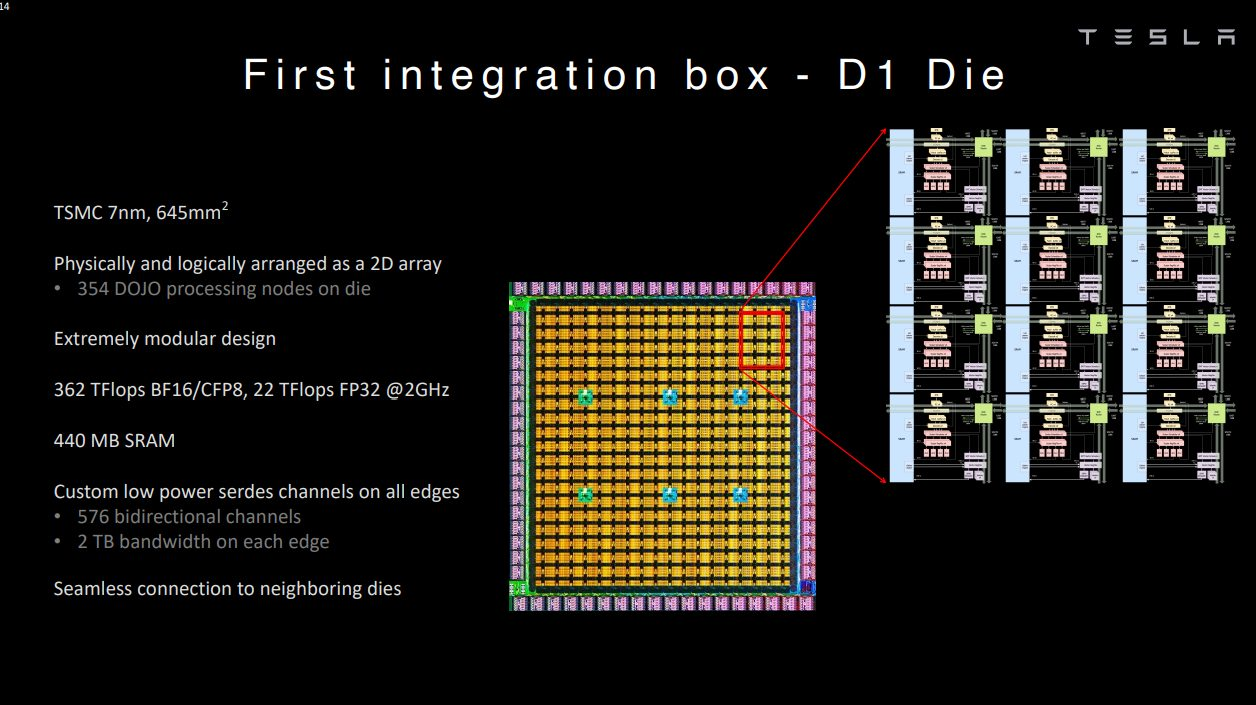
单个D1核心拥有1.25MB的SRAM,加载速度达到400GB/s,存储速度达到270GB/s。单个D1芯片的SRAM缓存达到440MB。简单来说,Dojo可以用远超L2缓存级别的SRAM容量,实现L1缓存级别的带宽和延迟。
当然了,这样的设计注定代表了投入大量的成本。在特斯拉2023财年Q4的财报会议上,马斯克强调他们做了英伟达和Dojo的两手准备。Dojo作为长远计划,因为最终的回报可能会值回现在的投入,但他也强调这确实不是什么高收益的项目。
所以对于已有的计算架构来说,走近存路线,提高DRAM的性能是最为适合的,比如HBM。HBM作为主流的近存高带宽方案,已经被广泛应用在新一代的AI芯片、GPU上。以HBM3e为例,1.2TB/s的超大带宽足以满足现如今绝大多数AI芯片的数据传输。未来的HBM4更是承诺1.5TB/s到2TB/s的带宽,
HBM的方案象征了目前DRAM堆叠的集大成技术,但目前还是存在不少问题,比如更高的成本以及对产能的要求。在现如今的AI需求驱动下,新发布的芯片很难再采用HBM设计的同时,保证大批量量产,无论是HBM产能还是CoWoS产能都处于满载的阶段,而且与制造厂商强绑定。可恰恰存储带宽决定了AI应用的速度,所以在HBM方案量产困难成本高昂的前提下,即便是英特尔和AMD这样的厂商也经不起这样挥霍,不少其他厂商更是选择了看下存内计算。
存内计算与处理,需要解决算力与存储双瓶颈
为了解决AI计算中数据存取的效率问题,把数据处理和筛选的工作放在存储端,就能极大地降低数据移动的能耗。以三星的PIM技术为例,其将关键的算法内核放在内存中的PCU模块中执行,相比已有的HBM方案,PIM-HBM可以将能耗降低70%以上。而且不仅是HBM,PIM也可以集成到LPDDR、GDDR等存储方案中。
不过存内处理的方案只解决了功耗和效率的问题,并没有对计算性能和存储性能带来任何大幅提升。至于将主要计算工作交给存内的计算单元,就是存内计算的目标了,比如不少厂商尝试的模拟存内计算(AIMC)。但这类方案实现大规模并行化运算的同时,还是需要昂贵的数模转换器,以及逃不开的错误检测。至于数字存内计算方案,一定程度上规避了模拟存内计算的缺陷,但还是牺牲了一些面积效率。对于一些大模型AI应用而言,单芯片的存储容量扩展性堪忧。
所以数模混合成了新的研究方向,比如中科院微电子研究所就在今年的ISSCC大会上发表了数模混合存算一体芯片的论文,其采用模拟方案来进行阵列内位乘法计算,利用数字方案来进行阵列外多位移位累加计算,从而达到整体的高能量效率和面积效率,INT8精度下的计算峰值能效可达111.17TFLOPS/W.

除此之外,还有存间计算的厂商,将计算单元放在不同的SRAM之间。以存间计算初创公司Untether AI为例,他们以打造存内推理加速器AI为主,通过将计算单元放在两个存储单元之间,其IC可以提供更高能效比的推理性能。比如他们在打造的第二代IC,speedAI240,集成了1400个定制RISC-V核心,可以提供至高2PetaFlops的推理性能,能耗比最高可达30 TFLOPS/W。
除了各种存算一体架构的算力瓶颈外,存储本身也需要做出突破。以三星的PIM为例,其虽然在DRAM上引入了PIM计算单元,但并未对DRAM本身的带宽的性能带来提升,这就造成了在存算一体的架构中,依然存在计算单元与存储器性能不平衡的问题,各种其他类型的存储器,包括MRAM、PCM、RRAM,除了量产问题外,写入速度和功耗的问题也还未实现突破。
西安紫光国芯为此提出了一种3D异质集成DRAM架构,逻辑晶圆通过3D混合键合工艺堆叠至SeDRAM晶圆上,进一步提升了访存带宽,降低了单位比特能耗,还能实现超大容量。从去年紫光国芯在VLSI 2023发布的论文来看,其SeDRAM已经发展至新一代多层阵列架构。结合低温混合键合技术和mini-TSV堆叠技术,可以实现135Gbps/Gbit的带宽和0.66pJ/bit的能效。
写在最后
其实无论是哪一种突破存储墙瓶颈的方式,最终都很难逃脱复杂工艺带来的挑战。行业迟迟不愿普及相关的存算技术,还是在制造工艺上没有达到适合普及的标准,无论是良率、成本还是所需的设计、制造流水线变化。已经占据主导地位的计算芯片厂商,也不会选择非得和存储绑在一条船上,但行业必然会朝这个方向发展。
此外,不少存内计算的堆叠方案中,还没有选择将主计算资源的CPU或GPU与存储垂直堆叠,而是把部分计算负载交给与存储结合的计算单元。这样一来既提高了AI计算的效率,又不会因为结构变化而出现不兼容的情况。从行业发展的角度来看,近存计算和存内处理最有可能先普及开来。
打开APP阅读更多精彩内容
以LLM这个热门AI应用而言,其数据量已经在以2年750倍的速度爆发式增长,相较之下硬件算力正在以2年3倍的速度增长。但与存储不同,硬件算力是可以靠堆规模来实现持续提升的,可存储带宽和互联带宽却没法拥有同样的拓展性,只有存储容量能够勉强跟上。所以市场上多数都在追求某种形式的存算一体方案,但实现的形式和技术路线不尽相同。
近存方案,更大的SRAM和HBM
对于我们说的存储墙而言,其实在SRAM上并不那么明显,这种最接近处理单元的存储,常被用作高速缓存,不仅读写速度极快,能效比更是远超DRAM。但SRAM相对其他存储而言,存储密度最低,成本却不低。所以尽管现如今虽然更大的SRAM设计越来越普遍,但容量离DRAM还差得很远。
但这并不代表这样的设计没有人尝试,对于愿意花大成本的厂商而言,还是很高效的一条技术路线。以特斯拉为例,其Tesla Dojo超算系统的自研芯片D1就采用了超大SRAM的技术路线。Dojo在其网格设计中采用了超快且平均分布的SRAM。
D1芯片 / 特斯拉
单个D1核心拥有1.25MB的SRAM,加载速度达到400GB/s,存储速度达到270GB/s。单个D1芯片的SRAM缓存达到440MB。简单来说,Dojo可以用远超L2缓存级别的SRAM容量,实现L1缓存级别的带宽和延迟。
当然了,这样的设计注定代表了投入大量的成本。在特斯拉2023财年Q4的财报会议上,马斯克强调他们做了英伟达和Dojo的两手准备。Dojo作为长远计划,因为最终的回报可能会值回现在的投入,但他也强调这确实不是什么高收益的项目。
所以对于已有的计算架构来说,走近存路线,提高DRAM的性能是最为适合的,比如HBM。HBM作为主流的近存高带宽方案,已经被广泛应用在新一代的AI芯片、GPU上。以HBM3e为例,1.2TB/s的超大带宽足以满足现如今绝大多数AI芯片的数据传输。未来的HBM4更是承诺1.5TB/s到2TB/s的带宽,
HBM的方案象征了目前DRAM堆叠的集大成技术,但目前还是存在不少问题,比如更高的成本以及对产能的要求。在现如今的AI需求驱动下,新发布的芯片很难再采用HBM设计的同时,保证大批量量产,无论是HBM产能还是CoWoS产能都处于满载的阶段,而且与制造厂商强绑定。可恰恰存储带宽决定了AI应用的速度,所以在HBM方案量产困难成本高昂的前提下,即便是英特尔和AMD这样的厂商也经不起这样挥霍,不少其他厂商更是选择了看下存内计算。
存内计算与处理,需要解决算力与存储双瓶颈
为了解决AI计算中数据存取的效率问题,把数据处理和筛选的工作放在存储端,就能极大地降低数据移动的能耗。以三星的PIM技术为例,其将关键的算法内核放在内存中的PCU模块中执行,相比已有的HBM方案,PIM-HBM可以将能耗降低70%以上。而且不仅是HBM,PIM也可以集成到LPDDR、GDDR等存储方案中。
不过存内处理的方案只解决了功耗和效率的问题,并没有对计算性能和存储性能带来任何大幅提升。至于将主要计算工作交给存内的计算单元,就是存内计算的目标了,比如不少厂商尝试的模拟存内计算(AIMC)。但这类方案实现大规模并行化运算的同时,还是需要昂贵的数模转换器,以及逃不开的错误检测。至于数字存内计算方案,一定程度上规避了模拟存内计算的缺陷,但还是牺牲了一些面积效率。对于一些大模型AI应用而言,单芯片的存储容量扩展性堪忧。
所以数模混合成了新的研究方向,比如中科院微电子研究所就在今年的ISSCC大会上发表了数模混合存算一体芯片的论文,其采用模拟方案来进行阵列内位乘法计算,利用数字方案来进行阵列外多位移位累加计算,从而达到整体的高能量效率和面积效率,INT8精度下的计算峰值能效可达111.17TFLOPS/W.
speedAI240 / Untether AI
除此之外,还有存间计算的厂商,将计算单元放在不同的SRAM之间。以存间计算初创公司Untether AI为例,他们以打造存内推理加速器AI为主,通过将计算单元放在两个存储单元之间,其IC可以提供更高能效比的推理性能。比如他们在打造的第二代IC,speedAI240,集成了1400个定制RISC-V核心,可以提供至高2PetaFlops的推理性能,能耗比最高可达30 TFLOPS/W。
除了各种存算一体架构的算力瓶颈外,存储本身也需要做出突破。以三星的PIM为例,其虽然在DRAM上引入了PIM计算单元,但并未对DRAM本身的带宽的性能带来提升,这就造成了在存算一体的架构中,依然存在计算单元与存储器性能不平衡的问题,各种其他类型的存储器,包括MRAM、PCM、RRAM,除了量产问题外,写入速度和功耗的问题也还未实现突破。
西安紫光国芯为此提出了一种3D异质集成DRAM架构,逻辑晶圆通过3D混合键合工艺堆叠至SeDRAM晶圆上,进一步提升了访存带宽,降低了单位比特能耗,还能实现超大容量。从去年紫光国芯在VLSI 2023发布的论文来看,其SeDRAM已经发展至新一代多层阵列架构。结合低温混合键合技术和mini-TSV堆叠技术,可以实现135Gbps/Gbit的带宽和0.66pJ/bit的能效。
写在最后
其实无论是哪一种突破存储墙瓶颈的方式,最终都很难逃脱复杂工艺带来的挑战。行业迟迟不愿普及相关的存算技术,还是在制造工艺上没有达到适合普及的标准,无论是良率、成本还是所需的设计、制造流水线变化。已经占据主导地位的计算芯片厂商,也不会选择非得和存储绑在一条船上,但行业必然会朝这个方向发展。
此外,不少存内计算的堆叠方案中,还没有选择将主计算资源的CPU或GPU与存储垂直堆叠,而是把部分计算负载交给与存储结合的计算单元。这样一来既提高了AI计算的效率,又不会因为结构变化而出现不兼容的情况。从行业发展的角度来看,近存计算和存内处理最有可能先普及开来。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
大模型时代的算力需求2024-08-20 0
-
存算一体大算力AI芯片将逐渐走向落地应用2022-05-31 4995
-
ReRAM存算一体AI大算力芯片的独特优势2022-06-20 3982
-
亿铸存算一体AI大算力芯片:存算一体架构2022-11-24 2095
-
国产存算一体超速前进 存算一体架构有机会解决很多AI面临的问题2022-11-25 2192
-
基于3DIC架构的存算一体芯片仿真解决方案2023-02-24 4947
-
特斯拉的下一代AI芯片:存算一体2023-03-09 1800
-
知存科技再推存算一体芯片,用AI技术推动助听器智能化2023-03-10 3314
-
AI算力发展如何解决内存墙和功耗墙问题2023-04-12 1841
-
浅谈为AI大算力而生的存算-体芯片2023-12-06 397
-
大算力时代, 如何打破内存墙2024-03-06 320
全部0条评论

快来发表一下你的评论吧 !
