

面向汽车网络安全的生成式人工智能
描述
企业IT和产品IT与标准化软件的融合降低了恶意行为者的入侵门槛。适用于各种恶意软件的入门工具包已然面市,最近更是得到了基于大语言模型(LLM),如ChatGPT等AI工具的加持。然而,Vector Consulting和Robo-Test研究认为,生成式人工智能也有潜力使现有系统及新系统更加强大和安全。
随着企业IT与产品IT的融合,网络攻击及其带来的影响不断增加。图1显示工业物联网领域受攻击的增长几乎呈指数级的趋势[1,2]。而且,这些还只是已经通报的影响公共事业、工厂生产等相关场景的关键工业物联网攻击,还有大多数攻击没有被报告或被认为不相关。
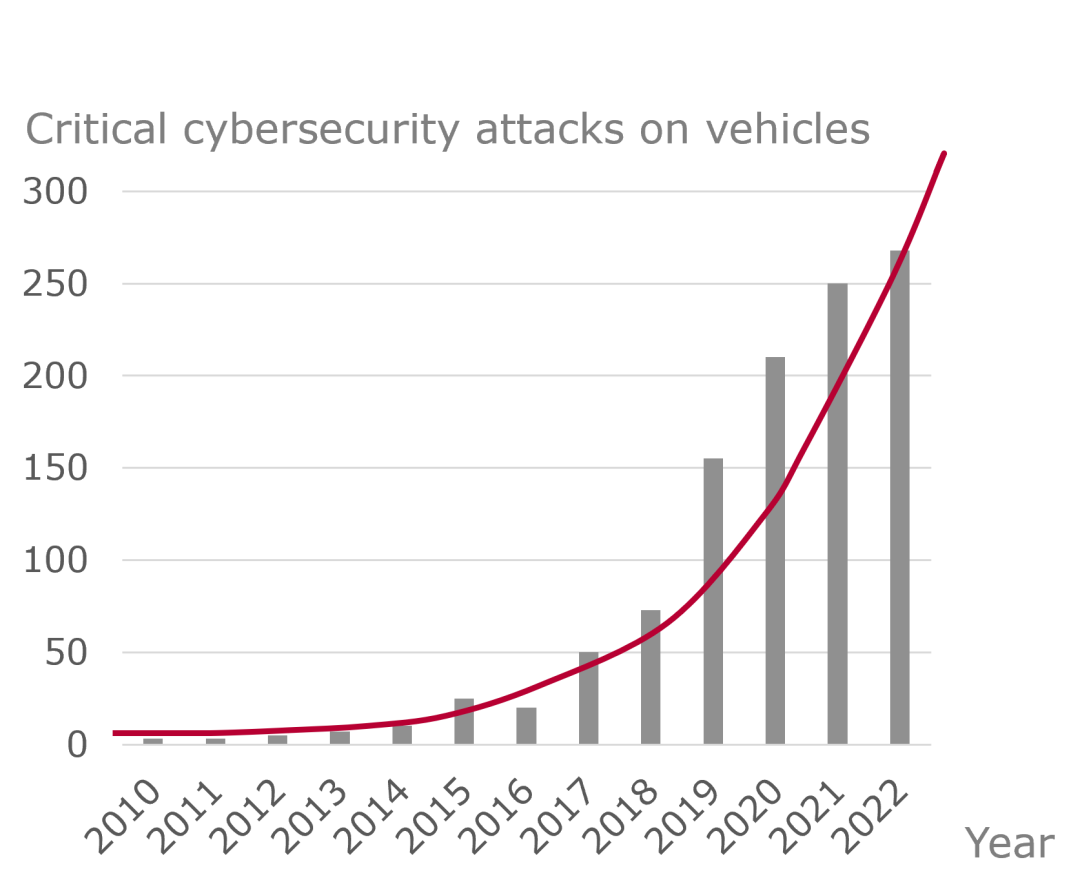
图 1:针对车辆的主要网络安全攻击
由于多种原因[1,2,3],汽车IT成为黑客的主要目标:
易于访问,因为可以轻松触及车辆来实施漏洞发掘而不被发现。
勒索软件和支付带来潜在好处,因为供应商和OEM担心网络攻击成为新闻头条。
三分之一的公司没有既定的产品网络安全计划和专门的安全研发团队。
三分之二的公司漏洞测试只涵盖了不到一半的硬件和软件。
以前的专有软件被标准软件堆栈和工具取代,从而允许使用标准黑客工具和知识,并且增加了攻击窗口期。
系统和组件具有更多的始终在线、连接性和用于软件更新的智能应用程序编程接口(API),从而允许远程执行几乎所有攻击。
没有网络安全就没有功能安全。随着软件和数据被操纵,系统的初始合格、验证或认证结果不再得到保障。随着网络犯罪的激增,整车厂和供应商必须提供足够的保护,防止其企业和产品IT系统被操纵。
网络安全中的人工智能技术
人工智能(AI)将很快成为打击网络犯罪的主要工具,因为它有助于建立高效和有效的安全工程。网络安全要求很高,需要系统化的流程。传统方法需要大量的手动工作,例如可追溯性,当我们关注各行业的不一致性和不合理的测试时,会发现他们几乎没有系统化的部署。用于网络安全的人工智能技术简化了这些活动[4]。例如,从TARA和安全需求到安全测试的安全工程,在人工智能的辅助下实现了更好的一致性,进而有助于生成、验证和关联必要的工作产品。
为了有效减轻网络安全风险,在安全生命周期内必须落实安全目标并使其在工作产品之间保持一致。可追溯性有助于保持一致性并降低责任风险。如果添加了新的需求,我们必须找出哪些设计部分需要修改或者哪些测试需要变更并重新运行。为此,三重峰模型将需求、设计和测试系统地联系起来[3]。
在此方法论基础上,生成式人工智能(GenAI)可以针对您提出的问题合成或生成对应的答案。自然语言处理(NLP),尤其是Transformer,为半自动安全分析、可追溯性和测试提供了新方法。特别是使用大语言模型(LLM)进行文本生成、汇总和分类,最近被证明有望提高安全分析和测试的效率和有效性[4]。虽然许多人已经尝试过基于直接输入问题的人机界面,但这个场景可以进一步自动化,从而将此类工具无缝集成到生产工具链中。
为了评估哪种基于人工智能的辅助将为网络安全带来最大收益,让我们看看整个产品生命周期。图2将安全生命周期显示为独立于底层开发方法的V模型抽象。灰色框描述了模型中各活动的抽象,蓝色框显示了我们识别到的一些基于人工智能的方法,这些方法可以支持网络安全开发过程中的相关环节。
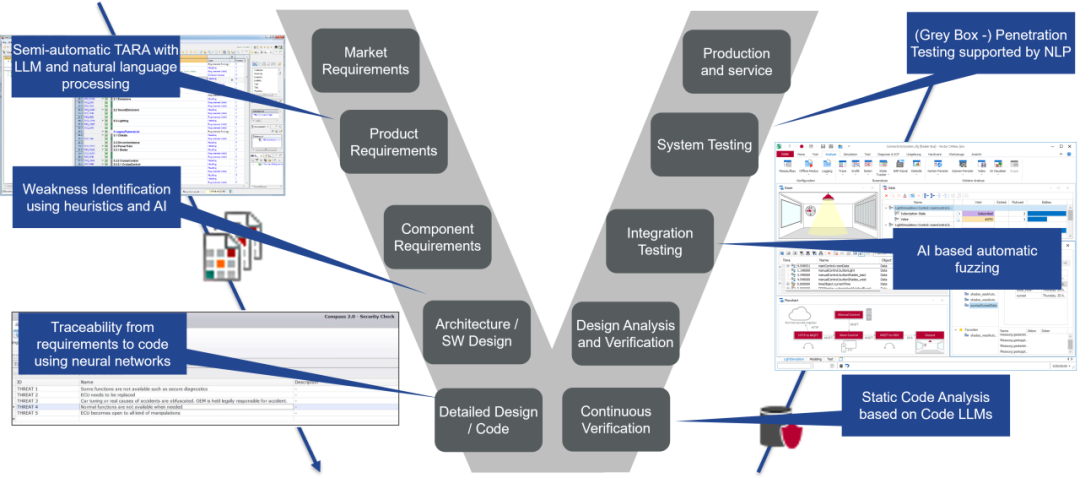
图 2:安全工程中的人工智能和底层工具链
将生成式人工智能用于安全工程
为了将生成式人工智能实际应用于网络安全工程,我们开发了Transformers和基于生成式人工智能的方法,用于网络安全需求的规范化和测试验证。我们在下述行业案例研究中的重点是使用生成式人工智能和NLP将行业需求与法规要求联系起来。
在实践中,我们使用带有网络安全语料库的定制化大语言模型作为基本模型。在评估哪种大语言模型最适合作为基准点时,我们测试了他们在令牌预测方面的能力,尤其是与安全相关的文本。为了进一步提高模型的适配度,我们使用CAPEC(常见攻击模式枚举和分类)、CVE(通用漏洞披露)和NVD(美国国家漏洞数据库)等数据库对模型进行了微调,同时也使用了经过验证的网络安全william hill官网 和博客的内容。该语料库不包含客户及专利数据,而且它会随着外部数据源的变化而不断增长。图3 显示了语料库最初的数据分布,这种分布既不是来源于现成的方案,也不是行业或标准既定的方法,而是基于Vector Consulting Services过往15年的安全分析经验。
在运行时,使用具有特定关联的敏感数据对模型进行投喂。为了保护软件免遭滥用和漏洞挖掘,它不会被存储,当然也不会脱离我们本地化的大语言模型引擎。例如,关联信息可以是为不同系统创建的TARA。这将有利于促进重用先前创建的TARA,并且进一步提高效率,TARA的某些部分通常可以重复使用,因为产品设计中使用了相同或非常相似的组件。这种使用本地化数据的双重方法会消耗大量内存、功耗和性能,但可以确保非常高的机密性。
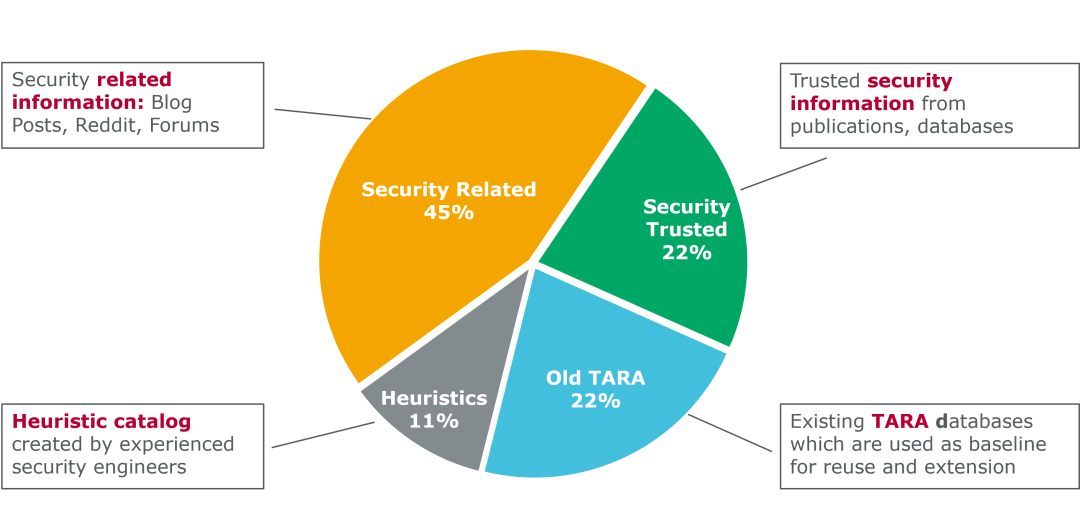
图 3:带有网络安全语料库的定制化大语言模型
市场和产品需求通常存储在应用程序或产品生命周期管理(ALM/PLM)数据库中,可以使用ReqIF或Excel将它们导出到我们的大语言模型中。图4显示了在将结果转移到专门的TARA工具之前,我们的大语言模型导出界面上的此类结果。根据此导出结果和其他关联信息(例如基于启发式的威胁目录),AI会生成针对条目、威胁和攻击路径的建议。
随后,生成的建议将加载到Vector COMPASS TARA工具中。紧接着,安全工程师将对其质量和准确性进行评估和评级。工程师还会决定GenAI工具给出的哪些建议将保留在TARA中,以及哪些应该被替换或删除。如果TARA是完整的,则将数据存储到白盒信息数据库中。该白盒数据库包含所有内部可用信息,稍后可用于执行白盒渗透测试。与此相反,灰盒数据库仅包含公开可用的数据和常见的攻击模式,他们将在灰盒渗透测试时被使用。根据需要执行的渗透测试类型,下一阶段的人工智能将使用两个或一个数据库来建议攻击或渗透策略。此策略信息用于对待测系统(SUT)进行攻击,该攻击通过使用CANoe测试环境或类似的集成测试框架来实现。
使用AI生成灰盒与白盒攻击路径是一种检查方法,它可以查明有多少可用的与系统或组件相关的信息(例如SUT中使用的库和依赖项)。将这些方法引入安全生命周期后,将有助于更好地对工具进行集成,以及实现敏捷交付流程中应对变更的快速部署,进而实现从TARA到安全需求和(回归)测试用例的一致性。
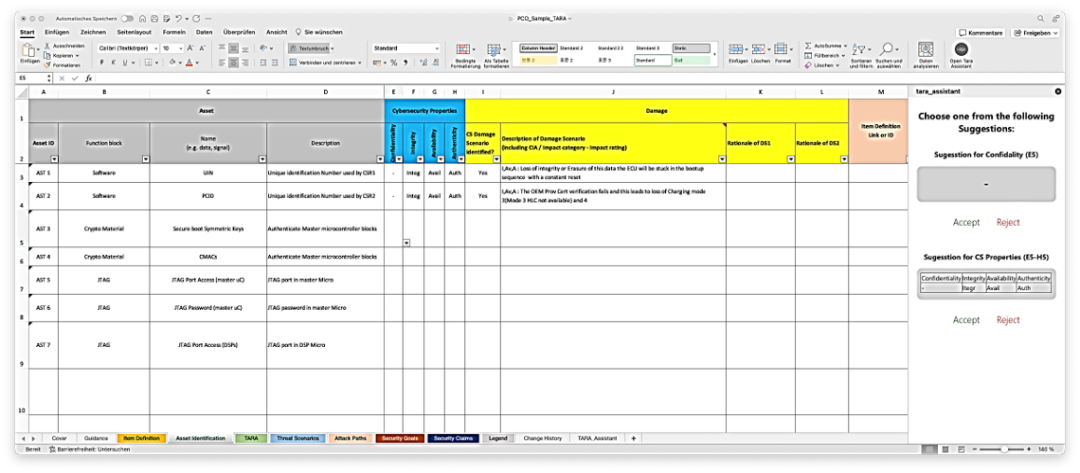
图 4:集成到开放的TARA接口
结论
关于网络安全领域应用人工智能的一个提醒,请注意隐私和安全影响:
人工智能本身可能会成为风险,因为它可以更改或添加代码。
人工智能可能会威胁您的知识产权,因为大多数模型都试图捕获您的数据。
许多人工智能工具,例如代码生成和分析工具,通常会将数据反馈给工具供应商,从而严重影响知识产权和隐私。
您的专利代码必须受到良好的保护,并且确保其不会离开您的私人数据库。因此,我们建议您建立自己的大语言模型,并针对您的特定应用领域对其进行训练。同时,避免使用GenAI建议的代码或代码片段。我们已经检测到生成式AI工具和平台在处理代码时会插入不需要的代码片段。此类片段可能看起来无风险,但存在引入后门、操纵数据或向外部目标提供信息的风险,例如库调用和外部接口(例如 REST API)。如果您想重用代码或嵌入生成的片段,请对所有外部代码运行彻底的静态分析以识别潜在的漏洞。
作者信息
Christof Ebert
Vector Consulting Services总经理,
德国斯图加特大学教授。
Maximilian Beck
德国斯图加特大学Robo-Test孵化器的人工智能企业家。
-
汽车网络安全攻击实例解析(二)2023-08-08 1603
-
人工智能在汽车中有什么应用?2019-08-06 0
-
人工智能和机器学习提高网络安全性的方法2021-01-25 0
-
人工智能对汽车芯片设计的影响是什么2021-12-17 0
-
人工智能安全有哪一些软肋2020-05-01 425
-
华为智能汽车解决方案BU正式获得汽车网络安全ISO/SAE证书2021-10-14 3825
-
汽车网络安全左移实践——基于信任构建汽车安全的探索2023-02-06 904
-
【文章转载】基于ISO 21434的汽车网络安全实践2023-04-23 957
-
生成式人工智能将如何影响网络安全领域的技能差距2023-08-08 1124
-
汽车网络安全:防止汽车软件中的漏洞2023-12-21 1096
-
汽车网络安全-挑战和实践指南2024-02-19 538
-
国内首个生成式人工智能安全技术文件发布,燧原科技深度参编2024-03-12 698
-
黑芝麻智能获得ISO/SAE 21434:2021汽车网络安全流程认证证书2024-04-03 689
-
人工智能大模型在工业网络安全领域的应用2024-07-10 750
-
经纬恒润荣获ISO/SAE 21434汽车网络安全流程认证2024-12-03 167
全部0条评论

快来发表一下你的评论吧 !
