

如何利用FPGA技术革新视觉人工智能应用?
描述
嵌入式视觉人工智能应用通过在边缘实现高度复杂的实时视频流处理和决策,正在为各行各业带来变革。这些应用范围从自动驾驶到智能制造,其中快速分析视觉数据至关重要。这些应用要求实时处理、低延迟和低功耗,以有效分析和解释视觉数据。
挑战
要满足嵌入式人工智能应用的严格要求,选择合适的硬件平台至关重要。这些要求包括在保持低功耗的同时,以最小的确定性延迟实现高性能视频处理。人工智能边缘应用的另一个要求是与多个传感器和其他外围设备互联。CPU和GPU等传统处理器往往难以满足这些要求;CPU专为顺序处理而设计,无法提供并行化处理器架构的处理带宽;GPU即使基于高度并行化架构,也难以实现高能效和超低确定性延迟;这两种技术都无法提供复杂的传感器融合功能。ASIC虽然能够实现超低延迟、高能效和传感器融合能力,但并不适合需要灵活适应不断发展的人工智能算法的应用。
解决方案
瑞苏盈科FPGA开发板为应对嵌入式视觉人工智能的挑战提供了令人信服的解决方案:
并行处理:可同时处理多个数据流,是实现高度并行化人工智能模型的完美硬件平台。
(超)低延迟:通过在硬件层面对算法实施的完全控制,可以实现超低延迟设计,这在需要瞬间决策的应用中是一个关键因素。
电源效率:可定制的逻辑块和较少的处理开销可优化功耗,使其成为边缘人工智能和功耗关键型应用的理想选择。
灵活性:可进行空中重新编程,以适应不断发展的人工智能算法,而无需重新设计硬件,从而确保了较长的产品生命周期。
传感器融合:FPGA器件拥有大量不同类型的I/O,支持各种数据协议,能够直接连接大量传感器和其他外围设备,简化了系统架构,使数据协议适配器、电平转换器等变得过时。

Mercury+ XU7和Mercury+ ST1
应用实例
瑞苏盈科设计服务团队在产品Mercury+ XU7和Mercury+ ST1基板上实现了视觉人工智能应用。Enclustra团队将两个可用的人工智能模型(图像分类(基于 YoloV3)和序列中的汽车颜色检测)结合起来,以实现最高的算法性能。这些模型是使用AMD Vitis AI工具链实现的,该工具链可将AI模型转化为FPGA/SoC结构中的最佳实施方案,并实现SoC资源的最佳利用。
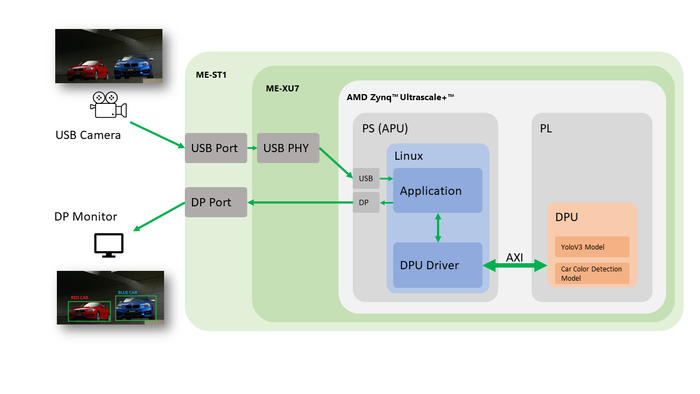
Enclustra FPGA/SoC模块和基板组合
(Mercury+ XU7和Mercury+ ST1)上的视觉人工智能应用
FPGA技术在性能、效率和适应性方面的独特组合使其成为下一代嵌入式人工智能应用的首选硬件。瑞苏盈科在FPGA技术和FPGA开发工具方面拥有丰富的经验,能够将最初的想法转化为现实!
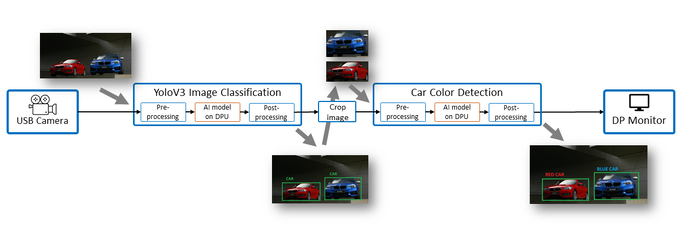
两个人工智能模型的序列:
基于YoloV3的图像分类和汽车颜色检测
水星Mercury+ XU7亮点

水星Mercury+ XU7核心板
(点击图片,了解更多产品详情)
基于AMD Xilinx's Zynq Ultrascale+ MPSoC XCZU6EG/9EG/15EG
PS端(DDR4 ECC SDRAM)和PL端(DDR4 SDRAM)2个独立的内存通道
最高28.8 GByte/sec内存带宽
提供PCIe Gen2 x 4,2 x USB 3.0,2x Gigabit Ethernet
多个型号可供选择,提供工业级型号
采用3个168-pin Hirose FX10连接器,引出236个用户I/O
提供Linux BSP和工具链
功能强大、身材小巧的FPGA核心板
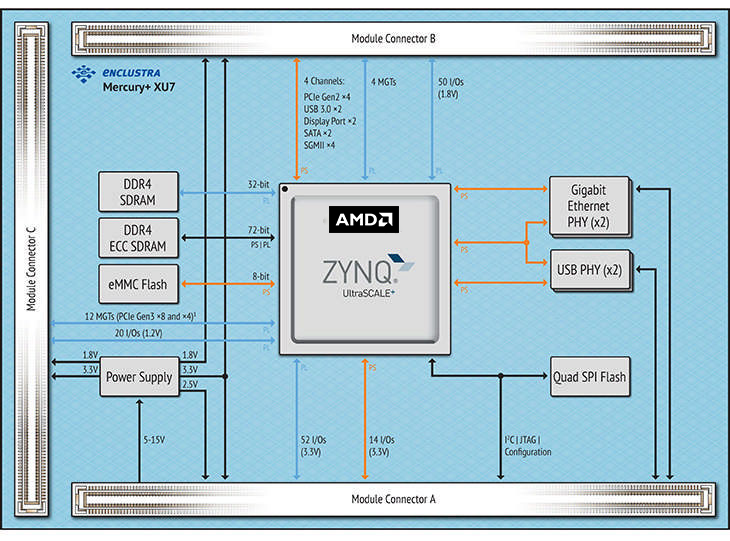
水星Mercury+ XU7结构框图
水星Mercury+ ST1亮点

水星Mercury+ ST1底板
(点击图片,了解更多产品详情)
兼容所有水星Mercury(+)系列FPGA和SoC核心板
适用于从原型到量产
身材紧凑(120 × 100 mm)
为视频应用而设计的大量接口
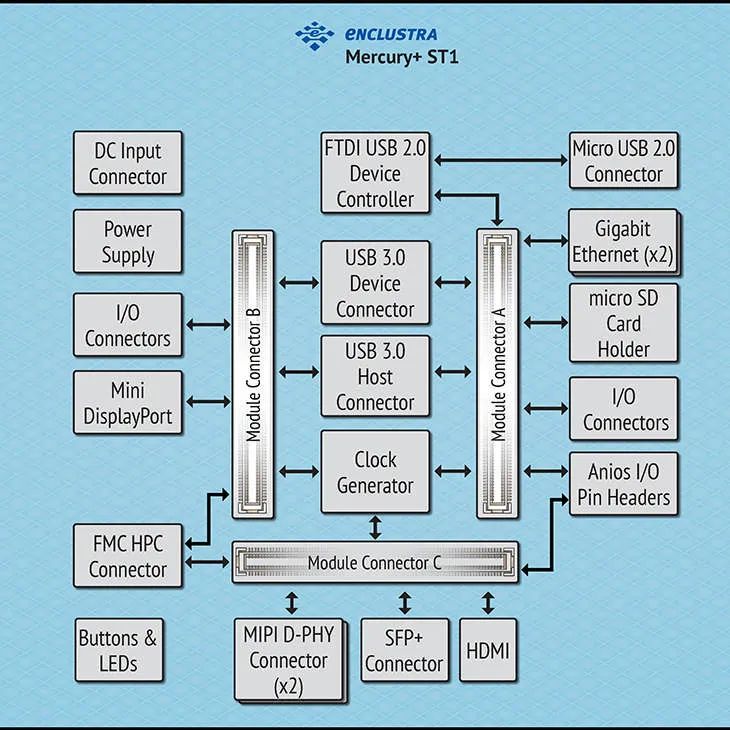
水星Mercury+ ST1结构框图
-
FPGA在人工智能中的应用有哪些?2024-07-29 0
-
人工智能是什么?2015-09-16 0
-
人工智能技术—AI2015-10-21 0
-
人工智能传感技术2016-06-03 0
-
初学AI人工智能需要哪些技术?这几本书为你解答2019-01-21 0
-
人工智能技术及算法设计指南2019-02-12 0
-
【专辑精选】人工智能之机器视觉教程与资料2019-05-05 0
-
基于人工智能的传感器数据协同作用2019-07-25 0
-
人工智能语音芯片行业的发展趋势如何?2019-09-11 0
-
如何使用人工智能来发挥传感器数据的协同作用2020-05-19 0
-
中国人工智能的现状与未来2021-07-27 0
-
人工智能芯片是人工智能发展的2021-07-27 0
-
物联网人工智能是什么?2021-09-09 0
-
人工智能对汽车芯片设计的影响是什么2021-12-17 0
-
高通剑指下一代智能手机技术革新的关口———人工智能2018-01-09 3113
全部0条评论

快来发表一下你的评论吧 !
