

介绍Python 3 的功能 让人轻松地从Python 2迁移到Python 3
电子说
描述
Python 已经成为机器学习及其他科学领域中的主流语言。它不但与多种深度学习框架兼容,而且还包含优秀的工具包和依赖库,方便我们对数据进行预处理和可视化操作。
据最新消息,到2019 年底,Numpy 等很多科学计算工具包都将停止支持Python 2版本,而 2018 年后 Numpy 的所有新功能版本也都将只支持 Python 3。
为了使初学者能够轻松地从 Python 2 向 Python 3 实现迁移,我收集了一些 Python 3 的功能,希望对大家有所帮助。
使用 pathlib 模块来更好地处理路径
pathlib 是 Python 3默认的用于处理数据路径的模块,它能够帮助我们避免使用大量的 os.path.joins语句:
from pathlib import Path dataset = 'wiki_images'datasets_root = Path('/path/to/datasets/') train_path = datasets_root / dataset / 'train'test_path = datasets_root / dataset /'test'for image_path in train_path.iterdir(): with image_path.open() as f: # note, open is a method of Path object # do something with an image
在Python2中,我们需要通过级联字符串的形成来实现路径的拼接。而现在有了pathlib模块后,数据路径处理将变得更加安全、准确,可读性更强。
此外,pathlib.Path含有大量的方法,这样Python的初学者将不再需要搜索每个方法:
p.exists() p.is_dir() p.parts() p.with_name('sibling.png') # only change the name, but keep the folderp.with_suffix('.jpg') # only change the extension, but keep the folder and the namep.chmod(mode)p.rmdir()
使用pathlib还将大大节约你的时间。
类型提示(Type hinting)成为Python3中的新成员
下面是在编译器PyCharm 中,类型提示功能的一个示例:
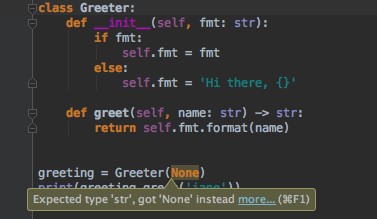
Python 不只是一门脚本的语言,如今的数据流程还包括大量的逻辑步骤,每一步都包括不同的框架(有时也包括不同的逻辑)。
Python3中引入了类型提示工具包来处理复杂的大型项目,使机器可以更好地对代码进行验证。而在这之前,不同的模块需要使用自定义的方式,对文档中的字符串指定类型 (注意:PyCharm可以将旧的文档字符串转换成新的类型提示)。
下面是一个简单的代码示例,利用类型提示功能来处理不同类型的数据:
def repeat_each_entry(data): """ Each entry in the data is doubled
上述代码对多维的 numpy.array、astropy.Table 和 astropy.Column、bcolz、cupy、mxnet.ndarray 等操作同样适用。
这段代码还可用于 pandas.Series 操作,但是这种形式是错误的:
repeat_each_entry(pandas.Series(data=[0, 1, 2], index=[3, 4, 5])) # returns Series with Nones inside
这仅仅是一段两行的代码。所以,复杂系统的行为是非常难预测的,有时一个函数就可能导致整个系统的错误。因此,明确地了解哪些类型方法,并在这些类型方法未得到相应参数的时候发出错误提示,这对于大型系统的运作是很有帮助的。
def repeat_each_entry(data: Union[numpy.ndarray, bcolz.carray]):
如果你有一个很棒的代码库,诸如 MyPy这样的类型提示工具将可能成为一个大型项目的集成流程中的一部分。不幸的是,类型提示功能还没办法强大到为 ndarrays/tensors 这种细粒度类型发出提示。或许,不久的将来我们就可以拥有这样全面的的类型提示工具,这将成为数据科学领域需要的强大功能。
从类型提示(运行前)到类型检查(运行时)
默认情况下,函数的注释对于代码的运行是没有影响的,它只是帮你指出每段代码所要做的工作。
在代码运行阶段,很多时候类型提示工具是不起作用的。这种情况你可以使用 enforce 等工具,强制性对代码进行类型检查,同时也可以帮助你调试代码。
@enforce.runtime_validationdeffoo(text: str) -> None: print(text) foo('Hi') # okfoo(5) # fails@enforce.runtime_validationdefany2(x: List[bool]) -> bool: return any(x)any ([False, False, True, False]) # Trueany2([False, False, True, False]) # Trueany (['False']) # Trueany2(['False']) # failsany ([False, None, "", 0]) # Falseany2([False, None, "", 0]) # fails
函数注释的其他用途
正如上面我们提到的,函数的注释部分不仅不会影响代码的执行,还会提供可以随时使用的一些元信息(meta-information)。
例如,计量单位是科学界的一个普遍难题,Python3中的astropy包提供了一个简单的装饰器(Decorator)来控制输入的计量单位,并将输出转换成相应的单位。
# Python 3from astropy import units as u@u.quantity_input()def frequency(speed: u.meter / u.s, wavelength: u.m) -> u.terahertz: return speed / wavelength frequency(speed=300_000 * u.km / u.s, wavelength=555 * u.nm)# output: 540.5405405405404 THz, frequency of green visible light
如果你需要用Python处理表格类型的科学数据,你可以尝试astropy包,体验一下计量单位随意转换的方便性。你还可以针对某个应用专门定义一个装饰器,用同样的方式来控制或转换输入和输出的计量单位。
通过 @ 实现矩阵乘法
下面,我们实现一个最简单的机器学习模型,即带 L2 正则化的线性回归 (如岭回归模型),来对比 Python2 和 Python3 之间的差别:
# l2-regularized linear regression: || AX - b ||^2 + alpha * ||x||^2 -> min# Python 2X = np.linalg.inv(np.dot(A.T, A) + alpha * np.eye(A.shape[1])).dot(A.T.dot(b))# Python 3X = np.linalg.inv(A.T @ A + alpha * np.eye(A.shape[1])) @ (A.T @ b)
在 Python3 中,以@作为矩阵乘法符号使得代码整体的可读性更强,且更容易在不同的深度学习框架间进行转译:因为一些代码如X @ W + b[None, :]在 numpy、cupy、pytorch 和 tensorflow 等不同库中都表示单层感知机。
使用 ** 作为通配符
Python2 中使用递归文件夹的通配符并不是很方便,因此可以通过定制的 glob2 模块来解决这个问题。递归 flag 在 Python 3.6 中得到了支持。
import glob# Python 2found_images = glob.glob('/path/*.jpg') + glob.glob('/path/*/*.jpg') + glob.glob('/path/*/*/*.jpg') + glob.glob('/path/*/*/*/*.jpg') + glob.glob('/path/*/*/*/*/*.jpg') # Python 3found_images = glob.glob('/path/**/*.jpg', recursive=True)
Python3 中更好的选择是使用 pathlib:(缺少个import)
# Python 3found_images = pathlib.Path('/path/').glob('**/*.jpg')
Python3中的print函数
诚然,print 在 Python3 中是一个函数,使用 print 需要加上圆括弧(),虽然这是个麻烦的操作,但它还是具有一些优点:
使用文件描述符的简单句法:
print >>sys.stderr, "critical error" # Python 2print("critical error", file=sys.stderr) # Python 3
在不使用str.join情况下能够输出 tab-aligned 表格:
# Python 3print(*array, sep=' ')print(batch, epoch, loss, accuracy, time, sep=' ')
修改与重新定义 print 函数的输出:
# Python 3_print =print# store the original print functiondefprint(*args, **kargs): pass # do something useful, e.g. store output to some file
在 Jupyter notebook 中,这种形式能够记录每一个独立的文档输出,并在出现错误的时候追踪到报错的文档。这能方便我们快速定位并解决错误信息。因此我们可以重写 print 函数。
在下面的代码中,我们可以使用上下文管理器来重写 print 函数的行为:
@contextlib.contextmanagerdefreplace_print(): import builtins _print = print # saving old print function # or use some other function here builtins.print = lambda *args, **kwargs: _print('new printing', *args, **kwargs) yield builtins.print = _print with replace_print():
但是,重写print函数的行为,我们并不推荐,因为它会引起系统的不稳定。
print函数可以结合列表生成器或其它语言结构一起使用。
# Python 3result = process(x) if is_valid(x) elseprint('invalid item: ', x)
f-strings 可作为简单和可靠的格式化
默认的格式化系统提供了一些灵活性操作。但在数据实验中这些操作不仅不是必须的,还会导致代码的修改变得冗长和琐碎。
而数据科学通常需要以固定的格式,迭代地打印出一些日志信息,所使用的代码如下:
# Python 2print('{batch:3} {epoch:3} / {total_epochs:3} accuracy: {acc_mean:0.4f}±{acc_std:0.4f} time: {avg_time:3.2f}'.format( batch=batch, epoch=epoch, total_epochs=total_epochs, acc_mean=numpy.mean(accuracies), acc_std=numpy.std(accuracies), avg_time=time / len(data_batch) ))# Python 2 (too error-prone during fast modifications, please avoid):print('{:3} {:3} / {:3} accuracy: {:0.4f}±{:0.4f} time: {:3.2f}'.format( batch, epoch, total_epochs, numpy.mean(accuracies), numpy.std(accuracies), time / len(data_batch) ))
样本输出为:
120 12 / 300 accuracy: 0.8180±0.4649 time: 56.60
Python 3.6 中引入了格式化字符串 (f-strings):
# Python 3.6+print(f'{batch:3}{epoch:3} / {total_epochs:3} accuracy: {numpy.mean(accuracies):0.4f}±{numpy.std(accuracies):0.4f} time: {time / len(data_batch):3.2f}')
另外,这对于查询语句的书写也是非常方便的:
query = f"INSERT INTO STATION VALUES (13, '{city}', '{state}', {latitude}, {longitude})"
「true division」和「integer division」之间的明显区别
虽然说对于系统编程来说,Python3所提供的改进还远远不够,但这些便利对于数据科学来说已经足够。
data = pandas.read_csv('timing.csv') velocity = data['distance'] / data['time']
Python 2 中的结果依赖于『时间』和『距离』(例如,以米和秒为单位),关注其是否被保存为整数。
而在 Python 3 中,结果的表示都是精确的,因为除法运算得到的都是精确的浮点数。
另一个例子是整数除法,现在已经作为明确的运算:
n_gifts = money // gift_price # correct for int and float arguments
值得注意的是,整除运算可以应用到Python的内建类型和由numpy、pandas等数据包提供的自定义类型。
严格排序
下面是一个严格排序的例子:
# All these comparisons are illegal in Python 33<'3'2
严格排序的主要功能有:
防止不同类型实例之间的偶然性排序。
sorted([2, '1', 3]) # invalid for Python 3, in Python 2 returns [2, 3, '1']
在处理原始数据时帮助我们发现存在的问题。此外,严格排序对None值的合适性检查是(这对于两个版本的 Python 都适用):
if a is not None: passif a: # WRONG check for None pass
自然语言处理中的Unicode编码
下面来看一个自然语言处理任务:
s = '您好'print(len(s))print(s[:2])
比较两个版本Python的输出:
Python2: 6
��
Python3: 2
您好
再来看个例子:
x = u'со' x += 'co' # ok x += 'со' # fail
在这里,Python 2 会报错,而 Python 3 能够正常工作。因为我在字符串中使用了俄文字母,对于Python2 是无法识别或编码这样的字符。
Python 3 中的 strs 是 Unicode 字符串,这对非英语文本的自然语言处理任务来说将更加地方便。还有些其它有趣的应用,例如:
'a' < type < u'a' # Python 2: True'a'
Python 2: Counter({'xc3': 2, 'b': 1, 'e': 1, 'c': 1, 'k': 1, 'M': 1, 'l': 1, 's': 1, 't': 1, 'xb6': 1, 'xbc': 1})
Python 3: Counter({'M': 1, 'ö': 1, 'b': 1, 'e': 1, 'l': 1, 's': 1, 't': 1, 'ü': 1, 'c': 1, 'k': 1})
对于这些,Python 2 也能正常地工作,但 Python 3 的支持更为友好。
保留词典和**kwargs 的顺序
CPython 3.6+ 的版本中字典的默认行为是一种类似 OrderedDict 的类,但最新的 Python3.7 版本,此类已经得到了全面的支持。这就要求在字典理解、json 序列化/反序列化等操作中保持字典原先的顺序。
下面来看个例子:
import json x = {str(i):i for i in range(5)} json.loads(json.dumps(x))# Python 2{u'1': 1, u'0': 0, u'3': 3, u'2': 2, u'4': 4}# Python 3{'0': 0, '1': 1, '2': 2, '3': 3, '4': 4}
这种保顺性同样适用于 Python3.6 版本中的 **kwargs:它们的顺序就像参数中显示的那样。当设计数据流程时,参数的顺序至关重要。
以前,我们必须以这样繁琐的方式来编写:
from torch import nn # Python 2 model = nn.Sequential(OrderedDict([ ('conv1', nn.Conv2d(1,20,5)), ('relu1', nn.ReLU()), ('conv2', nn.Conv2d(20,64,5)), ('relu2', nn.ReLU()) ])) # Python 3.6+, how it *can* be done, not supported right now in pytorch model = nn.Sequential( conv1=nn.Conv2d(1,20,5), relu1=nn.ReLU(), conv2=nn.Conv2d(20,64,5), relu2=nn.ReLU()) )
注意到了吗?名称的唯一性也会被自动检查。
迭代拆封
Python3 中引入迭代式拆封功能,下面来看一段代码:
# handy when amount of additional stored info may vary between experiments, but the same code can be used in all casesmodel_paramteres, optimizer_parameters, *other_params = load(checkpoint_name) # picking two last values from a sequence *prev, next_to_last, last = values_history # This also works with any iterables, so if you have a function that yields e.g. qualities,# below is a simple way to take only last two values from a list *prev, next_to_last, last = iter_train(args)
默认的 pickle 引擎为数组提供更好的压缩
Python3 中引入 pickle 引擎,为数组提供更好的压缩,节省参数空间:
# Python 2import cPickle as pickleimport numpyprint len(pickle.dumps(numpy.random.normal(size=[1000, 1000])))# result: 23691675# Python 3import pickleimport numpylen(pickle.dumps(numpy.random.normal(size=[1000, 1000])))# result: 8000162
这个小的改进节省了3倍的空间,而且运行阶段速度更快。实际上,如果不关心速度的话,类似的压缩性能也可以通过设置参数 protocol=2 来实现,但是用户经常会忽略这个选项或者根本不了解这个功能。
更安全的解析功能
Python3 能为代码提供更安全的解析,提高代码的可读性。具体如下段代码所示:
labels =
关于 super(),simply super()
Python2 中的 super() 方法,是常见的错误代码。我们来看这段代码:
# Python 2classMySubClass(MySuperClass): def __init__(self, name, **options): super(MySubClass, self).__init__(name='subclass', **options) # Python 3classMySubClass(MySuperClass): def __init__(self, name, **options): super().__init__(name='subclass', **options)
更好的 IDE 会给出变量注释
编程过程中使用一个好的IDE,能够给初学者一种更好的编程体验。一个好的IDE能够给不同的编程语言如Java、C#等,提供友好的编程环境及非常有用的编程建议,因为在执行代码之前,所有标识符的类型都是已知的。
对于 Python,虽然这些 IDE 的功能是很难实现,但是代码的注释能够在编程过程帮助到我们:
以清晰的形式提示你下一步想要做的
从 IDE 获取良好的建议
这是 PyCharm IDE 的一个示例。虽然例子中所使用的函数不带注释,但是这些带注释的变量,利用代码的后向兼容性,也能保证程序的正常工作。
多种拆封(unpacking)
下面是 Python3 中字典融合的代码示例:
x = dict(a=1, b=2) y = dict(b=3, d=4)# Python 3.5+z = {**x, **y} # z = {'a': 1, 'b': 3, 'd': 4}, note that value for `b` is taken from the latter dict.
如果你想对比两个版本之间的差异性,可以参考以下这个链接来了解更多的信息: https://stackoverflow.com/questions/38987/how-to-merge-two-dictionaries-in-a-single-expression
aame 方法对于 Python 中的列表(list)、元组(tuple)和集合(set)等类型都是有效的,通过下面这段代码我们能够更清楚地了解它们的工作原理,其中a、b、c是任意的可迭代对象:
[*a, *b, *c] # list, concatenating (*a, *b, *c) # tuple, concatenating {*a, *b, *c} # set, union
此外,函数同样支持 *args 和 **kwargs 的 unpacking 过程:
Python 3.5+ do_something(**{**default_settings, **custom_settings}) # Also possible, this code also checks there is no intersection between keys of dictionaries do_something(**first_args, **second_args)
不会过时的技术—只带关键字参数的 API
我们来看这段代码:
model = sklearn.svm.SVC(2, 'poly', 2, 4, 0.5)
显而易见,这段代码的作者还不熟悉 Python 的代码风格,很可能刚从 C++ 或 rust语言转 Python。代码风格不仅是个人偏好的问题,还因为在 SVC 接口中改变参数顺序(adding/deleting)会使代码无效。特别是对于 sklearn,经常要通过重新排序或重命名大量的算法参数以提供一致的 API。而每次的重构都可能使代码失效。
在 Python3中依赖库的编写者通常会需要使用*以明确地命名参数:
class SVC(BaseSVC): def __init__(self, *, C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, ... )
使用时,用户需要明确规定 sklearn.svm.SVC(C=2, kernel='poly', degree=2, gamma=4, coef0=0.5) 中参数的命名。
这种参数命名机制使得 API 同时兼具可靠性和灵活性。
微调:math模块中的常量
Python3 中 math 模块的改动,可以查看下面这段代码:
# Python 3math.inf # 'largest' numbermath.nan # not a numbermax_quality =-math.inf # no more magic initial values!for model in trained_models: max_quality = max(max_quality, compute_quality(model, data))
微调:单精度整数类型
Python 2 中提供了两种基本的整数类型,即 int(64 位符号整数)和用于长整型数值计算的 long 类型(长整型)。而在 Python 3 中对单精度的整型数据有个微小的改动,使其包含长整型(long) 的运算。下面这段代码教你如何查看整型值:
isinstance(x, numbers.Integral) # Python 2, the canonical way isinstance(x, (long, int)) # Python 2 isinstance(x, int) # Python 3, easier to remember
其他改动
Enums 的改动具有理论价值,是因为字符串输入已广泛应用在 python 数据栈中。Enums 虽然不与 numpy 库交互,但是在 pandas 中有良好的兼容性。
协同程序将很有可能用于数据流程的处理,虽然目前还没有大规模应用的出现。
Python 3 有稳定的 ABI。
Python 3 支持 unicode 编码格式,如 ω = Δφ / Δt 也是可以允许的,但最好使用兼容性更好的旧 ASCII 名称。
一些库比如 jupyterhub(jupyter in cloud)、django 和新版 ipython 都只支持 Python 3,因此这些用处不大的库对你来讲,可能只会偶尔使用一次。
数据科学中代码迁移所会碰到的问题及解决方案
放弃对嵌套参数的支持:
map(lambda x, (y, z): x, z, dict.items())
然而,它依然能够完美地适用于不同的理解:
{x:z for x, (y, z) in d.items()}
通常,理解在 Python2 和 3 之间差异能够帮助我们更好地‘转义’代码。
map(), .keys(), .values(), .items() 等等,返回的是迭代器而不是列表。迭代器的主要问题包括:没有琐碎的分割,以及无法进行二次迭代。将返回的结果转化为列表几乎可以解决所有问题。
如遇到其他问题请参见这篇有关 Python 的问答:“如何将 Python3 移植到我的程序中?
Python 机器学习和 python 数据科学领域所会碰到的主要问题
这些课程的作者首先要花点时间解释 python 中什么是迭代器,为什么它不能像字符串那样被分片/级联/相乘/二次迭代(以及如何处理它)。
我相信大多数课程的作者都很希望能够避开这些繁琐的细节,但是现在看来这几乎是个不可避免的话题。
结论
Python 的两个版本( Python2 与 Python3 )共存了近10年的时间。时至今日,我们不得不说:是时候该转向 Python 3 了。
科学研究和实际生产中,代码应该更短,可读性更强,并且在迁移到 Python 3 后的代码库将更加得安全。
目前 Python 的大多数库仍同时支持 2.x 和 3.x 两个版本。但我们不应等到这些依赖库开始停止支持 Python 2 才开始转向 Python3,我们现在就可以享受新语言的功能。
迁移到 Python3 后,我敢保证你的程序运行会更加顺畅。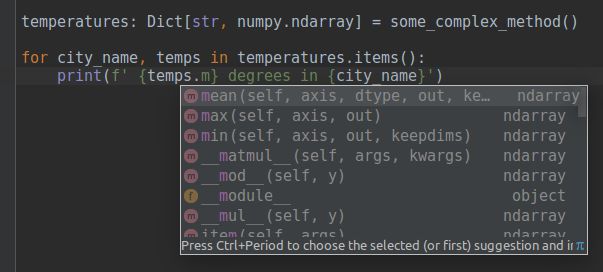
-
新手Python学习该学Python2还是Python32018-04-17 0
-
python2和python3同时安装的详细步骤2020-10-27 0
-
python2和python3是如何互相切换的2021-07-12 0
-
Python程序员必须掌握从Python2到Python3的转型2017-09-14 870
-
Instagram迁移到Python 的原因和好处2017-09-28 771
-
python2与python3问题的分析2017-11-28 1047
-
python基础教程之如何使用python进行环境搭建2018-10-25 1329
-
Python2与python3的八个主要区别2020-01-19 13616
-
再见,Python 2 你好,Python 32020-06-27 2912
-
python2与python3到底有什么区别2020-09-16 685
-
Linux备份方案 rdiff-backup 为Python 3提供了多种新功能2020-10-08 2101
-
Python之父:不要对Python 4.0抱有希望,可能不会有的2021-06-17 1589
-
如何通过python轻松处理大文件2023-04-27 878
-
Python2与Python3中对字符串的支持2023-07-05 732
-
Python2与Python3的差异2023-11-23 1007
全部0条评论

快来发表一下你的评论吧 !
