

算力基础篇:从零开始了解算力
电子说
描述
什么是算力
算力即计算能力(Computing Power),狭义上指对数字问题的运算能力,而广义上指对输入信息处理后实现结果输出的一种能力。虽然处理的内容不同,但处理过程的能力都可抽象为算力。比如人类大脑、手机以及各类服务器对接收到的信息处理实际都属于算力的应用。
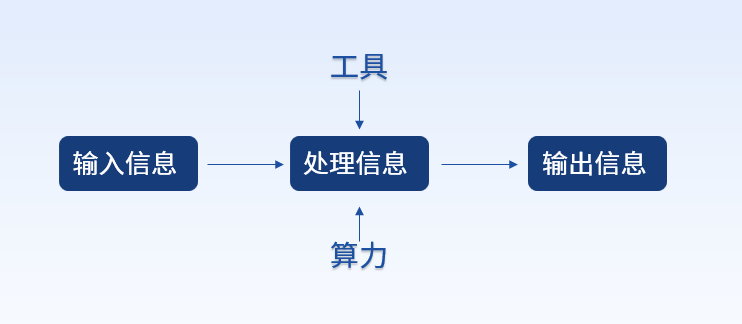
随着信息技术的不断发展,[《中国算力白皮书(2022)》]中将算力明确定义为数据中心的服务器通过对数据进行处理后实现结果输出的一种能力。当前行业中讨论的算力,狭义上可理解为CPU、GPU等芯片的计算能力,广义上可理解为芯片技术的计算能力,内存、硬盘等存储技术的存力,以及操作系统、数据库等软件技术的算法的三者集合。
算力的分类
随着数字经济时代的到来,算力发展迎来高潮,广泛应用于各个领域,其中包括但不限于日常消费领域、人工智能领域、半导体技术领域。不同应用场景对算力的需求各异,需要不同类型的算力支撑。目前算力主要分为通用算力、智能算力和超算算力。未来还会出现比传统计算更高效、更快速的新一代算力,例如量子算力等。
通用算力
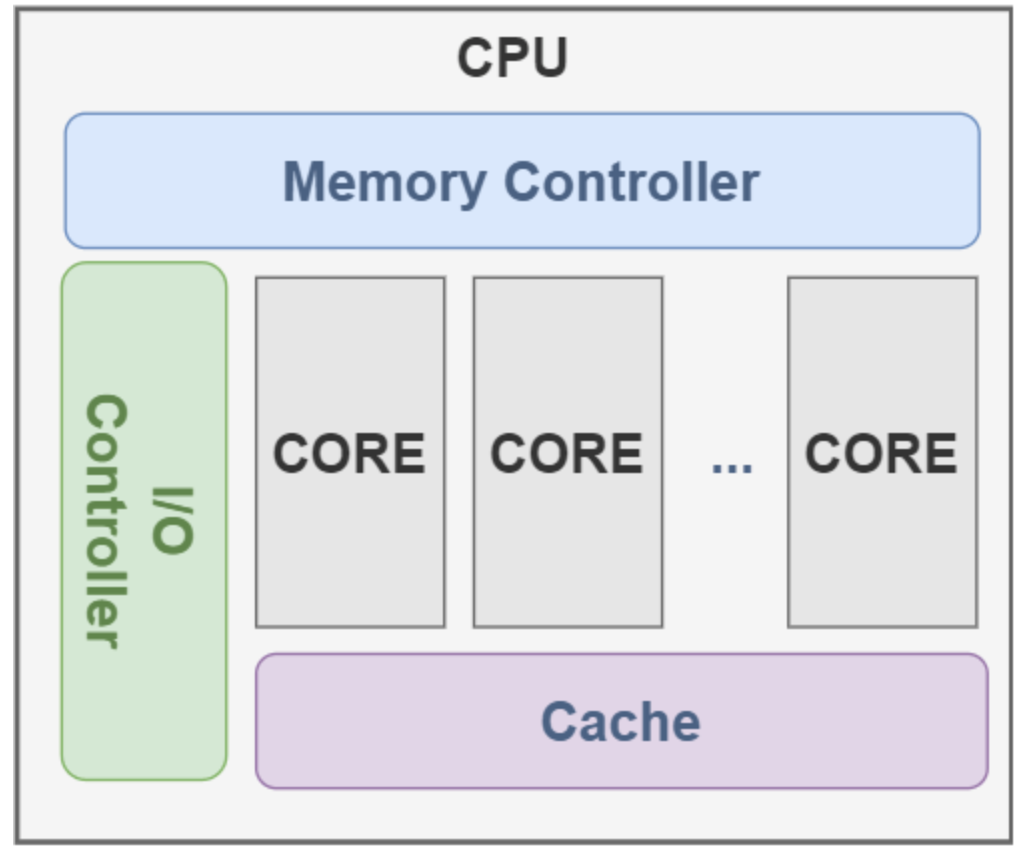
通用算力主要以CPU为代表,即CPU芯片执行计算任务时所表现出的计算能力。不同架构的CPU计算能力不同,因为CPU算力受核心数量、主频、缓存大小等多种因素影响。目前可以根据DMIPS指标来衡量CPU性能。该指标表示CPU每秒能执行多少百万条Dhrystone指令。
| 分类 | 特点 | 引领者 | 优劣势 |
|---|---|---|---|
| x86 | 复杂指令集、单核能力强 | Intel、AMD、海光、兆芯 | 软件生态好,占有率高;指令集实现复杂,功耗高 |
| ARM | 精简指令集、追求多核、低功耗 | 安谋、高通、Amazon | 授权厂商多,能效比高;软件生态劣于x86 |
| MIPS | 精简指令集、低功耗 | 龙芯 | 软件生态弱、市占率正在下降 |
| Power | 单核能力强、高可靠性、高成本 | IBM | IBM掌控技术,应用于金融领域 |
| RISC-V | 精简指令集 | RISC-V基金会、阿里巴巴、兆易创新 | 完全开放开源、模块化、可扩展 |
| Alpha | 精简指令集、速度快 | 申威 | 软件生态弱,市占率小 |
通用算力计算量小,但能够提供高效、灵活、通用的计算能力。因为CPU的架构属于少量的高性能核心结构,即核心数量少,但核心频率高,更加擅长处理复杂的逻辑判断和串行计算的单线程任务,如操作系统的管理、应用程序的执行以及各类后台服务等。而这样的设计在面对大规模并行计算任务时则显得力不从心。
智能算力
智能算力主要以GPU、FPGA、ASIC芯片为代表。每种类型的芯片具有各自的特点和优势。
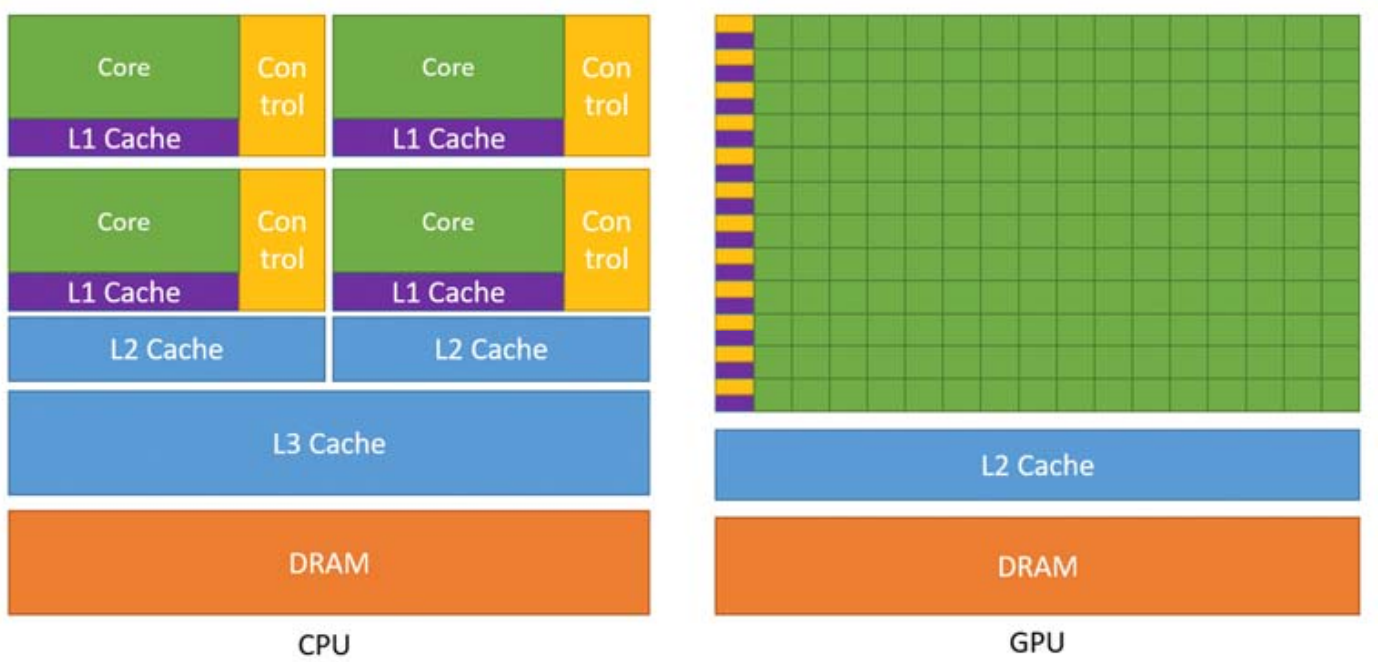
- GPU(Graphics Processing Unit,图形处理器):GPU在设计之初用于图形渲染,即同时处理大量简单的计算任务。不同于CPU的少量高性能核心架构,GPU拥有大量的核心数但较小的控制单元和缓存,能够完成高度并行的计算任务。GPU主要应用在机器学习的训练阶段,因为机器学习的操作并不依赖于复杂指令,而是大规模的并行计算。
- FPGA(Field Programmable Gate Array,现场可编程逻辑门阵列):FPGA是在PAL、GAL 等可编程器件的基础上进一步发展的产物。FPGA是半定制集成威廉希尔官方网站 ,具有可重配置的逻辑结构。其内部的威廉希尔官方网站 不是硬刻蚀的,而是可以通过HDL(硬件描述语言)编程来重新配置。这种可编程灵活性使其可以完成人工神经网络的特定计算模式,轻松升级硬件以适应AI场景中新的应用需求。除此以外,FPGA的每个组件功能在重新配置阶段都可以定制,因此在运行时无需指令,可显著降低功耗并提高整体性能。
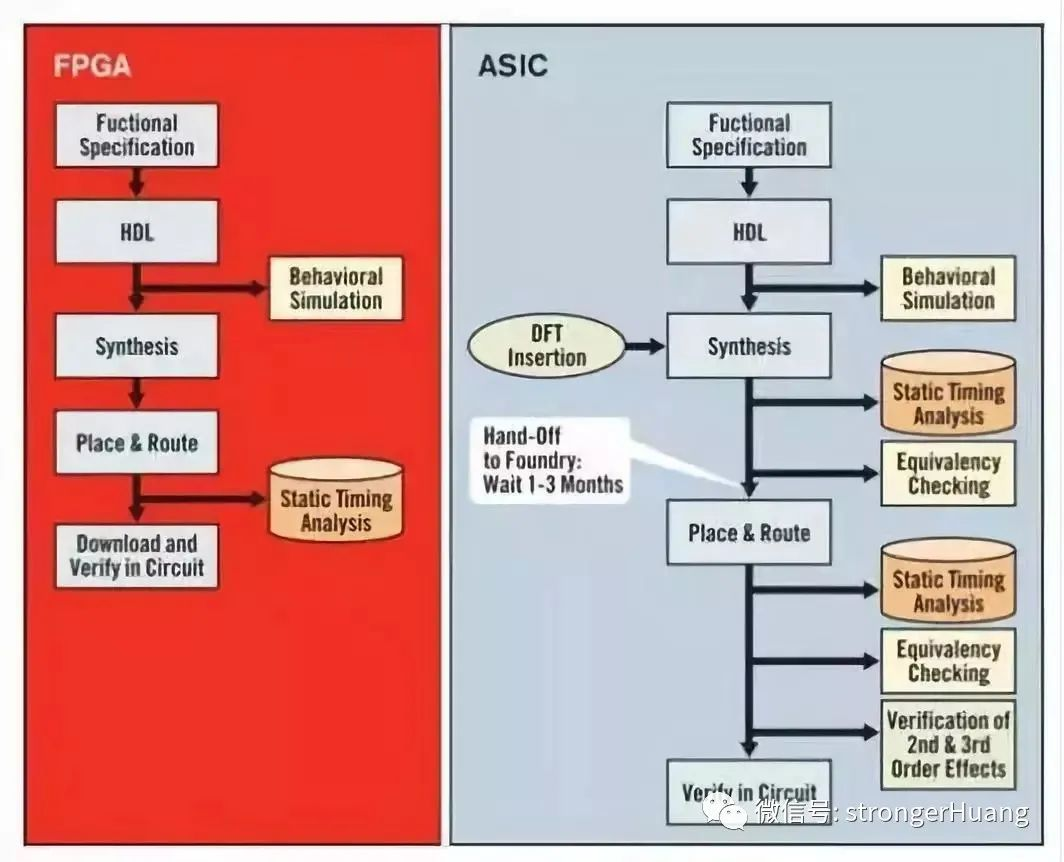
- ASIC(Application-Specific Integrated Circuit,应用特定集成威廉希尔官方网站 ):ASIC是专为满足特定需求而设计的全定制集成威廉希尔官方网站 芯片。ASIC的优势在于其能够针对特定任务进行深度优化,从而实现更高的性能和更低的功耗。一旦量产,其单位成本会显著降低,尤其适合于大规模生产和应用。然而,ASIC设计周期长、成本高,一旦设计完成,很难进行修改或升级以适应新的应用需求。因此,在选择使用ASIC还是FPGA时,需要根据具体的应用场景和需求进行权衡。对于需要高性能、低功耗且应用场景相对固定的系统,ASIC可能是更好的选择;而对于需要快速适应新技术和市场需求变化的应用场景,FPGA则更具优势。
GPU、FPGA、ASIC能力对比表格:
td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;} | | GPU | FPGA | ASIC |
| -------------- | -------------------------- | -------------------------------- | ----------------------------- |
| 并行计算能力 | 强大 | 灵活配置 | 高效但定制 |
| 灵活性 | 较低(专用于图形和计算) | 高(可编程) | 低(定制后固定) |
| 功耗 | 高 | 适中 | 低 |
| 成本 | 中等 | 低 | 高(设计和制造) |
| 整体性能 | 高 | 中等(因可重置而消耗芯片资源) | 非常高(高度定制针对性强 ) |
| 应用领域 | 图形处理、机器学习等 | 实时计算、原型设计等 | 特定应用场景(如数据中心) |
超算算力
超算即超级计算,又称高性能计算 (HPC),利用并行工作的多台计算机系统的集中式计算资源,通过专用的操作系统来处理极端复杂的或数据密集型的问题。超算算力则是由这些超级计算机等高性能计算集群所提供的算力,主要应用于尖端科研、国防军工等大科学、大工程、大系统中,是衡量一个国家或地区科技核心竞争力和综合国力的重要标志。目前,美国的Frontier以 1.206 EFlop/s的HPL性能位居全球超级计算机Top500榜第一,达到了E级计算。
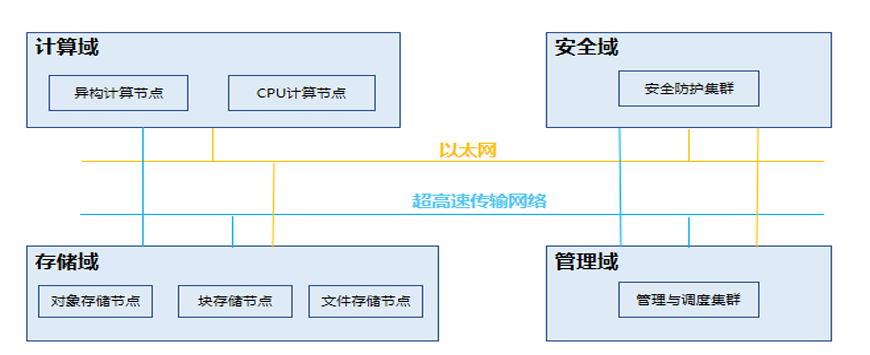
中国信息通信研究院结合业内实践和设想,提出了超算参考架构,由计算系统、存储系统、网络系统、管理系统、安全系统五部分构成。
- 计算系统:由CPU和异构加速卡计算节点共同组成。
- 存储系统:采用分布式存储,可提供PB级别以上的容量来进行数据和算据存储。
- 网络系统:分为存储网络、业务网络以及监控网络等多个网络平面,实现超算系统间各个硬件设备以及子系统间的通信互联。
- 管理系统:包括资源与业务监控、告警监控、可视化等功能。
- 安全系统:由防火墙、负载均衡、堡垒机、抗DDoS、日志审计、漏洞扫描、DNS服务器等设备组成。
新一代算力
自人工智能加速应用后,算力需求激增,人们很难保证在未来经典计算能一直满足指数级的算力增长并应用于重大计算问题。于是在全球科技竞争加剧、数字经济快速发展以及新兴技术的推动下出现了以量子计算为代表的新一代算力。
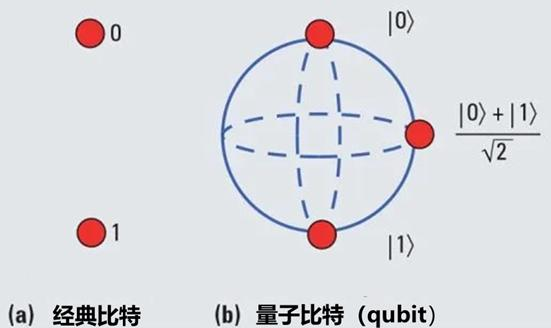
量子计算运用量子态的叠加性,使得量子比特拥有更强的信息编码能力,并可实现多个量子比特的量子纠缠,性能上限远超经典计算。量子计算机使用亚原子粒子的物理学领域来执行复杂的并行计算,从而取代了当今计算机系统中更简单的晶体管。传统计算机中的字符,要么打开,要么关闭,要么是 1,要么是 0。而在量子比特计算中,计算单元是可以打开,关闭或之间的任何值。量子比特的“叠加态”能力,为计算方程增加了强大的功能,使量子计算机在某种数学运算中更胜一筹。
目前阿里巴巴、Google、Honeywell、IBM 、IonQ 和 Xanadu 等少数几家公司都运营着量子计算机,但仍存在退相干、噪声与误差、可扩展性等问题,处于硬件开发的早期阶段。根据专家预测,想要进入量子计算机真正有用的高保真时代,还得需要几十年。
数据中心算力组成
数据中心的计算能力主要依赖于服务器。目前CPU类型的服务器几乎部署在所有的数据中心中,而高性能算力GPU等更多的使用在AI应用场景中,小规模部署于部分数据中心中。然而随着机器学习、人工智能、无人驾驶、工业仿真等新兴技术领域的崛起,传统数据中心遭遇通用CPU在处理海量计算、 海量数据时越来越多的性能瓶颈。 在数据中心加快步伐部署48核以及64核心等更高核心CPU来应对激增的算力需求的同时,为了应对计算多元化的需求,越来越多的场景开始引入加速芯片,如前文提到的GPU、 FPGA、 ASIC 等。这些加速硬件承担了大部分的新算力需求。
然而实际上的数据中心是一个汇集大量服务器、存储设备及网络设备的基础设施,数据中心算力是服务器、存储及网络设备合力作用的结果,计算、存储及网络传输能力相互协同才能促使数据中心算力水平的提升。单独讨论服务器的算力水平并不能反映数据中心的实际算力水平。
总之,数据中心是人工智能、物联网、区块链等应用服务的重要载体。数据中心算力水平的提升将会在很大程度上推动全社会总体算力供给,满足各行业数字化转型过程中的算力需求。
数据中心网络设备
以实际情况来说,数据中心的算力水平不仅取决于服务器的算力,同时还会在很大程度上受到网络设备的影响,如果网络设备算力水平无法满足要求,很有可能引发“木桶效应”,拉低整个数据中心的实际算力水平。
星融元[CX-N系列] 交换机可以帮助用户构建超低时延、 灵活可靠、按需横向扩展的数据中心网络。
- 超低时延:所搭载的交换芯片具备业界领先的超低时延能力,最低时延达到400ns左右。
- 高可靠性:通过MC-LAG、EVPN Multihoming、ECMP构建无环路、高可靠、可独立升级的数据中心网络。
- RoCEv2能力:全系列标配RoCEv2能力,提供PFC、ECN等一系列面向生产环境的增强网络特性。
- RESTful API:支持REST架构的第三方平台和应用都能自动化地管理、调度星融元数据中心网络。
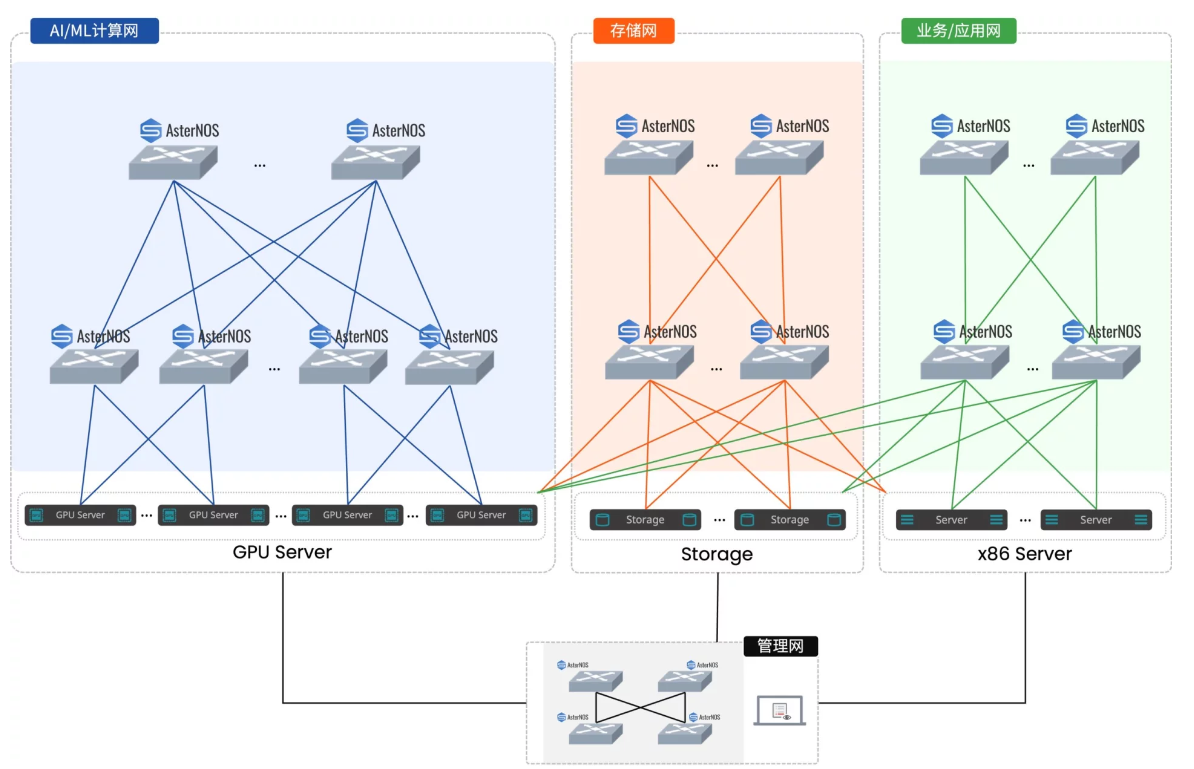
不论是在[AI智算] 还是[HPC高性能计算] 场景下,CX-N交换机都达到了媲美InfiniBand专用交换机的性能,以下是场景测试数据表:
表一:AIGC场景性能测试结果
| 带宽 | 时延 | 备注 | |
|---|---|---|---|
| E2E网卡直连 | 392.95Gb/s | 1.95us | |
| E2E跨交换机 | 392.96Gb/s | 2.51us | 交换机时延560ns |
| NCCL网卡直连 | 371.27GB/s | / | |
| NCCL跨交换机 | 368.99GB/s | / | CX-N交换机端口利用率95%。 |
表二:HPC应用测试(对比IB交换机)
| HPC应用测试 | CX-N交换机 | MSB7000 | ||||||
|---|---|---|---|---|---|---|---|---|
| HPC应用 | Test1[sec] | Test2[sec] | Test1[sec] | avg[sec] | Test1[sec] | Test2[sec] | Test3[sec] | avg[sec] |
| WRF | 1140.35 | 1134.64 | 1128.35 | 1134.44 | 1106.72 | 1099.36 | 1112.68 | 1106.25 |
| LAMMPS | 341.25 | 347.19 | 342.61 | 343.69 | 330.47 | 335.58 | 332.46 | 332.83 |
参考文献:
https://13115299.s21i.faiusr.com/61/1/ABUIABA9GAAgqvv2nAYowLyGBA.pdf
https://13115299.s21i.faiusr.com/61/1/ABUIABA9GAAgk4DrjQYo76ziRQ.pdf
审核编辑 黄宇
全部0条评论

快来发表一下你的评论吧 !
