

一种面向飞行试验的数据融合框架
描述
摘要
风洞试验和飞行试验是飞行器研制过程中进行气动性能分析与优化设计的重要手段,然而,在高超声速飞行条件下,真实气体效应、黏性干扰效应和尺度效应的复杂变化给气动数据精准预测带来巨大挑战。为了提升天地气动数据一致性,针对某外形飞行试验数据开展了典型对象的天地气动数据融合方法研究。结合数据挖掘的随机森林方法,本文提出了一种面向飞行试验的数据融合框架,通过引入地面风洞试验气动数据,实现了对复杂输入参数的特征分析与特征排序,进一步对不同飞行时刻下飞行试验的气动数据开展了交叉验证。结果表明随机森林的机器学习框架对风洞-飞行试验数据关联具有较好的预测与外推能力,可以有效提升气动数据预测精度,相关研究为复杂环境下气动数据多源融合提供了思路。
关键词
高超声速;风洞试验;飞行试验;随机森林;数据融合;参数特征分析;交叉验证
00
引言
作为当前世界航空航天强国争相追逐的重点研究方向,高超声速飞行器具有高速度、强机动、超远程、强突防等优势,这些特点对飞行器气动性能评估提出了更高的要求。如何实现高超声速气动性能的精确评估与预测是当前高超声速领域高性能飞行器发展的关键难题。
长期以来,计算流体力学方法、风洞试验方法和飞行试验都被作为航空航天领域气动性能评估的三大手段。由于在物理模型精度、试验成本与测量能力等方面互有优劣,这些手段在飞行器设计中发挥着不同的作用,同时获取的气动数据需要相互验证。在亚声速与跨声速阶段,风洞试验可以直接模拟飞行条件下的真实飞行环境,然而随着流动进入高超声速范围,天地数据不一致性问题开始凸显。
高超声速气动数据天地差异性的原因主要体现在试验与数值手段难以直接精确模拟飞行条件,量热完全气体效应的差异和黏性干扰现象的出现对气动数据的一致性产生重要影响。在高超声速气动问题中,流动具有明显的热效应,并且工作环境的气体比较稀薄,雷诺数较小。在高马赫数、低雷诺数、高焓值的条件下,高超声速流动呈现出较强的复杂性,其复杂流动现象包括薄激波层、熵层、真实气体效应、黏性干扰、稀薄气体效应等等[5-6]。由于常规高超声速风洞试验马赫数范围有限,并且难以通过控制气体密度来达到低雷诺数的要求,不能充分模拟真实飞行过程中的黏性干扰效应与真实气体效应,导致风洞试验数据与真实飞行试验下气动数据差异较大。
为了提升天地气动数据一致性,数据融合方法逐渐开始[8-9]被应用于多源气动数据的预测模型构建。所谓数据融合方法,是指根据多种信息来源(同质或异质),根据某标准在空间或时间上进行组合,获得被测对象的一致性描述,并使得该信息系统具有更好的性能。近些年来,此类方法被广泛应用于数值仿真与风洞试验数据的融合建模中。Meysam等[10]针对返回舱外形的飞行器开展了数值仿真数据与风洞试验数据的融合建模方法研究。结果显示,对于高超声速气动数据库构建问题,所采用的Co-Kriging类数据融合模型[11-12]可以有效提升气动数据库建立效率,在相似外形下气动数据利用效率可以提升80%以上。Ghoreyshi等[13-14]利用风洞试验数据和CFD仿真结果融合构建了飞机的高维定常气动模型,从而建立了定常气动数据多源数据库。利用这一方法使得数据库构建所需的试验样本降低30%以上。基于以上研究,Yondo等[15]综述了气动数据代理模型方法的发展以及抽样方法对航空航天领域数据库构建的影响,同时对数据融合模型的发展进行了展望。
针对高超声速飞行器天地气动数据差异,国内的研究团队和学者也开展了丰富的研究。陈坚强等[2]综述了国内外高超声速飞行器气动力数据天地换算技术方面的研究现状及趋势,并分析了天地气动数据关联的两大途径:一是利用天地气动数据差异,构建关联修正模型,以此实现地面风洞试验数据的修正与外推,从而提升天地一致性。在这一思路下,李金晟等[16]提出了一种适用于工程数据的天地气动数据修正框架,在飞行辨识数据中取得了较好的修正结果;龚安龙等[17]结合关联参数进行修正和改进,给出了高超声速黏性干扰下的关联修正结果;王文正等[18]提出了基于数学模型的气动力数据融合准则和方法,以气动力数据满足的准则为依据,将不同类型的数据进行融合;邓晨等[11]分别采用基于高斯回归方法和梯度信息的数据融合模型对飞行试验数据与风洞试验数据进行融合,并对比了不同融合结果中飞行试验气动数据的精度提升。二是利用高超声速气动数据关联参数,实现飞行状态与地面试验状态的关联参数对齐,从而提升天地一致性。在这一思路下,沙心国等[19]针对高超声速气动热问题开展了关联研究,并对比了不同关联参数对关联结果的影响。罗长童等[3,20]发展了基于自适应空间变换(adaptivespacetransformation,AST)的关联参数数据挖掘方法,并将其应用于高超声速气动力关联。
然而当前的天地气动数据一致性研究大多还停留在实验室阶段,面向真实飞行环境的多源气动融合依然存在未解决的问题。为了提升多源气动数据库的构建精度,获取高效的飞行试验气动数据融合能力,在以上研究思路的基础上,本文提出了一种面向飞行试验气动数据的天地气动数据差异修正模型,以风洞试验数据为低精度逼近量构建多源气动数据融合的随机森林模型。以某典型轴对称飞行器为研究对象,本文开展了风洞-飞行试验气动关联融合研究。针对不同飞行阶段开展气动数据交叉验证的结果表明,所提出的随机森林气动数据融合框架可以有效提升气动数据预测精度,在强噪声、多物理量气动数据干扰下依然具有很好的预测能力。相关工作为高超声速多源气动数据一致性提升提供了一种可行的解决方案。
01
风洞试验与飞行试验气动数据
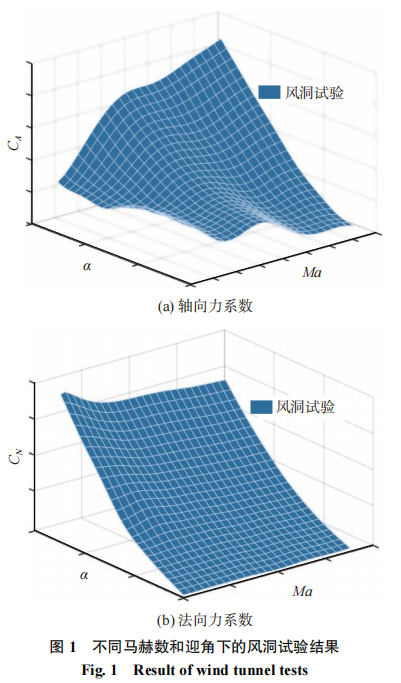
风洞试验在中国空气动力研究与发展中心完成,实现了目标对象飞行器在不同马赫数、迎角和舵偏条件下的气动力测试,相关结果的示意图如图1所示。基于该风洞试验结果,构建了复杂的气动数据库,用以完成不同飞行状态气动力的准确预测。
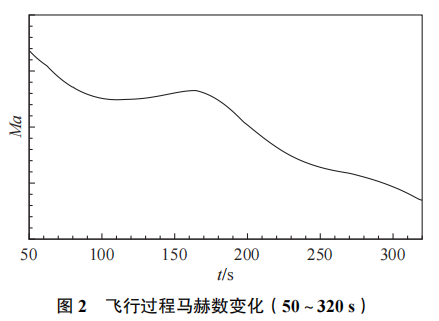
以目标对象飞行器飞行试验50~320s的气动辨识数据为研究样本进行数据融合建模。飞行器飞行马赫数变化如图2所示,马赫数在270s的飞行时间内产生了较大的变化,丰富的气动特性为模型构建提

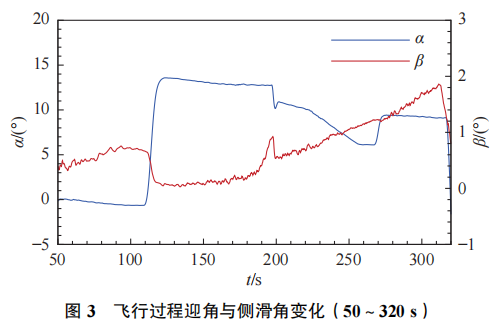
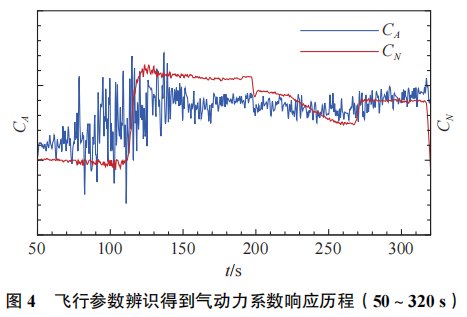
由于风洞试验不能完全匹配飞行条件,特别是雷诺数等关键物理量难以直接满足。在气动数据库构建过程中,风洞试验结果与飞行辨识结果存在一定的差异,这一问题在高超声速飞行器气动领域较为常见。对于上述飞行试验的过程,气动力响应历程存在较大的差异,相关结果的对比如图5和图6所示。
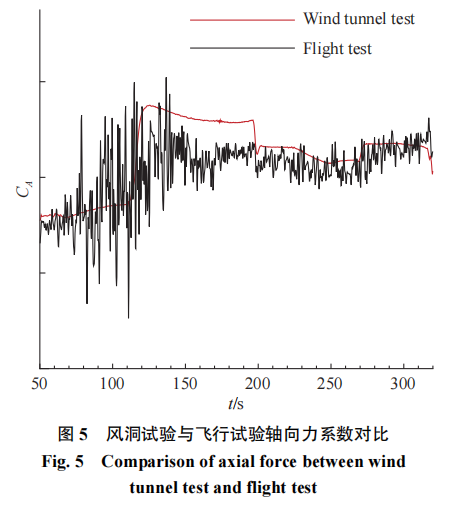
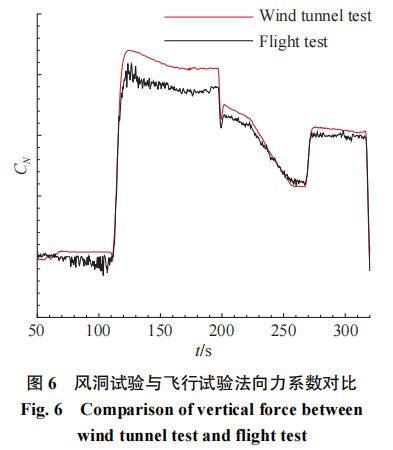
图中黑色线代表飞行参数辨识得到的响应气动力,由于传感器灵敏度与精度的限制,相关结果存在一定的噪声。而风洞试验数据利用克里金插值实现,气动力响应用红色线表示。由于试验条件、支撑干扰等差异的存在,天地气动数据在数据库中存在显著差异,在工程中往往依赖于专家经验和工程算法进行天地数据换算和修正工作。随着数据挖掘、深度学习算法的发展,利用数据本身特性开展天地气动数据融合正逐渐成为新的研究方向。
02
随机森林数据融合框架
考虑到气动数据的差异普遍存在于飞行过程,本文发展了一种基于随机森林的飞行试验天地气动数据融合框架,用来提升风洞试验数据与飞行试验数据一致性,从而大幅提高飞行气动数据预测精度。
2.1随机森林模型
考虑到飞行遥测数据存在较大噪声,同时飞行过程气动影响参数较为复杂,难以直接确定建模输入。所以这里考虑构建随机森林模型,以提升模型融合过程中处理复杂输入数据的能力。相比于传统神经网络类回归模型,随机森林方法采用集成学习框架实现参数的学习和模型预测,可以充分利用多传感器遥测数据、飞行姿态数据、地面风洞试验数据来同时构建数据融合模型。
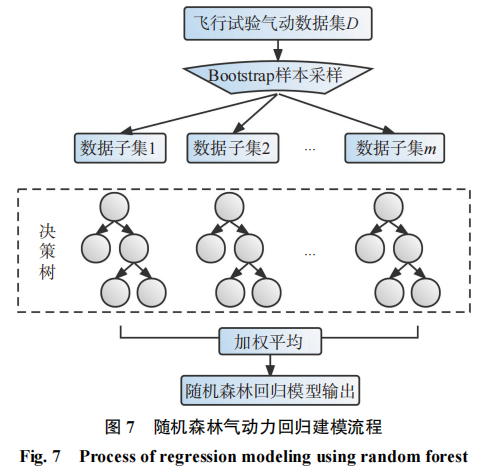
随机森林(random forest,RF)是Breiman等[21]提出的一种并行式集成机器学习方法。随机森林通过集成大量决策树达到较好的泛化性能,其通过Bootstrap取样法从D个训练样本中有放回地随机选取n个样本得到m个子集,并对每个子集单独训练一棵决策树,将m棵决策树预测结果的平均值作为回归随机森林的输出。其建模流程如图7所示。
2.2面向飞行试验的数据融合框架
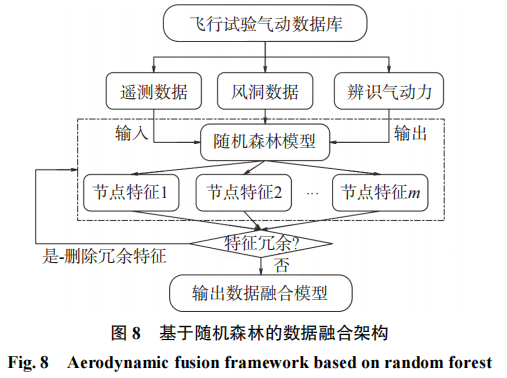
本文结合数据融合方法与随机森林模型,提出了一种可以结合不同输入特征的随机森林气动融合架构。数据融合架构的构建流程如图8所示,这里采用循环随机森林建模来调整模型输入特征,避免森林结构的冗余。
模型建模流程可以表述为:


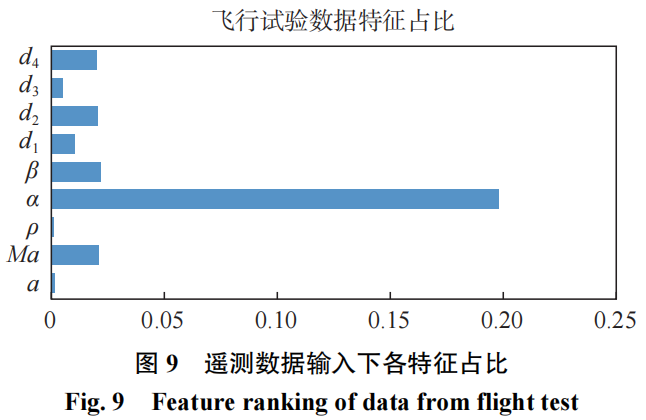
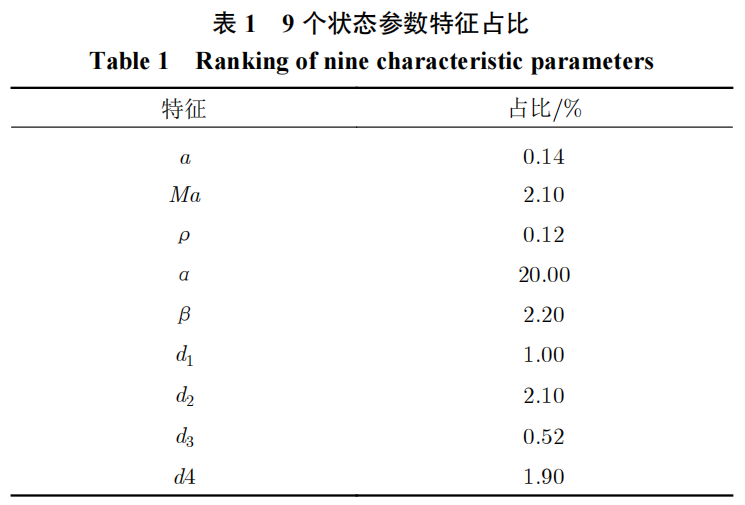
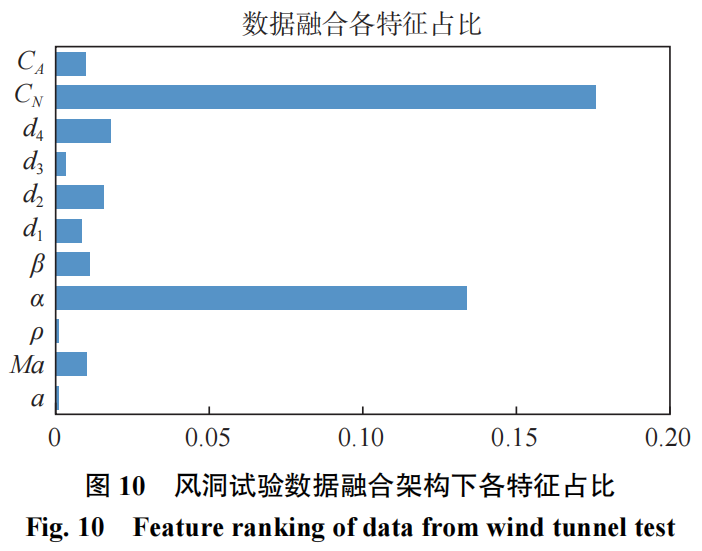
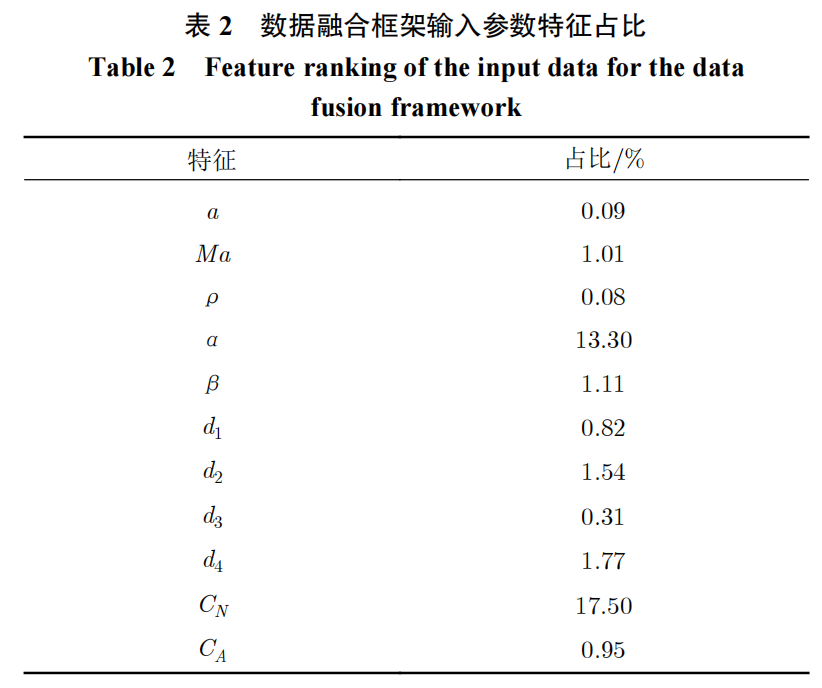
模型的特征分析结果如图10和表2所示,可以看到,数据融合的模型结构很大程度上提供了建模时的支撑,风洞试验数据得到很好体现。特别是法向力系数的占比达到最大,超过了迎角的占比。同时,由于数据融合的模型优势,随机森林对高维输入的模化有着较好的继承,传统建模下占优的输入特征不会因为风洞试验数据的引入而消退。这也是我们所追求的融合效果。同时可以看到,由于支撑干扰等风洞试验条件的限制,轴向力系数与飞行的偏差较大,在模型中所产生的贡献并不明显,这也是可以接受的。
第四步:对比随机森林模型1和模型2的特征重要性,选取特征排序倒数的特征进行特征冗余筛选。每删除一个输入特征就需要重新构建随机森林模型并进行特征排序,直到特征占比最小的值为风洞试验数据或两模型占比的最小特征不再相同,这时数据融合模型架构实现最优。因为风洞试验数据的引入是当前模型所评估的特征中占比的最小值,此时模型的其他输入不会对风洞试验数据的融合结果产生负面干扰,最终的数据融合结构也就达到了最优。由于飞行试验数据中训练数据的量和数据样本本身含噪声特性,对模型的最终建模结果有着主要影响,因此不同训练数据下模型的架构都有所不同,这里就不再展示模型的最终特征分布结果。
03
飞行试验天地气动数据融合结果
针对某对象飞行器飞行试验数据,开展模型的天地气动数据融合验证与特征分析。由于飞行试验数据涵盖了复杂的气动状态,这里选择采用同一组飞行试验数据的交叉验证来进行模型预测结果分析。
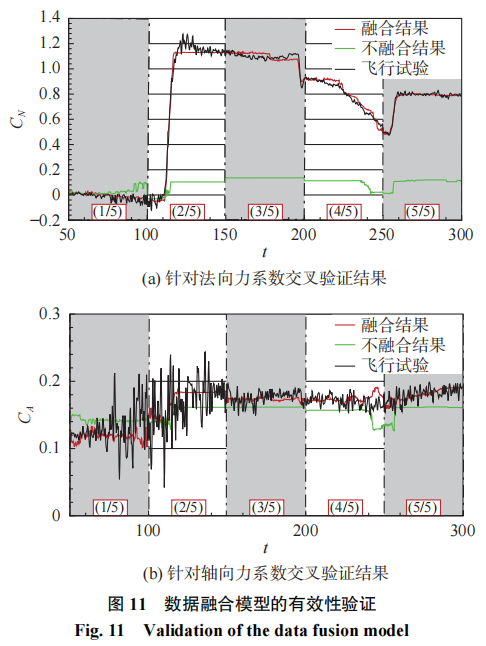
首先针对数据融合策略的有效性进行验证,选择50~300s的飞行试验气动数据开展5折交叉验证进行对比。将完整的飞行试验数据按时间顺序等分为5组,分别针对各部分进行预测,对比数据融合模型和不采用数据融合的模型在相同模型参数设置下的预测精度。对比结果如图11所示。
图11中黑色虚线代表真实飞行气动系数的辨识结果,也是我们所需要预测的真实值,而红色实线代表采用了数据融合模型后给出的气动系数预测值,而不采用数据融合方法的框架下建模的预测结果用绿色实线表示。可以发现,采用数据融合的随机森林框架得到了很好的泛化能力和预测精度,在交叉验证的结果中与真实飞行数据吻合最好。而直接采用遥测数据构建的气动力模型不能实现有效的气动力系数预测,这也显示出数据融合模型给飞行试验气动力预测带来的优势。
接下来,选取了训练预测比约为4∶1的飞行试验数据进行气动预测结果验证。即采用飞行过程中220s的飞行辨识气动数据构建融合模型,对50s的飞行气动数据进行预测,以此检测模型对于飞行状态的外推能力。模型的训练结果表示为模型拟合的能力,模型的预测结果是指模型对于非训练状态的外推泛化能力。
选取了两个状态进行气动预测对比,模型的训练、预测数据划分如表3所示。
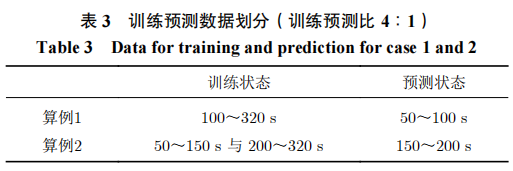
针对50~100s的气动预测结果如图12所示,其中蓝色点线代表风洞试验结果,黑色虚线代表飞行试验辨识气动力,红色实线结果代表随机森林数据融合模型的预测结果。横坐标表示为等距时间的数量,这里数据采样频率为4Hz,因此共200个时刻。当前预测样本采用100~320s的数据训练模型,可以看到随机森林模型很好地吻合了飞行试验结果,相比风洞试验数据有着较大的精度提高,特别是在法向力系数上,气动误差可以降低一个量级以上。
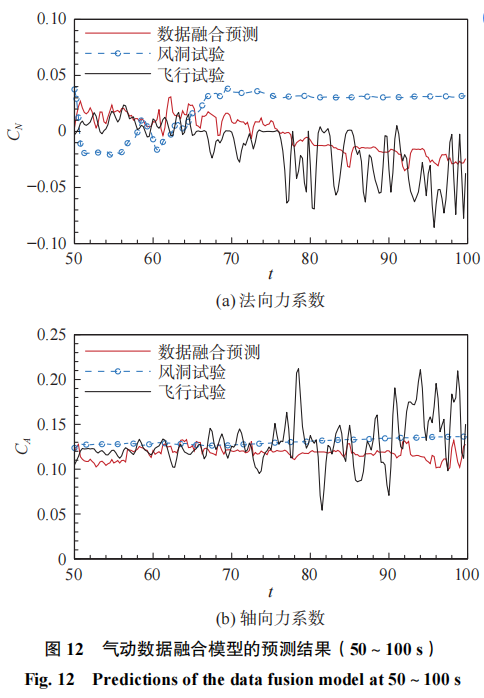
针对150~200s的气动预测结果如图13所示,随机森林模型对轴向力系数和法向力系数的预测结果都要远远好于风洞试验。甚至是在辨识结果存在较大噪声的情况下,模型也识别出了较为精确的气动力范围,相比于风洞试验有着较高的精度。
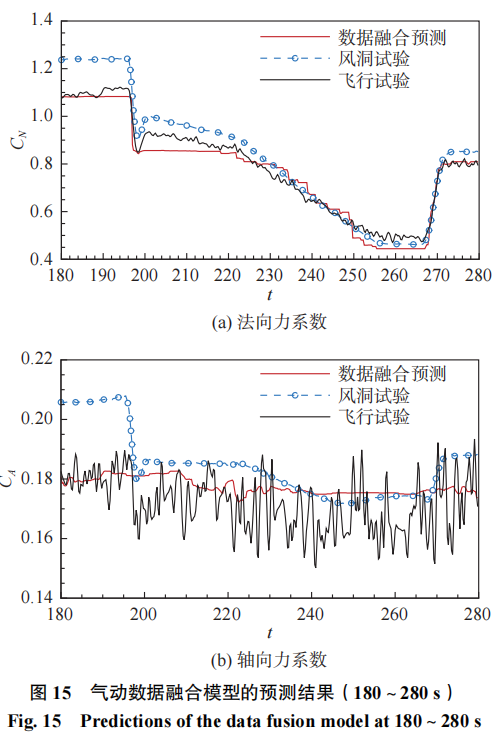
进一步地,为了测试模型对于训练样本的收敛性,降低训练、预测的数据比进行验证。这次选取100s的飞行试验气动数据作为测试算例,剩余170s飞行试验数据作为训练样本给模型参数训练,训练、预测数据比在1.7。算例3和4的预测状态分布如表4所示。
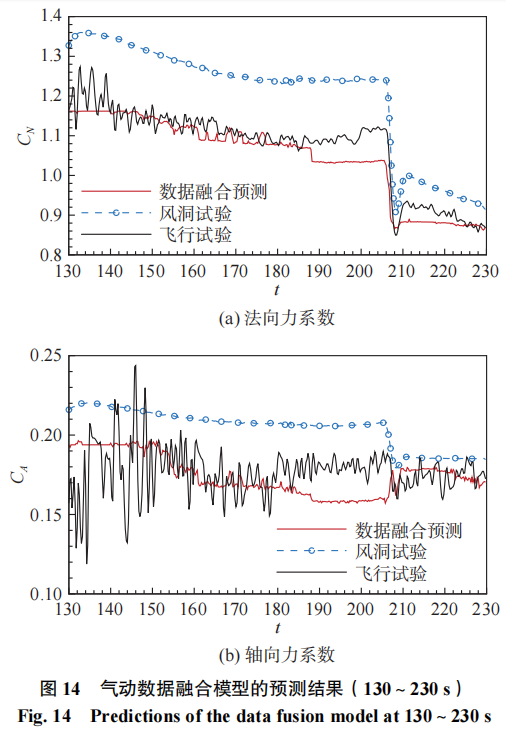
图14给出了随机森林模型在130~230s飞行区间气动预测的结果。可以发现,由于训练样本的减少,融合模型的精度有所下降,但是相较于风洞试验结果依然相有着较大的精度优势。对于法向力系数而言,随机森林模型在梯度较大值的附近模型存在一定误差,这是由于试验数据与飞行数据在这附近的趋势产生了快速变化,难以通过数据融合模型实现较好的弥补,这也是数据融合类模型的共有问题。

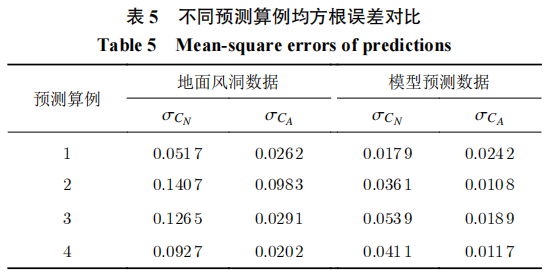
针对飞行试验的气动数据预测结果显示,数据融合模型可以较好地实现天地气动数据修正。所提出的随机森林模型可以自适应地从训练样本中挖掘复杂输入形式下的数据特征,并且实现对不同来流与飞行条件下的多源气动数据融合。基于随机森林的数据融合模型可以有效降低天地数据差异,所提供的均方误差显示,平均的误差降低在60%左右。针对训练预测比的对比情况得出,不同比例的训练、预测样本对模型能力有着一定影响。在训练比为4∶1时,数据融合模型相对风洞试验数据的误差可以降低72%,而当训练预测比降低后,均方根误差平均只降低了54%。因此,为了确保模型的有效性在使用前应尽可能进行精度收敛性测试。另外,针对飞行试验数据的建模体现出很好地抗噪声能力,在实际工程应用中具备很好的鲁棒性。对同一组飞行试验的交叉验证测试同时也印证了飞行辨识数据的可靠性,这也作为模型验证的一部分包含在模型预测精度之中。
04
结论
针对高超声速飞行器广泛存在的天地气动数据差异问题,本文提出了一种面向飞行试验的多源气动数据融合方法。结合所提出的随机森林框架与特征分析回路,实现了不同飞行条件、飞行姿态下试验气动数据的高精度预测。针对不同阶段飞行试验数据的验证表明,所提出的方法具备泛化与外推能力,可以克服一定的噪声干扰建立数据融合模型。具体结论如下:
1)结合风洞试验的数据融合框架可以有效修正天地气动数据差异,降低由于风洞试验条件带来的气动数据误差,在飞行试验的不同阶段提升气动数据预测精度。
2)所提出的随机森林数据融合模型可以很好地降低飞行环境下气动辨识数据噪声干扰,实现准确的特征筛选,为高精度气动模型输入提供帮助。
3)不同训练数据与预测数据的比值会影响模型预测精度,应在建模前尽可能进行收敛性分析,以保证模型泛化能力。
目前所采用的随机森林数据融合模型还没有开展不同飞行轨迹下的多源融合研究。未来的工作将考虑进一步提升模型泛化能力,推广应用范围。同时,针对输入数据的特征分析有可能进一步揭示天地气动数据关联参数的形式,这也将是一个很好的数据融合研究方向。
-
【WaRP7试用申请】一种高效的协议融合解决方案2017-07-03 0
-
介绍一种基于融合SoC处理器的平台软件解决方案2021-05-17 0
-
介绍一种基于四轴飞行器的双闭环PID控制算法2021-05-19 0
-
如何去实现一种ThreadX内核框架的设计呢2021-11-29 0
-
怎样去建立一种IIC数据采集USART串口通信框架呢2021-12-10 0
-
如何去实现一种四轴飞行器的硬件设计呢2021-12-20 0
-
一种较通用的界面切换框架分享,绝对实用2021-12-27 0
-
一种专门用于检测小目标的框架Dilated Module2022-11-04 0
-
一种实用的数据融合算法2009-01-18 526
-
一种新的Ad Hoc网络QoS框架2009-04-14 610
-
有限状态机的一种实现框架2016-03-22 648
-
一种成分取证的理论分析模式的分类框架2017-03-20 518
-
一种基于框架特征的共指消解方法2021-03-19 736
-
一种面向MapReduce的中间数据传输流水线优化机制2021-04-13 649
-
非常实用,推荐一种面向对象思维的单片机程序框架2023-10-24 528
全部0条评论

快来发表一下你的评论吧 !
