

龍鹰一号siengine SE1000开发板测评
描述
大家好,这期测评一款国产芯片(龍鹰一号siengine SE1000)。 主要侧重其中的AI能力部分,围绕着“如何在开发板上跑一个完整AI应用”这一主题来写,前期根据官方提供的信息编译简单app,跟大家一起熟悉流程,知道如何配置开发环境、要用到哪些工具、操作流程是啥。后面接着就跑复杂一点的AI模型,讲解软件SDK中每个模块(parser,quant,Gbuilder,simulator,profiler)的作用,逐代码进行讲解,以及如何DIY适配自己的需求等,so, let’s go!
1.硬件信息
龍鹰一号是一颗国产 7nm 智能座舱芯片,拥有 8 核 CPU 和 14 核 GPU,CPU算力能够达到90~100K DMIPS,GPU算力900+GFLOPS,NPU算力达到8TOPS,对标的是高通的8155,从安兔兔跑分来看确实数据差不多,目前已知是搭载在吉利汽车旗下领克08(23年9月发布)车型上
定位是座舱芯片的“龍鹰一号”不仅会负责中控屏幕的计算与显示,还会负责汽车仪表、功能屏幕甚至HUD的显示。“龍鹰一号”支持输入11路相机数据(遗憾的是截至目前,我仍然无法购买适配好的摄像头进行应用开发),最高可支持7块高清显示屏显示。 “龍鹰一号”会同时运行三个操作系统,分别是仪表的RTOS操作系统、HUD的Linux系统以及中控屏幕的安卓系统(目前提供的SDK默认是使用linux系统的);开发板是交给第三方的RADXA设计的,型号为SiRider S1,具体链接在这:https://docs.radxa.com/sirider/s1

虽然BOM中的车规级物料改成了普通物料,但是凭借其扎实的配置(16GB LPDDR5, 128G UFS)还是使得成本达到了千元+级别,比同类的开发板(RK3588、树莓派)是要贵上三五百块的,其实也合理,毕竟RK3588 4核A76,6TopsNPU,450Gops都稍弱于SiRider S1; 由于我们关注的是AI这一部分,因此固件编译部分我们就不细说了,因为板子默认就刷了ubuntu的固件,开箱后插上HDMI显示器,插入鼠标键盘就可直接开干了!
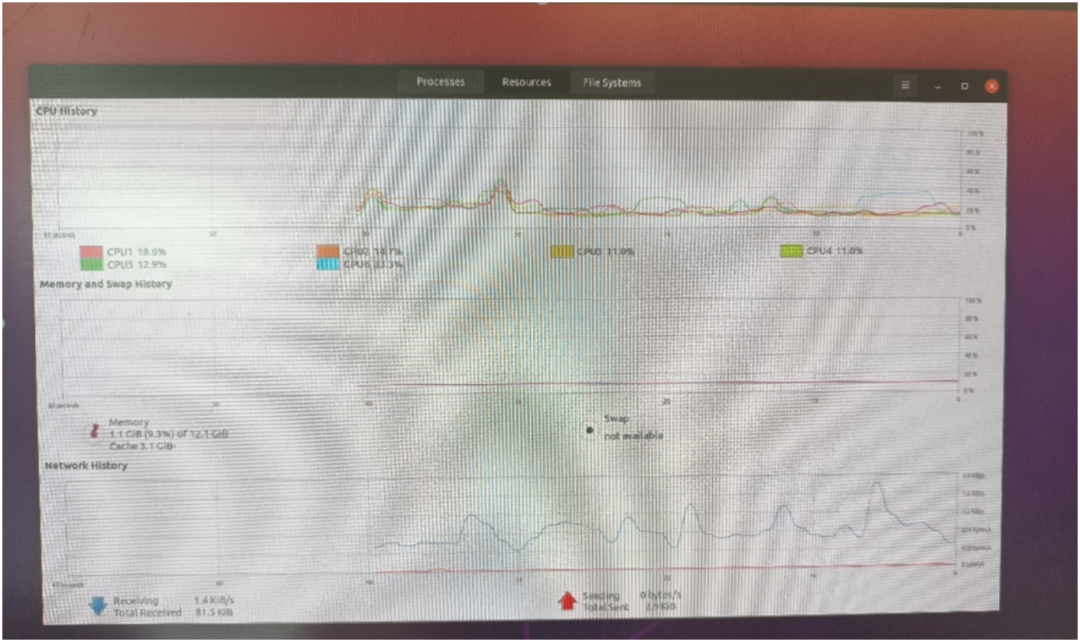
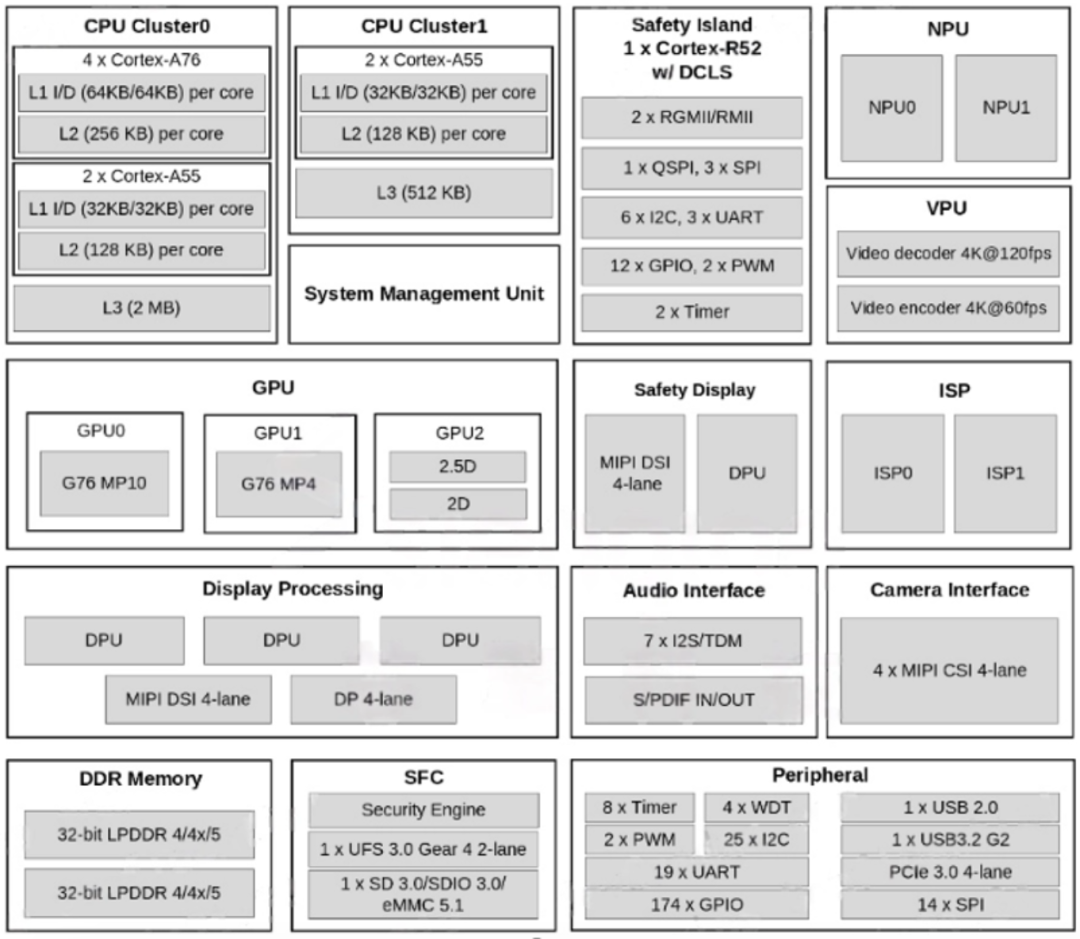
可以看到,ubuntu分配了4个大核A76+两个小核A55;内容用了12GB,剩下的都分配给FreeRTos了。 如下图SOC框架图所示,主要的算力担当以及视频编解码部分我认为足够惊艳了,用来做NAS,软路由,平板,电视盒子等应用都分分钟ok的呀!外设部分同样如此,接口最多的是UART,IIC跟SPI口,这些都是低速通用接口,因此想要做外设控制相关的应用的话,指定不是直接去快速控制了(比如FOC无刷电机,一般是需要3PWM接口/电机来进行控制, 而外设这里只提供了2个),而是通过低速接口间接驱动外设模块了,比如开启车门,开启后备箱,开启雨刮等非实时性要求高的应用,嗯,定位非常准确,所以我们做应用的时候尽量去选这三种接口(uart/iic/spi)的封装较好的独立模块就好了。
2. AI知识小科普
好的,背景介绍完毕,那我们现在开始进入AI部分的内容吧!在这个大模型百家争鸣的时代,我相信大家对AI都有一定的了解吧!
“AI就是人工智能呀!” “AI就是像人一样跟你对话!” “AI就能将你的口头描述转化成实际的图片!”
其实除了这些高大上的AI之外,你每天使用的打卡器(打工人必备)、刷脸机、以及监控摄像头、麦克风等都含有AI技术在里面,你肯定好奇:
AI到底是怎么跑在具体的硬件设备上的呢?
假如我自己有个idea想要实现跑在具体硬件上,而不是通用PC上,我又该怎么做呢? 接下来我将为你一一解答。 类似于如何将大象塞入一个冰箱的问题,如何做一个AI应用的顶层流程是这样的,
第一步,你得有个天才般或者脑残般的想法,针对这个想法提出需求;
第二步,基于需求训练一个模型出来;
第三步,将模型部署到具体的硬件上面去。
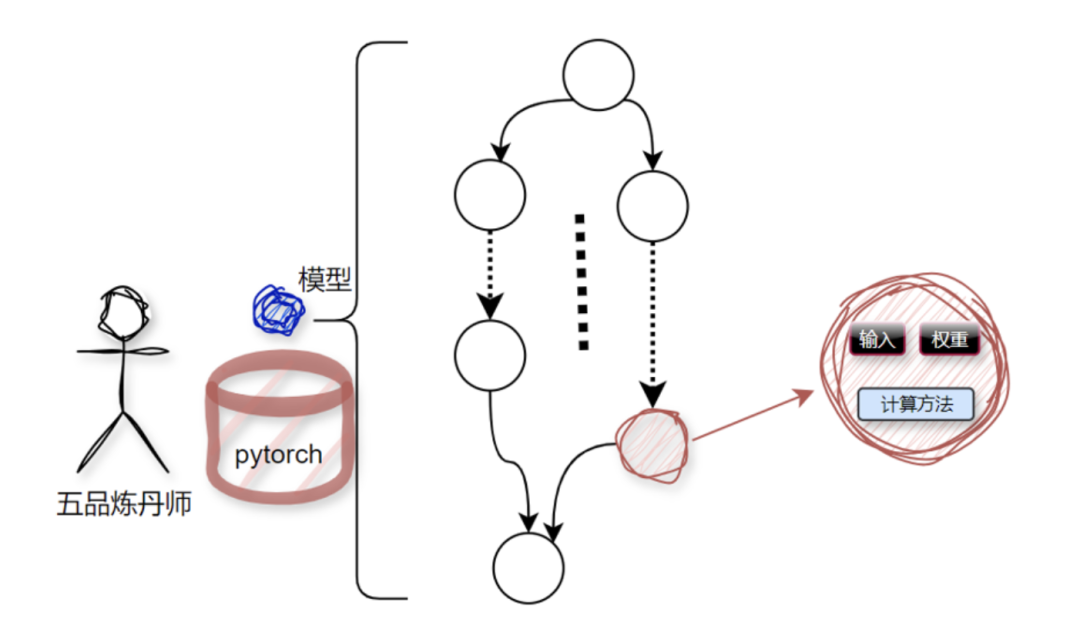
第一步跟第二步不是我们这次的主要学习内容,接下来简单带过。 AI模型是由智力绝顶的算法工程师们训练出来的,俗称炼丹。炼丹的丹炉各式各样,炼丹界主流的就是Tensorflow跟Pytorch;
这颗丹内部由一堆的节点组成,节点本质就是一堆数据加处理这堆数据的计算方法,如下图所示:
在个人PC上或者服务器上,想要让整个模型跑起来是非常简单的,因为,整个基建部分都被各大厂商(主要是英伟达)给搭建好了,我们直接使用就好了,这就好比我们要找个地方住一晚,最方便且安全的选择就是去找现成的五星级酒店(缺点显然是*),而不是去自己建房子然后住进去。而且,这些AI部署的相关服务是被全球开发者多年验证过的,好用、方便。但是,一旦你想部署到某个具体的、特定的、不通用的硬件上时,之前那一套就完全没用了,得“入乡随俗”,用与特定硬件相匹配的软件栈。具体到我们这里,就是周易SDK这一套软件栈,想把AI模型跑到板子上我们就得学习这一套SDK的使用、开发方法。
3. 周易SDK介绍
老规矩,还是先看下整体流程:首先,假设现在已经拿到一个训练好的模型model了,比如model.onnx,
这个模型只能是tensoflow/pytorch/caffe/mxnet/onnx格式的
然后我们用SDK中的工具链对模型model.onnx进行编译得到aipu.bin,就像这样aipubuild build.cfg 最后将这个aipu.bin封装到应用程序APP中, 放到到板子上运行即可;
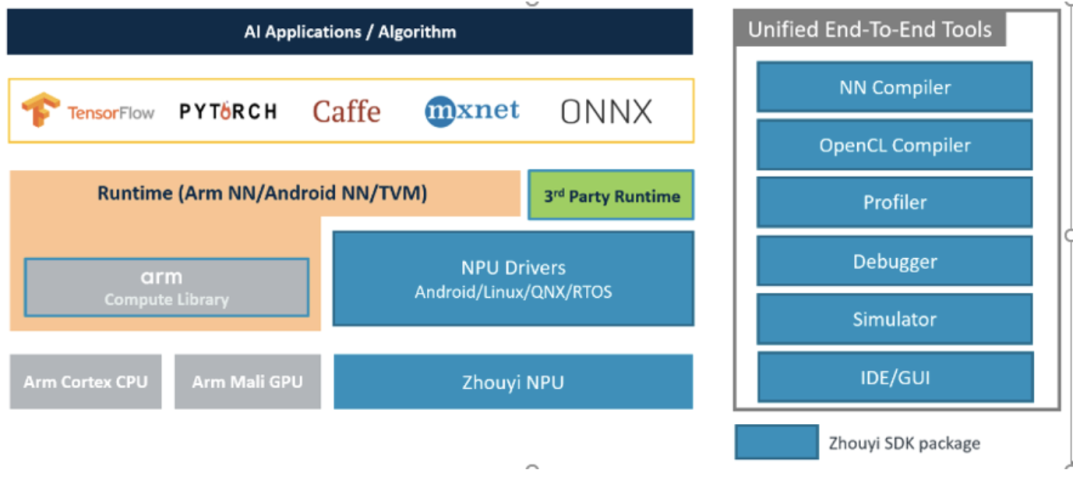
简单来说,流程跟你gcc编译c代码是一样的,只是参数格式不一样而已,这里的输入是模型,输出的是NPU支持的bin可执行文件; 此外,调bug有debugger可用,性能问题可以用profiler,没有具体硬件可以用simulator模拟硬件来跑,当然了IDE图形化操作界面也是有的。 后续的课程中我将就每一个模块结合SDK文档进行详细讲解+逐代码分析。这章回,我们先跟着教程走一遍流程,认识认识代码框架。
4. 操作流程+代码框架初识
第一步是搭建开发环境,跟着这个教程:https://docs.radxa.com/sirider/s1/app-development/zhouyi\\\_npu一步一步来,就能把整个环境搭建流程跑通(windows直接用WSL2即可)。 第二步是编译模型,在x86 PC段进行模型编译,还是上面链接(看编译部分)
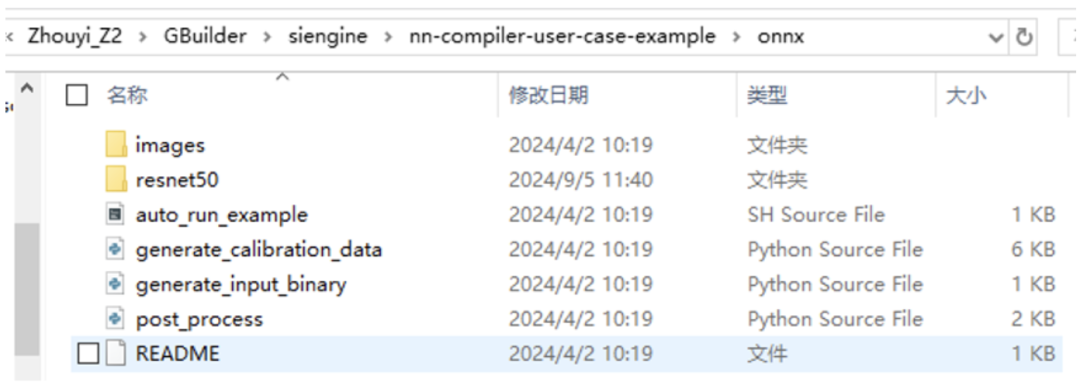
看到有如上文件,第一步是生成量化校准集,因为我们的原始模型是fp32的,但NPU是不支持fp32的,因此我们需要将其量化到int8/int16。 一个fp32的值量化到int8,在量化领域有非常多的算法来实现,我们这里使用的是PTQ(假设不理解也不要紧,后面我会专门讲解一下量化相关的内容,因为这部分代码开源了,因此甚至对着开源的代码进行code级讲解的)进行量化。 量化需要准备一个数据集进行数据范围分布的采集过程,假如不理解为什么要这一步也不要紧,知道有这个流程就行了,后面讲量化算法的时候就明白了。
python3 generate_calibration_data.py

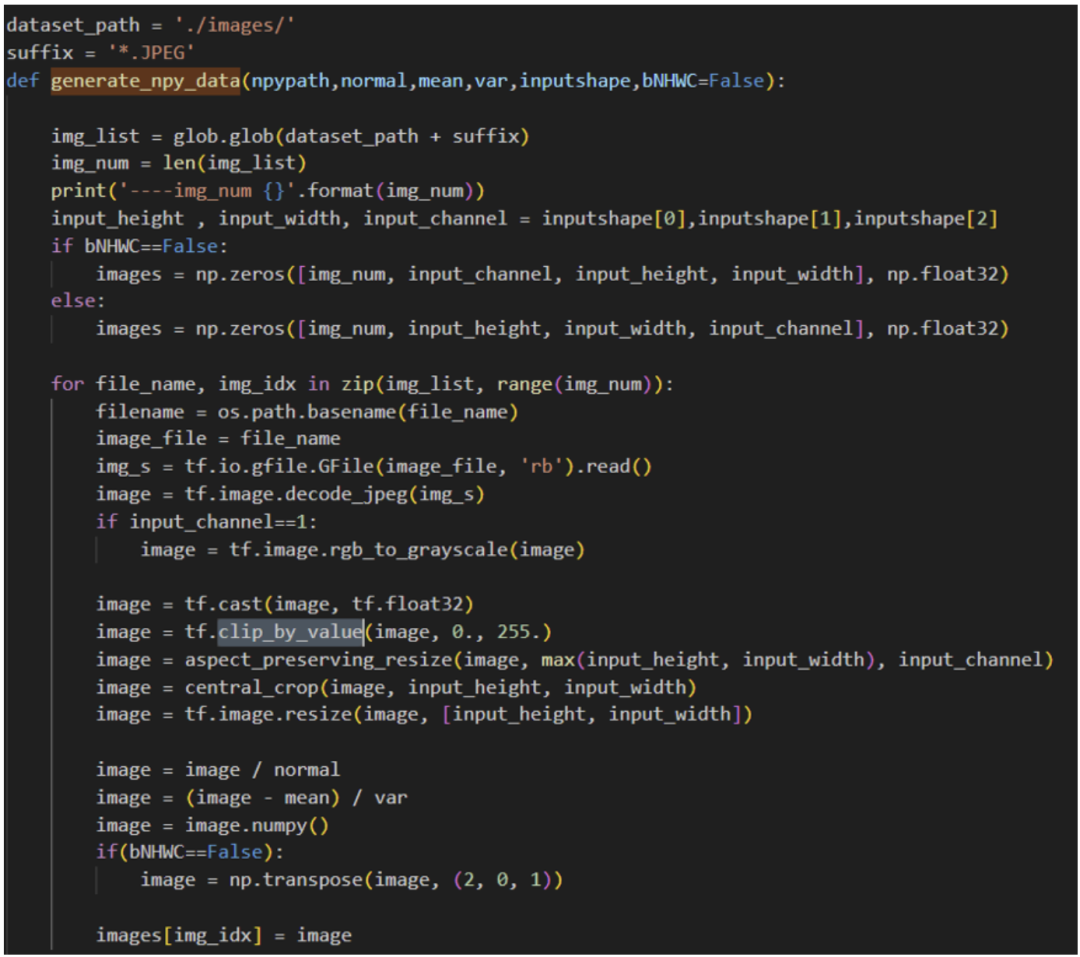
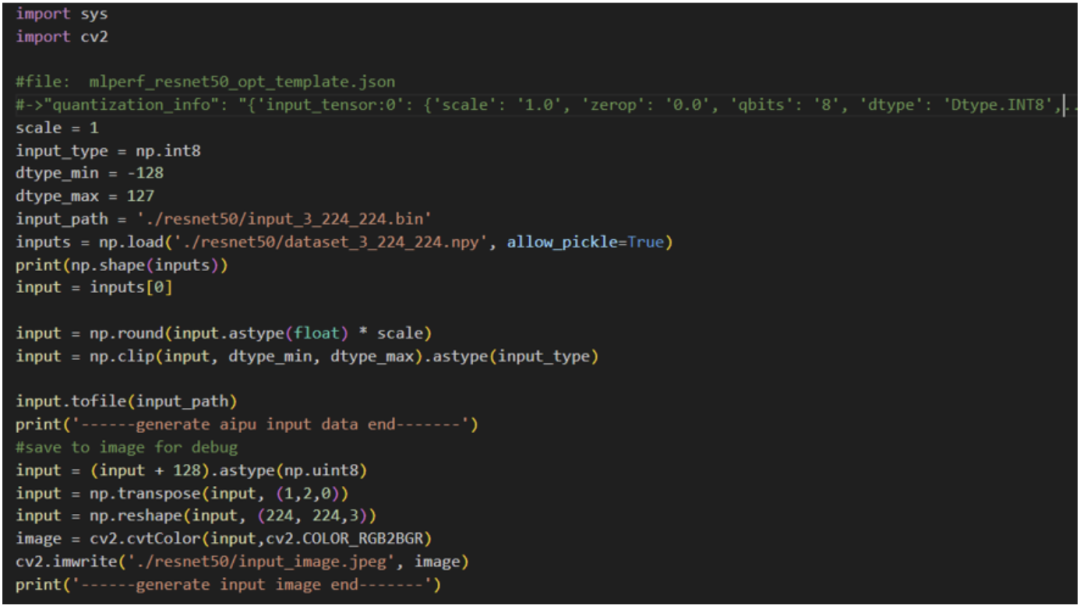
python3 generate\_input\_binary.py
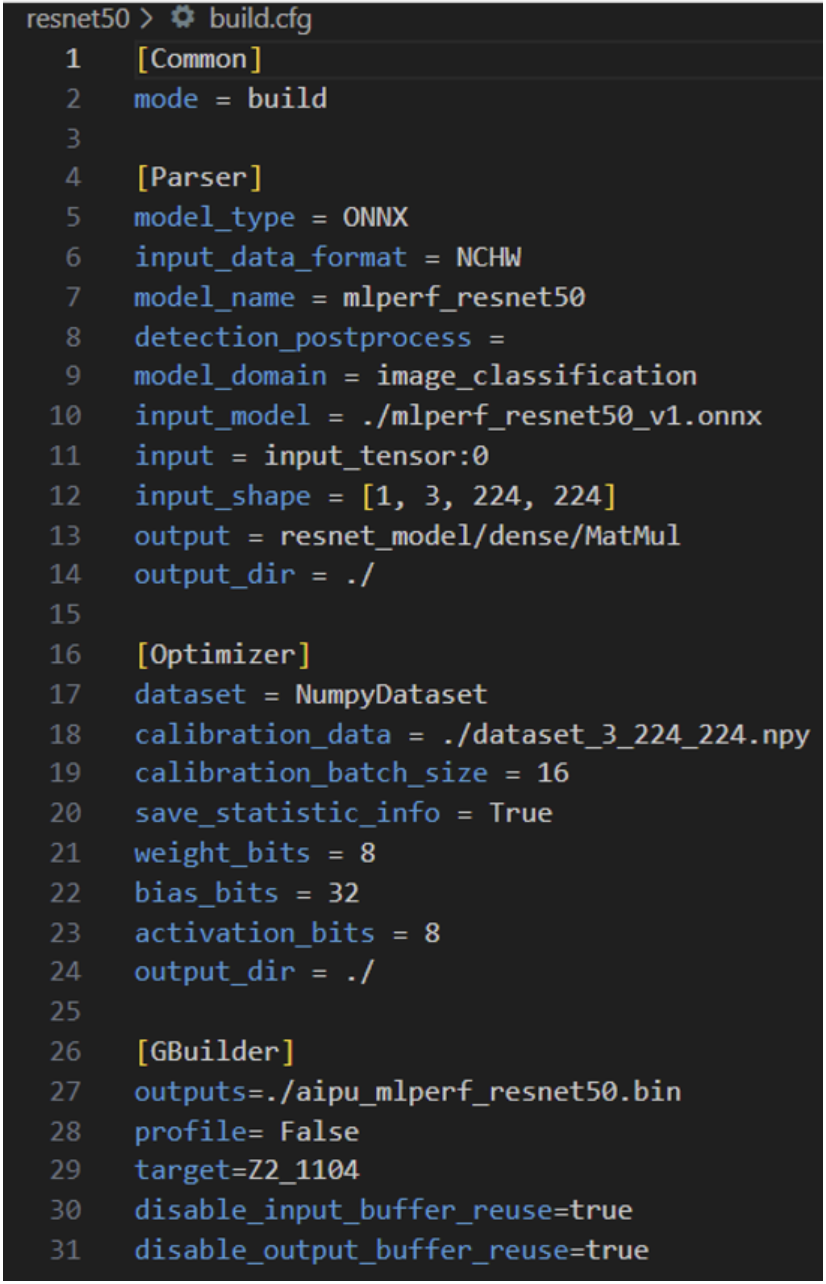
vim ./resnet50/build.cfg
解析模型;
量化
编译执行
Parser的作用是将标准的通用模型(ONNX、TF、pytorch等)转换为内部专用的IR;Input\_data\_format 指的是输入的data\_layout,我们在前面的构造输入数据时选的就是NHWC,所以这里填NHWC;模型名字model\_name,标准填就好了;Detection\_postprocess填后处理的算子名,像检测模型都是有后处理部分的,我们对应填,当然也可以选择不填,直接在CPU端做后处理;其他都是所见即所得,除了注意input的配置即可,这是输入tensor的名字,用netron打开onnx model即可得到; Optimizer中dataset字段就是指定数据集的格式,前面我们构造的是numpy格式的,所以这里填NumpyDataset;主要注意下bits部分的设置,因为一般的玩法只有这里有可调,来粗粒度的调整精度/性能的权衡,当然了,后期大家想玩的话我就带大家进行代码级的玩法。 Gbuilder部分就是直接编译的,profile就是输出perf性能数据的,会一定程度上影响性能,因此在debug阶段使用即可;target指的是硬件的版本号,这里是固定的填Z2\_1104即可,这一块没有什么需要额外配置的,当然具体的每一个参数我们可以到后面的Gbuilder章节进行详细解说,这里堪堪带过。 按照官方教程直接编译:

可以看到Gbuilder的版本是5.3.2194,开始进行解析模型了,这里由于我使用的是WSL2没有cuda,所以会比较慢

解析完后输出如上,此时就得到了我们NPU所需的中间表达格式(IR)了

得到IR后,我们会先做一个检查,看解析出来的IR格式以及graph的连接关系是否合理,再初步做一个float graph级的图优化,可以看到这里优化掉了一个Transpose层;
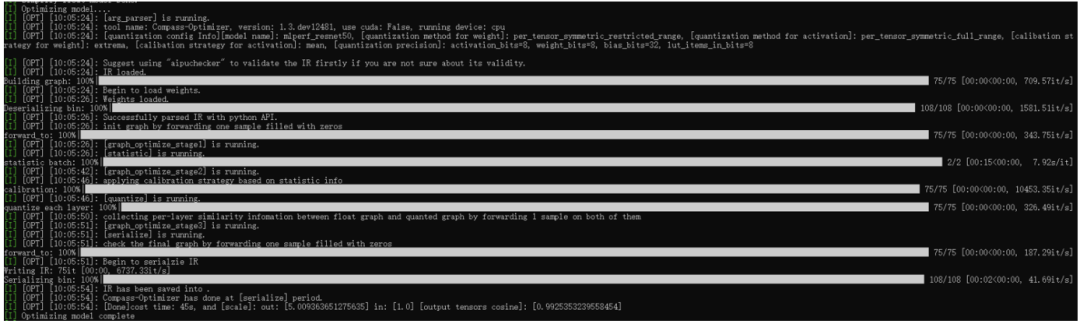
紧接着就进入量化阶段了,可以看到整个流程里面有非常多的阶段,每个阶段都有在做特定的事,这里涉及的内容比较多,我们暂且按下不表,后面我们将会对照源码进行一一解说(有机会的话,还会跟业界做的比较好的ppq框架进行相关的对比)。 这里主要关注下最后的输出scale,用来在后处理阶段使用的;以及输出tensor的cosine值,这个值是反应模型精度的。 总之,经过量化后,我们就得到了定点格式的IR,此IR经过编译后,可以直接在NPU硬件上跑起来的。

由于量化过程中也会有图结构的改变,因此这里做完量化后也需要执行图检查以及图优化步骤的。
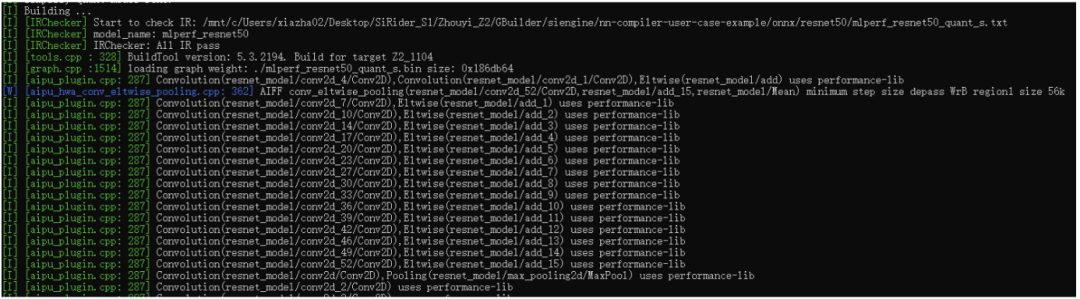
到这里后,终于开始编译模型了,这个部分主要内容包括给graph中的node进行算子匹配,整网内存分配及优化,多核调度,硬件底层图优化等。比如上图中的aipu\_plugin就是算子,每个标准算子都有好几种底层硬件实现(opencl、asm),根据特定机制进行整网全局匹配。

这里是layout的调度部分,目标就是尽可能减少途中layoutconvert的个数,这个部分也是个最优化的问题,细讲下去也就停不下来了,将来有机会我们详细说说。
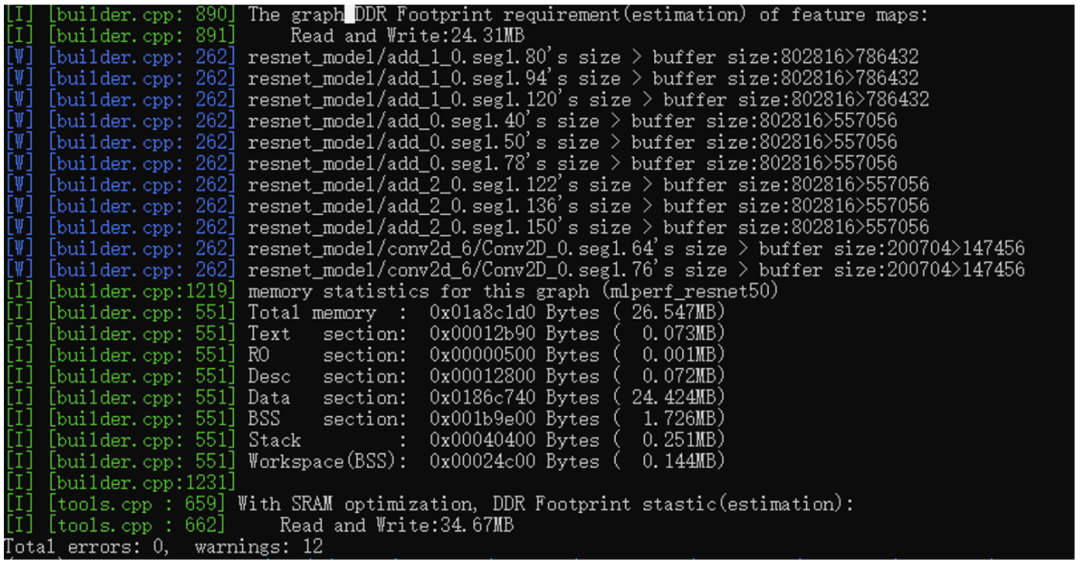
最后就是内存部分的内容了,整网所需的内存是26.547MB,代码段、RO段、desc段(这个不常见,这是底层算子的特定格式),DataBss都是标准格式。最后可以看到是有个SRAM的优化的,这个是NPU内部的一个快速静态存储区域,用来缓存node间的featuemap的,不仅能降低footprint还能提升性能。 好了,到这里,模型终于编好了,我们看下编出了些啥:
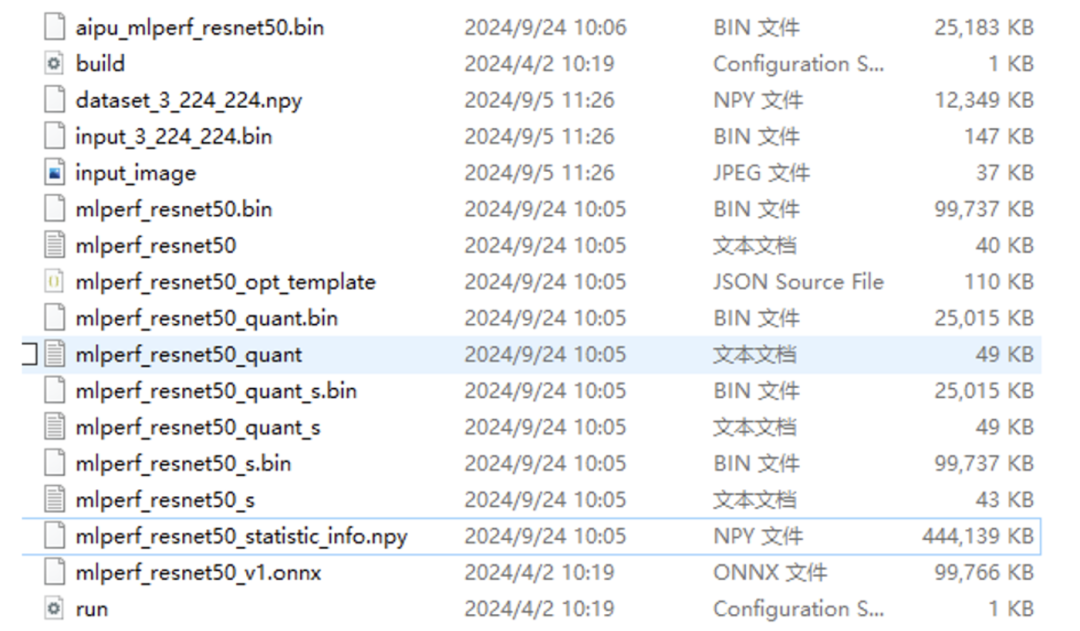
第一个文件就是我们NPU需要的可执行文件,也就是在build.cfg指定的输出文件;
第二个文件就是build配置脚本;
第三个时量化校准数据集;
第四个时输入数据,第五个是输入数据对应的图片;
第六个、第七个就是parser后得到的浮点IR文件(图结构文件以及权重文件);
第八个是量化产生的文件,有啥量化的问题你去这个文件内查查即可;
第九个、第十个是量化后产生的定点IR;
第十一个、第十二个文件是定点IR经过图优化后的精简IR;
第十三个、第十四个是浮点IR经过图优化后产生的IR;
第十五个文件是验证集的统计信息,有这个文件后,下次编译就不用继续跑耗时的校准过程了;
第十六个文件是原始的resnet50.onnx模型;
第十七个文件是 run的时候(不是跑在NPU上而是在PC上跑simulator用的)用的cfg配置文件;
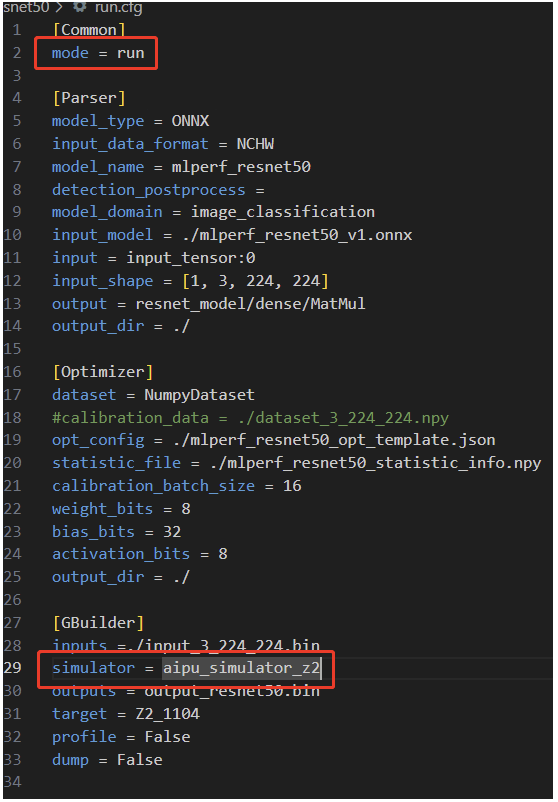
可以看到除了红框内的东西外,其余都是差不多的。 现在我们生成了模型的bin文件,但还不是最终应用的可执行文件,最终的应用是调用我们刚刚生成的模型,这部分的代码在这:
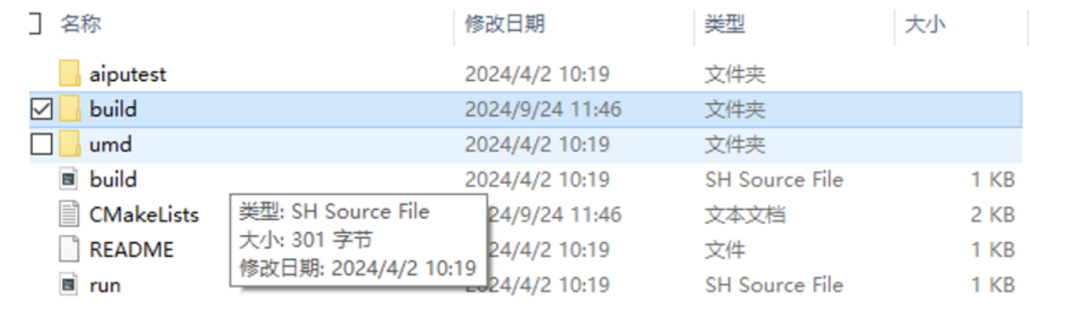
Aiputest就是应用程序的逻辑部分,umd里面就是一堆面向用户的库函数,库函数里面是直接调用驱动,以及环境构建的(待会我们直接进去看下代码结构)。 按照软件工程的结构,我们先查看顶层的CMakeLists.txt文件,获取到的信息如下:
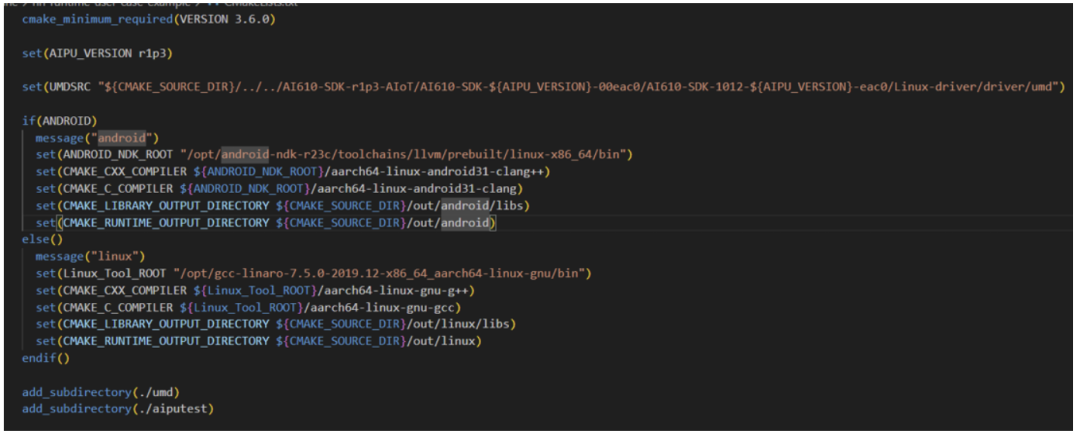
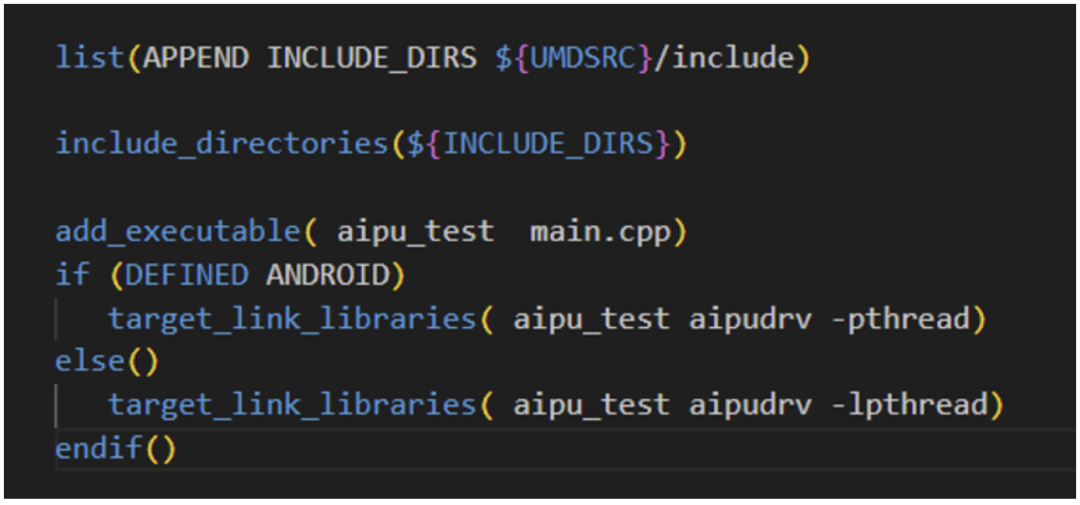
Cmake版本要搞对噢,UMDSRC变量要仔细检查对路径哈!设置好交叉编译器的路径,设置好最终的输出路径; 顶层配置好参数,然后直接add\_subdirectory让子目录自己去根据参数执行具体的编译任务。 我们先看umd文件夹,里面直接Linux-driver/driver/umd的源码拉进来编成动态库,给后面的应用aiputest来动态链接。
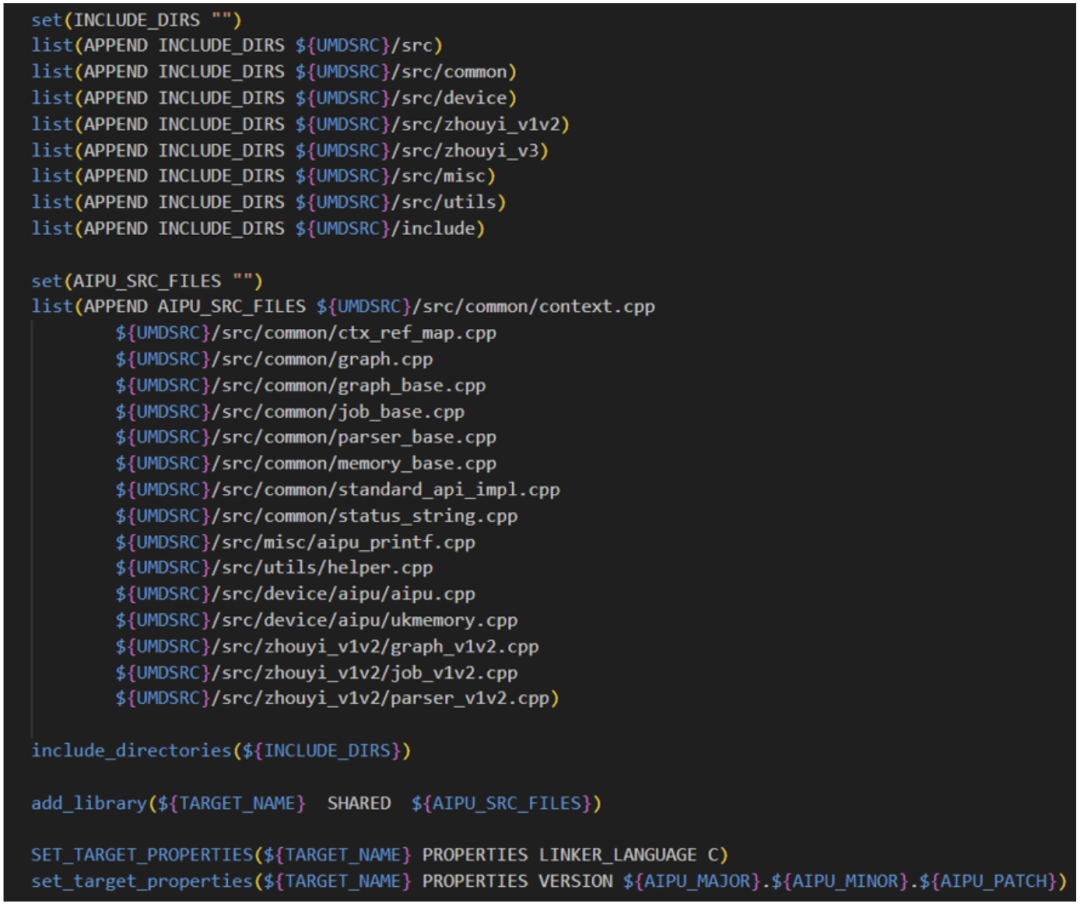
Aiputest是个非常简单的应用,因此我们只需要将umd头文件引进来,umd动态库链接进来,直接编译即可。
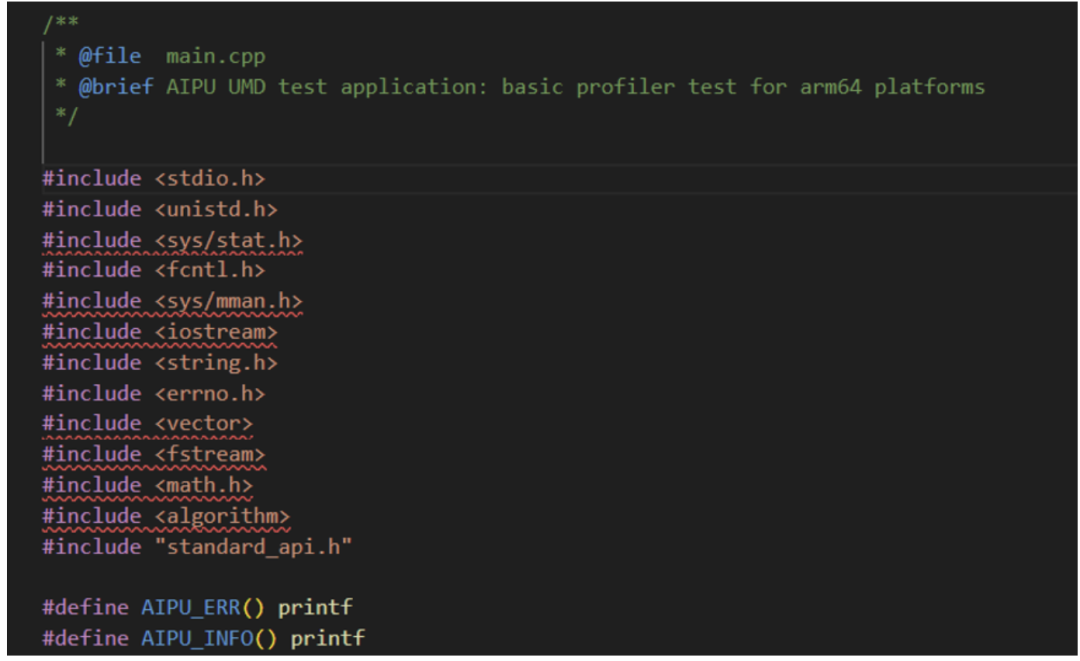
我们看下main.cpp文件中的内容结构:
其中UMD相关的功能全都封装到standard\_api.h接口文件中了,接下来的代码无非就是初始化环境,开启NPU任务,接受返回数据,清理“战场”(环境)等标准步骤,没啥特殊的,具体参数解析可以查文档或者等我后续的文章逐代码解析。 (ps. 其中可以看到虽然是c++环境,但是用的都是非常标准的c代码风格,挺好的,非常适合用来直观理解执行流程。)
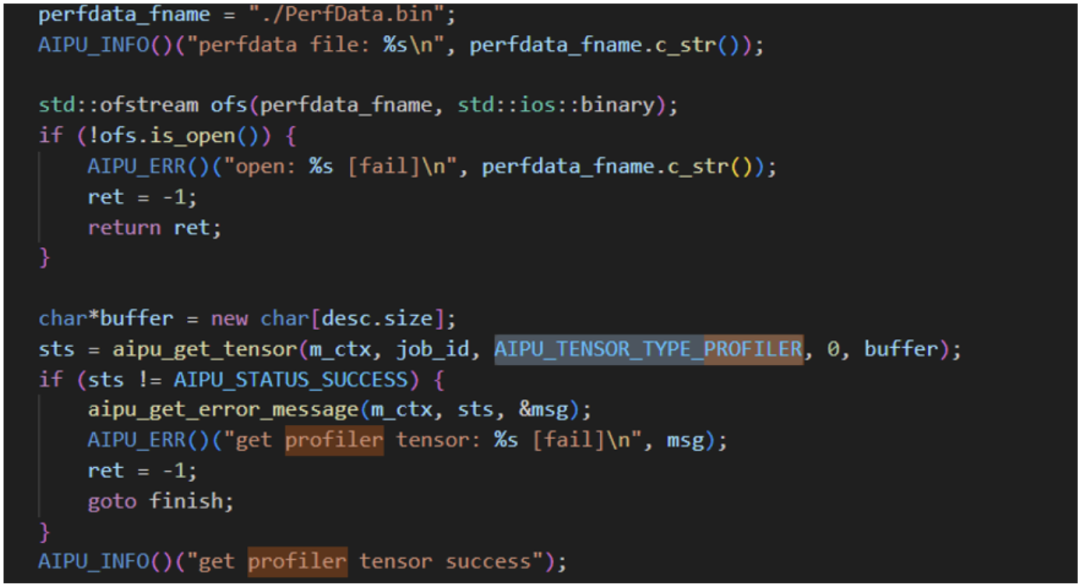
研究代码发现这里有dump profiler的逻辑;
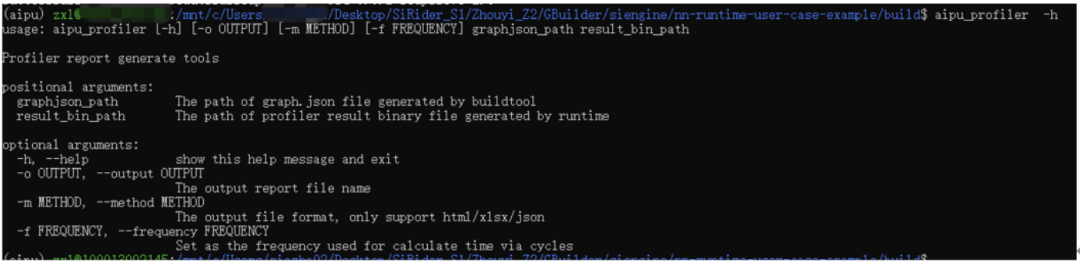
应用中也是有profiler的程序的,其中result\_bin\_path就是上面代码中输出的PerfData.bin文件,因此我们可以留个坑,将来讲讲如何用这个来分析模型的性能优化。 好了,视角拉回,我们直接编译得到了对应的文件,
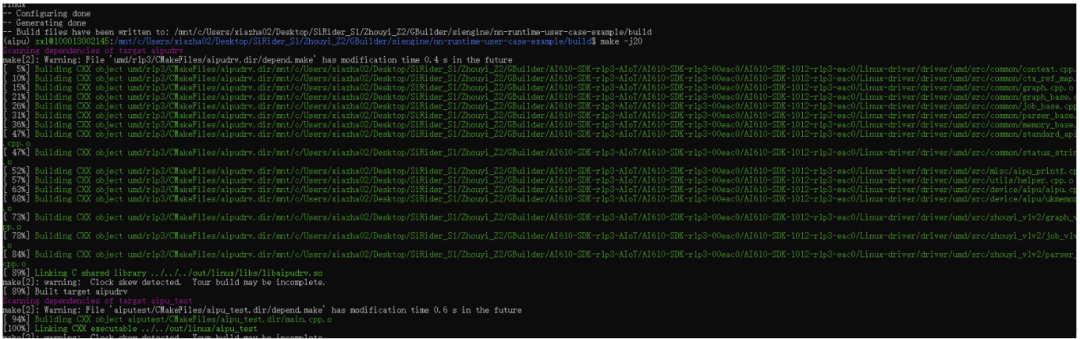
按照官方教程的步骤将文件scp到板子后,直接就可以跑啦~
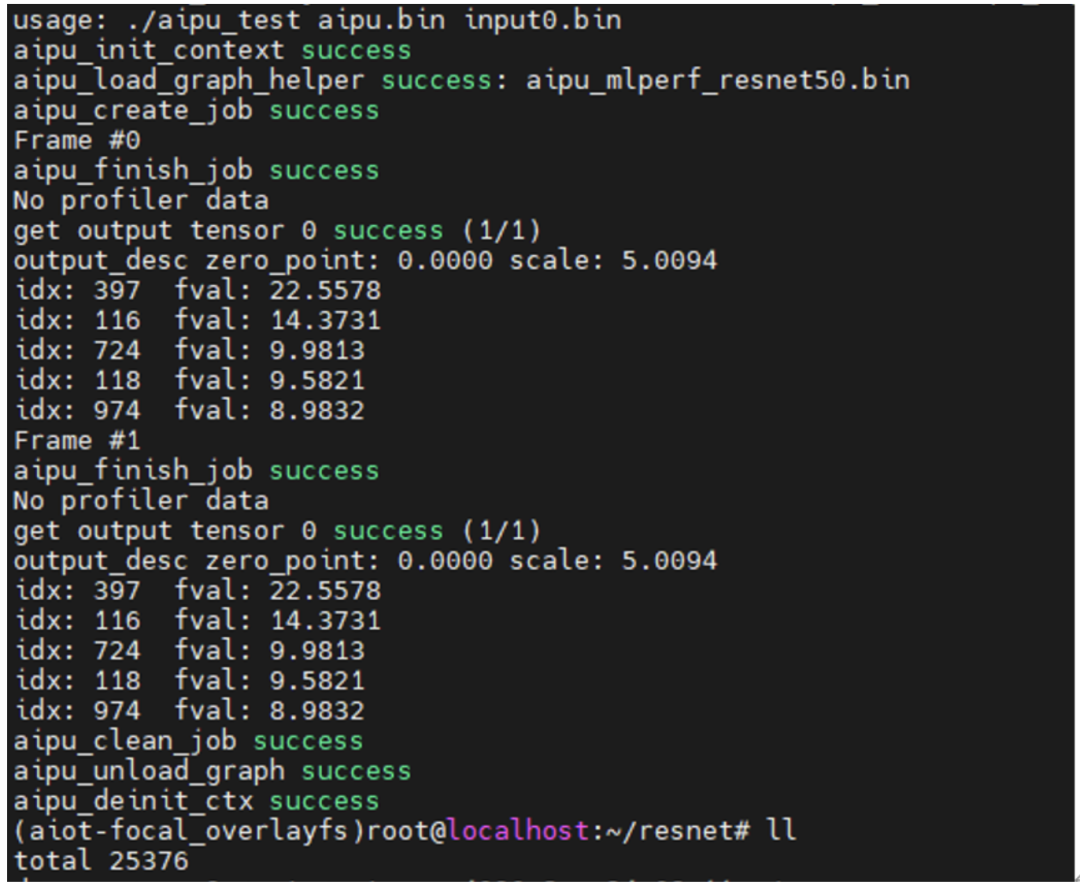
-
请问有没有用过奥科航母一号开发板的。2012-06-06 0
-
基于安芯一号开发板设计2013-11-12 0
-
安心一号开发板2014-01-15 0
-
请问神舟一号开发板上的启动文件有什么用?2019-06-28 0
-
洋桃一号开发板测试U盘有什么问题?如何去解决?2021-07-06 0
-
RT-Thread的麻雀一号开发板介绍2021-07-29 0
-
怎样去使用RT-Thread麻雀一号开发板呢2021-11-01 0
-
芯擎科技发布首款车规芯片“龍鹰一号”2021-12-15 633
-
云芯一号试用教程一:开箱上手及基本配置2022-01-26 423
-
云芯一号-QT应用开发环境2022-01-26 314
-
芯擎科技助力“龍鷹一号”快速验证和实现量产2022-06-16 1482
-
芯擎科技7纳米智能座舱芯片“龍鷹一号”正式上车领克082023-04-26 693
-
智能手机与星火一号开发板之间的WIFI通讯设计实现2023-08-01 1475
-
龍鹰一号实力验证,领克06 EM-P官宣搭载2023-11-07 1087
-
“龍鹰一号”迎来出货量20万片里程碑,助力首搭车型成为爆款,众多搭载车型陆续上市2023-12-26 675
全部0条评论

快来发表一下你的评论吧 !
