

超越人类视觉!昱感微“多维像素”多模态超级摄像头方案产品赋能超凡感知力
描述
如今人工智能发展之日新月异,令人不由感叹也许科幻电影里仿生人的应用不再是遥不可及,那么未来AI会超越人类甚至取代人类吗?也许现在AI的大脑还无法做到,但眼睛已经做到,机器视觉的感知力已全面超越人类视觉——人眼只能感知所见目标大概的距离/位置/速度以及外观信息,并且受到天气、光线等因素影响较大;昱感微“多维像素”多模态感知方案的超级摄像头每秒可输出30帧(甚至更高频率)多模态融合感知数据,每一帧不仅有高清图像数据,还有对应像素级的目标精准3D空间位置坐标距离、速度、温度(目标热辐射)、对应材质(RCS)等数据,并且感知力不受天气、光线等因素影响。
多模态融合感知的“多维像素”数据
那么昱感微“多维像素”多模态感知超级摄像头是如何做到的呢?首先,昱感微采用最前沿的多维像素多模态前融合技术,将可见光摄像头、红外摄像头、4D毫米波雷达/激光雷达的探测数据在前端(数据获取时)融合,并将各传感器的探测数据“坐标统一、时序对齐”,最后以“多维像素”的数据格式输出;昱感微的核心技术创新——“多维像素”,它是指在可见光摄像头像素信息上加上其它传感器对于同源目标感知的信息:即图像数据+雷达探测目标的距离、速度、散射截面R的感知数据+红外传感器探测的热辐射图像数据叠加组合到一起,以摄像头的像素为颗粒度组合全部感知数据,每个像素不仅有视觉信息,还包含了雷达和红外传感器的探测数据,形成多维度(多模态)测量参数矩阵数组。
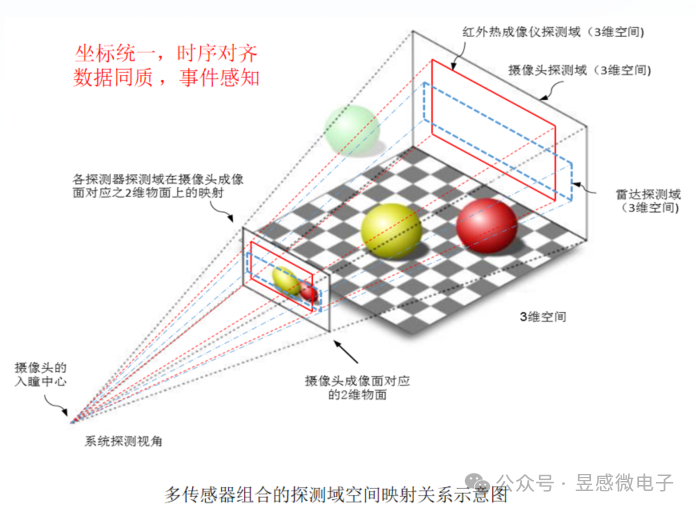
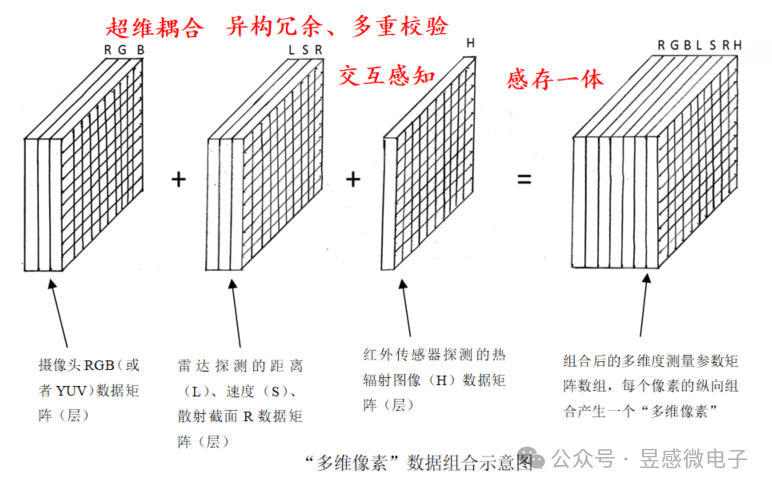
目前的传感器融合感知技术存在的挑战,正如埃隆马斯克所说的:“激光雷达和雷达与视觉结合所带来的感知不一致性使得这些技术无法达到理想的效果”,昱感微的“多维像素”多模态感知方案能够帮助大家彻底解决这个技术难题, 而且还能达到1+1>2的效果。在高分辨率宽动态的可见光摄像头感知基础上,雷达提供目标的距离、速度维度的精准感知还可以帮助可见光摄像头克服天气光线的影响,摄像头的图像又为雷达增添了语义信息,进一步提高雷达点云的置信度以及感知信息量;远红外摄像头有针对性的目标热辐射图像感知则赋予了自动驾驶系统卓越的夜视能力。昱感微“多维像素”超级摄像头就像是一双比人眼更敏锐的眼睛,看到的不仅仅是一幅幅二维的图像,还有更多维度的精确信息(目标的距离/速度/3D空间位置/温度/材质等),形成完整的多模态“视觉语言”,令自动驾驶系统可以精确全面地感知道路上各种状况。
提升性能+降本增效,融合感知的最优解
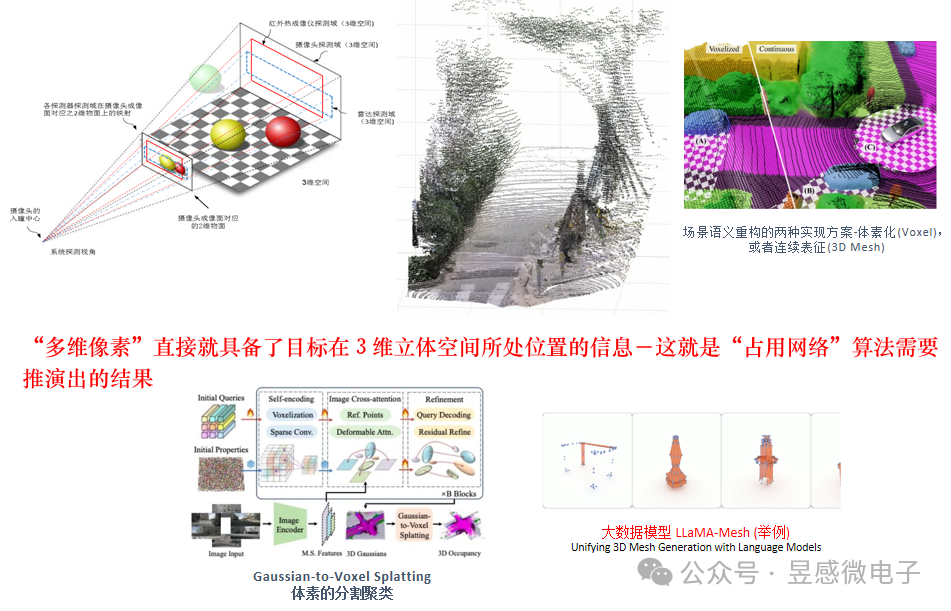
多维像素还可以直接高效支持“占用网络” (Occupancy Network)算法。占用网格是指将感知空间划分为一个个立体网格(体素),通过检测网格空间是否被占用来完成3D空间场景的语义表征(包括探测到各类异形物体)——这也是特斯拉等车厂目前力推的视觉算法。昱感微的“多维像素”包含了目标的图像信息、3D空间位置信息、目标的速度信息和材质信息,可以直接高效实时支持占用网格中的体素算法。并且,昱感微目前已经可以提供的产品的空间感知分辨率(右下图)的精准度远高于特斯拉公开方案中的体素颗粒度(左下图)。

基于“多维像素”感知数据来做场景语义重构(体素Voxel,或者,立体连续表征3D Mesh),然后支持大数据模型,是最精准高效并节省算力的实现方法。
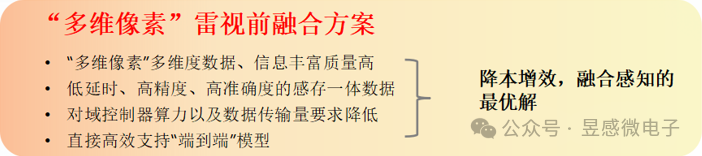
昱感微“多维像素”超级摄像头方案实时输出丰富高质量的多维度感知数据,其对目标与环境的3D物理空间感知与定位精度可以达到图像像素级的精度,多模态感知精度大幅优于人类视觉;此外,得益于“多维像素”包含的丰富高效的感知数据在输出时就已经完成了全部目标感知数据(对应图像像素)的确认与精准定位,“多维像素”超级摄像头方案可大幅降低系统对域控制器算力的要求,并且还能够高效支持“端到端”感知系统以及生成式验证系统(高效支撑数字化场景重构)。“多维像素”数据的组合格式在不降低感知有效信息量的前提下大幅降低了数据体量,传感器感知端侧的感知数据传输到中央域控端的系统传输成本也可以进一步降低。总体来看,昱感微“多维像素”超级摄像头方案可为客户提升性能、降本增效,是融合感知的最优解。
审核编辑 黄宇
-
未来已来,多传感器融合感知是自动驾驶破局的关键2024-04-11 0
-
“多维像素”超级摄像头方案-(摄像头+毫米波雷达组合)演示视频sensemi 2024-11-05
-
【Firefly RK3399试用体验】+ 双目摄像头校准2017-09-17 0
-
【案例分享】机器视觉应用的摄像头设计2019-07-19 0
-
想用wifi和500万像素到1200万像素摄像头,做个监控的产品,android手机app可以收到2020-04-20 0
-
联想Z6 Pro公布相机支持超级微距后置单个摄像头达到亿级像素2019-04-12 2287
-
广和通5G/4G智能模组赋能车载摄像头2022-01-21 3072
-
汽车的”眼镜“:广和通高算力智能模组全程赋能车载摄像头2022-01-19 815
-
什么是车载摄像头?车载摄像头与雷达技术对比有哪些优势2023-07-04 4078
-
感知融合为自动驾驶与机器视觉解开当前无解场景之困2024-10-29 542
-
昱感微“多维像素”超级摄像头产品方案发布!2024-11-06 331
-
YGW-L1产品简介2024-11-20 55
-
YGW-R1产品简介2024-11-20 73
-
YGW-L2产品简介20241202V022024-12-02 50
-
昱感微争得首届供应链技术解决方案赛榜首,荣获车路云一体化智链先锋奖!2024-12-06 144
全部0条评论

快来发表一下你的评论吧 !
