

Flexus X 实例 ultralytics 模型 yolov10 深度学习 AI 部署与应用
电子说
描述
前言:
���深度学习新纪元,828 B2B 企业节 Flexus X 实例特惠!想要高效训练 YOLOv10 模型,实现精准图像识别?Flexus X 以卓越算力,助您轻松驾驭大规模数据集,加速模型迭代,让 AI 智能触手可及。把握此刻,让创新不再受限!
���本实验演示从 0 到 1 部署 YOLOv10 深度学习 AI 大模型的环境搭建、模型训练、权重使用,以及各项指标解读。实验环境为 Flexus 云服务器 X 实例 服务器,配置:4vCPUs | 12GiB
环境准备
购买服务器配置
本次实验使用的是 Flexus 云服务器 X 实例 服务器。

在性能设置中我选择了自定义模式,使用了 4vCPUs | 12GiB,因为本次要实验的是 yolov10 的部署与应用,Windows 操作系统具有更加直观的用户界面和强大的图形支持,我选择了公共镜像 Windows Server 2022 数据中心版。以上配置仅供参考,并非硬性要求!
连接服务器
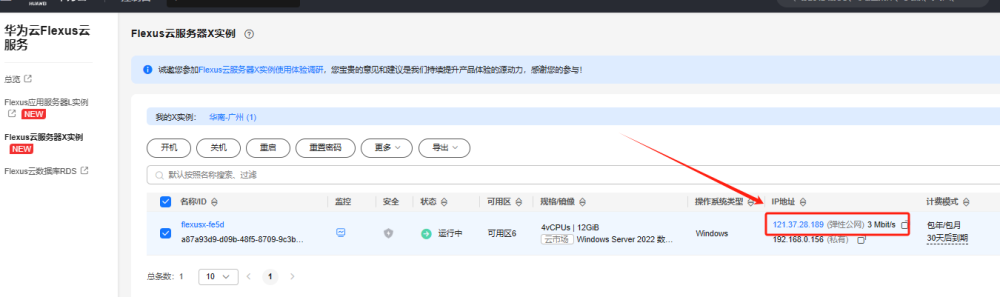
在华为云服务器控制台中找到我们刚刚购买的服务器,将弹性公网 IP 地址复制下来。
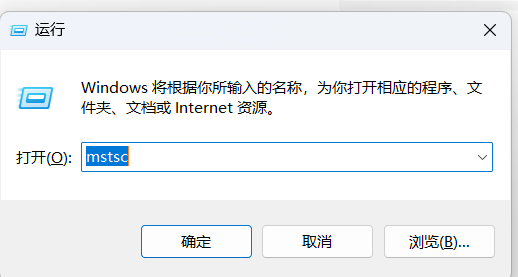
快捷键 Windows + R 打开运行窗口,输入 mstsc,回车!
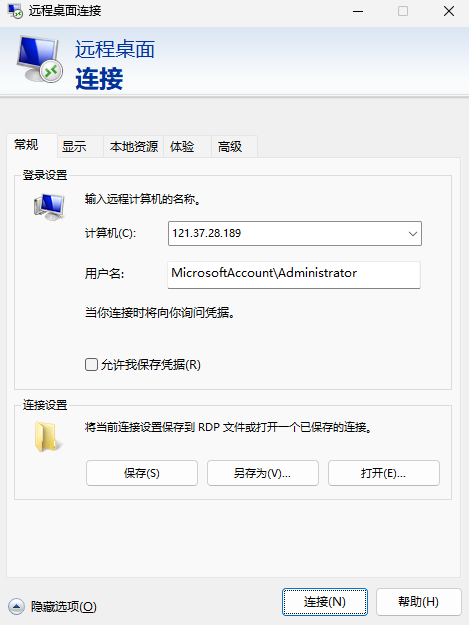
输入计算机:弹性公网 IP 地址;用户名:MicrosoftAccountAdministrator,单击“确定”。
然后输入密码,就成功的连接到我们的服务器了。
如果忘记密码了,可以在操作列中点击重置密码,重新设置我们的服务器密码。
安装 Python
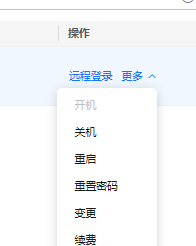
我们先来安装 python3,打开官网地址
Download Python | Python.org
在官网下一个大于大于 3.8 的 python 安装包(官方建议使用 3.9 的版本),选择 amd64 的 exe 版本
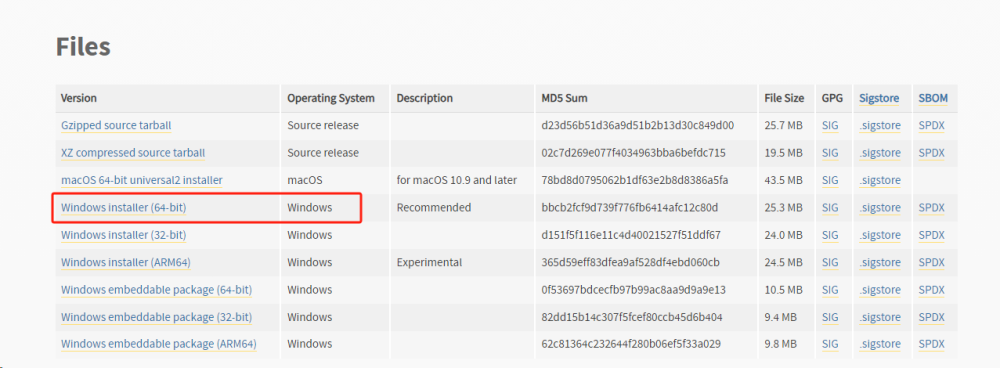
安装的时候勾选最底下的帮我们添加环境变量
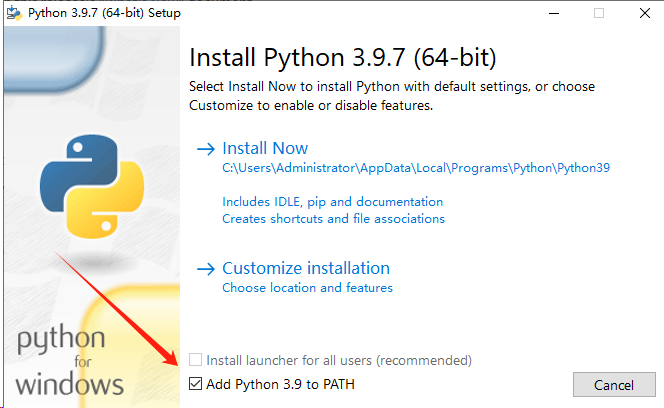
等待片刻,出现下面这个界面就是安装成功了。
CMD 打开控制台小黑窗,执行 python -V 和 pip -V 查看 python 版本与 pip 版本,看看我们的环境变量是否设置成功。

安装 Pytorch
到官网安装 Pytorch
Start Locally | PyTorch
在安装之前看看自己买的服务器是否有 GPU,可以使用命令来查看
查看 CPU 型号:cat /proc/cpuinfo | grep "model name"
查看 GPU 型号(Nvidia GPU):nvidia-smi --query-gpu=gpu_name --format=csv
查看 GPU 型号(AMD Radeon GPU):sudo lshw -C display
因为我这台是只有 CPU 的,因此在官网中选择 Stable(稳定版),系统 Linux,用 pip 来安装吧,然后 Compute Platform 选择 CPU,然后把 Run this Command:中的命令���cmd 打开黑窗口执行。
我这里执行的是
pip3 install torch torchvision torchaudio 直接执行可能会很慢,我在后面加上指定镜像源,切换为国内镜像 pip3 install torch torchvision torchaudio -i https://pypi.mirrors.ustc.edu.cn/simple/
出现如下画面即是成功下载完成。
部署 YOLOv10
YOLOv10 是 YOLO(You Only Look Once)系列的最新版本,由清华大学的研究人员开发,旨在进一步提高实时目标检测的效率和准确性。以下是对 YOLOv10 的详细介绍:
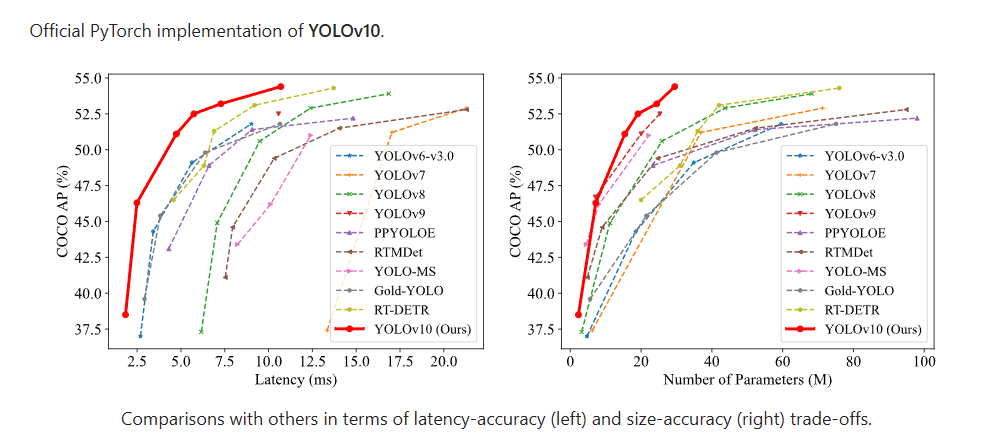
之前的 YOLO 版本在后处理和模型架构方面仍存在不足,特别是依赖于非最大抑制(NMS)进行后处理,这限制了模型的端到端部署并增加了推理延迟。YOLOv10 通过消除 NMS 和优化模型组件,旨在解决这些问题,实现更高的性能和效率。
拉取 YOLOv10 代码并安装相关依赖
打开 YOLOV0 的 GItHub 代码库,将源码下载到本地,解压。
GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
解压完成后,打开命令行窗口,cd 到源码的工作目录,执行下面两个命令。


当以上相关依赖都安装完毕后,执行以下训练命令测试我们的环境(此步骤可跳过)。
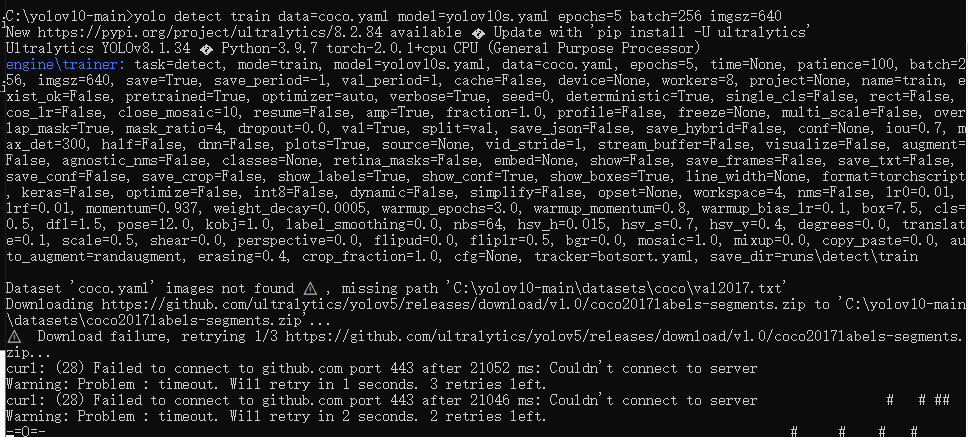
yolo detect train data=coco.yaml model=yolov10s.yaml epochs=5 batch=256 imgsz=640
第一次执行会自动下载官方提供的训练案例文件,需要等待较长时间。
数据集准备
YOLOv10 作为实时目标检测模型,理论上支持多种类型的数据集,只要这些数据集符合 YOLOv10 的输入格式和标注要求。具体来说,YOLOv10 可以支持的数据集包括但不限于以下几种类型:
1. 通用目标检测数据集:如 COCO(Common Objects in Context)数据集,这是一个大型、丰富的图像数据集,用于目标检测、分割、关键点检测等多种任务。YOLOv10 在 COCO 数据集上取得了显著的性能提升,展现出优异的精度-效率平衡能力。
2. 特定领域数据集:YOLOv10 也可以应用于特定领域的数据集,如交通标志检测数据集、人脸检测数据集、车辆检测数据集等。这些数据集通常针对特定场景或任务进行收集和标注,以满足特定领域的需求。
3. 自定义数据集:用户还可以根据自己的需求创建自定义数据集,并使用 YOLOv10 进行训练和测试。自定义数据集需要按照 YOLOv10 的输入格式进行标注和组织,包括图像文件、标签文件以及可能的数据集配置文件等。
通常来说,我们需要将标注结果与原图按比例分配到三个文件夹中
如你有 100 张标注了的图片,大约 80 张图片用于训练数据,约 10 张图片用于验证数据,约 10 张图片用于测试数据
train 路径用于训练模型,val 路径用于验证模型,test 路径用于测试模型。在训练和验证期间,模型将在不同的数据集上进行训练和验证,以便评估模型的性能。在测试期间,模型将使用整个数据集进行测试,以确定其性能指标
需要注意的是:训练过的图片通常不能用于验证数据。这是因为在训练期间,模型已经对这些图片进行了训练,并学会了识别这些图片中的对象和场景类别。
因为数据标注要花费大量的时间,这里直接拿出我最爱的皮卡丘标注数据
400多张“皮卡丘”原图与标注结果以及yolov8的训练结果best.pt权重和ONNX格式文件_yolov8权重转onnx资源-CSDN文库
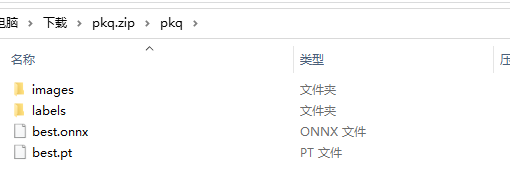
在这个压缩包中有皮卡丘图片与标注信息,还有 yolov8 的训练好的权重文件,我们只留下 images 和 labels 用来训练 yolov10 版本的权重。
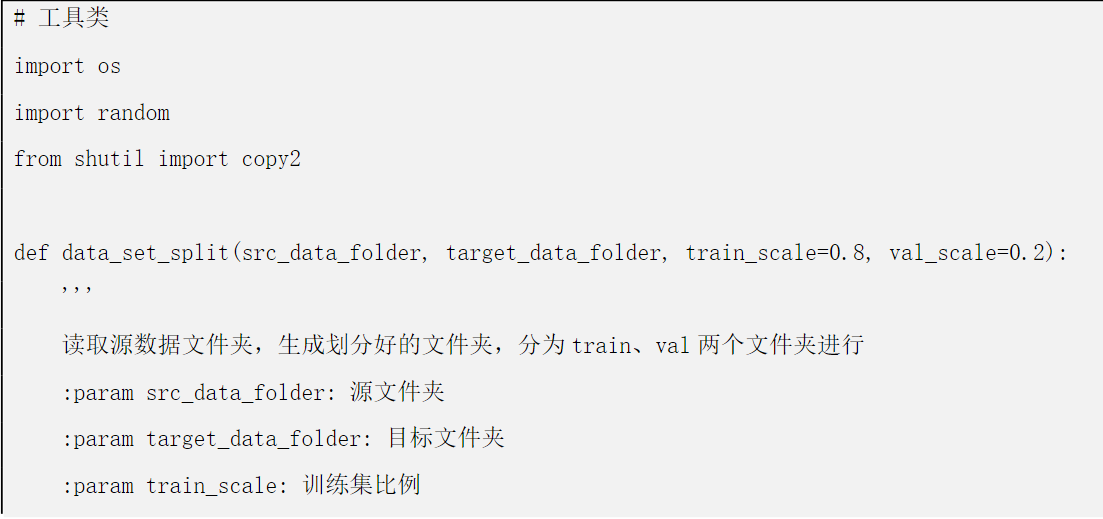
因为我比较懒,能用代码解决的事就用代码,下面我们使用 python 对数据集进行随机分配。
修改下面代码中 66-67 行中的
src_data_folder = '数据集路径' target_data_folder = '处理后的数据集'




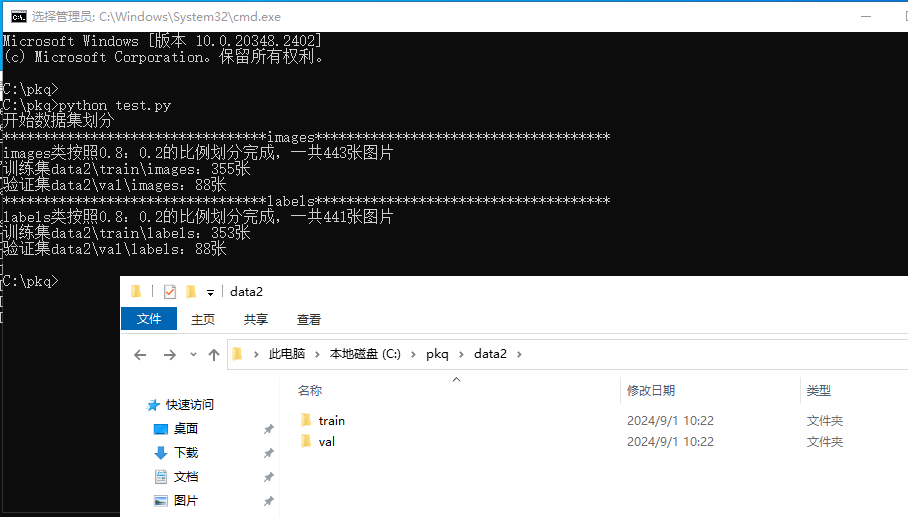
因为在 yolo 训练中,我们并不需要将图片和标注结果分开存放,因此我们将 train 和 val 中的 images 和 labels 里的文件都全部移出来,然后将这两个文件夹删掉即可。
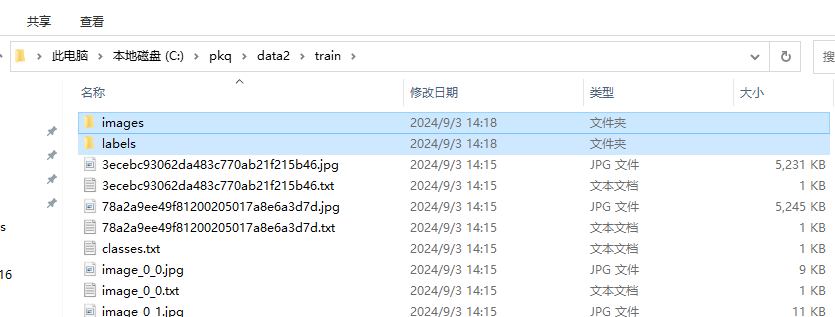
要注意的是,不管是 train 还是 val 都需要检查是否包含这么一个 classes.txt 文件,如果没有的话需要自己手动补上,因为我这里的素材只有一个皮卡丘目标,并且标注为 1 了,所以只写了一个 1。
训练数据集的配置文件
参考路径 C:yolov10-mainultralyticscfgdatasets 找到 voc.yaml,复制一份,自定义一个名字
执行完识别命令后,可在输出信息中看到识别结果文件所在位置,detectpredict(数字会自动叠加)
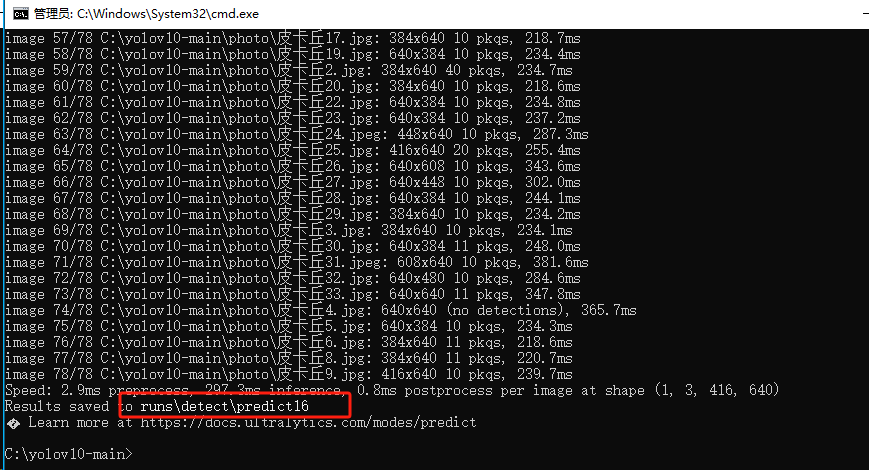
任意打开一张图片,找出识别前的图片对比一下,皮卡丘已经被框出来了,并打上我们设置的 pkq 标签。
至此~我们就完成了 YOLOv10 目标检测模型的训练与识别工作了!整个实验操作下来,Flexus 云服务器 X 实例的表现都是非常出色的!
审核编辑 黄宇
-
人工智能AI-卷积神经网络LabVIEW之Yolov3+tensorflow深度学习有用吗?2020-11-27 0
-
labview调用深度学习tensorflow模型非常简单,附上源码和模型2021-06-03 0
-
龙哥手把手教你学视觉-深度学习YOLOV5篇2021-09-03 0
-
【爱芯派 Pro 开发板试用体验】爱芯元智AX650N部署yolov8s 自定义模型2023-11-24 0
-
使用YOLOv8做目标检测和实例分割的演示2023-02-06 7496
-
使用旭日X3派的BPU部署Yolov52023-04-26 909
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8-seg实例分割模型2023-06-05 1014
-
三种主流模型部署框架YOLOv8推理演示2023-08-06 2748
-
用OpenVINO C# API在intel平台部署YOLOv10目标检测模型2024-06-21 1037
-
AI大模型与深度学习的关系2024-10-23 732
-
YOLOv10:引领无NMS实时目标检测的新纪元2024-11-13 687
-
YOLOv10自定义目标检测之理论+实践2024-11-16 466
-
基于 Flexus 云服务器 X 实例体验大模型部署体验测评2024-12-24 99
-
华为云 Flexus X 实例 MySQL 性能加速评测及对比2024-12-25 126
全部0条评论

快来发表一下你的评论吧 !
