

一种基于MapReduce模型的并行化k-medoids聚类算法
电子说
描述
摘要:
随着电力通信技术的发展,产生了大量分布式电力通信子系统以及海量电力通信数据,在海量数据中挖掘重要信息变得十分重要。聚类分析作为数据并行化处理和信息挖掘的一个有效手段,在电力通信中得到了广泛的应用。然而,传统聚类算法在处理海量电力数据时已不能满足时间性能的要求。针对这一问题,提出了一种基于MapReduce模型的并行化k-medoids聚类算法,首先采用基于密度的聚类思想对k-medoids算法初始点的选取策略进行优化,并利用Hadoop平台下的MapReduce编程框架实现了算法的并行化处理。实验结果表明,改进的并行化聚类算法与其他算法相比,减少了聚类时间,提高了聚类精度,有利于对电力数据的有效分析和利用
0 引言
随着电力通信网络以功能为中心持续性发展,产生了大量分专业、分功能和分管理域的运维管理系统,进而导致大量电力数据孤岛的产生。如何利用分布式系统更好地处理这些数据量巨大且类型复杂的电力通信运维数据已成为研究的热点问题。聚类分析作为数据处理的一个有效手段,支持对大量无序分散数据进行整合分类从而进行更深层次的关联性分析或者数据挖掘,在电力通信网络中得到越来越广泛的应用。同时,分布式系统中并行化处理机制因其优秀的灵活性和高效性逐渐成为数据挖掘的一个重要研究方向。
国内外学者也越来越对这方面加大关注,文献[1]提出了一种基于DBSACN算法的并行优化的聚类算法。文献[2]中通过计算距离选择最中心的k个数据点作为初始聚类中心,然后用k-medoids算法进行迭代聚类,提高了聚类效果,但不适合处理大规模数据;文献[3]提出了一种蚁群 k-medoids 融合聚类算法,该算法不需要人为确定类簇数目和初始聚类中心,提高了聚类效果,但也仅只适用于小型数据集;文献[4]采用基于粒计算的聚类算法,该算法在初始聚类中心的选取过程中的计算量较大,且在处理大规模数据时存在时延问题;文献[5]提出了将局部搜索过程嵌入到迭代局部搜索过程中的方法,显著减少了计算时间。文献[6]在Hadoop平台上实现了传统k-medoids聚类算法的并行化处理,减少了聚类时间,但在初始聚类中心的选取机制上没有进行改进,没有提高聚类效果;文献[7]采用基于核的自适应聚类算法,克服了k-medoids 的初值敏感问题,但是没有降低算法的时间复杂度。
综上所述,k-medoids聚类算法存在初始值敏感、运行速度慢、时间复杂度较高等问题,需要对k-medoids算法中初始点选取以及并行化方式进行算法优化设计。
1 k-medoids聚类初始点选取改进机制
k-medoids算法是一种基于划分的聚类算法,具有简单、收敛速度快以及对噪声点不敏感等优点,因此在模式识别、数据挖掘等领域都得到了广泛的应用。k-medoids算法初始中心点的选取十分重要,如果初始中心点选择的是离群点时,就会导致由离群点算出的质心会偏离整个簇,造成数据分析不正确;如果选择的初始中心点离得太近,就会显著增加计算的时间消耗。因此本文算法首先对初始中心点的选取进行优化。基于密度的聚类可以很好地分离簇和环境噪声,所以本文采用基于密度的聚类思想,尽量减少噪声数据对选取初始点的影响。
定义1:点密度是对于数据集U中的数据集的样本点x,以x为球心,某一正数r为半径的球形域中所包含样本点的个数,记作Dens(x)。其中:

本文算法中,首先对每个数据点并行计算点密度,并将点密度作为该数据点的一个属性。选取初始聚类中心的具体步骤如下:
(1)计算数据集中m个数据点之间的距离。
(2)计算每个样本点的点密度Dens(xi)以及均值点密度AvgDens,将点密度大于AvgDens的点即核心点存入集合T中,并记录其簇中所包含的数据点。
(3)合并所有具有公共核心点的簇。
(4)计算各个簇的类簇密度CDens(ci),选择其中k个较大密度的簇,计算其中心点,即为初始聚类中心。
类簇中心点的计算方法如下:假设有一个类簇ci包含m个数据点{x1,x2,…,xm},则其中心点ni按如式(5)计算:

经过上述步骤,可以优化初始聚类中心点的选取,使之后的聚类迭代运算更加有效,降低搜索范围,大大减少搜索指派的时间。
2 k-medoids聚类算法并行化设计策略
本文针对k-medoids算法具有初始点选取复杂、聚类迭代时间久、中心点选取消耗资源过多等缺点,使用Hadoop平台下的MapReduce编程框架对算法进行初始点的点密度计算选取并行化、非中心点分配并行化和中心点更新并行化等方面的改进。MapReduce分为Map(映射)和Reduce(化简)两部分操作,使用MapReduce实现算法并行化关键在于Map函数和Reduce函数的设计。其中Map函数将可并行执行的多个任务映射到多个计算节点,多个计算节点对各自被分派的任务并行进行处理,Reduce函数则是在各计算节点处理结束后,将计算结果返回给主进程进行汇总。
2.1 点密度计算并行化策略
在点密度的计算中,由于一个数据点的点密度对其他数据点的点密度没有影响,所以该计算过程是可以并行化的。使用MultithreadedMapper在一个JVM进程里以多线程的方式同时运行多个Mapper,每个线程实例化一个Mapper对象,各个线程并发执行。主进程把数据点分派给若干个不同的计算节点进行处理,计算节点将数据平均分成k份,且有k个线程,每个线程中的数据点都与数据集中所有点进行距离计算,进而计算出点密度,最后通过Reduce函数将计算结果汇总并输出。并行处理使得点密度计算所用时间大大减少,提高了算法的执行效率。
2.2 非中心点分配及中心点更新并行化策略
非中心点分配阶段的主要工作是计算各数据点到每个中心点的距离,由于每个数据点跟各个中心点距离的计算互不影响,所以该计算过程也是可并行化的。此阶段的MapReduce化过程中,Map函数主要负责将数据集里除中心点外的每一个样本点分配给与其距离最近的聚类中心,Reduce函数则负责通过计算更新每一个簇的中心点,按照这个原则迭代下去一直到达到设定阈值。主进程利用Map函数把非中心点分配的任务分派给若干个计算节点,每个计算节点采用基于Round-Robin的并行化分配策略。首先把每一个数据点看作一个请求,轮询地分配给不同的线程,对非中心点和每一个中心点的距离进行计算,找出最小的距离,然后把该非中心点指派给最小距离所对应的中心点。
因为轮询调度算法是假设所有服务器中的处理性能都是相同,并不关心每台服务器当前的计算速度和响应速度。因此当用户发出请求时,如果服务间隔的时间变化较大的时候,那么Round-Robin调度算法是非常容易导致服务器之间的负载发生不平衡表现。而本文中所运用的每个数据点都是平等的,所以不会造成服务器分配任务不均的问题。因此基于Round-Robin的策略是可行的。
本文算法在实现聚类的过程中经历了两次并行化划分,分别是非中心点分配和中心点更新过程。这两次并行化过程是周而复始的,直到满足程序退出的条件才会终止循环。
3 仿真实验与结果分析
仿真实验分别使用本文算法、DBSCAN并行化算法[1]和k-medoids并行化算法[8]进行对比试验,证明各个算法的优劣性。为了证明本文算法的有效性,实验将分析不同算法的聚类时间、聚类准确度以及增加线程数之后的时间消耗。实验将在两种类型的数据集上进行测试:
(1)电力数据集。电力通信数据的属性有设备状态、设备资产、网络拓扑等,其数据量约为1 GB。
(2)公有数据集。分别为200数量级的Northix、1 000数量级的DSA、5 000数量级的SSC和10 000数量级的GPSS。
3.1 电力数据集实验结果分析
实验首先设置6个线程对数据集进行处理,三种算法对电力数据进行聚类的结果见表1。其中k-medoids并行化算法[8]采用标签共现原则对初始点选取进行改进,但没有考虑线程的分配方式,因此其执行效率最差;DBSCAN算法考虑到了初始点的选取,并采用动态分配策略实现并行化,但在计算动态分配过程中增加了一定消耗,因此聚类准确度和执行效率都略有提升;本文所提出的算法,既考虑了初始点的合理选取,同时采用简单有效的并行化分配策略,以减少计算和过多资源占用,因此相对于k-medoids并行化算法和DBSCAN并行化算法执行效率大幅提升,准确度也有所提高。
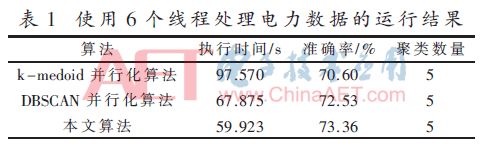
然后增加线程处理器的数量至8个,得到下表的聚类结果,见表2。
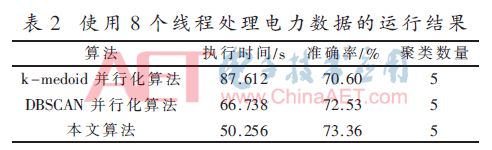
由表2可得,使用8个线程时,本文算法比k-medoids并行化算法执行时间快了42.64%,比DBSCAN并行化算法快了24.70%。
各类算法增加线程后所用时间相比原算法减少的百分比如图1。
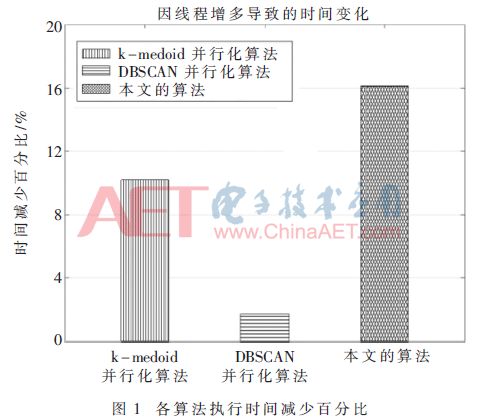
由图1可知,k-medoids并行化算法减少了10.20%,DBSCAN并行化算法减少了1.68%,本文算法减少了16.13%,说明本文算法在线程数增加时,可以更有效地减少运算时间,提高执行效率。
3.2 公有数据集实验结果分析
基于Northix、DSA、SSC和GPSS数据集使用5个线程实现算法的聚类准确度比较见表3。
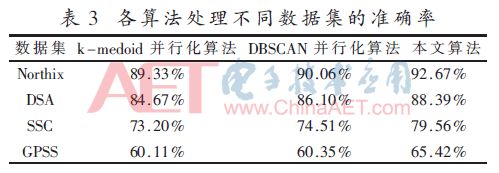
本文算法的聚类准确度均高于k-medoids并行化算法和DBSCAN并行化算法,并且在处理较大数量级的数据集时,本文算法准确度更占优势。不同数据集上各算法的执行时间如图2。
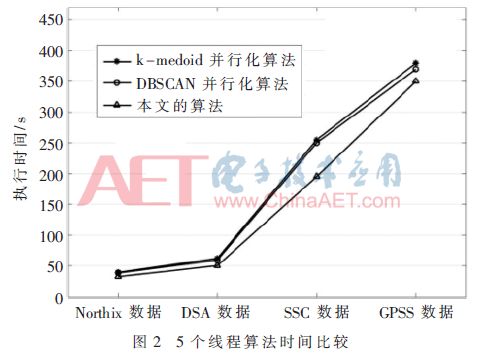
根据图2,随着数据量的增大,三种算法执行效率差异逐渐增大,本文算法性能明显优于k-medoids并行性算法和DBSCAN并行算法。接着对三个算法使用7个线程时的执行时间进行比较,如图3所示。
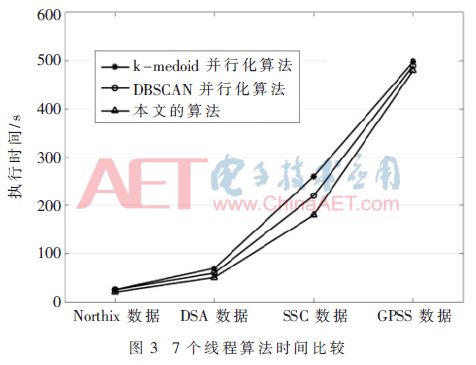
从图3中可以看出,使用7个线程在1 000、5 000、10 000数据级时,本文算法执行时间明显优于其他两个算法。
3.3 实验小结
仿真实验可知,在同一线程数时,本文算法比对比算法聚类准确率高,执行时间短;在线程数增加时,本文算法执行时间显著降低;随着数据量的增长,本文算法在保证更高准确度的基础上,执行时间优势逐渐凸显。
4 结论
本文针对电力通信数据的聚类处理问题,提出基于密度的聚类思想对k-medoids算法初始点的选取策略进行优化,并利用MapReduce编程框架实现了算法的并行化处理。通过仿真实验表明本文提出的优化算法可行有效,并具有较好的执行效率。在接下来的研究中可以考虑线程数小于聚类数时的优化分配策略,进一步提高算法性能。
-
一种改进的聚类算法及其在说话人识别上的应用2009-09-07 590
-
一种基于随机游动的聚类算法2009-11-21 547
-
一种改进的粒子群和K均值混合聚类算法2010-02-09 742
-
一种改进的BIRCH算法聚类方法2017-11-10 728
-
基于Hash改进的k-means算法并行化设计2017-11-24 769
-
K均值聚类算法的MATLAB实现2017-12-01 20599
-
基于人群疏散仿真的折半聚类算法2017-12-03 647
-
一种新的人工鱼群混合聚类算法2017-12-04 592
-
一种高效的基于MapReduce分布式蜂群模式挖掘算法2017-12-05 673
-
一种新的基于流行距离的谱聚类算法2017-12-07 827
-
基于Spark框架与聚类优化的高效KNN分类算法2017-12-08 1182
-
一种基于MapReduce的图结构聚类算法2017-12-19 829
-
距离不等式的K-medoids聚类算法2017-12-22 659
-
一种自适应的关联融合聚类算法2021-04-01 814
-
基于混合蛙跳算法的K-mediods聚类算法2021-05-08 713
全部0条评论

快来发表一下你的评论吧 !
