

在FPGA上实现基于802.16d的定时同步算法改进方案
描述
引言
WiMAX ( Wordwide Interoperability for Mi-crowave Access)是代表空中接口满足IEEE 802.16标准的宽带无线通信系统。其中IEEE标准在2004年定义了空中接口的物理层(PHY),即802.16d协议。该协议规定数据传输采用突发模式,调制采用OFDM技术。在接收端,为了正确解调,必须找到符号的起始位置,因此,必须进行定时估计。如果定时不正确,就可能引起严重的码间干扰。由于频偏估计是在定时估计之后进行,如果定时估计不准确,也会影响频偏的估计性能,从而导致整个OFDM系统性能下降。因此,必须在短时间内对接收数据进行快速准确的定时同步。
目前常用的定时算法多采用计算序列的相关性。由于计算复杂,其硬件资源消耗非常庞大,所以,目前OFDM系统中的同步算法以软件方法为主,已有的硬件方法由于消耗资源太大而无法将同步模块和接收部分的其他模块集成在一片芯片中。本文参考IEEE 802.16d物理层帧结构,提出了一种低复杂度的帧同步和定时同步联合算法,该算法可在FPGA上利用较少资源来实现。
1 OFDM中的符号定时同步算法
对于定时同步算法的研究,总体上可以分为两类:第一类是依靠OFDM固有的结构,如利用OFDM符号周期性前缀CP的方法,这通常被称作循环前缀同步方法;第二类是利用OFDM中插入导频或者训练符号的方法。在两类同步方法中,第一类方法中最具代表性的是Beek提出的最大似然估计法,其优点是不需要额外的开销,可以提高通信的效率,但其缺点是估计的时间较长,而且对频偏和噪声比较敏感;第二类方法中最具代表性的是Schmidl和Cox提出的利用PN序列相关性的SCA算法,这一种算法受频偏的影响较小,而且估计的时间相对比较短,非常适合用于突发通信系统。
2 适合802.16d的定时同步算法
IEEE 802.16d定义了一组特殊的训练符号,以用于同步和信道估计。这组特殊的训练符号包括短训练序列和长训练序列两部分,其中短训练序列包括4个重复的64点数据加上循环前缀(CP);长训练序列包括两个重复的128点数据加上循环前缀。在发射端,若干OFDM符号再加上短训练序列和长训练序列,所构成的帧头经过发送滤波器和A/D转换,再通过上变频后,即可发送到信道中。而在接收端,则利用帧头的训练序列来进行同步。为了使定时同步不受频偏的影响,同时可以在较短时间内完成,本文采用SCA算法。该算法又可细分为延时自相关算法和本地序列互相关算法两类。
2.1 延时自相关法
通常选用短训练序列来进行定时同步。假设接收到的基带数字序列为rn,n是该序列的序号,然后将接收序列经过两个滑动窗口R和P,其中R是接收信号和接收信号延时的互相关系数,P是互相关系数窗口期间接收信号的能量,此窗口的值可用于判决的归一化,它和接收功率的绝对值是独立的,其公式如下:

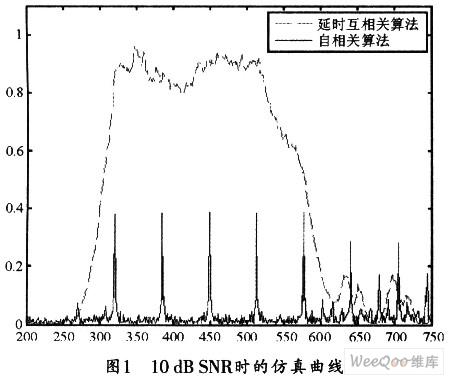
式中,N为窗口长度,N=64,即短训练序列的周期,d在窗内滑动时,可同时计算M(n)的值。当没有包含前导字结构的信号出现时,得到的M(n)值通常非常小(远小于1),而当有前导字结构的信号出现时,相应的M(n)值迅速升高,并将出现一个台阶,对应的峰值接近于1。由于M(n)值升高需要一个时间范围,因此该算法并不能精确定时,只适合粗略的检测帧是否到达。图1所示的虚线即表示信号出现时M(n)曲线的变化情况。
2.2 互相关法
由于IEEE 802.16d协议中的前导字具有良好的互相关特性,故可用已知的训练序列和接收序列做滑动互相关。当已知的训练序列和接收的训练序列恰好对齐时,便会产生一个峰值,峰值对准的位置正是训练符号的起始点。因此,可以通过寻找互相关的峰值位置来做精确的定时同步。算法公式如下:
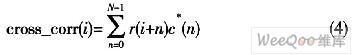
式中,c(n)为短训练符号在本地的复制样本,N为短训练符号的样值点数。当已知的训练序列和接收训练序列恰好对齐时,也会产生一个峰值,其仿真曲线如图1中的实曲线所示。该算法的缺点是易受频偏的影响。
根据以上分析,并从算法性能上考虑,若采用延迟自相关法,帧到达时会出现一个峰值平台,该方法并不能确定帧到达的准确时刻;而采用与本地序列互相关算法又容易受到频偏的影响而导致定时偏差。
3 算法改进
针对上述算法的不足,可对其加以改进,以保证同时具有良好的性能和硬件实现的可行性。改进算法是将两种算法结合起来进行联合估计,首先确定一个帧到达的大致平台,再在这个平台内找到互相关峰值,如果各个峰值间隔相等,那么可根据最后一个峰值来判断下一个符号的开始。这种联合估计的办法在软件仿真时具有良好的性能,但若要在硬件上实现则比较困难。因为在延时自相关算法中,计算M(n)的值虽然可采用迭代算法,每次计算只需1次复数运算和若干加法运算;但在自相关计算中,假设接收信号被定点化为16位整数,那么计算一次自相关的值需要16位数据的64次复数乘法,显然,所需要的硬件资源开销非常大,而且会影响系统的运行速度。这在硬件上,因资源消耗太大而无法实现。为了兼顾算法的估计精度和实现的复杂性,有必要将算法做进一步改进。即对接收数据进行二阶量化以得到d[n]=Q[r(n)],其中Q表示复数量化器,见下式:
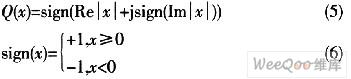
利用这种改进的自相关算法和延时自相关算法进行联合估计的仿真曲线如图2所示。
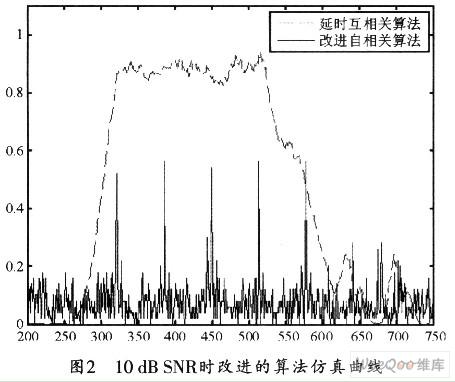
将图1和图2进行对比可知,这种对接收数据二阶量化的方法会损耗算法的性能,但是,由于帧的大致位置已被限制在一定范围之内,因此,只需根据峰值就可以确定下一个OFDM符号的准确位置。这种方法既能保证估计精度,又能满足硬件资源利用率的要求。
4 基于FPGA的实现
4.1 自相关延时模块的FPGA实现
为了进一步简化运算,也可以不进行算法中的归一化运算,而直接计算R(n)的值,并将公式简化为:
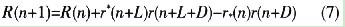
图3所示是自相关延时模块的硬件组成结构。它主要由FIFO延时单元、复数运算器、加法器、取模模块组成。其中复数乘法器可直接使用IP核来实现,这比直接使用四个实数乘法器和两个加法器更节省资源。
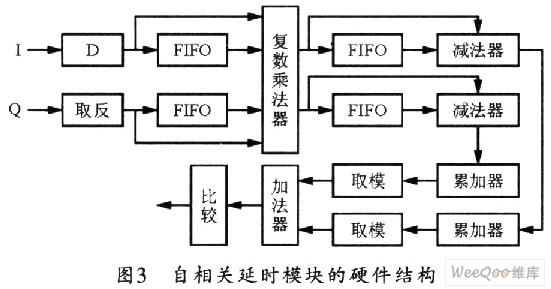
将接收端经过下变频的I路和Q路数据分为两路送入模块,I路比Q路数据应多延时一个时钟周期,这是为了和Q路数据保持相同的时延,此后再进入FIFO经过64个时钟周期的延时。Q路数据首先进行取相反数运算。这是因为复数共轭运算相当于先取相反数再做复数乘法。把相减的结果送入FIFO进行延时,并将送入系统的复数与做减法和延时64个时钟周期的复数进行复数乘法运算。由于两路数据都是16位定点化整数,经过运算后会成为33位,为了节省资源,可将所得结果的高5位和低12位截去,而这并不会影响运算的精度。经过复数乘法运算的实部和虚部再分别经过64个时钟周期的FIFO延时,并将延时前后的数据做减法运算,然后对计算的结果做累加运算。累加器输出的结果经过取模模块后,即可得到实部和虚部的绝对值,然后将两部分结果相加,再将相加结果与门限值比较,超过门限则将标志位置高。但应注意门限值的选取会影响帧检测的范围,由于采用的是联合检测方法,应适当扩大门限范围,本设计设定的门限值为峰值的1/4。
4.2 互相关模块的FPGA实现
互相关模块主要由匹配运算单元、取模器和加法器组成。改进的算法只对输入数据的符号位与本地序列的符号位进行相关运算,并规定输入符号为正取值为1,输入符号为负取值为-1,接着根据输入数据的符号和本地序列的符号构成的16种输入做全排列,将所有可能的相关运算值算好存放在运算模块中,这样就可以根据输入数据的符号来选择相关运算的结果。这等效于把复数相关运算简化为数据选择器来实现。
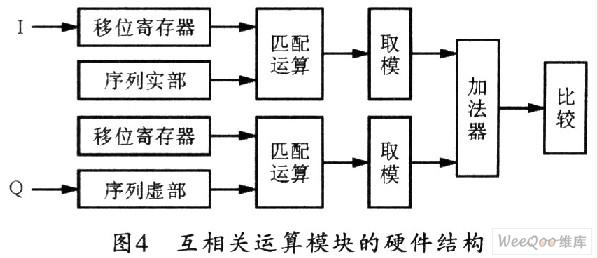
图4所示为互相关模块的FPGA实现框图,其中I、Q两路数据进入模块后,可取出其最高位存入移位寄存器,然后与本地序列做匹配运算。匹配运算模块由64个数据选择器和126个加法器组成,加法运算采用6级流水线来实现,这样,可使系统的运算速率更高。
4.3 仿真结果分析
系统中的各模块可采用Verilog HDL语言设计,并可使用Xilinx公司集成设计环境ISE中的ModelSim SE 6.0来完成仿真,仿真结果如图5所示。其中frame_re_dout和frame_im_dout为送入系统的实部和虚部数据,abs_out为延时自相关算法中取模相加的结果,frame_head为采用延时自相关算法使数据升高时得到的一个峰值平台,top_flag为改进自相关算法计算所得的峰值。图中的自相关平台内有5个峰值,这与MATLAB仿真结果相符。最后采用Xilinx公司VirtexⅡpro系列xc2vp30器件进行实现。总共逻辑单元使用率为8%,系统最高工作频率为236.373 MHz 。

5 结束语
本文在研究基于802.16d的OFDM定时同步算法的基础上提出了一种改进的算法,并在FPGA上完成了其硬件威廉希尔官方网站 设计。仿真结果表明该算法在保持了原算法优秀性能的同时,可节省硬件资源,有利于把同步模块和接收部分其他模块集成在单芯片中。同时,该算法也可推广到具有相似前导字结构的802.1 1a等协议中。
-
求助-在FPGA上实现retinex算法2013-05-08 0
-
802.16e技术浅析2019-04-10 0
-
如何定时同步算法改进及实现FPGA?2019-08-09 0
-
求一种基于802.16d的低复杂度的帧同步和定时同步联合算法2021-05-06 0
-
IEEE802.16接收机检测模块的FPGA 实现2009-06-17 421
-
802.16d协议OFDM接入同步误差影响研究2010-02-21 459
-
基于802.16d的定时同步算法改进及FPGA实现2010-02-22 936
-
WCDMA主同步的FPGA实现2011-05-14 962
-
OFDM系统定时同步算法的改进2011-08-05 725
-
多径信道下OFDM系统定时同步算法2012-02-16 891
-
高阶QAM定时同步算法的MATLAB仿真及FPGA实现2012-11-23 6817
-
在FPGA上实现CRC算法的程序2016-06-07 940
-
实时图像增强算法改进及FPGA实现2016-09-17 576
-
适用于802.16d标准的智能化5.8GHZ双向功率放大器2018-02-27 586
-
适用于5G系统的PSS定时同步改进算法2021-03-15 1035
全部0条评论

快来发表一下你的评论吧 !
