

ucos-II移植到51单片机的解决办法
电子说
描述
本文主要是关于ucos-II的相关介绍,并着重对ucos-II移植到51单片机进行了详尽的阐述。
ucos-II
μC/OS-II由Micrium公司提供,是一个可移植、可固化的、可裁剪的、占先式多任务实时内核,它适用于多种微处理器,微控制器和数字处理芯片(已经移植到超过100种以上的微处理器应用中)。同时,该系统源代码开放、整洁、一致,注释详尽,适合系统开发。 μC/OS-II已经通过联邦航空局(FAA)商用航行器认证,符合航空无线电技术委员会(RTCA)DO-178B标准。
μC/OS-II被广泛应用于微处理器、微控制器和数字信号处理器。
μC/OS-II 的前身是μC/OS,最早出自于1992 年美国嵌入式系统专家Jean J.Labrosse 在《嵌入式系统编程》杂志的5 月和6 月刊上刊登的文章连载,并把μC/OS 的源码发布在该杂志的B B S 上。
μC/OS 和μC/OS-II 是专门为计算机的嵌入式应用设计的, 绝大部分代码是用C语言编写的。CPU 硬件相关部分是用汇编语言编写的、总量约200行的汇编语言部分被压缩到最低限度,为的是便于移植到任何一种其它的CPU 上。用户只要有标准的ANSI 的C交叉编译器,有汇编器、连接器等软件工具,就可以将μC/OS-II嵌入到开发的产品中。μC/OS-II 具有执行效率高、占用空间小、实时性能优良和可扩展性强等特点, 最小内核可编译至 2KB 。μC/OS-II 已经移植到了几乎所有知名的CPU 上。
严格地说uC/OS-II只是一个实时操作系统内核,它仅仅包含了任务调度,任务管理,时间管理,内存管理和任务间的通信和同步等基本功能。没有提供输入输出管理,文件系统,网络等额外的服务。但由于uC/OS-II良好的可扩展性和源码开放,这些非必须的功能完全可以由用户自己根据需要分别实现。
uC/OS-II目标是实现一个基于优先级调度的抢占式的实时内核,并在这个内核之上提供最基本的系统服务,如信号量,邮箱,消息队列,内存管理,中断管理等。
uC/OS-II以源代码的形式发布,是开源软件, 但并不意味着它是免费软件。你可以将其用于教学和私下研究(peaceful research);但是如果你将其用于商业用途,那么你必须通过Micrium获得商用许可。
uCOSII移植的一点心得
uCOS-II是一种十分优秀实时操作系统,其在NASA的认证通过直接说明了其优秀及稳健的性能,同时由于其完全open,所以受到广大开源爱好者的喜爱。uCOS-II简单明了,同时绝大部分代码都采用ANSI C编写(除了与CPU相关代码外),所以学习起来十分容易,是嵌入式学习乃至操作系统学习最好的入门OS之一。
我主要想讲一下自己最近移植uCOS-II的心得,因为最近也在学习操作系统,所以这段日子对于uCOS-II的学习的确也让我对于操作系统有了一个实际深刻的认识。
uCOS-II移植其实十分简单。对于一个处理器,需要做的工作只有:修改三个文件――os_cpu_c.c、os_cpu.h、os_cpu_a.asm(ASM文件根据编译器不同而又有一些不同)。
用另一种方式说,需要做的工作就是修改五个函数:
1、os_cpu_c.c:OSTaskStkInit;
2、os_cpu_a.asm:OSStartHighRdy、OSCtxSw、OSIntCtxSw、OSTickISR;
OSTaskStkInit函数是针对CPU压栈的函数,需要模仿出CPU初始化后的寄存器状况。也使需要修改的唯一一个C语言函数。其他的都是汇编函数。
如果我们可以从uCOS-II官方网站上找到相同CPU或是相似的同一家族的CPU移植代码,那么我们的移植工作将会简单得多。因为至少我们可以只用了解这个处理器的内部结构,而不用细致的了解其汇编指令等很多繁琐而没有意义的事情(有的处理器你可能一辈子不再用它,了解得太细致只是在浪费时间)。
譬如,此次我要做的是将uCOS-II移植到瑞萨M16C/62A上,而官方网站上只有其62P的移植代码,于是乎我就将二者的datasheet在CPU的寄存器、中断部分仔细比对,发现二者区别很小。最大的区别恐怕就在CPU内部寄存器中的INTBL和PC寄存器二者顺序相反吧,这只要在相关部分注意就可以了,所以很容易就搞定了CPU相关代码部分。
总结一下移植中浪费我时间的几个小错误吧,这完全是个人粗心导致的失误:
1、在os_cpu.h文件中需要用宏定义将OS_TASK_SW指向OSCtxSw函数,而我开始像以前一样直接将OSCtxSw函数与0号软终端链接起来,结果发现函数调用不成功。后来直接用宏定义将OS_TASK_SW define为OSCtxSw函数,初步调试通过,即验证OSCtxSw函数正确,但是到后来调用任务的时候却发现任务切换不正常,不得不重新将函数与中断结合起来,当然就不能还是0号中断了,而是改为一个比较保险的软终端,这个问题纠结了很长时间。
2、在看书的时候不仔细直接导致我犯了一个大错误。起初以为task只要是能够达到功能的死循环即可。所以每个task函数都是while(1)或者for(;;;),但是我没有注意到一点就是每个task里面都应该有OSTimeDly()函数,否则将导致任务之间不能跳转。所以最初的实验现象是永远只有一个任务在运行,但是任务不能切换……
3、未注意到版本之间的区别。我们知道在新版本的uCOS-II中,添加了一个文件os_tmr.c,主要是在timer上面做了很大的调整,但是我没有注意到这一点,仍旧按照老版本的方法调试,导致函数调用让我完全不知所措。最后注意到os的源代码的不同,仔细阅读源代码之后知道了其用法,其实如果不需要timer太强大的功能,只要在os_cfg.h文件中将OS_TMR_EN设置为0即可。这在习惯老版本调试方法的同学而言是很好的方法。
ucos-II移植到51单片机的解决办法
先来了解和51移植相关的三个概念:
第一,移植UCOS必须要了解编译器,我们一般使用的51编译器都是KEIL。值得一提的是KEIL对可重入函数的处理。由于51单片机的堆栈指针是8位的,所以硬件堆栈只能设置在内部RAM的DATA区和IDATA区(DATA、IDATA、PDATA、XDATA、CODE这些概念相关资料很多,我不想在此处滋述),所以51的堆栈是很紧张的。于是,KEIL将函数内的动态变量和函数传递的参数(当然有一部分参数是用寄存器直接传送的),放在分配的固定数据段中,函数执行时在固定的数据段中去取得相关的数据,而不是像传统的CPU都用堆栈来处理,这就导致了函数不可重入,因为当一个函数没执行完成时再次执行会把数据段里的内容覆盖掉。为了使函数可重入KEIL引入了仿真堆栈的概念(重入函数需在函数定义后面加上reentrant关键字),用仿真堆栈来传递参数及分配动态变量,就好像传统堆栈的入栈、出栈操作一般,如此函数第二次进入执行时,就不会覆盖掉上一次的变量和参数,仿真堆栈实现原理详见http://hi.baidu.com/lyb1900/blog/item/99b6313defc2b40abaa167fe.html 。但是,KEIL的这一机制会给我们移植造成了麻烦,任务切换时不仅要保存好硬件堆栈内容,还要保存好仿真堆栈的内容。(建议先理解仿真堆栈的概念)
第二,其他类型的CPU可以在任务切换时先将SP指针保存到被中断任务的OSTCBCur-》OSTCBStkPtr中,再将高优先级任务的OSTCBCur-》OSTCBStkPtr恢复到SP中就可以了,各个任务使用各自的堆栈空间,互不干扰,切换也很方便。而51的堆栈指针是8位的,SP只能指向内部RAM空间,但是内部RAM很小,根本不可能将所有任务堆栈都设置在内部RAM中(DATA和IDATA区)。所以,51只能设置一个固定的硬件堆栈,每个任务可以在外部RAM中设置各自的任务堆栈,任务切换时,将本任务所使用到的硬件堆栈的长度和内容保存到任务堆栈中,然后将高优先级任务的用户堆栈里的内容恢复到硬件堆栈中。所以51切换任务会比较慢。
第三,在KEIL的工程配置Target选项中会有一个Memory Model选项。用鼠标点击Memory Model的下拉箭头,会有3个选项。
Small:变量存储在内部ram里。
Compact:变量存储在外部ram里,使用页8位间接寻址
Large:变量存储在外部Ram里,使用16位间接寻址。
这三个变量决定了定义的变量在不加存储类型关键字时,变量存放的位置。这一点很多网站、资料都说的很明白。但是其实还有一点很多资料都是没说的。它还默认决定了上述仿真堆栈的位置。这一点在51的启动代码STARTUP.asm中能体现出来。其中有一段如下:
; Stack Space for reentrant functions in the SMALL model.
IBPSTACK EQU 1 ; set to 1 if small reentrant is used.
IBPSTACKTOP EQU 0FFH+1 ; set top of stack to highest location+1.
;
; Stack Space for reentrant functions in the LARGE model.
XBPSTACK EQU 0 ; set to 1 if large reentrant is used.
XBPSTACKTOP EQU 7FFFH+1; set top of stack to highest location+1.
;
; Stack Space for reentrant functions in the COMPACT model.
PBPSTACK EQU 0 ; set to 1 if compact reentrant is used.
PBPSTACKTOP EQU 7FFFH+1; set top of stack to highest location+1.
IF IBPSTACK 《》 0
EXTRN DATA (?C_IBP)
MOV ?C_IBP,#LOW IBPSTACKTOP
ENDIF
IF XBPSTACK 《》 0
EXTRN DATA (?C_XBP)
MOV ?C_XBP,#HIGH XBPSTACKTOP
MOV ?C_XBP+1,#LOW XBPSTACKTOP
ENDIF
IF PBPSTACK 《》 0
EXTRN DATA (?C_PBP)
MOV ?C_PBP,#LOW PBPSTACKTOP
ENDIF
注释讲的很清楚,根据所选模式,编译器会将IBPSTACK、PBPSTACK或者XBPSTACK设置为1,就决定了仿真堆栈在IDATA区、PDAIA区还是XDATA区。对应的,KEIL会自动分配一个仿真堆栈指针,分别是?C_IBP、?C_PBP和(?C_XBP、?C_XBP+1),由于寻址XDATA区需要16位地址,所以需要两个字节。这三个指针是KEIL根据选择的Memory Model选项自动分配的。
注意:不要试图在选择好模式后将仿真堆栈设置在另一模式的空间中。比如,我用的小模式编译,仿真堆栈在IDATA区,用的仿真堆栈指针是?C_IBP,但是我现在在启动代码中将IBPSTACK定义为0,将XBPSTACK设置为1,看起来我们先把仿真堆栈设置在XDATA区了,但实际上其它代码段中使用的仿真堆栈指针任然是?C_IBP。有趣的是,KEIL还为我们的启动代码做了一个很友好的列表框选择界面。但实际上选择好编译模式后,仿真堆栈使用空间是不能更改的,不知道KEIL为什么这么做?但是我们有时候要根据单片机的型号选择仿真堆栈的起始地址。
讲了那么多,应该来看看关于堆栈的组织了,首先是不知道哪位前辈移植的,用的小模式编译的堆栈结构:

每个任务分都需要配一个任务堆栈,OSTCBCur-》OSTCBStkPtr指向任务堆栈的栈底,任务堆栈的首字节是仿真堆栈指针?C_IBP(由于是小模式编译,所以使用的仿真堆栈设置在IDAIA区)。用户堆栈中紧接着存放的是该任务的仿真堆栈中的内容。再接着是系统堆栈(就是SP指针所指的堆栈)的长度,最后是系统堆栈的内容。
任务在切换时,首先将当前的?C_IBP的值保存到本任务堆栈的首地址中,然后将仿真堆栈的全部内容复制到任务堆栈中(仿真堆栈栈底固定在IDATA区的最高字节0xff,可以根据(0xff-?C_IBP+1)的值来确定所使用的仿真堆栈的长度),接着保存系统堆栈的长度(系统堆栈设置在DATA或IDATA区中,系统堆栈的栈底的地址我们可以在启动代码中设置,长度可以用(SP-Stack+1)来计算得到)最后将所用的系统堆栈中的内容复制到任务堆栈中。
然后得到高优先级的任务堆栈,首先恢复高优先级任务的?C_IBP,然后计算出高优先级任务所用仿真堆栈的长度,将保存的仿真堆栈的内容一一恢复到仿真堆栈中,然后得到系统栈的长度,再将保存的系统堆栈的内容恢复到系统堆栈中,最后恢复SP指针并执行RETI返回指令,便实现了任务切换。
任务被打断时将仿真堆栈和系统堆栈的内容全都备份到任务堆栈中,在恢复运行时将相应的内容还原到系统堆栈和仿真堆栈中。
这种方法的缺点是,任务切换将会变的很慢,因为要分别拷贝和恢复仿真堆栈和系统堆栈的全部内容。完全可以将仿真堆栈设置在XDATA区中,任务切换时,只需保存和恢复?C_XBP指针就行了,而不必每次都拷贝和恢复仿真堆栈的全部内容。由于SP指针只有8位,系统堆栈只能设置在内部RAM中。
再来看看杨屹大侠大模式编译下的堆栈结构:
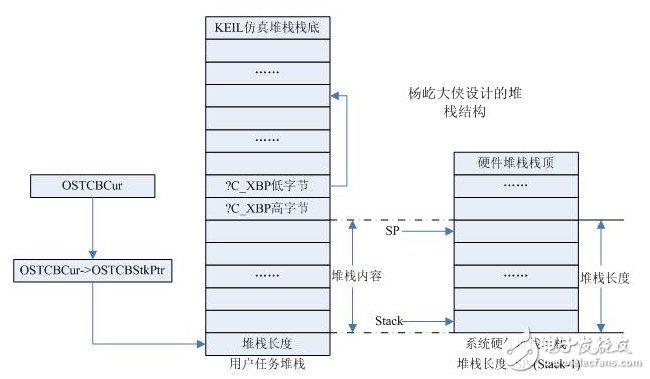
同样,每个任务分配一个任务堆栈,OSTCBCur-》OSTCBStkPtr指向任务堆栈的栈底,任务堆栈的首字节是系统堆栈的长度,接着是系统堆栈的全部内容。再接着是仿真堆栈指针?C_XBP的高低字节(因为是大模式编译,所以仿真堆栈在XDATA区),任务堆栈再高的字节是作为仿真堆栈用的,用户堆栈的栈顶就是仿真堆栈的栈底。
任务切换时,首先计算任务使用的系统堆栈的长度,将长度保存在任务堆栈栈底,然后将使用的系统堆栈的内容全部复制到任务堆栈中,最后保存当前的?C_XBP仿真堆栈指针的高低字节。
接着恢复高优先级任务的信息,先得到堆栈长度,将备份的堆栈内容恢复到系统堆栈中,并恢复SP指针(根据长度和系统堆栈的栈底可以计算出SP指针的值)。最后恢复?C_XBP的高低字节。便实现了任务的切换。
任务切换时将系统堆栈的内容和仿真堆栈指针保存起来,再将高优先级任务的仿真堆栈指针和系统堆栈的内容恢复。
和上述的小模式下的切换过程相比,仿真堆栈的内容在任务切换时不需要保存和恢复了,任务切换速度会提高不少。但是读过杨屹大侠代码的朋友肯定知道,每个任务堆栈的大小都要设置成相同。这对于有些堆栈使用很少的任务来说是很浪费的,而且51的RAM本来就那么紧张?仿真堆栈被设置在任务堆栈的最高地址处,细心的朋友会发现,堆栈检测函数肯定是无法运行了。
正是意识到这些缺陷,我对杨屹大侠移植的代码进行了一些改动,堆栈结构也有较大改变,使用的也是大模式编译:
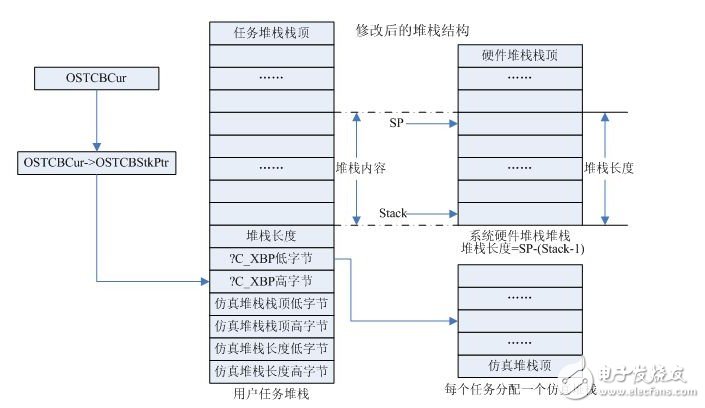
先来了解和51移植相关的三个概念:
第一,移植UCOS必须要了解编译器,我们一般使用的51编译器都是KEIL。值得一提的是KEIL对可重入函数的处理。由于51单片机的堆栈指针是8位的,所以硬件堆栈只能设置在内部RAM的DATA区和IDATA区(DATA、IDATA、PDATA、XDATA、CODE这些概念相关资料很多,我不想在此处滋述),所以51的堆栈是很紧张的。于是,KEIL将函数内的动态变量和函数传递的参数(当然有一部分参数是用寄存器直接传送的),放在分配的固定数据段中,函数执行时在固定的数据段中去取得相关的数据,而不是像传统的CPU都用堆栈来处理,这就导致了函数不可重入,因为当一个函数没执行完成时再次执行会把数据段里的内容覆盖掉。为了使函数可重入KEIL引入了仿真堆栈的概念(重入函数需在函数定义后面加上reentrant关键字),用仿真堆栈来传递参数及分配动态变量,就好像传统堆栈的入栈、出栈操作一般,如此函数第二次进入执行时,就不会覆盖掉上一次的变量和参数,仿真堆栈实现原理详见http://hi.baidu.com/lyb1900/blog/item/99b6313defc2b40abaa167fe.html 。但是,KEIL的这一机制会给我们移植造成了麻烦,任务切换时不仅要保存好硬件堆栈内容,还要保存好仿真堆栈的内容。(建议先理解仿真堆栈的概念)
第二,其他类型的CPU可以在任务切换时先将SP指针保存到被中断任务的OSTCBCur-》OSTCBStkPtr中,再将高优先级任务的OSTCBCur-》OSTCBStkPtr恢复到SP中就可以了,各个任务使用各自的堆栈空间,互不干扰,切换也很方便。而51的堆栈指针是8位的,SP只能指向内部RAM空间,但是内部RAM很小,根本不可能将所有任务堆栈都设置在内部RAM中(DATA和IDATA区)。所以,51只能设置一个固定的硬件堆栈,每个任务可以在外部RAM中设置各自的任务堆栈,任务切换时,将本任务所使用到的硬件堆栈的长度和内容保存到任务堆栈中,然后将高优先级任务的用户堆栈里的内容恢复到硬件堆栈中。所以51切换任务会比较慢。
第三,在KEIL的工程配置Target选项中会有一个Memory Model选项。用鼠标点击Memory Model的下拉箭头,会有3个选项。
Small:变量存储在内部ram里。
Compact:变量存储在外部ram里,使用页8位间接寻址
Large:变量存储在外部Ram里,使用16位间接寻址。
这三个变量决定了定义的变量在不加存储类型关键字时,变量存放的位置。这一点很多网站、资料都说的很明白。但是其实还有一点很多资料都是没说的。它还默认决定了上述仿真堆栈的位置。这一点在51的启动代码STARTUP.asm中能体现出来。其中有一段如下:
; Stack Space for reentrant functions in the SMALL model.
IBPSTACK EQU 1 ; set to 1 if small reentrant is used.
IBPSTACKTOP EQU 0FFH+1 ; set top of stack to highest location+1.
;
; Stack Space for reentrant functions in the LARGE model.
XBPSTACK EQU 0 ; set to 1 if large reentrant is used.
XBPSTACKTOP EQU 7FFFH+1; set top of stack to highest location+1.
;
; Stack Space for reentrant functions in the COMPACT model.
PBPSTACK EQU 0 ; set to 1 if compact reentrant is used.
PBPSTACKTOP EQU 7FFFH+1; set top of stack to highest location+1.
IF IBPSTACK 《》 0
EXTRN DATA (?C_IBP)
MOV ?C_IBP,#LOW IBPSTACKTOP
ENDIF
IF XBPSTACK 《》 0
EXTRN DATA (?C_XBP)
MOV ?C_XBP,#HIGH XBPSTACKTOP
MOV ?C_XBP+1,#LOW XBPSTACKTOP
ENDIF
IF PBPSTACK 《》 0
EXTRN DATA (?C_PBP)
MOV ?C_PBP,#LOW PBPSTACKTOP
ENDIF
注释讲的很清楚,根据所选模式,编译器会将IBPSTACK、PBPSTACK或者XBPSTACK设置为1,就决定了仿真堆栈在IDATA区、PDAIA区还是XDATA区。对应的,KEIL会自动分配一个仿真堆栈指针,分别是?C_IBP、?C_PBP和(?C_XBP、?C_XBP+1),由于寻址XDATA区需要16位地址,所以需要两个字节。这三个指针是KEIL根据选择的Memory Model选项自动分配的。
注意:不要试图在选择好模式后将仿真堆栈设置在另一模式的空间中。比如,我用的小模式编译,仿真堆栈在IDATA区,用的仿真堆栈指针是?C_IBP,但是我现在在启动代码中将IBPSTACK定义为0,将XBPSTACK设置为1,看起来我们先把仿真堆栈设置在XDATA区了,但实际上其它代码段中使用的仿真堆栈指针任然是?C_IBP。有趣的是,KEIL还为我们的启动代码做了一个很友好的列表框选择界面。但实际上选择好编译模式后,仿真堆栈使用空间是不能更改的,不知道KEIL为什么这么做?但是我们有时候要根据单片机的型号选择仿真堆栈的起始地址。
结语
关于ucos-II的相关介绍就到这了,如有不足之处欢迎指正。
-
快速实现STM32移植ucos-ii2013-08-08 0
-
ucos_II在51单片机上的移植源代码2014-04-26 0
-
在51系列单片机上移植uCOS-II2009-06-16 4656
-
ucOS-II入门经典教程2015-11-06 1591
-
盘古STM32F103开发板移植uCOS-II详细说明2016-03-02 933
-
STM32平台移植uCOS-II详细说明-2012.11.132016-03-04 942
-
uCOS-ii中文书2016-08-24 903
-
uCOS-II原理12016-12-20 743
-
uCOS-II原理22016-12-20 696
-
uCOS-II原理32016-12-20 770
-
在W78E58处理器上移植的uCOS-II2017-01-08 1016
-
uCOS-II在MSP430移植2017-10-12 774
-
手把手盘古STM32开发板移植uCOS-II教程2017-10-16 990
-
如何在系列51单片机上移植uCOS-II2019-08-02 950
-
基于51单片机的uCOS_ii仿真源码下载2021-04-09 1127
全部0条评论

快来发表一下你的评论吧 !
