

最新加速深度强化学习:谷歌创造
电子说
描述
深度强化学习技术可以通过视觉输入来为复杂任务学习有效策略,这种方法在最近的研究中已经被成功应用经典的雅达利2600系列游戏。最新的研究表明,即使在像Montezuma’s Revenge这样复杂的游戏中基于深度强化学习依然可以达到超越人类的表现。然而深度强化学习最大的限制在于要达到高水平的效果,需要与环境进行非常多次的交互,远远超过了人类学习游戏时与环境交互的次数。这也许是由于人类在游戏时可以有效预测其行为可以长生的结果,有效提升了学习的效率。可以通过行为序列和对应的结果来进行游戏建模。通过为游戏建模并学习选择行为的策略,是基于模型强化学习(model-based reinforcement learning (MBRL))的主要假设。在先前研究的基础上,谷歌研究人员在新论文中提出了模拟策略学习算法(Simulated Policy Learning (SimPLe) algorithm),这是一套大幅度提高雅达利游戏主体训练效率的MBRL框架,在仅仅100k次的交互训练后就可以达到较好的效果。100k次交互大概等效于人类两个小时的游戏时间。这一算法通过观测、建模、模拟学习的方式很好的处理了深度强化学习过程中的效率问题。
学习SimPle环境模型
从宏观上来看,SimPle主要分为两个交替进行的学习过程,一个是学习游戏行为并建立环境模型的过程,另一个是在模拟游戏环境中利用这一模型优化策略的过程。学习的流程如下图所示循环进行。
SimPle的主要流程,主体与环境交互并收集数据更新环境模型,随后基于环境模型更新策略。
为了训练一个有效的雅达利游戏模型,后向需要在像素空间生成对未来的预测,换句话说我们需要根据先前的观察和动作行为预测游戏的下一帧。选择像素空间来预测的主要原因在于图像观测中包含了丰富且稠密的监督信号。一旦完成未来帧预测模型的训练,算法就可以利用这一信息为游戏主体生成轨迹来训练好的策略,例如可以基于最大化长期回报来选择行为。这意味着我们可以替代耗时和 消耗资源的真实游戏序列来训练策略,直接使用基于环境模型生成的图像序列来进行策略训练。
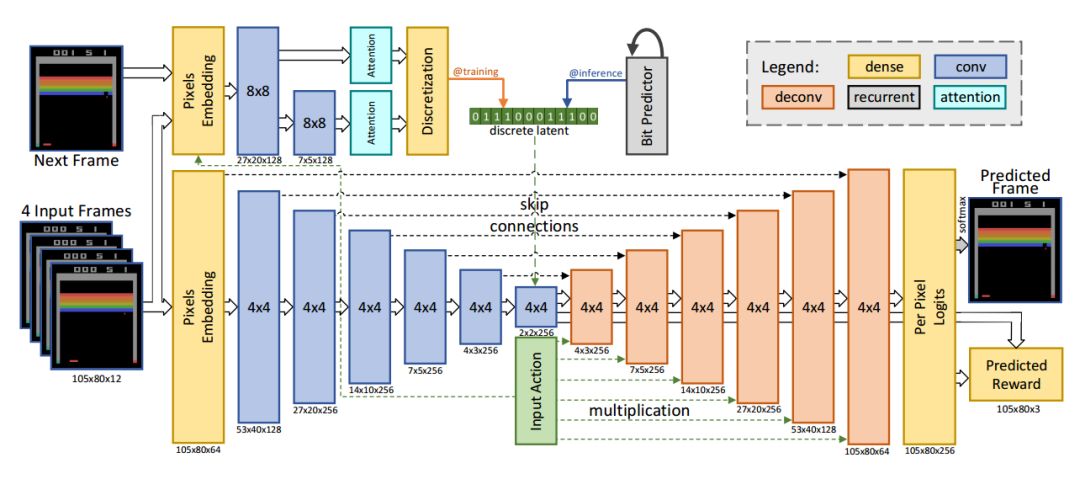
帧预测模型的架构图
基于前馈卷积网络研究人员利用4帧输入预测出下一帧的输出以及对应的反馈。输入的像素和动作通过全连接层编码,输出则由逐像素的256色softmax构成。模型有两个主要的部分,下半部分是基于编码器的卷积,解码器的每一层与输入动作都进行了连接。另一部分是推理网络,在训练的时候从近似后验中约化采样的隐空间编码被离散成比特,为了保持模型可差分bp绕过了离散部分。在推理时利用网络自回归预测隐空间比特。

kufu在功夫大师游戏中,系统错误预测了对手的数量。其中左侧是预测输出、中间是基准右边是逐像素的差别。
这一模型虽然表现良好,但在某些特殊情况下依然会输出错误的结果。例如在Pong游戏中,但球落到帧以外的时候系统就不能有效预测后续帧的结果。在先前工作的启发下,研究人员利用新的视频模型架构来解决这类随机问题。在模型训练后的每一个迭代中,研究人员利用Monique生成一系列包含动作、观测和结果的序列,并利用PPO来改进策略。其关键在于每一个生成序列都是从真实数据集开始的。考虑到长程序列的时间复杂度和误差,SimPLe仅仅使用中程序列来进行改进。但PPO算法可以从内部价值函数中学习到行为和结果间的长程作用,使得有限长度的序列在较为稀疏奖励的游戏中也是足够的。
高效的SimPLe
为了评测算法的效率,研究人员测评了主体在100k次环境交互后的输出。研究人员在26个不同游戏中比较了Rainbow和PPO两种流行的强化学习方法,在大多数情况下SimPLe算法都比其他算法块两倍以上。

20中不同游戏的测评,左侧是Rainbow算法,右边是PPO算法,展示了达到SimPLe100k训练分数所需的交互次数。其中红线是SimPLe的结果。
效果
SimPLe算法在Pong和Freeway中表现最精彩,在模拟环境中训练的主体可以达到最高分。同时在Pong,Freeway和Breakout中几乎可以无误差预测未来50步的像素帧。
两种游戏中完美的像素预测结果,最又侧是预测的误差图,可以看到几乎与真实情况相同。
但这一算法也在某些情况下无法正确预测,它难以捕捉画面中很多微小但十分重要的物体,例如游戏中的子弹。同时也无法使用迅速变化的游戏画面,比如gameover时候的闪烁画面。
但总的来说,新方法有助于学习模拟器更好的理解周遭的环境并提供了更新更好更快的训练方法来适应多任务强化学习。虽然目前与最优秀的无模型方法还有差距,但SimPLe具有很大的效率潜力,研究人员将在未来不断深入改进。
如果你想详细了解其中的算法流程,可以参看下面的链接:
Paper: https://arxiv.org/pdf/1903.00374.pdf
这一部分代码已经集成到了tensor2tensor的强化学习代码中:
Code:https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/rl/README.md
研究人员还准备了代码和Colab帮助好学的你复现实验:
Colab:https://colab.research.google.com/github/tensorflow/tensor2tensor/blob/master/tensor2tensor/notebooks/hello_t2t-rl.ipynb
ref:https://arxiv.org/abs/1509.06113http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.329.6065&rep=rep1&type=pdf
logo pic from:https://dribbble.com/shots/4166879-Controllers
- 相关推荐
- 谷歌
-
反向强化学习的思路2019-04-03 0
-
深度强化学习实战2021-01-10 0
-
将深度学习和强化学习相结合的深度强化学习DRL2018-06-29 28025
-
萨顿科普了强化学习、深度强化学习,并谈到了这项技术的潜力和发展方向2017-12-27 11263
-
如何深度强化学习 人工智能和深度学习的进阶2018-03-03 4215
-
深度强化学习是否已经到达尽头?2019-05-10 2534
-
深度强化学习的笔记资料免费下载2020-03-10 744
-
深度强化学习到底是什么?它的工作原理是怎么样的2020-06-13 6066
-
DeepMind发布强化学习库RLax2020-12-10 738
-
模型化深度强化学习应用研究综述2021-04-12 907
-
基于深度强化学习仿真集成的压边力控制模型2021-05-27 729
-
基于深度强化学习的无人机控制律设计方法2021-06-23 987
-
《自动化学报》—多Agent深度强化学习综述2022-01-18 1621
-
ESP32上的深度强化学习2022-12-27 687
-
什么是深度强化学习?深度强化学习算法应用分析2023-07-01 1455
全部0条评论

快来发表一下你的评论吧 !
