

如何将强化学习用于火箭发动机引擎研发的创新解决方案中
电子说
描述
如何将强化学习用于火箭发动机引擎研发的创新解决方案中。
超越科技行业的机器学习
机器学习(ML)在各个行业以及众多的应用软件中产生了令人难以置信的影响,其中包括个性化电视推荐和顺风车应用中的动态价格模型等。因为它是当下科技行业各大公司成功的核心要素,所以机器学习相关理论研究和应用的发展速度十分惊人。
对于科技以外的行业,机器学习可用于用户的个性化体验,自动地执行繁重的任务并优化主观决策。然而,即使是科技行业的业内人士,了解最新的机器学习进展并且知道如何最大化利用现有的先进技术依然十分困难,更不用说那些在其他领域(例如制造业)致力于优化工作的人。
然而,跨学科的产品经理能够很好地应对这一艰巨的挑战。通过了解行业,进程和商业价值,以及对机器学习应用广度的深入理解,产品经理可以确定现有哪些领域的创新是成熟的。
具有产品管理、软件工程和数据科学经验的他们具有独特的视角,使他们自己能够促进那些尚未广泛应用机器学习的行业与先进技术应用之间的融合。通过与跨学科的各领域专家合作,产品经理可以重塑制造流程,全面提升其效率、安全性和可靠性。
作为Insight的数据产品管理研究员,我曾与机器学习工程研究员,Nina Lopatina,仿真工程师Saeed Jahangirian以及Jordan Noone的动力工程师一起工作,研究提高火箭发动机引擎的生产效率。硬件设计人员和制造商的最大成本来自于控制系统的测试、验证和校准。
我们提出了一个概念,并验证可以将强化学习用于自动调整火箭引擎中的子组件,以满足验证和协作中对大量时间和资源的需求问题。我们的解决方案可以节省数千美元,从而避免在昂贵的测试设备上进行长达三个月的手动测试。传统的程序也十分危险,很小的错误也会对昂贵的硬件造成重大损害,更重要的是,会对参与测试的技术人员构成危害。
测试,验证和校准是硬件开发中最昂贵,最耗时的任务
在制造过程中开发控制软件的过程是非常繁琐的
在我上一份工作中,我是一名软件和控制工程师,为一个大型金属3D打印机开发控制回路。控制回路是一台机器控制软件的别称。控制汽车巡航的控制软件就是一个相当简单的例子。它监控车辆的速度并控制油门直至达到目标速度。对于3D金属打印机这个项目,控制算法相对更复杂一些。我们开发的打印机是一个连接机器人手臂的焊工。机器人逐层跟踪零件,而焊工将新的一层焊接到先前的一层并构建零件。
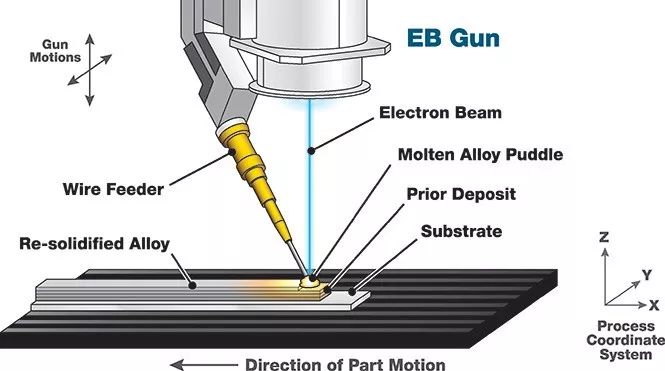
在逐层追踪零件的同时,热源熔化金属丝并将新层融合到前一层 - 图片由Sciaky Inc.提供
控制软件可控制热量的输入,遍历速度,送丝速度以及其他一些旋钮,以确保零件符合规格要求。规范包括最终部件的质量,例如缺陷的数量和尺寸,以及部件的尺寸,每层的宽度和高度。如果一切正常,结果将符合规范。但是如果控制算法没有正确地完成其工作,则该部件会变形、断裂或撕裂,并具有许多裂缝和毛孔。
开发控制算法包括三个阶段:
控制器法则设计:在这个阶段,目标是理解管理过程的物理学。开发了该过程的模拟仿真并用于创建控制软件,而无需进行昂贵且冗长的物理试验。
软件开发:在此阶段,我们使用不同的建模技术来定义过程中输入和输出之间的关系。此步骤需要工程师将问题分解为更小的部分并为每个部分开发相对应的模型。然后使用这些模型创建可以控制过程以达到预期结果的软件。
控制校准:一旦软件成功通过模拟仿真测试,工程师就会花几个月的时间在物理系统上对软件进行调整优化,以解释模拟仿真和物理现实之间的差异。
问题是每个阶段可能需要数周到数年,并且在大多数情况下,包括微调过程模型或微调控制软件以实现所需输出的种种试验。这是许多试验所做的优化问题。更智能的方法是将系统分解为更容易建模的子组件,然后使用直接和迭代方法来找到控制子组件的最佳方法。这种方法仍然需要工程师的聪明才智来解决问题,并且最终需要通过多次试验来优化各个子组件之间的交互。它还远远不是一个全自动化的过程。
为了寻找解决这一问题的自动化方法,我们将强化学习作为开发复杂机械控制回路的端到端解决方案。
强化学习
强化学习(RL)正在学习如何最大化奖励功能。从某种意义上说,强化学习是学习环境中代理的控制算法的自动化过程。
1. 一个代理在一个环境中运行,它可以使用我们称为“动作”的执行器来执行环境。
2. 然后环境响应代理所采取的操作,这样会将代理和环境置于一个新的状态。
3. 然后根据代理的状态和环境定义奖励函数。
4. RL的目标是学习采取行动的最佳策略,使未来的回报总和最大化。
强化学习的组成部分
例如,像俄罗斯方块这样的电子游戏可以被认为是一个环境,游戏中的玩家可以被认为是一个代理。
1.动作是玩家可以采取的动作,比如旋转形状。
2. 这些动作改变了游戏的状态,游戏状态可以定义为在每个时间点上显示器上的所有像素。
3.我们可以将奖励函数定义为玩家清除的每一行的+1和输掉游戏的-100。
4. 强化学习的目的是提出一个将状态映射到操作的函数,从而使总回报最大化。
类似地,金属3D打印机控制回路的开发也可以表示为强化学习问题。
1. 所采取的动作是改变热输入的强度、遍历速度、送丝速度等。
2. 这些操作改变了打印的几何形状及其质量,我们称之为打印状态。
3.奖励函数可以被定义为这样一种函数:它显示了打印结果在任何时刻与它的规格的接近程度。
4. 其目标是提出一个函数,告诉打印机如何控制其执行器,给定其当前打印状态,以获得最佳打印结果。
所有控制的问题都可以描述为强化学习问题。目的是估计一个称为“策略”的函数。策略将状态映射到操作,从而使奖励函数最大化。如果函数域是有限的,那么你可以探索和存储每个输入和输出映射,但是如果函数具有复杂的动态和很大或无限的域,那么这时机器学习就可以发挥作用了。
最近,强化学习研究人员一直致力于解决棘手的问题。他们跟随深度学习的脚步,解决了经典算法无法解决的任务(图像分类),得到了很多的牵引和关注。他们着手解决目前经典算法几乎无法解决的非常困难的问题。谷歌的DeepMind专注于在围棋等非常复杂的游戏中击败人类,而OpenAI专注于开发通用的人工智能。
另外,强化学习也可以用来自动解决更简单的问题,而不是专注于困难的问题,这些问题目前都是人工完成的,需要花费大量的时间和精力来解决,比如为3D打印机或其他复杂的机械部件开发一个控制循环。这种影响不如开发通用智能具有新闻价值,但它可以为许多制造组织中的许多控制工程师节省时间和精力。
用RL调整火箭发动机
我们制作了火箭发动机或燃气轮机中遇到的流体动力学问题的简化版本。为这样的系统开发控制算法可能需要长达3个月的设计、测试和验证。这是一个非线性控制问题,需要工程师的智慧和时间来解决,可以证明强化学习在解放工程师时间方面的可行性。
以流体动力学中的一个非线性控制问题为例,说明了用强化学习开发控制算法的可行性
这是一个跨学科的项目,需要推动工程师之间的合作来定义问题,仿效工程师来构建一个准确的系统模拟,以及一个培训代理的机器学习工程师。最后,结果表明强化学习算法可以产生与控制工程师一样好的控制策略,并且可以节省数月的试验时间。
针对流体动力学控制问题,策略优化过程中的模拟状态快照。
一个使用深度增强学习(Proximal Policy Optimization)训练过的代理对一个新目标做出反应。代理平均通过4个步骤自动更改输入参数以匹配所需的输出。结果与由工程师开发和调整的控制算法一样好。
结论
我们使用强化学习来为火箭发动机的制造提供一个有效的解决方案,而不是使用机器学习技术来解决以前几乎不可能完成的任务。使用机器学习解决更简单的问题是一种适用于许多领域的方法,如制造业、汽车和航空航天工业。强化学习研究人员通常是看不到这些行业所面临的困难,同样地,这些行业往往也不熟悉强化学习领域的进展。这种脱节更突出了机器学习产品经理在机器学习与产品需求之间的联系,以及弥合学科之间的差距方面所起到的作用。
Insight的数据产品管理研究项目(The Insight Data Product Management Fellowship)提供了一个协作学习环境来弥补这一差距。产品经理、工程师和数据科学家通过利用各自在这些领域的专长,共同构建交叉学科的产品。Insight吸引了来自工程、科学和产品领域的不同背景的学者,当他们聚在一起时,我们看到机器学习的新应用成功地解决了各个行业的问题。
-
发动机分为哪几种2021-07-12 0
-
VXI总线技术在固体火箭发动机测试中的应用2009-07-15 657
-
遥测技术在火箭发动机过载试验中的应用2010-03-09 1050
-
7月19日快讯:3D打印火箭发动机/多晶硅初裁2013-07-19 1611
-
液体火箭发动机的设计与制作资料免费下载2019-02-12 3652
-
200吨级碳纤维火箭发动机研制成功,未来国产导弹更轻、射程更远2019-03-19 5541
-
商业航天的固体火箭发动机数字化快速总体论证APP2020-11-02 1930
-
重新设计核动力火箭发动机 飞向火星!2020-12-29 2991
-
我国最大推力分段式固体火箭发动机试车成功2020-12-30 2248
-
我国自主研制分段式火箭发动机试车成功2020-12-30 1620
-
3D打印在火箭发动机上的应用2021-05-25 638
-
火箭发动机的防热结构件智能压粘机控制系统2021-06-23 558
-
模型火箭发动机试验台开源分享2022-10-21 432
-
混合动力火箭发动机开源2023-02-01 344
-
航天科技集团重磅发布六款固体火箭发动机2023-10-22 887
全部0条评论

快来发表一下你的评论吧 !
