

Linux微服务架构中容错隔离的详细资料技术
描述
我们知道,在单体应用的架构下一旦程序发生了故障,那么整个应用可能就没法使用了,所以我们要把单体应用拆分成具有多个服务的微服务架构,来减少故障的影响范围。但是在微服务架构下,有一个新的问题就是,由于服务数变多了,假设单个服务的故障率是不变的,那么整体微服务系统的故障率其实是提高了的。
比如:假设单个服务的故障率是0.01%,也就是可用性是99.99%,如果我们总共有10个微服务,那么我们整体的可用性就是99.99%的十次方,得到的就是99.90%的可用性(也就是故障率为0.1%)。可见,相对于之前的单体应用,整个系统可能发生故障的风险大幅提升。
那么在这种情况下,我们应该怎么去保证微服务架构的可用性呢?
其实我们参考造船行业对船舱进水风险的隔离方法,如上图。
造船行业有一个专业术语叫做「舱壁隔离」,利用舱壁将不同的船舱隔离起来,如果某一个船舱进了水,那么就可以立即封闭舱门,形成舱壁隔离,只损失那一个船舱,其他船舱不受影响,整个船只还是可以正常航行。
对应到微服务架构中,我们要做的就是最大限度的隔离单个服务的风险,也就是「 容错隔离 」的方法。
一、微服务架构中可用性风险有哪些?
在聊「容错隔离」方法之前,我们先来看一下微服务架构中,常见的可用性风险到底有哪些吧,知道了有哪些风险我们才知道该如何去规避、去隔离风险。
我们可以从项目部署规模的角度去分析风险:
单机可用性风险:
这个很好理解,就是微服务部署所在的某一台机器出现了故障,造成的可用性风险。这种风险发生率很高,因为单机器在运维中本身就容易发生各种故障,例如 硬盘坏了、机器电源故障等等,这些都是时有发生的事情。不过虽然这种风险发生率高,但危害有限,因为我们大多数服务并不只部署在一台机器上,可能多台都有,因此只需要做好监控,发现故障之后,及时的将这台故障机器从服务集群中剔除即可,等修复了再重新上线到集群里。
单机房可用性风险:
这种风险的概率比单机器的要低很多,但是也不是完全不可能发生,在实际情况中,还是有一定概率的。比如最为常见的就是通往机房的光纤被挖断了,前段时间支付宝所在机房不是就发生过光纤被挖么。
咱们全国大小城市都在疯狂的进行基建,修桥修路修房子,GDP就这么搞起来了,地下的光纤挖断几根不是再正常不过的事情了么,哈哈。
如果我们的服务全部都部署在单个机房,而机房又出故障了,那就没辙了。好在,现在大多数中大型项目都会采用多机房部署的方案,比如同城双活、异地多活等。一旦某个机房出现了故障不可用了,咱们立即采用切换路由的方式,把这个机房的流量切到其它机房里。
跨机房集群可用性风险:
既然都跨机房集群了,可用性理论上应该没啥问题啊。但要知道这是在物理层面没有问题了,如果咱们的代码有坑,或者因为特殊原因用户流量激增,导致我们的服务扛不住了,那在跨机房集群的情况下一样会不可用。但如果我们提前做好了「容错隔离」的一些方案,比如 限流、熔断 等等,用上这些方法还是可以保证一部分服务或者一部分用户的访问是正常。
二、「 容错隔离 」的方法有哪些?
好了,上面讲了微服务架构中可能遇到这么多的可用性风险,并且也知道了「容错隔离」的重要性,下面我们再来看看常见的「容错隔离」方法有哪些:
超时:
这也是简单的容错方式。就是指在服务之间调用时,设置一个 主动超时时间,超过了这个时间阈值后,如果“被依赖的服务”还没有返回数据的话,“调用者”就主动放弃,防止因“被依赖的服务”的故障所影响。
限流
顾名思义,就是限制最大流量。系统能提供的最大并发有限,同时来的请求又太多,服务不过来啊,就只好排队限流了,就跟去景点排队买票、去商场吃饭排队等号的道理一样一样儿的。
降级
这个与限流类似,一样是流量太多,系统服务不过来。这个时候可以可将不是那么重要的功能模块进行降级处理,停止服务,这样可以释放出更多的资源供给核心功能的去用。同时还可以对用户分层处理,优先处理重要用户的请求,比如VIP收费用户等。
延迟处理
这个方式是指设置一个流量缓冲池,所有的请求先进入这个缓冲池等待处理,真正的服务处理方按顺序从这个缓冲池中取出请求依次处理,这种方式可以减轻后端服务的压力,但是对用户来说体验上有延迟。
熔断
可以理解成就像电闸的保险丝一样,当流量过大或者错误率过大的时候,保险丝就熔断了,链路就断开了,不提供服务了。当流量恢复正常,或者后端服务稳定了,保险丝会自动街上(熔断闭合),服务又可以正常提供了。这是一种很好的保护后端微服务的一种方式。
熔断技术中有个很重要的概念就是:断路器,可以参考下图:
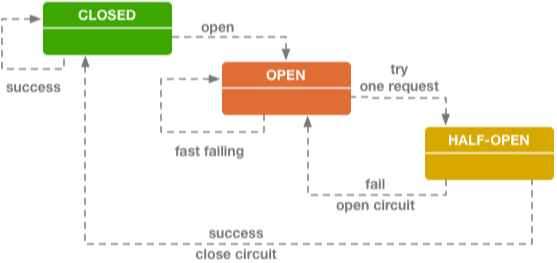
断路器其实就是一个状态机原理,有三种状态:Closed(闭合状态,也就是正常状态)、Open(开启状态,也就是当后端服务出故障后链路断开,不提供服务的状态)、Half-Open(半闭合状态,就是允许一小部分流量进行尝试,尝试后发现服务正常就转为Closed状态,服务依旧不正常就转为Open状态)。
三、「 容错隔离 」的应用?
在容错隔离或者说熔断技术方面做得最出名的框架就是 Hystrix 了。Hystrix是由Netflix开源,在业内应用非常广泛。
下面是Hystrix的原理流程图:
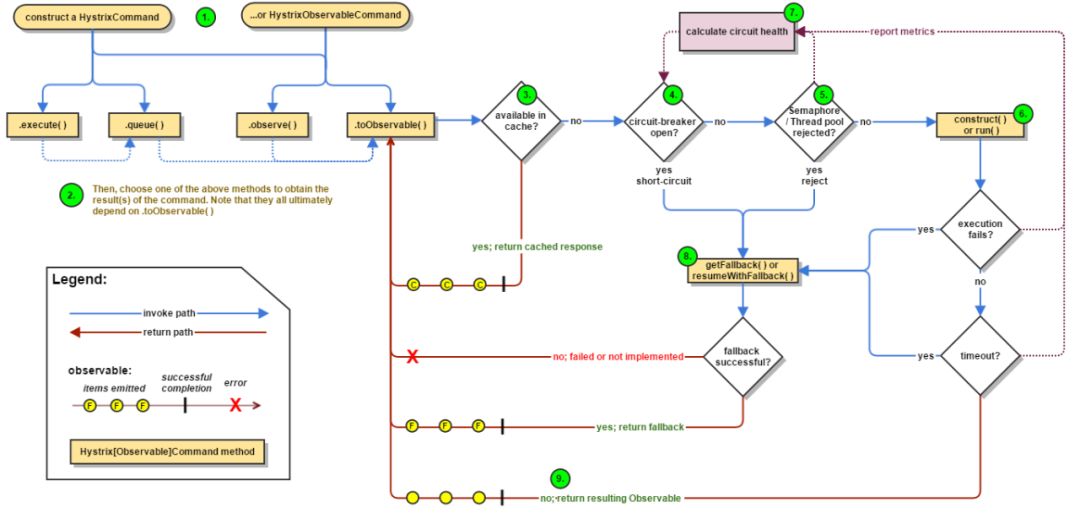
这是新版流程,比之前旧版本又复杂很多,如果不讲解一下,估计很多人都不容易看懂。
图中标注了数字1-9,可以按照这个数字顺序去理解这个流程。
当我们使用了Hystrix之后,请求会被封装到HystrixCommand中,这也就是第一步。然后第二步就是开始执行请求,Hystrix支持同步执行(图中.execute方法)、异步执行(图中.queue方法)和响应式执行(图中.observer)。然后第三步判断缓存,如果存在与缓存中,则直接返回缓存结果。如果不在缓存中,则走第四步,判断 断路器 的状态是否是开启的,如果是开启状态,也就是短路了,那就进行失败返回,跳到第八步,第八步需要对失败返回的处理也需要再做一次判断,要么正常失败返回,返回相应信息,要么根本没有实现失败返回的处理逻辑,就直接报错。如果 断路器 不是开启状态,那请求就继续走,进行第五步,判断线程/队列是否满了,如果满了,那么同样跳到第八步,如果线程没满,则走到第六步,执行远程调用逻辑,然后判断远程调用是否成功,调用发生异常了就挑到第八步,调用正常就挑到第九步正常返回信息。
图中的第七步,非常牛逼的一个模块,是来收集Hystrix流程中的各种信息来对系统做监控判断的。
另外,Hystrix的断路器实现原理也很关键,下面就是Hystrix断路器的原理图:
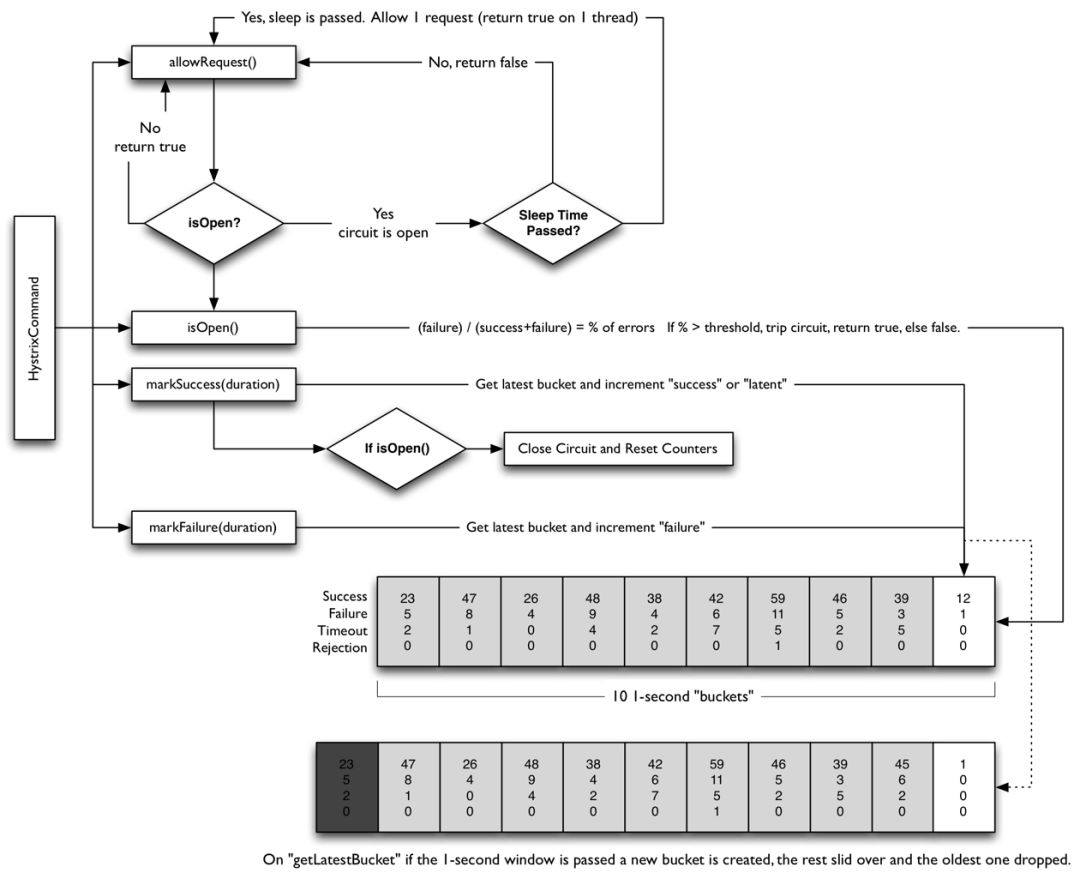
Hystrix通过滑动时间窗口算法来实现断路器的,是以秒为单位的滑桶式统计,它总共包含10个桶,每秒钟一个生成一个新的桶,往前推移,旧的桶就废弃掉。
每一个桶中记录了所有服务调用的状态,调用次数、是否成功等信息,断路器的开关就是把这10个桶进行聚合计算后,来判断当前是应该开启还是闭合的。
以上,就是对微服务架构中「容错隔离」的一些思考。
-
微服务架构和CQRS架构基本概念介绍2019-05-22 0
-
萌新求助,求ARM内核架构和SOC架构的详细资料2021-10-25 0
-
微服务网关gateway的相关资料推荐2021-12-23 0
-
微服务架构与实践摘要2018-02-07 6140
-
微服务优势_微服务架构的好处与不足2018-02-23 4395
-
什么是微服务架构_微服务架构的优缺点及应用2019-06-02 17438
-
微服务架构有哪些_微服务架构设计模式2021-05-17 28889
-
微服务架构的特点_微服务架构适用场景2021-05-17 5155
-
微服务软件架构应用研究综述2021-05-26 665
-
微服务架构中的服务之间如何互相调用呢?2023-01-31 2212
-
什么是微服务架构?2023-02-24 1345
-
springcloud微服务架构2023-11-23 1351
-
docker微服务架构实战2023-11-23 654
-
设计微服务架构的原则2023-11-26 601
-
微服务架构与容器云的关系与区别2024-10-21 232
全部0条评论

快来发表一下你的评论吧 !
