

Xilinx UltraScale:为您未来架构而打造的新一代架构
FPGA/ASIC技术
描述
Xilinx UltraScale™ 架构针对要求最严苛的应用,提供了前所未有的ASIC级的系统级集成和容量。
UltraScale架构是业界首次在All Programmable架构中应用最先进的ASIC架构优化。该架构能从20nm平面FET结构扩展至16nm鳍式FET晶体管技术甚至更高的技术,同时还能从单芯片扩展到3D IC。借助Xilinx Vivado®设计套件的分析型协同优化,UltraScale架构可以提供海量数据的路由功能,同时还能智能地解决先进工艺节点上的头号系统性能瓶颈。这种协同设计可以在不降低性能的前提下达到实现超过90%的利用率。
UltraScale架构的突破包括:
• 几乎可以在晶片的任何位置战略性地布置类似于ASIC的系统时钟,从而将时钟歪斜降低达50%
• 系统架构中有大量并行总线,无需再使用会造成时延的流水线,从而可提高系统速度和容量
• 甚至在要求资源利用率达到90%及以上的系统中,也能消除潜在的时序收敛问题和互连瓶颈
• 可凭借3D IC集成能力构建更大型器件,并在工艺技术方面领先当前行业标准整整一代
• 能在更低的系统功耗预算范围内显著提高系统性能,包括多Gb串行收发器、I/O以及存储器带宽
• 显著增强DSP与包处理性能
赛灵思UltraScale架构为超大容量解决方案设计人员开启了一个全新的领域。
越多越好
自从“全面数字化”(all things digital)概念引入以来,“越多越好”成为了所有市场领域中数字系统的一种基本的、必然的发展趋势。这一期望成为了促使系统要求更高分辨率、更高带宽和更大存储量的基本动力。而“更多”这一理念同时从逻辑上也引发了如下事实的产生:
• 更多的器件生成更多数据。
• 更多的数据意味着数据必须更快流动。
• 更多快速流动的数据要求计算速度更快。
• 更多的应用需要更快速地访问更多数据。
• 数据量的增长和数据速率的提高对数据完整性提出了更高要求。
目前几乎每个领域的数据创建和数据传输速率都在快速增长,这会加大对新型器件架构的需求,以应对如下问题所带来的重重挑战:
• 海量数据流以及类似于ASIC的时钟布线
• 海量I/O和存储器带宽
• 更快的DSP和包处理
• 电源管理
• 多级安全
UltraScale架构:赛灵思的新一代All Programmable架构
为了达到每秒数百Gb的系统性能和全线速下的智能处理能力,并扩展到Tb级和每秒万亿次浮点运算,需要采用一种新的架构方案。为此,我们要做的不仅仅是简单地提高每个晶体管或系统模块的性能,或扩展系统中的模块数量,而是要从根本上改善通信、时钟、关键路径和互连功能,以满足海量数据流、实时数据包和图像处理需求。
UltraScale™ 架构通过在一个全面可编程(All Programmable)架构中应用最先进的ASIC 技术,可应对上述需要海量I/O和存储器带宽、海量数据流以及卓越DSP和包处理性能的挑战。。UltraScale架构经过精调可提供大规模布线能力并且与Vivado®设计工具进行协同优化,因此该架构的利用率达到了空前的高水平(超过90%),而且不会降低性能。
UltraScale架构是业界首次在All Programmable架构中应用最先进的ASIC架构优化该架构能从20nm平面FET结构扩展至16nm鳍式FET晶体管技术甚至更高的技术,同时还能从单芯片扩展到3D IC。UltraScale架构不仅能解决系统总吞吐量扩展和时延方面的局限性,而且还能直接应对先进工艺节点上的头号系统性能瓶颈,即互连问题。
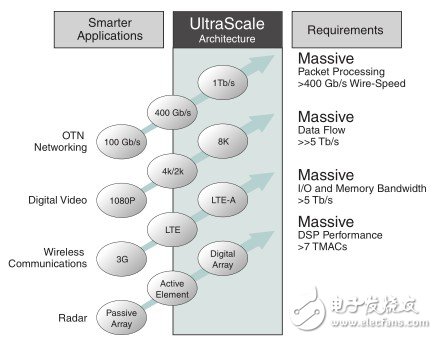
Xilinx UltraScale架构旨在满足下一代系统级性能要求。(见图1)
赛灵思对UltraScale架构进行了数百项设计提升,并将这些改进实现有机结合,让设计团队能够打造出比以往功能更强、运行速度更快、单位功耗性能更高的系统。见图2。
图2:Xilinx UltraScale架构
UltraScale架构与Vivado™设计套件结合使用可提供如下这些新一代系统级功能:
· 针对宽总线进行优化的海量数据流,可支持数Tb级吞吐量和最低时延
· 高度优化的关键路径和内置高速存储器,级联后可消除DSP和包处理中的瓶颈
· 增强型DSP slice包含27x18位乘法器和双加法器,可以显著提高定点和IEEE 754标准浮点算法的性能与效率
· 第二代3D IC系统集成的晶片间带宽以及最新3D IC宽存储器优化接口均实现阶梯式增长
· 类似于ASIC的多区域时钟,提供具备超低时钟歪斜和高性能扩展能力的低功耗时钟网络
· 海量I/O和存储器带宽,用多个硬化的ASIC级100G以太网、Interlaken和PCIe® IP核优化,可支持新一代存储器接口功能并显著降低时延
· 电源管理可对各种功能元件进行宽范围的静态与动态电源门控,实现显著节能降耗
· 新一代安全策略,提供先进的AES比特流解密与认证方法、更多密钥模糊处理功能以及安全器件编程
· 通过与Vivado工具协同优化消除布线拥塞问题,实现了90%以上的器件利用率,同时不降低性能或增大时延
系统设计人员将这些系统级功能进行多种组合,以解决各种问题。下面的宽数据路径方框图可以很好地说明这一问题。见图3.
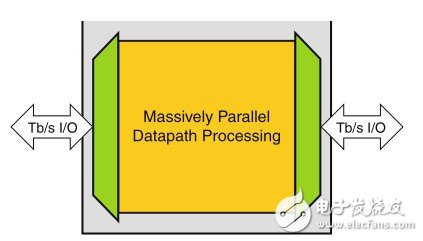
图3:Tb级I/O需要海量的并行数据路径
图中,数据速率高达Tbps的数据流从从左侧流入再从右侧流出。系统必须在左右两侧的I/O端口之间传输数据流,同时还要执行必要的处理工作。可以通过高速串行收发器来进行I/O传输,运行速率高达数Gbps。一旦数Gbps的串行数据流进入器件,就必须扇出(fan out),以便与片上资源的数据流、路由和处理能力相匹配。
Tb级系统的设计挑战:时钟歪斜与海量数据流
举一个现实的实例,假设左侧和右侧I/O端口的带宽为100Gb/s。这意味着片上资源也必须要处理至少100Gb/s的流量。设计人员一般采用512至1024位的宽总线或数据路径来处理相关的数据吞吐量,产生一个与片上资源功能相匹配的系统时钟。如果线速提高到400Gb/s,那么总线宽度达到1024至2048位也并不少见。
现在考虑一下这类总线的时钟要求。在UltraScale架构推出之前,高系统时钟频率运行会使这些海量数据路径上的时钟歪斜程度增大,甚至达到整个系统时钟周期的将近一半。时钟歪斜几乎占用一半的时钟周期,这种情况下设计方案需要依靠大量流水线才有可能达到目标系统性能。只剩下一半的时钟周期可用于计算,因此得到可行解决方案的几率就会很低。大量使用流水线不仅会占用大量寄存器资源,而且还会对系统的总时延造成巨大影响,这也再次证明了这种方法在当今的高性能系统中不可行。
UltraScale架构提供类似ASIC时钟功能
多亏UltraScale 架构提供类似ASIC的多区域时钟功能,使得设计人员现在可以将系统级时钟放在整个晶片的任何最佳位置上,从而使系统级时钟歪斜降低多达50%。将时钟驱动的节点放在功能模块的几何中心并且平衡不同叶节点时钟单元(leaf clock cell)的时钟歪斜,这样可以打破阻碍实现多Gb系统级性能的一个最大瓶颈。系统总体时钟歪斜降低后,就无需再使用大量流水线,并可消除随之而来的时延问题。UltraScale架构中类似于ASIC的时钟功能不仅能移除时钟布置方面的限制,还能在系统设计中实现大量独立的高性能、低歪斜时钟源。这与前几代可编程逻辑器件中所采用的时钟方案完全不同。从系统设计人员的角度出发,这种解决方案能轻松解决时钟歪斜问题。
从容应对海量数据流挑战
极高性能应用一般采用宽总线或宽数据路径来匹配路由到片上处理资源的数据流。然而采用宽总线来扩展性能时,除了要简单处理时钟歪斜问题外,还要应对一系列自身挑战。众所周知,同类竞争架构经证实其适用于高性能设计的布线资源非常有限且缺乏灵活性。如果FPGA的互连架构性能较低,那么用它来实现100Gb/s吞吐量的应用时,需要将数据总线提升到1536至2048位的宽度。
尽管更宽的总线实现方案可以降低系统时钟频率,但由于缺乏支持宽总线系统所需的布线资源,因此会产生严重的时序收敛问题。而且有些FPGA厂商采用的是过时的模拟退火布局布线算法,不考虑拥塞程度和总线路长度等全局设计指标,因此会进一步加剧时序收敛问题。这样,设计人员就不得不进行多方面权衡,包括降低系统性能(通常不可取);使用大量流水线,不惜增大时延;或者降低可用器件资源利用率。在任何情况下,经证明这些解决方案都是不佳或存在欠缺的方案。最重要的是,传统FPGA中布线资源(用于满足100Gb/s应用的要求)的局限性几乎可以说明它们不可能适用新一代多Tb应用的要求,即便能适用,但器件的利用率会非常低,时延极高。
更为复杂的问题在于,通过大量的宽数据总线来扩展性能会带来额外的代价,那就是需要显著增加逻辑威廉希尔官方网站 开销用以支持宽总线的实施,从而进一步加大实现时序收敛的难度。
以以太网数据包大小为例可以很好地说明这个情况。以太网的数据包最小为64字节(512位)。假设采用2048位宽的总线来实现400G的系统,那么总线最多容纳4个数据包。
在2048位宽的总线中存在多种数据包组合形式,例如4个完整数据包或者1个、2个或3个完整或部分数据包,这样需要使用大量逻辑来处理不同的情况与组合。需要大量复杂的重复逻辑来应对这些可能的组合。此外,如果总线要求对四个数据包进行同时处理并写入到存储器中,那么可能需要对逻辑的某些部分进行加速(或扩展性能)。可以考虑通过逻辑加速或用四个独立的相同存储器控制器来相继处理多个数据包,但这些方式会进一步加大布线资源的压力,迫使架构必须具备更多的高性能、低歪斜布线资源。参见图4。
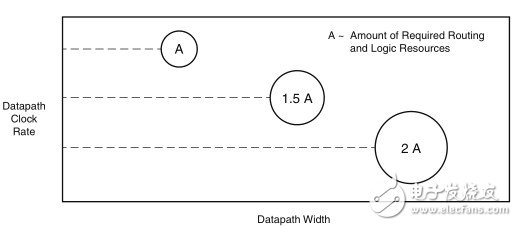
图4:增加数据路径时钟宽度和时钟速率需要更多逻辑和布线资源
半导体工艺的扩展影响互连技术
随着业界向20nm或更高级半导体工艺技术推进,在与铜线互连有关的RC延迟方面出
现了新的挑战,它会阻碍向新工艺节点演进所实现的性能提升效果。晶体管互连延迟的增加会直接影响所能实现的总体系统性能,因此更加需要所使用的布线架构能提供满足新一代应用要求的性能等级。UltraScale布线架构在开发过程中充分考虑了新一代工艺技术的特点,而且能明显减轻铜线互连的影响——如不进行妥善处理会成为系统性能瓶颈。
UltraScale互连架构:针对海量数据流进行优化
UltraScale新一代互连架构的推出体现了可编程逻辑布线技术的真正突破。赛灵思致力于满足从多Gb智能包处理到多Tb数据路径等新一代应用需求,即必须支持海量数据流。在实现宽总线逻辑模块(将总线宽度扩展至512位、1024位甚至更高)的过程中,布线或互连拥塞问题一直是影响实现时序收敛和高质量结果的主要制约因素。过于拥堵的逻辑设计通常无法在早期器件架构中进行布线;即使工具能够对拥塞的设计进行布线,最终设计也经常需要在低于预期的时钟速率下运行。而UltraScale布线架构则能完全消除布线拥塞问题。结论很简单:只要设计合理,就能进行布线。
我们来做个类比。位于市中心的一个繁忙十字路口,交通流量的方向是从北到南,从南到北,从东到西,从西到东,有些车辆正试图掉头,所有交通车辆试图同时移动。这样通常就会造成大堵车。现在考虑一下将这样的十字路口精心设计为现代化高速公路或主干道,情况又会如何。道路设计人员设计出了专用坡道(快行道),用以将交通流量从主要高速路口的一端顺畅地疏导至另一端。交通流量可以从高速路的一端全速移动到另一端,不存在堵车现象。
赛灵思为UltraScale架构加入了类似的快行道。这些新增的快行道可供附近的逻辑元件之间传输数据,尽管这些元件并不一定相邻,但它们仍通过特定的设计实现逻辑上的连接。这样,UltraScale架构所能管理的数据量就会呈指数级上升,如图5所示。
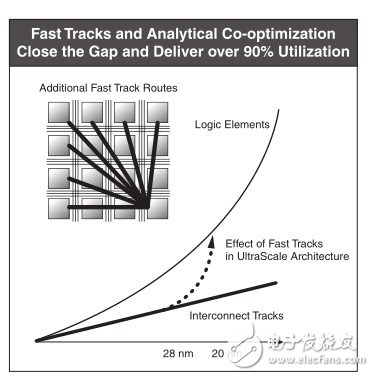
图5:增加真实有效的路由路径可以帮助解决日益增长的系统复杂性
UltraScale架构堆叠硅片互联技术全面强化所有功能
很少有开发的技术能够像堆叠硅片互联(SSI)技术集成那样对器件容量和性能产生如此重大的影响,这已得到了赛灵思第一代基于7系列All Programmable器件的3D IC产品的验证。集成SSI技术后,设计人员可以构建出工艺技术领先行业标准整整一代水平的更大型器件。而且该技术在赛灵思第二代基于UltraScale架构的3D IC产品中也同样会达到这种效果。
由于3D IC中硅片间通信连接比独立封装的硅片间通信连接更密集、更快速,因此硅片间的通信所需功耗更低(假设硅片无需驱动硅片到封装间互连以及板级互连的附加阻抗)。所以,与独立封装的硅片相比,SSI技术的集成能够在显著扩大容量和性能的同时降低功耗。此外,由于无法轻易访问威廉希尔官方网站 板层面的硅片间通信,这样系统安全性也得到了加强。
Virtex®UltraScale和Kintex®UltraScale系列成员在第二代3D IC中的连接资源数量以及相关的硅片间带宽都实现了阶梯式增长。布线资源和硅片间带宽的大幅增长确保了新一代应用能够在实现其高器件利用率的前提下达到目标性能和时序收敛。
更多内容,请点击链接下载:http://www.elecfans.com/soft/5/2013/20130715324025.html
-
Xilinx UltraScale:为您未来架构而打造的新一代架构2013-07-15 2884
-
直击关于Xilinx UltraScale架构、Virtex和Kintex UltraScale架构FPGA 和最新的Vivado开发工具的9大要点2017-02-08 714
-
Xilinx高级副总裁Victor Peng带您了解 UltraScale 架构2018-06-05 4018
-
龙芯中科携手百代存储打造基于龙架构的新一代国产统一存储解决方案2023-10-09 798
-
Xilinx UltraScale 系列发布常见问题汇总2013-12-17 0
-
新一代音频DAC的架构介绍2019-07-22 0
-
德州仪器(TI)推出新一代KeyStone II架构2021-05-19 0
-
UltraScale DSP48 Slice架构的优势是什么?2021-05-24 0
-
常见问题解答:Xilinx采用首个ASIC级UltraScale可编程架构2013-07-09 2357
-
Xilinx UltraScale:新一代架构满足您的新一代架构需求(EN)2013-07-09 1558
-
UltraScale架构面世 Xilinx挑战ASIC竞争格局2013-07-11 2650
-
Xilinx UltraScale架构打造高性能智能系统(EN)2013-12-18 1518
-
Imagination宣布推出新一代GPU架构2017-03-10 892
-
如何使用UltraScale架构解决功耗问题2018-11-22 3325
-
Xilinx全新UltraScale架构介绍2021-05-28 3471
全部0条评论

快来发表一下你的评论吧 !
