

使用LabVIEW进行GPU计算
FPGA/ASIC技术
描述
具有并行处理架构的平台,例如FPGA和GPU,在快速分析大型数据集方面得到了广泛应用。这两项技术可以减轻运算密集型算法对CPU造成的负担,在高度并行的平台上进行处理。FPGA灵活性高、处理延迟低,但是由于容量不足,在浮点运算方面具有一定的局限性。GPU因为其灵活性、便捷性以及低成本的特点,已经成为并行处理的普遍选择。它们可以成功地与FPGA协同工作,优化一个算法的执行速度。举例来说,在一个算法中,当 GPU分析浮点数据时,内联(Inline)计算能够在FPGA上快速地执行。NVIDIA®计算统一设备架构(Compute Unified Device Architecture)CUDA™,,可以帮助创建基于GPU计算的算法,CUDA™允许用户使用C编程语言及其NVIDIA扩展创建程序代码。
图1.FPGA和GPU可以与CPU协同工作,优化性能。
对于实时高性能计算领域的许多应用来说,都可以将数据和任务需求很好地映射到GPU中进行处理。高强度算术运算的算法应用非常适合在GPU上进行处理;如果一个应用中的算术运算相对于内存运算的比例较高,则表明当在GPU架构上解决这个计算任务可以带来明显的速度提升。举例来说,对于处理多通道运算的应用,(如可以并行计算几个FFT变换),或者数学运算(如大型的矩阵运算),都可以有效地映射到GPU中。
LabVIEW GPU分析工具包让开发人员能够在LabVIEW应用框架中充分利用GPU并行架构。该工具包利用了NVIDIA的CUDA工具包的功能,以及CUBLAS和CUFFT库,同时允许开发人员直接调用那些在LVGPU SDK已经写好的GPU代码。
LabVIEW GPU 分析工具包
LabVIEW GPU分析工具包允许开发人员利用NVIDIA CUDA以及CUBLAS和CUFFT方法的核心资源,可以在LabVIEW中调用这些库中封装的函数。对于高级的运算,利用在CUDA中已经被开发的代码,可以使用LabVIEW GPU分析工具包,将计算任务转移到GPU中。请注意,该工具包将无法编译LabVIEW代码用于GPU,但是它可以在LabVIEW中使用封装好的CUDA函数或者自定义的CUDA内核代码。在唯一的设备执行环境中(即CUDA环境),通过处理CUDA核心程序运算及其参数,高级的自定义内核代码可以在LabVIEW执行过程中安全地调用。该环境还确保了所有的GPU资源和功能要求得到妥善管理。
LabVIEW GPU分析工具包的出现能够使科学家和工程师执行大规模的数据采集、将数据块转移到GPU进行快速处理,并在统一的LabVIEW应用程序中查看处理的数据。常见的信号处理技术和数学运算,例如信号的快速傅立叶变换,可以通过直接调用NVIDIA库中相应的VI来实现,非常方便。这样,开发人员可以使用所有可用的计算资源快速开发应用的原型。对于那些已经在CUDA出来的复杂的应用程序,能够被用于LabVIEW当中,使用自定义的算法快速地处理数据。
在GPU上快速处理FFT运算
一般情况下,使用LabVIEW GPU 分析工具包与GPU通信可以被细分为三个阶段:GPU初始化、在GPU上执行运算,以及释放GPU资源。下面的部分将讨论使用LabVIEW GPU分析工具包将一个FFT运算任务从CPU FFT转移到GPU中。
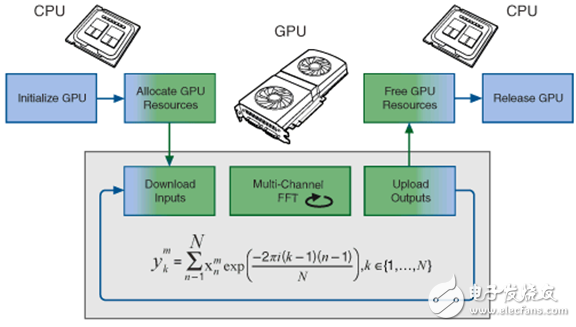
图2. 将一个FFT运算任务从CPU转移到GPU进行分析的程序流程。
本范例对来自多个仿真通道的仿真信号进行FFT运算,来模拟来自DAQ设备或日志文件的多通道输入数据的采集。该工作流程是典型的将一个FFT运算任务从CPU转移到GPU进行分析的过程。
I. 初始化GPU资源
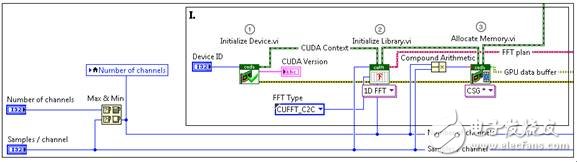
图3. 初始化GPU资源
首先,选择一个GPU设备是很有必要的。接着,将创建CUDA环境,用于实现LabVIEW和GPU间的通信。这是通过使用Initialize Device VI来完成的。接下来,GPU将通过选择FFT的类型为FFT运算做准备。该类型包括FFT大小、在GPU上并行执行FTT的数量,以及输入信号或者谱线的数据类型等信息。该过程将预定GPU上的资源,实现最高的性能。Allocate Memory VI在GPU上创建一个内存缓冲区,用于CPU和GPU间的数据传输,以便进行FFT运算。它将存储用于下载到GPU的通道数据,以及GPU上计算完成后准备上传到CPU的数据结果。
II. 在GPU上执行FFT计算
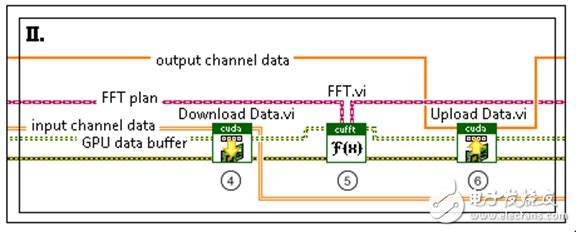
图4. 在GPU上执行FFT通信
首先,从CPU传输数据到GPU的缓冲区上来执行计算。在GPU上执行FFT计算时,将利用其大规模的并行架构来同时计算每个通道的FFT。当计算完成后,数据从GPU的缓冲区传输回CPU中的数组中。Download Data VI将存储在LabVIEW数组中的多通道数据从CPU传输到在初始化阶段已经分配的缓冲区中。FFT VI为每一个下载的通道数据并行计算其频谱。最后,Upload Data VI将存储在GPU缓冲区中的频谱数据传输回LabVIEW数组,用于CPU进一步处理。
III. 释放GPU资源
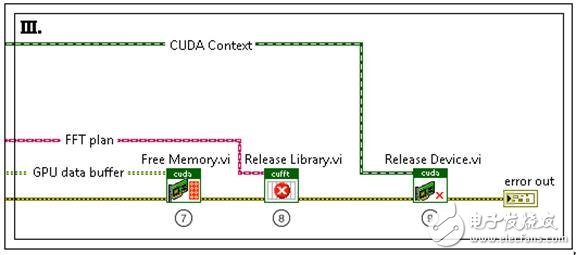
图5.释放GPU资源
最后一步的操作是释放第一步中初始化的GPU资源。Free Memory VI释放GPU上用来存储FFT数据的缓冲区。Release Library VI释放GPU上在FFT运算初始化过程中保留的资源。最后,Release Device VI释放CUDA环境初始化过程中为建立GPU通信所保留的GPU资源。
结论
使用LabVIEW GPU 分析工具,开发人员能够将重要的运算转移到GPU中进行处理,从而释放CPU资源用于其它任务。这为LabVIEW用户提供了一个非常强大的、前所未有的处理资源。现在,无论使用FPGA和CPU,还是GPU,采集到的数据可以快速地被处理,并可以从一个单一的LabVIEW应用程序中查看。因此,用户能够更有效地利用系统资源,同时最大限度地减少高度并行的数据处理运算和转换所带来的计算成本。
-
《CST Studio Suite 2024 GPU加速计算指南》2024-12-16 0
-
GPU2016-01-16 0
-
NVIDIA火热招聘GPU高性能计算架构师2017-09-01 0
-
labVIEW读取excel数据并进行计算2018-04-17 0
-
在K520上能使用两个GPU进行CUDA作业吗2018-09-26 0
-
请问Mali GPU的并行化计算模型是怎样构建的?2021-04-19 0
-
如何对RK GPU进行调试呢2022-02-15 0
-
Labview之计算e近似值2016-04-19 2069
-
Labview之复杂公式计算2016-04-19 688
-
Labview之函数计算与绘图2016-04-19 609
-
CPU内存或GPU内存进行分组方式实战2018-05-03 7155
-
labview计算器2023-05-29 545
-
labview计算秒钟小程序2023-08-21 271
-
GPU加速计算平台是什么2024-10-25 251
全部0条评论

快来发表一下你的评论吧 !
