

成像声纳中多波束形成的FPGA工程实现
FPGA/ASIC技术
描述
摘要:本文提出了一种计算方法简单、计算量小、所需存储量小的近场聚焦多波束形成的高速FPGA实现方法,用于成像声纳中高精度、高覆盖、高波束数的多波束形成。本方法基于180阵元均匀半圆阵,通过阵元等效弦的转动,仅采用6组加权系数矢量即可在90°范围内产生540个波束,使存储量降低了两个数量级,从而有效降低对硬件存储资源的要求。该系统工作在270MHz,通过乒乓操作实现数据不间断的输入输出,从而提高速度;通过多通道多系数复用乘法器和流水并行技术,仅采用24个乘法器完成了540个波束的实时产生,实现了8190倍复用。与传统并行处理架构相比,该方法提高了系统稳定性和速度,并大大节约了FPGA硬件资源。
引言
由于成像系统具有通道数多、数据量大、计算复杂、实时成像的特点[1][2],因此要求处理器在保证声纳的灵敏度的前提下具有高速、高精度、大存储量和实时处理的能力[3]。与其他CPU、DSP处理器相比,FPGA具有无法比拟的系统级的用户可编程特性以及强大的并行计算能力,适用于高速、高密度的高端数字逻辑威廉希尔官方网站
设计。此外,FPGA具有非常高性能的I/O带宽。大量的I/O引脚和多块存储器可让系统在设计中获得优越的并行处理性能,适用于具有180通道信号输入的成像声纳系统。利用FPGA可以实现成像声纳的实时信号处理[4-6]。
因为需要在FPGA中存储大量的波束加权数据,所以芯片内部Block RAM的数量是选择芯片的一个重要因素。对工作速度和芯片本身的各种资源、成本等方面进行权衡,选择Virtex-6系列的vc6vlx130t来实现本系统。
1 近场聚焦多波束形成
成像声纳往往工作在近场,在近场范围内,声波近似为球面波,指向性是距离的函数,所以必须作近场聚焦进行校正[7-11]。本文采用所有波束都聚焦的方法,提前计算好聚焦在不同距离的补偿相位并存储在存储器中,以供波束形成时调用。
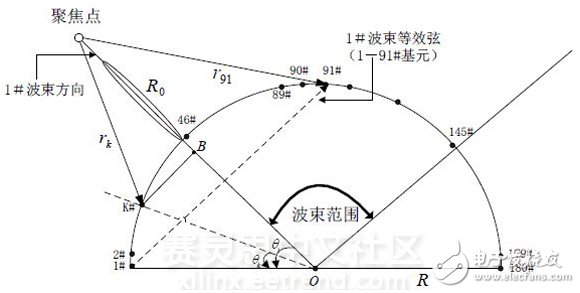
图1 近场聚集多波束形成示意图


根据系统需要,焦面位置可以有多个,焦面位置的多少并不影响运算速度,只是消耗的ROM资源稍多。为了降低存储需求,应在不降低性能的条件下尽可能减少聚焦面个数。本文中,在允许主瓣方向有0.001°误差、旁瓣电平小于-14dB和主瓣宽度不大于1°的情况下需要7个聚焦面就能完成近场(r<18m)范围的波束形成,聚焦距离从1米到18米(1米以内为盲区,不考虑),焦面之间的距离不是均匀的,而是随着声源距离的增加而增加。
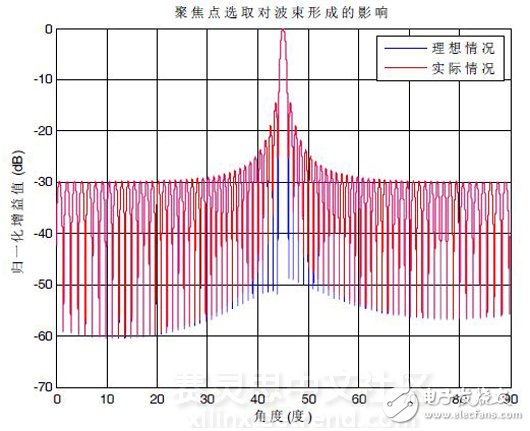
图2 聚集波束形成的1#波束方向图
以基阵所处位置为圆心,目标所处位置用(距离,方位)来表示。假设声源位于(1m,45°),选取不同聚焦面对波束形成的影响如图5所示,其中蓝线为理想情况下,采用与实际所处位置相同的聚焦距离(1.1m)进行聚焦时的1#波束方向图,其波束指向为45°,主瓣宽度为0.9010°,旁瓣电平为-14.47dB。红线为声纳系统实际工作情况下,按照上述8个聚焦面对实际距离进行近似选取,采用1.05m聚焦时的1#波束方向图。两种情况下的波束方向图吻合得很好,因此虽然只取了7个聚焦面做近场波束形成,但对波束形成的效果影响不大,却可以大大提高系统资源的利用效率。
2 多波束形成的FPGA 实现
因为数字多波束形成需要处理大量数据,且对处理速度有很高的要求,但计算结构相对简单,很适合利用FPGA实现多通道并行处理,同时兼顾速度和灵活性。
数字多波束形成(DBF)主要完成复数乘法和复数加法运算,每路输入信号为经过下变频后输出的基带I/Q 分量。采用91个阵元的单波束DBF要完成实数的364个乘法和363个加法运算,而在FPGA里影响计算速度和资源消耗的主要是乘法器。若仅采用并行处理方法,产生540个波束需要540×91×4=196560个乘法器,需要消耗大量的乘法器资源,在一片FPGA上实现不了。另一方面,单通道数据输入波束形成器的速度为30KHz,而FPGA的芯片处理速度通常可达几百兆,因此可以利用FPGA的高速性能,充分利用乘法器资源,通过时分复用乘法器(TDM)实现多通道数据多系数乘法运算。采用90个波束91个系数共用一个乘法器,实现8190倍复用,产生540个波束所需乘法器的数量减少到24,如表1所示。
表1 资源利用率与速度关系

数字多波束形成分为6个模块,每个模块采用同一组加权系数产生90个波束,如图3所示:
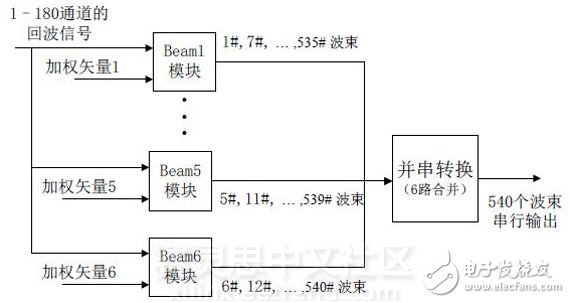
图3 DBF整体功能框图
Beam1-beam6模块功能相同,唯一的区别是输入加权矢量数据不同,因此以beam1模块为例说明其FPGA实现过程。基于FPGA 的多波束形成器由存储模块、控制模块、乘法累加模块等几部分实现,系统的组成结构框图如图4所示。
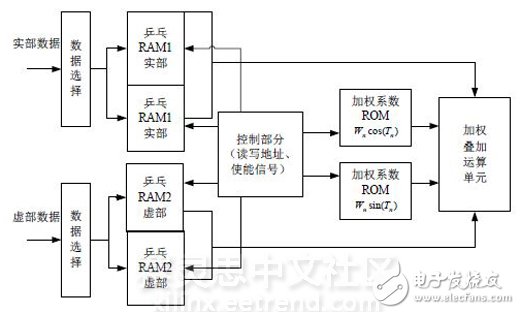
图4 波束形成FPGA实现功能模块
2.1 存储模块
前端处理后的数据采用乒乓操作实现数据不间断的写入和输出,实部数据和虚部数据使用独立的双端口RAM存储,如图4中所示实部RAM1和虚部RAM2。因为需要缓冲的数据为180通道上的16 bit数据, 所以乒乓RAM 的容量应为所需要缓冲数据的2倍,即16×180×2×2 =11.25 Kbit。

乒乓RAM的读顺序比较特殊:为了加速和节约乘法器资源,用4个实数乘法器来实现90个波束91个系数的复用,所以读时钟是写时钟的90×91/180=45.5倍。读顺序如下:读取0-99地址单元的信号数据用于产生1#波束,然后读取1-100地址单元的信号数据用于产生7#波束,…,读取88-187地址单元的信号数据用于产生529#波束,最后读取89-188地址单元的信号数据用于产生535#波束。读完这些数据之后正好下一时刻的信号数据已写入180-359地址单元,此时在上述读地址的基础上加180后,读取数据用于产生下一时刻的540个波束数据,依次循环往复。
片内ROM存储波束加权系数矢量,6个波束形成模块使用各自的系数ROM。其读时钟与乒乓RAM相同,读地址相对比较简单,重复地址0-90,根据数据点位置 确定该调用哪个聚焦面的加权系数矢量。
2.2 控制模块
控制模块产生读写地址信号和控制信号,对乒乓RAM和系数ROM的读写地址的控制按照上文所述内容设计;控制信号部分主要是产生控制运算部分和存储部分的运行使能控制信号。
2.3 运算模块
信号数据与对应的加权数据读取出之后以270M的速率串行进入乘法累加模块。其中复数相乘是其中最重要的运算操作。假设第 接收通道的信号表示为:

首先,1-91通道的数据串行进入乘法累加器,进行91次复乘和90次复加之后,得到一个包含实部和虚部的波束数据;之后,2-92通道的数据进入乘法累加器,得到第二个波束数据。如此,形成90个波束,只需要一个复数乘法器,即4个实数乘法器。
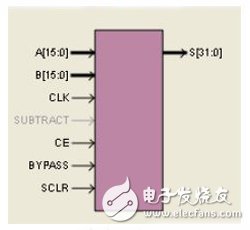
图5 乘法累加器IP核
乘法累加采用Xilinx的IP核实现,如图5所示,其中各个参数的含义如表2所示。
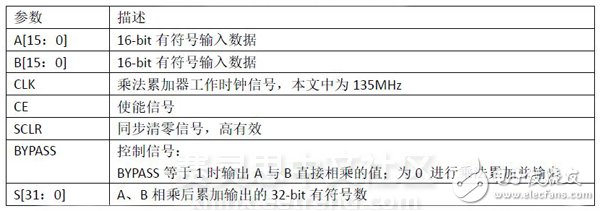
表2 乘法累加IP核各参数含义
通过控制BYPASS信号来控制乘法累加过程:当滤波后数据和加权系数有效时,使BYPASS维持一个周期的高电平后变为低电平,计数100周期后再次变为高电平,开始下一个波束数据的计算,因此bypass的周期为1.35MHz。

图6 波束形成模块波形图
如图6所示,波束数据输出速率为2.7MHz,对应着单个波束输出速率为30KHz,计算结果与MATLAB仿真结果一致。各个波束实部和虚部输出后,通过乘法运算得到波束的模平方。
3 验证结果
信号从基阵90°方向射向基元,1#基元至180#基元接收到信号,通过基元与波束点的延迟,得到各基元处的信号。180个基元的信号同时采集,一个周期采集4个点,采集到的数据作为标准信号源。系统设计时,将标准信号源数据存在信号处理单元。系统运行过程中,如果信号处理单元接收到使用标准信号源的命令,就读出标准信号源数据进行滤波抽取和多波束形成运算。将系统的波束输出结果与MATLAB仿真结果对比,可检测系统是否工作正常。
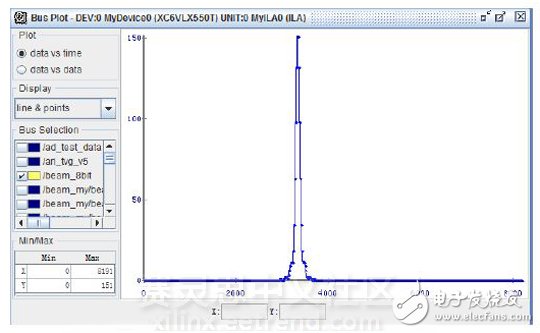
图7 Chipscope验证标准信号源测试
图7所示为Chipcsope采集到的采用标准信号源测试时某个时刻的540个波束的波束值,具有良好的指向性。
图8 标准信号源测试图像
图8所示为实际系统采用标准信号源测试,将波束数据通过千兆网上传至PC机得到的显示图像,为90°方向上的一条亮条纹。
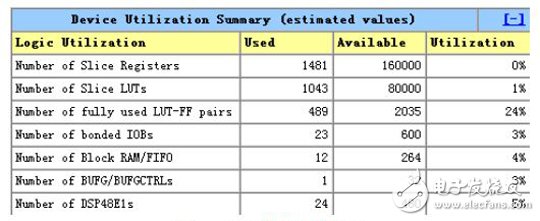
图9 FPGA资源利用率
本文提出的改进算法只需要6组加权系数矢量即可产生540个波束,有效降低了对存储资源的要求。通过乒乓操作实现了不间断的数据输入输出,以及流水并行处理,能够实现实时处理。通过多通道多系数复用技术,将乘法器资源使用量降低到24个,大大节省了FPGA的硬件资源。数字多波束形成所使用的FPGA资源如图9所示,其仅仅使用了整个芯片资源的一小部分,为成像声纳系统其余模块的实现提供了很大的空间。
结语
本文提出一种利用FPGA实现高速多通道的多波束形成方法。通过乒乓操作、流水并行处理提高速度;通过多通道多系数复用乘法器和模块复用技术,仅采用24个乘法器完成180通道数据的540个波束实时产生,有效降低了FPGA资源利用量,适用于工程上实现多波束形成系统。
- 相关推荐
- F
-
数字波束形成相控阵中射频电子的物理尺寸分配2018-12-13 0
-
怎么设计基于FPGA多波束成像的声纳系统?2019-10-09 0
-
基于FPGA器件和LVDS技术设计的高速实时波束形成器2020-11-25 0
-
相控阵雷达数字波束形成的实现2010-08-05 727
-
Rotman透镜多波束形成网络的数值分析2009-10-21 2852
-
基于FPGA的成像声纳FFT波束形成器设计2011-09-19 1097
-
基于FPGA圆阵超声自适应波束形成的设计2012-05-15 950
-
基于FPGA的数字波束形成技术的工程实现2012-05-25 3551
-
基于DSP和FPGA的多频声纳采集系统设计_刘寅2017-03-19 580
-
基于FPGA的多波束成像声纳整机硬件威廉希尔官方网站 设计方案解析2017-11-09 761
-
基于FPGA多波束成像的声纳系统设计2017-11-18 4136
-
基于声纳探测技术的水下三维场景实时成像系统2017-11-18 15388
-
采用FPGA器件和LVDS技术实现高速实时波束形成器的设计2020-08-17 2666
-
什么是波束形成?波束形成的类型2023-05-16 1622
-
基于FPGA的B超全数字波束形成技术2023-11-09 238
全部0条评论

快来发表一下你的评论吧 !
