

HLS:lab3 采用了优化设计解决方案
FPGA/ASIC技术
描述
本实验练习使用的设计是实验1并对它进行优化。
步骤1:创建新项目
1.打开Vivado HLS 命令提示符
a.在windows系统中,采用Start>All Programs>Xilinx Design Tools>Vivado2014.2>Vivado HLS>Vivado HLS 2014.2 Command Prompt
b. 在linux系统下,打开新的shell
2.变更到lab3路径:cdc:\Vivado_HLS_Tutorial\Introduction\lab3.
3.在命令提示符窗口中,键入:vivado_hls -f run_hls.tcl建立工程
4.在命令提示符窗口中,键入:vivado_hls -p fir_prj在vivado用户界面打开工程,Vivado HLS打开,如下图所示。方案1的综合已经完成
如前面所述,本设计的目标是:
?为这个设计创建一个的最高吞吐量的版本
?最终的设计应该能够处理一个伴随输入有效信号的输入数据。
?伴随着一个输出有效信号的输出数据。
?为了FIR设计,此滤波器系数存储在外部的一个单端口的ram中。
步骤2:优化I/O接口
因为设计规范中包含了I/O协议,所以首先你对创建正确的I/O协议和端口执行优化。I/O协议类型的选择可能会影响设计优化的可能性。如果有I / O协议的规定,应在设计周期的早期设置I/O协议。
在lab1中,查看一下设计中的I/O协议,您可以通过导航找到在solution1\syn文件夹下的报告文件夹中综合报告,可以重看一遍综合报告,会发现I/O要求是:
?端口C必须有一个单端口的RAM访问
?端口X必须有一个指示输入数据是有效的信号
?端口Y必须有一个指示输出数据是有效的信号
(重看了综合报告,看见了Interface里面x,y,c等RTL 端口,但是这样的具体要求不知道在什么地方体现出来,就是I/O协议方面的要求,应该是下面红色的圈起来的)
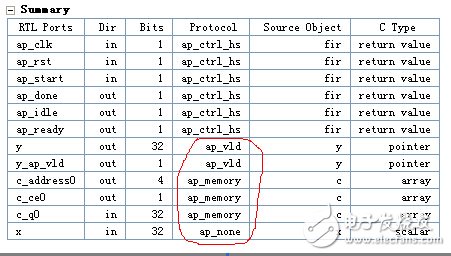
端口C已经是一个单端口RAM的访问。但是,如果你没有明确指定的RAM访问类型,高层次综合可能会使用双端口接口的RAM。HLS如果为了创建一个具有更高的吞吐量设计可以这样做。如果要求是单端口的,你应该明确地添加要求到设计的I / O协议中,要求使用单端口RAM。
输入端口x在默认情况下是一个简单的32位数据口。您可以通过指定的I / O协议ap_vld实现它与相关的数据有效信号的输入数据端口。
输出Y口已经有一个相关联的输出有效信号。这是默认的指针参数。你没有对这个端口指定明确的端口协议,因此就按照默认要求去实现,但如果要求了,那就按照要求去实现。
为了保存已经存在的结果,创建一个新的解决方案,命名为solution2
1. 点击New Solution工具栏按钮,创建一个新的解决方案
2. 保存默认的solution2名字,不要更改任何技术或时钟设定
3. 点击完成
创建solution2,并将其设置为默认的解决方案 - 确认solution2是在资源管理器窗格中突出显示,表示它是当前的解决方案。
要添加优化指令来定义所需的I / O接口的解决方案,请执行以下步骤。
4. 在资源管理器窗口中,打开Source包含项(见图22)
5. 双击fir.c ,在信息窗口中打开文件
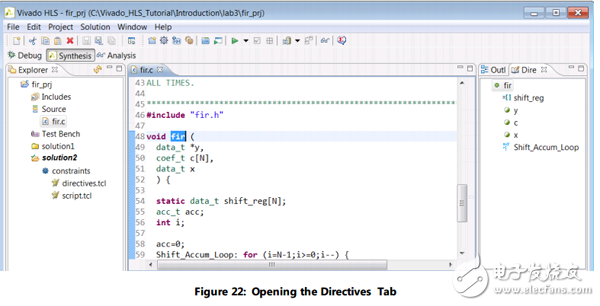
6. 激活辅助窗格中的指令选项卡(Directives tab),选择顶层函数中fir跳转到源代码视图中fir函数的顶部(图22)。
指令选项卡在图22右边展示,列出了在设计中的所有可以被优化的对象。在指令选项卡中,你可以为设计添加优化指令。只有当源代码是在信息窗格中打开时您才可以查看指令选项卡。
7. 在指令选项卡中,选择C的参数/端口(绿点)。
8. 右击并选择插入指令(Insert Directives)
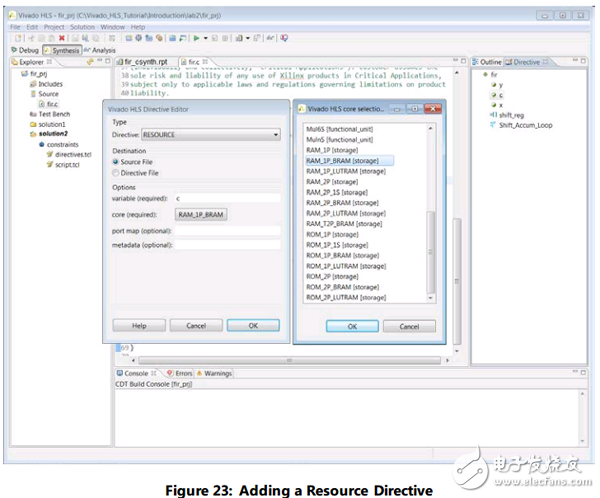
9. 实现单端口ram接口须按以下操作
a. 从该指令的下拉菜单中选择源(RESOURCE)(为什么要选择RESOURCE,这个下拉框中其他选项有什么意义,在什么情况下用,有待研究)
b. 点击core框
c. 选择RAM_1P_BRAM, 如图23所示(这个下拉菜单中也有很多选项,每个选项在什么情况下用有待研究,不知道从什么地方可以找到相关资料)
上述步骤指定数组c是使用单端口块RAM资源来实现。由于数组c是函数的参数列表,因此是函数之外。自动创建一组数据端口来访问单端口RAM块的RTL实现之外。
由于I / O协议是不可能改变的,你可以将这些指令优化添加到源代码里,作为编译指示,以确保正确的I/ O协议嵌入到设计中。
10. 在指令编辑器(Directive Editor)中的Destination中选择源文件(source file)。
11. 要应用指令,单击OK。
提示:如果你想改变任何指令的目的,就在指令选项卡中的指令双击并修改目标。
12. 接下来,指定端口X要有相关的有效信号/端口
a. 在指令选项卡中,选择输入端口x(绿色点)
b. 右击,并选择Insert Directives
c. 从指令编译下拉菜单中选择接口(Interface )
d. 从对话框的Destination中选择Source File
e. 在mode中选择ap_vld模式
f. 单击OK应用指令
13. 最后,明确指定端口Y,有一个相关联的有效信号/端口。
a. 在指令(Directive)选项卡中,选择输入端口y(绿色点)
b. 右击,并选择Insert Directives
c. 从指令编译下拉菜单中选择接口(Interface )
d. 从对话框的Destination中选择Source File
e. 选择ap_vld的模式
f. 单击确定应用指令
完成后,验证源代码和指令选项卡,如图24所示。对任何不正确的指令,用鼠标右键单击要修改它。

14. 点击Run C Synthesis 工具栏按钮,并综合设计
15. 出现提示时,单击Yes保存在C源文件中的内容。添加指令作为编译指示修改源代码。
当综合完成后,报告文件会自动打开。
16. 单击多级选项卡,查看接口的结果,或者干脆向下滚动到报告文件的底部。
图25展示了拥有正确I/O协议的端口

步骤3:分析结果
在优化设计前,最重要的是理解当前的设计,结果显示:在实验1中如何使用综合报告来理解实现功能,然而,分析视窗提供一个互动式的方式更加详细。
任然以solution2为例,在图26所示

1. 点击分析按钮(Analysis perspective button)
2. 点击Shift_Accum_Loop在性能(Performance)窗口中进行打开
?在图26中红色虚线的使用说明;它不是视图的一部分
?本教程的设计分析(Design Analysis)提供了更全面的对分析观点理解,但下面解释了什么要求可以从源代码中创建面积最小,速度最快的RTL设计。
?性能窗格视图左栏显示的RTL层级在此模块中的操作。
?最上面一行列出了设计中的控制状态。控制状态是指高层次综合的内部状态使用的计划表操作成时钟周期。RTL有限状态机(FSM)的控制状态和最终状态之间有密切的关系,但并不是一对一的映射。
这里给出的解释如下红色虚线在图26的路径,某些对象的位置直接相关的C源代码。用鼠标右键单击该对象交叉引用的C代码。
?设计开始时,在第一状态下读取端口x
?在下一状态中,开始执行由for循环Shift_Accum_Loop创建的逻辑。循环显示为黄色,你可以展开或折叠它们。握住鼠标移到该视图中的黄体循环显示循环细节:8个周期,11次迭代,总的延迟为88周期。
?在第一状态中,循环迭代计数检查:添加,比较,和退出潜在的循环。
?在操作由数组综合成的块RAM时,读取内存要花费两个周期。(一个周期产生地址,一个周期读取数据)
?把从C端口读取的数据放到memory里
?乘法运算需要3个周期来完成。
?一个for循环需要执行11次
?在最后一次迭代结束时,在状态C1退出循环并向端口Y写入数据。您还可以使用分析器来分析在设计中使用的资源。
3. 点击Resource,如图27
4. 打开所有的资源组如图27

图27展示了:
?x和y是I/O端口。在报告中可以看出端口c在memory部分,因为c是内存接口。
?在设计中用到了两个乘法器
?在memory shift_reg中进行了读写操作
?没有其它资源被共享,因为在每行或每个时钟周期内每次仅操作一个实例。
有敏锐的洞察力,通过分析得到,可以继续进行优化设计。
?在结束之前的分析,这是值得评论的多周期乘法运算,这需要多个DSP48s实现。源代码使用int数据类型。这是一个32位的数据类型,它导致大的乘法器。一个DSP48乘数是18位的,它需要多个DSP48s乘法器来实现数据宽度大于18位的乘法。
本教程任意精度类型显示了如何创建一个硬件更合适的数据类型的设计。使用任意精度的类型,可以定义任意位大小的数据类型。(超过标准的C / C+ +8位,16位,32位或64位的数据类型)。
步骤4:优化最高吞吐量(最低间隔)
在本设计中有两个问题限制了吞吐量,主要有:
?for循环。默认情况下,循环保持rolled:循环体的一个副本被综合和用于每次迭代中。这确保了在循环的每次迭代中被顺序地执行。你可以展开for循环,让所有操作并行发生。
?块RAM用于shift_reg。因为变量shift_reg在C源代码中是数组,综合实现的是为一个默认的RAM块。然而,这可以防止其实现为移位寄存器。因此,您应分区此块内存到单个寄存器。
开始创建一个新的解决方案
1. 点击New Solution按钮
2. 保存解决方案的名称为solution3
3. 点击Finish来创建新的解决方案
4. 在工程菜单(project)中,选择Close Inactive Solution Tabs 来关闭先前解决方案中的打开的标签页。
以下步骤,图28中概述解释了展开循环体

5. 在指令选项卡中选择循环Shift_Accum_Loop.(提醒:源代码必须在信息窗格中打开,就会看到在指令标签的所有代码对象)
6. 右击并选择Insert Directives
7. 在指令下拉菜单中选择Unroll, 保留目标作为优化文件。
当优化设计时,必须经常进行多次迭代的优化,确定最终应该优化的。通过添加优化指令文件,可以保证它们不会自动结转到下一个解决方案。
存储解决方案中指令文件的优化,让不同的解决方案有不同的优化。已添加的优化代码中的编译指示,他们会自动结转到新的解决方案,你将不得不修改代码回去,然后重新运行以前的解决方案。
保留其他选项的指令窗口选中空白,以确保循环完全展开。
8. 点击OK应用指令
9. 应用指令把数组分割成单个元素
a. 在在指令选项卡中,选择数组shift_reg
b. 右击,并选择Insert Directives
c. 从指令下拉菜单中选择Array_Partition
d. 在type(optional)中选择complete
e. 点击OK应用指令
嵌入在solution2代码中的指令和增加的两个新指令,solution3的指令窗格出现如图29所示。
在图29中,注意,在solution2里应用的指令对编译的指示相比较那些刚刚应用并保存到指令文件的指令有不同的注解。您可以在Tcl文件中查看新增加的指令。

10. 在资源管理窗口,展开Solution3中的Constraint文件夹,如图30
11. 双击solution3directives.tcl文件,并在信息窗口中打开

12. 点击Synthesis工具栏按钮,综合设计。当综合完成,综合报告自动打开
13. 比较不同方案的结果
14. 点击Compare Reports工具栏按钮。或者用Project>Compare Reports
15. 添加solution1、solution2、solution3进行比较
16. 点击OK
图31示出的报告进行比较。solution3具有最小的启动间隔和可以更快处理数据。作为间隔仅为16,它开始处理一个新的输入集需要16个时钟周期。

能够在此设计执行额外的优化。例如,您可以使用流水线操作,以进一步提高吞吐量和降低的时间间隔。本教程的设计优化提供了有关使用流水线来提高间隔的细节。
正如前面提到的,你可以修改代码本身使用任意精度的类型。例如,如果数据类型是不要求为32位int类型,可以使用位精确类型(例如,6位,14位或22位的类型),只要它们满足所要求的精度。有关使用任意精度类型的更多详细信息,请参阅教程任意精度类型。
结论
在本教程中,您学习了如何:
?创建的GUI和Tcl的环境中Vivado高层次综合项目。
?执行中的HLS设计流程的主要步骤。
?创建和使用一个Tcl文件运行VivadoHLS。
?创建新的解决方案,加上优化的指令,并比较不同解决方案的结果。
- 相关推荐
-
新思科技Synphony HLS解决方案2018-07-19 1662
-
优化 FPGA HLS 设计2024-08-16 0
-
请问如何在MOTORWARE LAB中添加一个新的C文件2018-09-13 0
-
怎么利用Synphony HLS为ASIC和FPGA架构生成最优化RTL代码?2019-08-13 0
-
如何查看lab3脚本2021-01-01 0
-
如何优化AR解决方案?2021-06-02 0
-
HLS高阶综合的定义与解决办法2021-07-10 0
-
Vivado HLS设计流的相关资料分享2021-11-11 0
-
Synopsys天宣布推出其Synphony HLS (Hi2009-11-04 1199
-
Altera功能安全锁步解决方案采用了FPGA、SoC,认证工具流程2018-08-31 1486
-
采用Zynq SDR套件的DDS HLS IP2018-11-30 3319
-
探索Vivado HLS设计流,Vivado HLS高层次综合设计2020-12-21 3614
-
PYNQ上手笔记 | ⑤采用Vivado HLS进行高层次综合设计2021-11-06 505
-
如何利用HLS功能创建图像处理解决方案2022-05-13 3603
-
关于HLS IP无法编译解决方案2023-07-07 782
全部0条评论

快来发表一下你的评论吧 !
