

基于FPGA器件实现CNN加速系统的硬件设计
可编程逻辑
描述
引言
随着近些年深度学习的迅速发展和广泛的应用,卷积神经网络(CNN)已经成为检测和识别领域最好的方法,它可以自动地从数据集中学习提取特征,而且网络层数越多,提取的特征越有全局性。通过局部连接和权值共享可以提高模型的泛化能力,大幅度提高了识别分类的精度。并且随着物联网的发展,部署嵌入式端的卷积神经网络要处理大量的数据,这将会消耗大量的资源与能量,而嵌入式设备通常用电池维持工作,频繁更换电池将会提高成本,因此对于推断阶段的运算加速以及低功耗设计有重要实际意义。
CNN的不同卷积核的运算之间是相互独立的,而且全连接层的矩阵乘法不同行之间也是独立的,因此神经网络的推断在CPU平台上串行计算的方式是非常低效的。GPU可以通过流处理器实现一定的并行性,但是缺乏对于网络并行结构的深度探索,不是最优的方案。而基于FPGA的神经网络可以更好地实现网络并行计算与资源复用,因此本文采用FPGA加速卷积神经网络运算。
此前已有一些基于FPGA的卷积神经网络加速器,WANG D设计了流水线卷积计算内核;宋宇鲲等人针对激活函数进行设计优化;王昆等人通过ARM+FPGA软硬件协同设计的异构系统加速神经网络;张榜通过双缓冲技术与流水线技术对卷积优化。本文针对卷积神经网络的并行性以及数据与权值的稀疏性,对卷积层和全连接层进行优化,根据卷积核的独立性设计单指令多数据(Single Instruction Multiple Data,SIMD)的卷积与流水线结构,提高计算速度与资源效率,利用全连接层数据极大的稀疏性,设计稀疏矩阵乘法器减少计算冗余,然后对模型参数定点优化,最后将实验结果与CPU、GPU平台以及基准设计进行比较分析。
1 、CNN模型与网络参数
1.1 CNN模型
CNN是基于多层感知机的神经网络结构,典型的CNN模型由输入层、卷积层、全连接层、输出层和分类层组成,如图1所示。由输入层读取图像数据,由卷积层通过多个卷积核分别和输入图卷积生成多个特征图,再由池化层降维提取特征图信息。经过几个卷积层后,再将特征图展开成向量,输入给全连接层,经过全连接层与输出层的矩阵运算得到输出,然后再通过Softmax分类层得到分类概率输出。
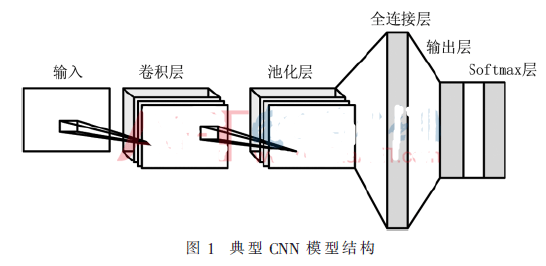
本文CNN模型结构如图2所示,该结构包含两个卷积层、两个池化层、一个全连接层,一个输出层、一个使用Softmax的分类层,其中激活函数不算作一层,共7层的网络结构。其中两个卷积层的输出特征图个数分别为16、32,卷积核大小为3×3,移动步长为1,输出尺寸与输入相同,系统使用线性修正单元(Rectified Linear Units,ReLU)作为激活函数。全连接层和输出层分别有1 024和40个神经元。由图2计算得权值与偏置的数量,本文模型共4 765 416个参数,其中全连接层占了99%的参数。

由于分类层是用输出层的值通过Softmax函数求得每个分类的概率,而Softmax函数的运算消耗大量的运算资源,而且对结果没有影响,这是不必要的运算开销,因此用输出值来判别即可。
1.2 CNN网络参数
根据所选的网络结构,本文使用TensorFlow框架搭建模型,学习率设置为0.000 1,使用自适应学习率优化算法Adam加速模型收敛,训练选择ReLU激活函数增加模型参数的稀疏性,使用交叉熵作为损失函数,加入L2正则化项减小过拟合。训练了50轮后,模型在ORL人脸数据库的正确率达到95%,满足实际应用需要。
神经网络模型推断降低一定的精度不会影响准确率,而且在FPGA上定点数比起浮点数的计算更有效率,所以将模型参数由32 bit浮点数量化为16 bit定点数,由深度压缩[6]中的方法,将16 bit的定点数权值再用8 bit的索引表示,索引表的值共28=256个,然后通过反向传播算法[7]更新索引表后,将索引和索引表存在外部存储器中。
2、 CNN系统硬件设计
本系统针对CNN模型结构以及数据与参数的特点进行设计和优化,卷积同一层内不同特征图的计算有天然的并行性,不同层之间因为不是独立的,无法同时进行计算,而全连接层和输出层都可以使用卷积层的PE来完成乘法运算。系统设计如图3所示。

首先通过控制器从外部存储器DDR3中读取图像数据到输入缓冲区,输入缓冲区通过移位寄存器设计,通过固定窗口读取数据。读取权值索引到权值缓冲区,然后由索引读取权值输入给卷积的处理单元(Processing Element,PE),经过每层的卷积后加上偏置,用ReLU函数激活,再经过池化操作降维,然后特征图经过非零检测模块统计稀疏性,读取对应的非零神经元的权值,然后由稀疏矩阵乘法器(Sparse Matrix-Vector Multiplication,SPMV)完成矩阵乘法,加上偏置后输出给输出层。输出层复用卷积层的PE完成矩阵乘法,然后遍历输出值求出最大值对应的神经元序号即为预测值。
2.1 卷积层硬件设计优化
如图4所示,卷积层采用移位寄存器作为输入缓存,本文卷积层的卷积核尺寸为3×3,每次读取9个权值,使用9个定点小数乘法器,然后使用4层加法树结构将结果与偏置相加。然后通过ReLU函数激活,该函数表达式为y=max(0,x),因此只要判断输入数据的符号位即可,使用一个数据选择器即可完成运算,消耗一个时钟。第一层卷积的不同卷积核是独立计算的,所以使用16个PE同时计算,然后通过流水线技术,可以在一个时钟周期内产生16个卷积输出,输出数据的延迟包括读取数据延迟和加法树的延迟。
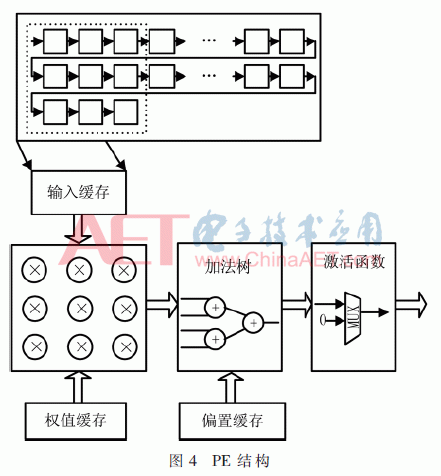
2.2 池化层设计优化
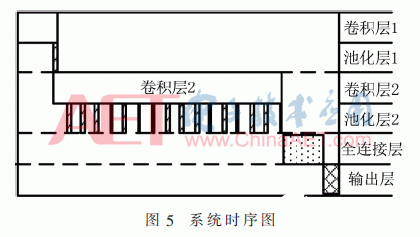
池化层用于对输入特征图降低维度和提取信息,池化分为平均值池化和最大值池化,本文使用最大值池化,池化尺寸为2×2,步长为2。池化层使用比较器得到最大值,经过两次比较得到结果。经研究发现,池化操作不影响卷积操作,因此设计了池化与卷积的并行计算,如图5所示。并行操作节省了池化运算的时间,加快了网络的计算速度。
2.3 全连接层与输出层的设计与优化
2.3.1 全连接层
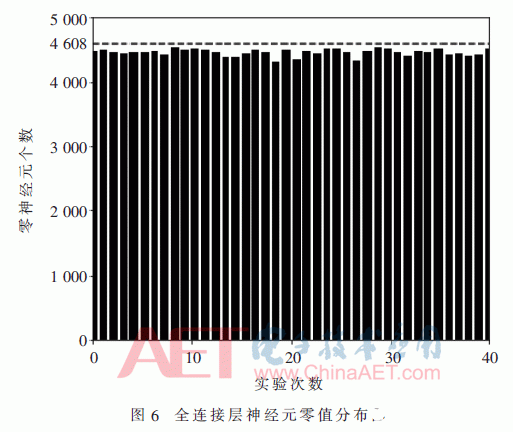
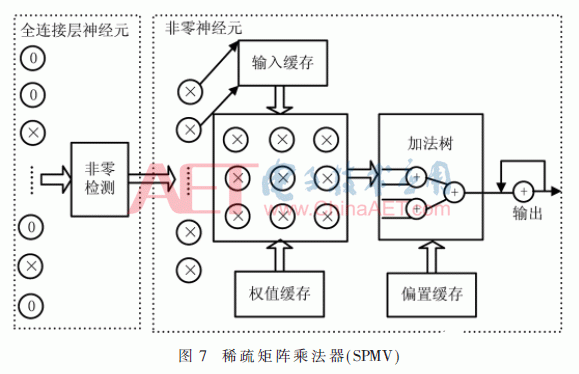
全连接层将所有输入特征图和输出向量相连接,每个神经元的值由卷积层特征图加权求和得到。本文多次实验发现全连接层有大量为零的神经元,如图6所示。因此可以利用神经元的稀疏性减少乘法的操作,设计如图7所示稀疏矩阵乘法器。首先通过非零元检测模块,得到不为零的神经元,然后复用卷积层的PE来计算非零神经元与权值的乘加操作。这样可以重复利用运算资源,并大大降低运算的时间复杂度,提高运算速度。
2.3.2 输出层
输出层对全连接层神经元做矩阵运算,然后通过Softmax层得到所有分类的概率。但是由于Softmax函数含有指数运算,需要消耗大量运算资源和时间,而且对结果没有影响,因此将Softmax层移除,直接使用输出层值的大小来分类。本文多次实验发现输出层没有稀疏性,大部分神经元不为零,输出层的计算复用SPMV的第二个部分进行计算,由PE与串行加法器组成,分别计算输出层的40个分类的值,40个运算单元共用一路数据输入,采用滑动窗口读取数据,多路PE同时计算,由串行加法器输出结果。最后遍历求得输出值最大值,并输出分类结果。
3、 数据量化与模型压缩
本文模型使用了两个卷积层、一个全连接层、一个输出层的结构,使用参数量由前文所述有476万参数,而全连接层又占了99%的参数,因此主要针对全连接层进行数据压缩。对于所有层的参数进行数据量化,从原本模型64 bit浮点数量化为16 bit定点数,然后用8 bit的索引,共256个共享的权值,然后通过反向传播算法[7]修正原始权值与共享权值的差值。压缩率公式如下:

其中,n为参数量,b为量化的比特数,k为b bit能表示的类数(256类)。式(1)代入数据求得压缩率大约为4倍。
4 、实验结果
系统设计使用Xilinx公司的ZYNQ-7000 xc7z020clg400-1芯片作为实验平台,该芯片内部有85 000个逻辑单元、4.9 MB的Block RAM、220个DSP48单元、1 GB片外DRAM,满足本系统所需。CPU平台使用Core i5 9400f,主频为2.9 GHz,GPU平台使用GTX 1060,GPU主频为1.5 GHz,显存带宽为160 GB/s。将实验结果与CPU、GPU平台以及基准设计[5]对比,资源使用情况如表1所示,实验结果如表2所示。


本文硬件平台的工作频率为100 MHz,识别每张图片时间为0.27 ms,功耗为1.95 W,性能达到了27.74 GOPS/s,分别是CPU、GPU平台的10.24倍、3.08倍,以及基准设计的1.56倍,能效比优于CPU、GPU平台以及基准设计[5]。在数据量化为16 bit定点数之后,识别率达到95%,没有造成精度损失。
5、结论
本文设计了一种基于FPGA的卷积神经网络加速系统。首先使用ORL人脸数据库,在卷积神经网络模型LeNet-5上训练,然后用短定点数对神经网络进行量化,再使用索引与索引表的方式进一步压缩模型的全连接层,最终压缩率达到了4倍。同时,从并行结构设计、流水线技术、时序合并等方式增加系统并行性,通过对模型稀疏性的利用,极大地加速了模型运算。本文使用的CNN模型压缩方法和利用稀疏性加速的方法理论上也适用于其他的硬件平台,在嵌入式终端部署更具有优势。在与CPU、GPU平台以及相关文献的设计的对比分析后,本文设计在性能和能耗比上都优于此前的方案。
责任编辑:gt
-
基于 FPGA 的目标检测网络加速威廉希尔官方网站 设计2023-06-20 0
-
基于FPGA的深度学习CNN加速器设计方案2023-06-14 2290
-
TF之CNN:CNN实现mnist数据集预测2018-12-19 0
-
【PYNQ-Z2申请】图像目标识别FPGA硬件加速2019-01-09 0
-
如何移植一个CNN神经网络到FPGA中?2020-11-26 0
-
基于FPGA的软硬件协同仿真加速技术2014-03-25 5344
-
Bitfusion支持通过云访问基于赛灵思All Programmable器件的FPGA硬件加速功能2017-02-08 297
-
基于FPGA的通用CNN加速设计2017-10-27 10165
-
简单快捷地用小型Xiliinx FPGA加速卷积神经网络CNN2018-06-29 4829
-
KORTIQ公司推出了一款Xilinx FPGA的CNN加速器IP——AIScale2018-01-09 10110
-
想要实现FPGA的CNN加速 需要考虑以下内容2019-02-14 1337
-
FPGA学习教程之硬件设计基本概念2020-12-25 996
-
电子学报第七期《一种可配置的CNN协加速器的FPGA实现方法》2021-11-18 638
-
基于FPGA的CNN加速项目案例解析2022-08-02 2876
-
如何采用带专用CNN加速器的AI微控制器实现CNN的硬件转换2023-05-16 798
全部0条评论

快来发表一下你的评论吧 !
