

基于Xilinx Virtex-II FPGA的硬件哈希算法的研究分析
可编程逻辑
描述
1、 引言
信息检索是自动识别和分类文字信息的过程,它的目的是从文档中提取出与用户请求相关的信息 。文档的基本单位是词,词在文档里出现的次数(以下称之为频率)是衡量词本身重要性的一个指标 。而词在一条语句里的出现次数(以下称之为密度)则决定了这条语句的重要性。所以说语句的重要性由构成语句的词的出现频率以及该词在语句里的密度这两个因素决定。基于这种逻辑我们可以使用关键词的频率和密度来标示文档里的重要语句,从而将文档内容进行分类,避免语言学里复杂的语法和句法分析,同时还能得到相对准确的结果。在实际操作中,出现频率极高和极低的词将被忽略,因为这些词往往与文档的内容关系不大。通过去除一些预定义的高频词和同义词将显著降低信息检索的工作量,之后得到的关键词列表则可以用来识别重要的语句。这些语句很有可能包含了和文档内容最密切相关的信息,所以这些语句将被用来与用户输入的请求作比较,作为检索结果返回给用户。这种信息检索方法的核心是计算每个关键词在文档里的出现次数,并根据各个词的重要性对词列表进行排序。本文第二部分将介绍一种硬件哈希算法来加速关键词的计数工作,而排序则将作为后续工作进行研究。
2 、方法描述
在计算关键词在文档里出现次数的过程中,需要一种存储结构来存储相关信息,这种存储结构必须易于执行查找、插入及删除操作。哈希是一种以常数平均时间执行查找、插入和删除操作的算法。在计算关键词在文档里的出现次数时应用哈希算法可以大大降低查找次数 。理想的哈希表数据结构是一个包含有关键字的具有固定大小的数组。一般情况下一个关键字就是带有相关值(关键词及其在文档里的出现次数)的字符串。假设哈希表的大小为TableSize,则每个关键字被映射到从0到TableSize-1这个范围内的某个数,并且被存放到对应的存储空间。这个映射称之为哈希函数,理想情况下哈希函数应该计算简单并且应该保证两个不同的关键字映射到不同的单元,不过由于单元的数目是有限的,而关键字一般情况下是远远大于单元数目的,所以两个关键字有可能哈希到同一个单元,这种情况称之为冲突。因此我们需要寻找一个哈希函数,该函数要在单元之间均匀的分配关键字,尽可能的将冲突发生的概率降到最低。
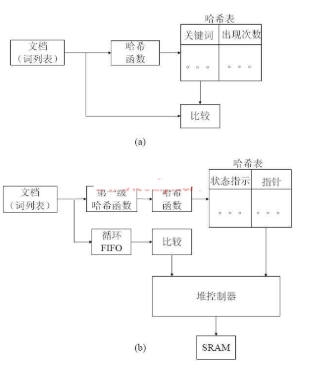
图1 硬件哈希结构
如图1(a)所示,首先将文档转换为一个关键词的列表,之后这个列表将通过哈希函数映射到哈希表数据结构中。每个关键词都将通过哈希函数映射到哈希表中的一个单元,如果该单元已经有内容,则比较该内容与输入的关键词是否相同,相同则“出现次数”增加一次;不同则为冲突,冲突解决方案将在后面介绍;如果该单元没有内容则说明输入的关键词是第一次出现,则将该关键词存储在这个单元,“出现次数”计为一次。哈希函数通过FPGA硬件来实现,为了有效利用FPGA的硬件资源,选用按位异或并与素数相乘的哈希算法。在实际操作中这个算法将被用来作为第一级的哈希函数,产生初始哈希表地址,因为关键词是一个可变长度的字符串,不能直接存储在哈希表里,取而代之的是一个指针(如图1(b)所示)。这个指针指向存储器堆里的一块存储区,关键词及其出现次数存储在这块存储区内。为了标示指针指向的存储区是否有内容,哈希表中除了存储指针之外还需要存储指针指向的存储区的状态。这些工作由一个硬件堆存储控制器来管理 。输入的关键词首先通过第一级哈希函数映射到哈希表中的状态指示和指针,如果状态指示为有内容,则通过指针得到其指向的存储内容,与输入关键词比较,相同则“出现次数”增加一次,不同则通过冲突解决方案处理;如果状态指示为无内容,则说明输入的关键词是第一次出现,该关键词将被存储到这块存储区,“出现次数”计为一次。为了将比较运算的时间降到最小,数据宽度需要尽可能宽一些,从而允许多个字符的比较并行完成。
冲突解决方案的实质是将发生冲突的数据存储在一个保留区域。通常的冲突解决方案分为两种:链表法和开放寻址法。链表法将所有映射到同一地址的关键字放在一个动态分配的链表里。由于给链表里新的关键字分配空间需要时间,从而导致这种方案的速度相对较慢,而且算法实际上还需要实现另一种数据结构(链表),因此并不适合在信息检索里使用。本文采用的是开放寻址法来解决冲突。开放寻址法的数据和保留区域在一个表里,使用伪随机探测法,允许每个循环产生一个新的探测地址。开放寻址法的一个缺点在于当哈希表里的条目增加的时候冲突的次数和搜索路径的长度也随着增加,从而导致平均检索时间的增加。因此,它的性能由表密度而不是列表长度决定,而表的大小则依赖于应用数据和期望的性能。
3、 硬件实现及实验结果
本文的硬件结构基于Xilinx Virtex-II FPGA,其最高频率为127.47MHz,FPGA资源利用率为392/5120 = 7.6%。文档存储使用1片128M x 72位的SDRAM,哈希表存储使用2片1M x 36位的ZBT(零总线翻转)SRAM。本文第二部分描述的算法通过一个5级流水线 来实现,如图2所示。每级需要的时钟周期的数目在图2(a)中给出,其中N为搜索关键字的字符数,括号内为至少需要的时钟周期数目。为了最优化性能,3个主流水线是重叠的,如图2(b)所示。

图2 处理过程流水线
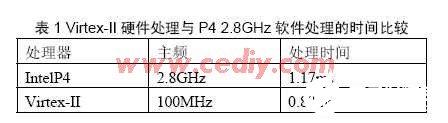
将这种结构的性能与软件实现做一下比较,比较结果见表1,使用的测试数据集是一样的。
4、 结论
本文描述了一种基于FPGA的硬件哈希算法,该算法用来加速信息检索过程中的关键词计数工作,实验结果表明,使用FPGA硬件哈希算法在提高信息检索速度方面明显优于高主频处理器上的软件实现。
本文作者创新点:本文通过使用关键词出现的频率和密度来标示文档里的重要语句,从而将文档内容进行分类,避免了语言学里复杂的语法和句法分析。同时利用FPGA技术提高了信息检索的速度,得到了比较满意的结果。
责任编辑:gt
-
Xilinx公司产品导购手册2012-02-28 0
-
Xilinx FPGA:Virtex-II基本架构2012-08-02 0
-
转:xilinx FPGA设计都用到哪些第三方EDA工具?2013-03-14 0
-
XC2V1000-4FGG456C XILINX Virtex-II™ 系列介绍2013-09-06 0
-
Virtex-II 配置回读问题2015-10-24 0
-
利用Xilinx FPGA进行片上设计验证2019-07-31 0
-
哪里可以获得USB和PCI驱动器xilinx xtreme DSP开发套件virtex-II pro?2019-11-06 0
-
Virtex-II ProTM FPGA的主要特性是什么? 它有哪些功能?2021-05-06 0
-
用PowerPC860实现FPGA 配置2009-04-16 283
-
Virtex-II系列应用指南2010-06-11 725
-
基于Xilinx FPGA的双输出DC/DC转换器解决方案2012-02-03 737
-
NBP7_Xilinx_Virtex-II_BGA456_Rev1.102016-02-17 534
-
NBP8_Xilinx_Virtex-II_Pro_BGA4562016-02-17 565
-
基于Virtex-II ProTM平台FPGA产品可解决与嵌入式系统设计相关的挑战2017-11-24 1361
-
基于FPGA的Poseidon哈希算法硬件加速方案2022-08-19 2816
全部0条评论

快来发表一下你的评论吧 !
