

GDDR6给FPGA带来的大带宽存储优势以及性能测试
可编程逻辑
描述
作者:黄仑,Achronix高级应用工程师
1. 概述
随着互联网时代的到来,人类所产生的数据发生了前所未有的、爆炸性的增长。IDC预测,全球数据总量将从2019年的45ZB增长到2025年的175ZB[1]。同时,全球数据中近30%将需要实时处理,因而带来了对FPGA等硬件数据处理加速器的需求。如图1所示。
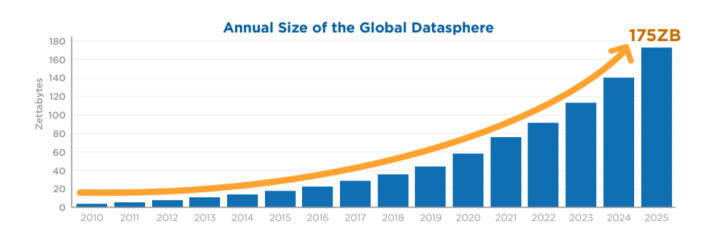
图1 全球数据增长预测
在这样的数据高速增长的情况下,用于传输数据的网络带宽和处理数据所需要的算力也必须急速增长。传统的CPU已经越来越不堪重负,所以用硬件加速来减轻CPU的负担是满足未来性能需求的重要发展方向。未来的硬件发展需求对于用于加速的硬件平台提出了越来越高的要求,可以概括为三个方面:算力、数据传输带宽和存储器带宽。
Achronix的新一代采用台积电7nm工艺的Speedster 7t FPGA芯片根据未来硬件加速和网络加速的需求,在这三个方面都做了优化,消除了传统FPGA的瓶颈。下面我们重点说一说为了提高存储器带宽,Achronix通过采用硬核GDDR6控制器所带来的优势。
2. GDDR6的发展
在GDDR的设计之初,其定位是针对图形显示卡所特别优化的一种DDR内存。因为2000年后电脑游戏特别是3D游戏的发展和火爆,使运行电脑游戏的显卡需要有大量的高速图像数据交互需求,GDDR在这种情况下应运而生。第一个GDDR标准是基于DDR的GDDR2,随后发展到了基于DDR3的GDDR5,在一段时间中非常流行。
2016年,GDDR5X正式发布,它引入了具有16n预取的四倍数据速率模式,但代价是访问粒度从GDDR5的32Byte提高到了64Byte。2018年,GDDR6发布,数据速率达到了16Gbps,带宽几乎是GDDR5X的两倍,同时采用了双通道设计,访问粒度和GDDR5一样是32Byte。
3. GDDR6 和 DDR4/5的比较
GDDR一直以来是针对图形显示卡所优化的一种DDR内存。因为显卡处理图像数据,特别是3D图像数据对显存带宽的要求更高,GPU和GDDR之间的数据交换非常频繁。而DDR内存专注于与CPU进行数据交换的效率,因此对于整体存取性能、低延迟更为看重,所以在CPU和传统的FPGA中基本都是用DDR4。
随着硬件加速需求对于存储器的带宽提出了越来越高的要求,传统的DDR4带宽显然已经无法满足要求,Achronix看重了GDDR6在数据存储中的带宽优势,创新地将GDDR6引入到了FPGA,彻底解决了传统FPGA存储带宽不够的瓶颈。
2020年7月15日,JEDEC存储协会正式发布了DDR5 SDRAM的标准(JESD79-5),内存的频率相对DDR4的标准频率有了大幅的提升,总传输带宽也提升了38%,但是还是和GDDR6的带宽有一定的差距。如图2所示[2],GDDR6和DDR4/5的带宽对比。
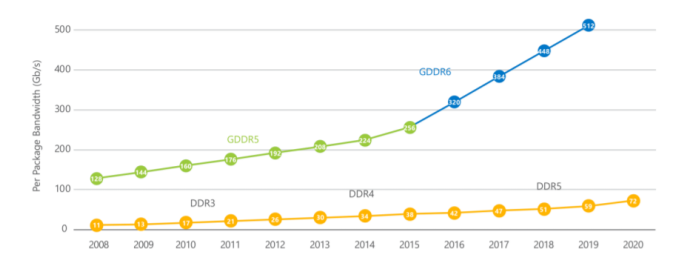
图2 GDDR与DDR带宽发展对比
如果实现同一个大带宽存储的应用,在提供相同的存储器带宽的情况下,无论在设计复杂度,PCB占用面积,还是在功耗方面,与DDR4相比,GDDR6的性能都有很大的提高,如图3所示[2]。

图3 GDDR6和DDR4性能对比
4. GDDR6 和 HBM2的比较
HBM全称High Bandwidth Memory,最初的标准是由JEDEC在2013年发布。2016年1月,HBM的第二代HBM2正式成为工业标准。HBM的出现也是为了解决存储器带宽问题。与GDDR6不同的是,HBM内存一般是由4个或者8个HBM的Die堆叠形成,我们称之为一个Stack。如图4所示[4]。
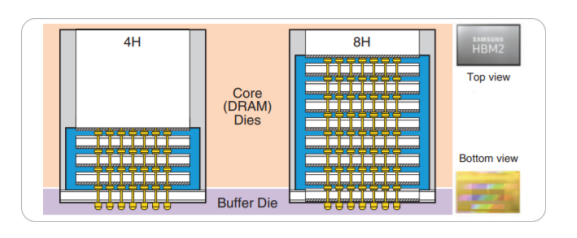
图4 HBM Die的堆叠
我们以市面上带有HBM2的高端 FPGA为例,这个系列的FPGA集成了1~2个这样的HBM2 Stack。两个Stack之间是相互独立的,各自有自己的地址空间。每个Die都有独立的两个128bit的Channel,所以4个Die 8个通道就是1024bit的位宽,HBM2的频率是900MHz,按DDR的方式访问,一个Stack总共带宽是 900(MHz)x 2(DDR)x 1024(位宽)/8 = 230GB/s,两个Stack最高可以到460GB/s的带宽。
Achronix的Speedster 7t FPGA集成了8个GDDR6的硬核,每个GDDR6的硬核支持双通道。总的带宽是 16Gbps x 16(位宽)x 2(通道)x 8(控制器)/8 = 512 GB/s,略高于带HBM2的FPGA存储器带宽。
从成本上来看,目前GDDR6与HBM2相比有着很大的优势,HBM2技术工艺要求高,目前芯片的良率和产量都会受到很大的影响。同时GDDR6使用起来更灵活,使用片外的DRAM,可以根据应用要求,选择不同速率,不同容量的GDDR6颗粒。HBM2的优势在于集成度高,不占用PCB板的面积。图5是DDR4、GDDR6和HBM2在成本上的一个综合比较。
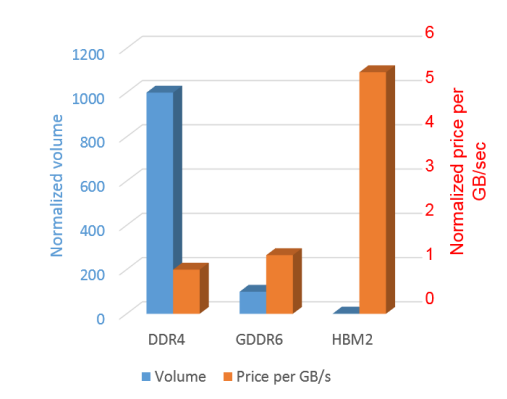
图5 DDR4 vs GDDR6 vs HBM2
5. GDDR6 技术细节以及Clamshell模式
GDDR6结构如图6所示[3]。它是采用16n Prefetch结构,一次写操作或者读操作的数据是16n。每个GDDR6颗粒有两个独立的通道,每个独立的通道访问独立的内存空间。对于每个通道,读或者写的位宽是256bit或者32Byte。P-to-S converter是一个并变串的转换器,把每个256bit位宽的数据转换成16位总线,每位总线上传输16bit的数据。这样GDDR6每个通道最小的访问粒度是256bit或者32Byte。
根据GDDR6这样16n 预取结构,内部存储阵列如果访问周期是1ns,则I/O上的数据率则是16Gbps。
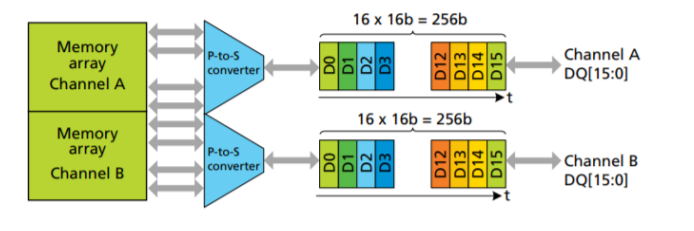
图6 GDDR6颗粒结构
一个GDDR6控制器支持两个独立通道,一个GDDR6颗粒也是两个独立的通道,所以在通常模式下,一个GDDR6控制器对应一个GDDR6的颗粒,用x16模式,实现最高512Gb/s的带宽。
因为目前市面上GDDR6颗粒的最大容量是16Gb,在有些应用中如果对容量有一定的要求,可以使用一种叫Clamshell的连接方式,如图7[5]所示,每个GDDR6控制器连接两个GDDR6颗粒,每个GDDR6的颗粒用x8模式,这样在这种Clamshell模式下,带宽不变,但是支持的GDDR6的容量翻倍了。
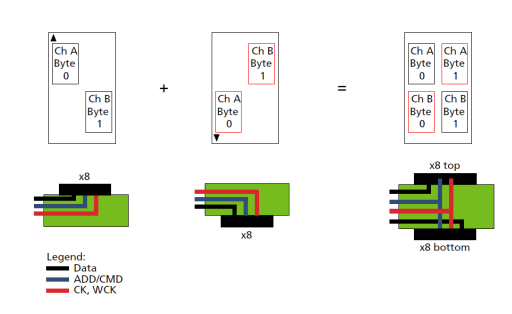
图7 GDDR6的Clamshell模式
6. GDDR6 在7t1500上的读写效率
最后,我们测试一下7t1500上GDDR6控制器的读写效率,所有的测试结果基于仿真数据。测试环境如图8所示。因为7t1500包含了片上网络(NoC),并且NoC已经实现了仲裁,时钟域转换的逻辑,我们用三个用户逻辑通过NoC去访问同一个GDDR6 Channel,得到的综合读写效率更能反映用户实际运用中的场景。
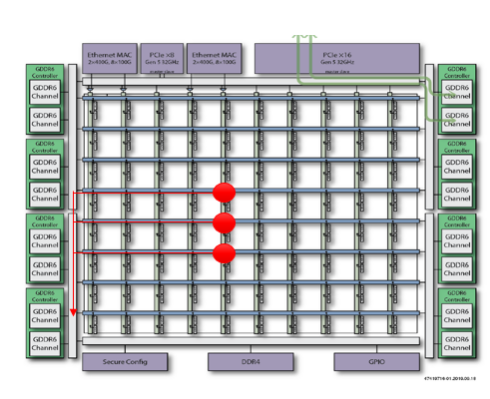
图8 GDDR6读写效率测试架构
在不同的突发长度和不同的地址访问方式下的测试结果如图9所示。
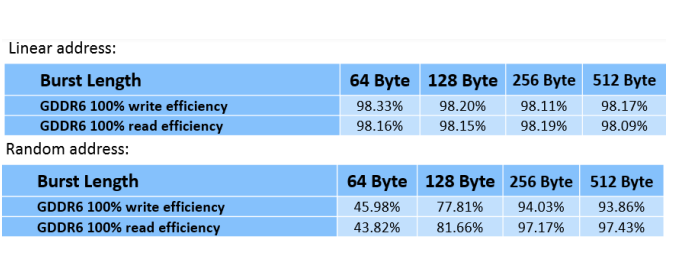
图9 GDDR6读写效率
后面我们会继续深入了解Speedster 7t FPGA芯片上的一些特性,以及这些特性如何运用在数据加速和网络加速中,敬请期待。 如需更多信息或者有任何疑问您可以通过Achronix公众号里的联系方式联系我们,也可访问Achronix公司官方网站 http://www.achronix.com
如果需要进一步联络Achronix中国区技术和产品应用团队,请发送邮件到:dawson.guo@achronix.com
参考文献:
1.The Digitization of the World From Edge to Core 2018
2.Extending the Benefits of GDDR Beyond Graphics by Micron
3.TN-ED-03: GDDR6: The Next-Generation Graphics DRAM Memory Array Prefetch and Access Granularity
4.Samsung网站:www.samsung.com
5.Micron网站:www.micron.com
6.Achronix网站:www.achronix.com
-
如何缓解GDDR6 DRAM实施所带来的挑战2021-01-01 0
-
美光已完成12Gbps /14Gbps GDDR6认证 计划2018年量产2017-12-25 1660
-
美光推出新 GDDR6 显卡存储器,与三星/海力士竞争2018-06-14 1396
-
美光宣布量产GDDR6存储器,与三星一较高下2018-06-27 4275
-
Micron和Achronix提供下一代FPGA并借助高性能GDDR6存储器支持机器学习应用2018-11-28 352
-
Achronix Speedster7t FPGA如何运用GDDR6满足网络产品的高带宽需求2020-02-17 1653
-
GTX 1650 GDDR6和GTX 1650 GDDR5区别在哪里2020-08-18 21645
-
紫光国芯宣布推出12nm工艺的GDDR6存储控制器和物理接口IP2020-11-19 2277
-
探究GDDR6给FPGA带来的大带宽存储优势以及性能测试(上)2021-12-03 5806
-
探究GDDR6给FPGA带来的大带宽存储优势以及性能测试(下)2021-12-03 6263
-
Rambus通过业界领先的24Gb/s GDDR6 PHY提升AI性能2023-05-17 462
-
Rambus推出提升GDDR6内存接口性能的Rambus GDDR62023-05-17 829
-
缓解AI推理算力焦虑,高带宽GDDR6成杀手锏?2023-06-02 600
全部0条评论

快来发表一下你的评论吧 !
