

自然语言和ChatGPT的大模型调教攻略
人工智能
描述
你是否想过,为什么ChatGPT能够如此火爆呢?我认为这主要是因为ChatGPT提供了好玩、有用的对话式交互功能,能够为用户提供帮助,而不仅仅是依靠“大”模型的魅力。毕竟,GPT-3在2020年就已经推出了,拥有175B的参数规模,但除了最初的热度之外,它并没有引起社会太多的关注。
那么,究竟是什么让ChatGPT能够生成相对客观且富有信息量的回答呢?研究者们基于预训练好的大规模语言模型,采用了多种调教手段,主要包括指令调整和基于人类反馈的对齐调整。这些调整手段的运用,使得ChatGPT的交互表现更为出色。本文基于人民大学团队一篇的综述论文,给大家简要介绍一下大模型的调教攻略。
指令调整
指令调整(Instruction Tuning)将多种任务转化成自然语言表述的形式,再通过seq2seq的监督学习+多任务学习的方式调整大规模语言模型的参数。经验表明,指令调整可以让大模型更好地执行指令,并提高跨任务与跨语言的泛化能力,并且可以缓解大模型输出重复内容以及补全输入而非完成任务的问题。
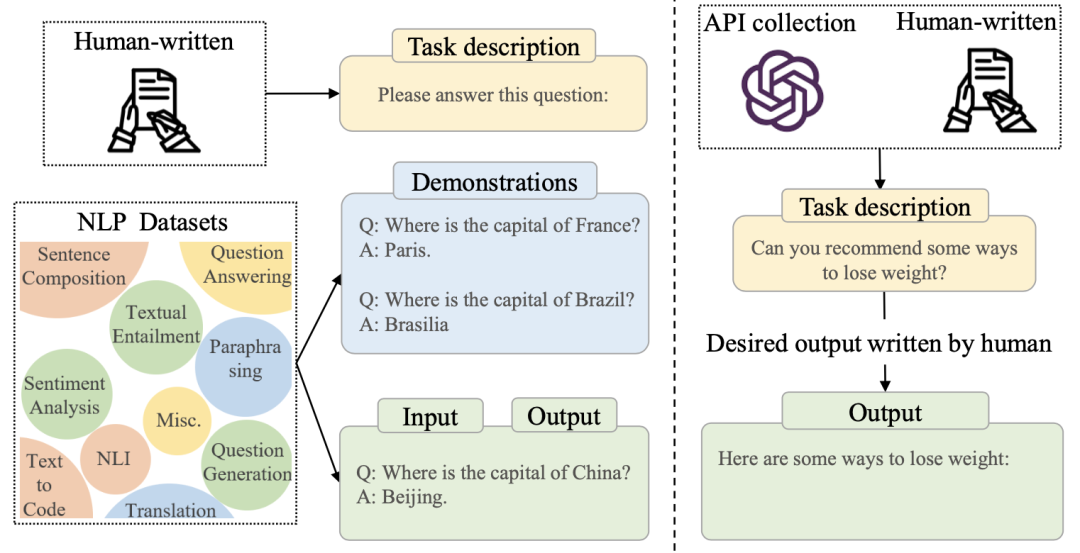
上图展示了指令精调的数据样例,通常包括一个任务描述,一组可选的展示样例,以及一组输入输出。模型在训练时,利用输出内容,进行监督学习训练。
指令调整的数据主要有两个来源。一为上图左侧,根据现有的数据集进行改写构建。其中,主要涉及通过众包平台构建不同的任务描述,有些工作用启发式模板构建数据,还有工作提出通过颠倒输入输出的方式扩充数据。
第二个来源为上图右侧,基于人类需求构建指令调整数据。InstructGPT提出利用人类在OpenAI API中输入的数据作为任务描述,以提高指令的多样性,更好满足真实需求。过程中涉及收集用户query,让标注者再计一些query,让标注者写出query的回复作为训练目标。GPT-4还额外构建高风险query来让模型学习“拒绝回复”。第二类数据在后面的对齐调整中也用到了。
在指令调整过程中,任务的数量和多样性对跨任务泛化能力很重要。多样性可以体现在长度、结构、创造性等多个方面。而每个任务所需的样本无需过多。
引入展示样本可以提高模型表现,降低模型对指令表述过度的敏感其他的prompt内容会带来负面影响。在展示样本中,包含类似代数运算等思维链(Chain of Thought)的内容可以有效提升模型多步推理能力,对其他任务也有好处。
指令调整中需要注意任务间的样本数量均衡问题,不能简单地按照任务数据集规模合并。增加高质量数据集的采样比例可以提升表现。不过,一般单一数据集样本量会设置一个上限,一般在几千到几万的范围。
OPT-IML提出在指令调整中引入部分预训练样本作为正则,来提高稳定性;GLM-130B 和 Galactica 在语言模型训练过程中引入了少许指令调整数据。
对齐调整
语言模型预训练预指令调整主要是提高模型建模语言,完成特定任务的能力。然而,对于ChatGPT这类“对话产品”而言,还需要通过对齐调整(Alignment Tuning)来让模型同人类的价值观对齐,从而生成“更令人满意”的回复内容。
对齐调整的主要动机是,有害的、误导的和有偏见的表述会严重影响人们主观的评价。即使这种调整客观上会损害大模型的能力,但可以极大地提升用户体验。大体上有三个需要调整的方向:
1.有帮助的:模型生成的内容应当是简介有执行力的,能够提供额外的信息并展现出模型的敏感、审慎和洞察力。2.忠诚的:模型不应该捏造事实,并且适当地时候表达不确定性。3.无害的:模型避免生成冒犯的、歧视性的内容,并且拒绝一些恶意请求。
用于对齐调整的标注数据有多种形式,例如排序若干候选;成对比较;回答既定的问题以从多个角度评价等。GPT-4还利用了基于自身的零监督分类器。
而在标注者质量筛选方面,除了母语、学历、标注平台(如AMT)上等级之外,研究者还利用标注者之间的内在一致性、标注者与研究者的标注一致性等信息来对标注者做筛选。
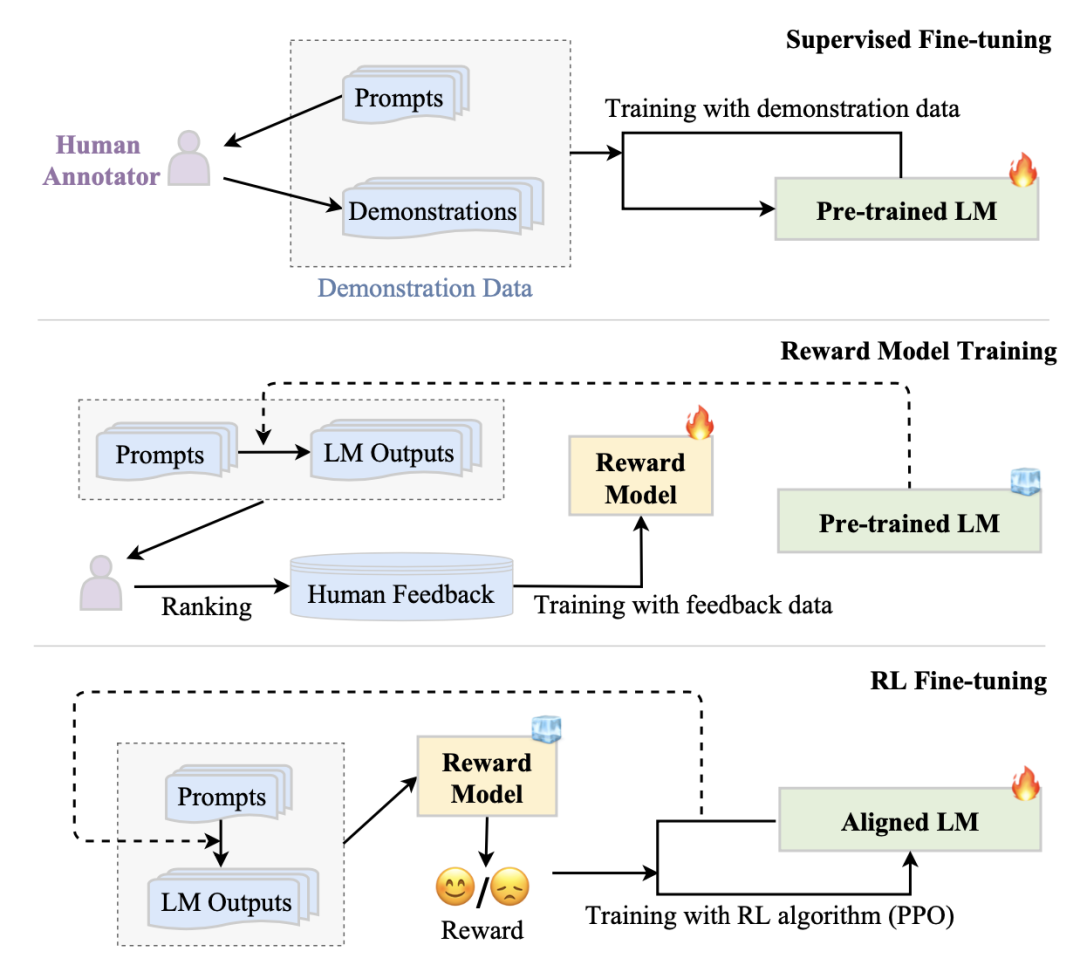
基于人类反馈的强化学习算法(RLHF)利用标注数据,基于强化学习PPO(Proximal Policy Optimization),调整大模型。上图显示了RLHF进行对齐调整的过程,具体包含三个步骤:
第一步是基于人类标注数据做有监督精调。这一步和指令调整差不多,不过用的数据都是人类标注的,内容也更自由一些,比如开放式问答,闲聊,头脑风暴,改写等。这一步并非必须,可以认为是针对强化学习的冷启动问题的预热。
第二步是基于人类反馈训练一个奖励模型(Reward Model)。比如InstructGPT中基于标注数据训练了一个排序模型。奖励模型将在第三部强化学习中提供反馈信号。奖励模型一般是一个较小的大语言模型,例如InstructGPT基于175B参数的GPT-3做调整,奖励模型采用6B的GPT3;GopherCite基于280B参数的Gopher做调整,奖励模型采用7B的Gopher。
第三步是强化学习优化的过程。待优化的大语言模型的动作域(action space)是预测词表,状态为当前生成的内容,并将奖励模型的反馈信号通过PPO算法传给大语言模型做优化。对了避免强化学习跑偏,InstructGPT还采用了优化后的模型与原模型生成内容的KL距离作为正则项。
结束语
虽然从头训练一个大模型可能对绝大多数研究者而言是一种奢望,但在现有的开源资料基础之上,对特定的任务或领域进行调教个人专属的大模型并非遥不可及。
编辑:黄飞
-
关于自然语言处理之54 语言模型(自适应)2020-04-09 0
-
python自然语言2018-05-02 0
-
自然语言处理怎么最快入门?2018-11-28 0
-
【推荐体验】腾讯云自然语言处理2019-10-09 0
-
自然语言处理的语言模型2020-04-16 0
-
自然语言处理——总结、习题2020-06-19 0
-
什么是自然语言处理2021-09-08 0
-
深度视频自然语言描述方法2017-12-04 845
-
自然语言处理常用模型解析2017-12-28 5885
-
自然语言处理怎么最快入门_自然语言处理知识了解2017-12-28 5311
-
基于深度学习的自然语言处理对抗样本模型2021-04-20 812
-
基于人工智能的自然语言处理模型GPT-3技术解析2023-03-02 5513
-
ChatGPT在自然语言处理中的局限性和挑战2023-04-18 1413
-
自然语言处理的概念和应用 自然语言处理属于人工智能吗2023-08-23 1596
-
自然语言处理与机器学习的关系 自然语言处理的基本概念及步骤2024-12-05 464
全部0条评论

快来发表一下你的评论吧 !
