

人工智能之神经网络新思路:OpenAI用线性非线性问题
人工智能
描述
神经网络通常由一个线性层和非线性函数(比如 tanh 和修正线性单元 ReLU)堆栈而成。如果没有非线性,理论上一连串的线性层和单一的线性层在数学上是等价的。因此浮点运算是非线性的,并足以训练深度网络。这很令人惊讶。
背景
计算机使用的数字并不是完美的数学对象,而是使用有限个比特的近似表示。浮点数通常被计算机用于表示数学对象。每一个浮点数由小数和指数的组合构成。在 IEEE 的 float32 标准中,小数分配了 23 个比特,指数分配了 8 个比特,还有一个比特是表示正负的符号位 sign。

按照这种惯例和二进制格式,以二进制表示的最小非零正常数是 1.0..0 x 2^-126,以下用 min 来指代。而下一个可表示的数是 1.0..01 x 2^-126,可以写作 min+0.0..01 x 2^-126。很显然,第一和第二个数之间的 gap 比 0 和 min 之间的 gap 小了 2^20 倍。在 float32 标准中,当一个数比最小的可表示数还小的时候,则该数字将被映射为零。因此,近邻零的所有包含浮点数的计算都将是非线性的。(而反常数是例外,它们在一些计算硬件上可能不可用。在我们的案例中通过设置归零(flush to zero,FTZ)解决这个问题,即将所有的反常数当成零。)
因此,虽然通常情况下,所有的数字和其浮点数表示之间的区别很小,但是在零附近会出现很大的 gap,而这个近似误差可能带来很大影响。
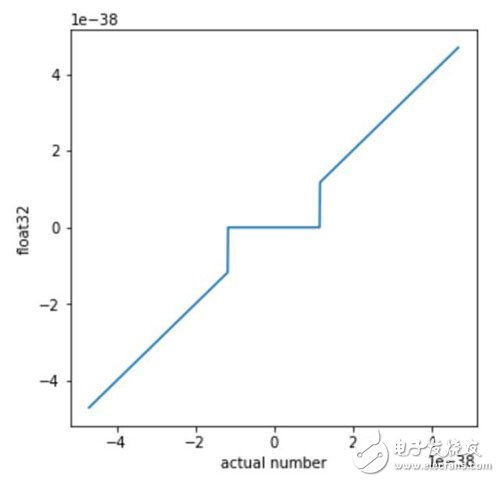
这会导致一些奇怪的影响,一些常用的数学规则无法发挥作用。比如,(a + b) x c 不等于 a x c + b x c。
比如,如果你设置 a = 0.4 x min,b = 0.5 x min,c = 1 / min。
则:(a+b) x c = (0.4 x min + 0.5 x min) x 1 / min = (0 + 0) x 1 / min = 0。
然而:(a x c) + (b x c) = 0.4 x min / min + 0.5 x min x 1 / min = 0.9。
再比如,我们可以设置 a = 2.5 x min,b = -1.6 x min,c = 1 x min。
则:(a+b) + c = (0) + 1 x min = min
然而:(b+c) + a = (0 x min) + 2.5 x min = 2.5 x min。
在这种小尺度的情况下,基础的加法运算变成非线性的了!
使用进化策略利用非线性
我们想知道这种内在非线性是否可以作为计算非线性的方法,如果可以,则深度线性网络能够执行非线性运算。挑战在于现代微分库在非线性尺度较小时会忽略它们。因此,使用反向传播利用非线性训练神经网络很困难或不可能。
我们可以使用进化策略(ES),无需依赖符号微分(symbolic differentiation)法就可以评估梯度。使用进化策略,我们可以将 float32 的零点邻域(near-zero)行为作为计算非线性的方法。深度线性网络通过反向传播在 MNIST 数据集上训练时,可获取 94% 的训练准确率和 92% 的测试准确率(机器之心使用三层全连接网络可获得 98.51% 的测试准确率)。相对而言,相同的线性网络使用进化策略训练可获取大于 99% 的训练准确率、96.7% 的测试准确率,确保激活值足够小而分布在 float32 的非线性区间内。训练性能的提升原因在于在 float32 表征中使用非线性的进化策略。这些强大的非线性允许任意层生成新的特征,这些特征是低级别特征的非线性组合。以下是网络结构:

在上面的代码中,我们可以看出该网络一共 4 层,第一层为 784(28*28)个输入神经元,这个数量必须和 MNIST 数据集中单张图片所包含像素点数相同。第二层与第三层都为隐藏层且每层有 512 个神经元,最后一层为输出的 10 个分类类别。其中每两层之间的全连接权重为服从正态分布的随机初始化值。nr_params 为加和所有参数的累乘。下面定义一个 get_logist() 函数,该函数的输入变量 par 应该可以是上面定义的 nr_params,因为定义添加偏置项的索引为 1、3、5,这个正好和前面定义的 nr_params 相符,但 OpenAI并没有给出该函数的调用过程。该函数第一个表达式计算第一层和第二层之间的前向传播结果,即计算输入 x 与 w1 之间的乘积再加上缩放后的偏置项(前面 b1、b2、b3 都定义为零向量)。后面两步的计算也基本相似,最后返回的 o 应该是图片识别的类别。不过 OpenAI 只给出了网络架构,而并没有给出优化方法和损失函数等内容。
-
应用人工神经网络模拟污水生物处理2009-08-08 0
-
人工智能到底用 GPU?还是用 FPGA?2017-08-23 0
-
【专辑精选】人工智能之神经网络教程与资料2019-05-07 0
-
人工神经网络实现方法有哪些?2019-08-01 0
-
如何采用神经网络技术,对镍铬-镍硅热电偶进行了非线性校正?2021-04-08 0
-
在人工智能神经网络ADC设计方面各位有什么见解呢?2021-06-24 0
-
基于BP神经网络的PID控制2021-09-07 0
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 0
-
基于神经网络的传感器非线性误差校正2009-06-29 588
-
人工神经网络的特点有哪些?2010-03-06 24614
-
基于小波神经网络的非线性噪声对消2012-05-07 867
-
GA_BP神经网络的非线性函数拟合_徐富强2017-03-19 1092
-
如何使用小波神经网络实现温度传感器非线性补偿的研究2020-03-27 980
-
人工神经网络和bp神经网络的区别2023-08-22 4512
-
神经网络辨识模型具有什么特点2024-07-11 470
全部0条评论

快来发表一下你的评论吧 !
