

深度学习入门课:你需要了解的十大框架和选型攻略
人工智能
描述
深度学习框架是帮助使用者进行深度学习的工具,它的出现降低了深度学习入门的门槛,你不需要从复杂的神经网络开始编代码,就可以根据需要使用现有的模型。
做个比喻,一套深度学习框架就像是一套积木,各个组件就是某个模型或算法的一部分,使用者可以自己设计和组装符合相关数据集需求的积木。
当然也正因如此,没有什么框架是完美的,就像一套积木里可能没有你需要的那一种积木,所以不同的框架适用的领域不完全一致。
深度学习的框架有很多,不同框架之间的“好与坏”却没有一个统一的标准,因此,当大家要开始一个深度学习项目时,在研究到底有哪些框架具有可用性,哪个框架更适合自己时,却找不到一个简明扼要的“说明书”告诉大家从何着手。
首先,我们先熟悉一下深度学习的框架。
Caffe
Caffe是最成熟的框架之一,由Berkeley Vision and Learning Center开发。它是模块化的,而且速度非常快,并且只需要很少的额外工作就可以支持多个GPU。它使用类似JSON的文本文件来描述网络架构以及求解器方法。
此外,在一个可以下载Caffe模型以及网络权重的网站——“model zoo”中,还可以帮助你快速地准备样本。但是,需要注意的是,在Caffe框架中,要调整超参数比其他框架更为繁琐,部分原因是需要为每组超参数单独定义不同的求解器和模型文件。
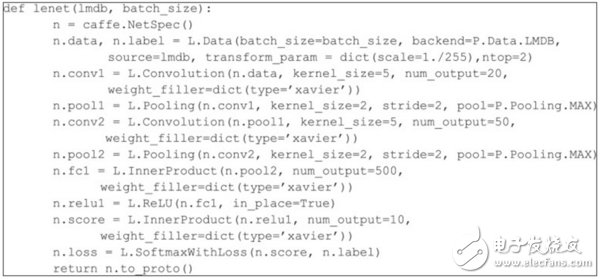
▲ 使用Caffe编写的LeNet CNN实现代码示例
上图是LeNet CNN架构的代码片段,该模型由卷积最大池化(convolution max pooling)和激活层组成的7层卷积网络构成。
Deeplearning4j
Deeplearning4j是由Andrej Karpathy开发的、支持GPU的多平台框架,它是用Java编写的,并拥有一个Scala API。Deeplearning4j也是一个成熟的框架(用Lua编写),在互联网上有许多可以使用的样本,并且支持多个GPU。
Tensorflow
Tensorflow是一个由谷歌开发的、相对比较新的框架,但已经被广泛采用。它性能良好,支持多个GPU和CPU。Tensorflow提供了调整网络和监控性能的工具,就像Tensorboard一样,它还有一个可用作网络应用程序的教育工具。
Theano
Theano是使用符号逻辑创建网络的框架,是以Python编写的,但利用了numpy的高效代码库,从而提高了性能,超过了标准的Python。Theano在构建网络方面有很大的优势,但是在创造完整的解决方案中则具有比较大的挑战。Theano将机器学习中使用的梯度计算作为网络创建的“免费”副产品,对于那些希望更多地关注网络架构而不是梯度计算的人来说,这可能是有用的。此外,它的文本文件质量也相当不错。
但需要提醒大家的一点是,Theano目前已停止更新。
Lasagne
Lasagne是用Python编写的,建立在Theano之上的框架。它是一个相对简单的系统,能够使得网络构建比直接使用Theano更容易。因此,其表现极大地反映了Theano的潜能。
Keras
Keras是用Python编写的框架,可以作为Theano或Tensorflow的后端(如下图)。这使得Keras在构建完整的解决方案中更容易,而且因为每一行代码都创建了一个网络层,所以它也更易于阅读。此外,Keras还拥有最先进算法(优化器(optimizers)、归一化例程(normalization routines)、激活函数(activation functions))的最佳选择。
需要说明的是,虽然Keras支持Theano和Tensorflow后端,但输入数据的维度假设是不同的,因此需要仔细的设计才能使代码支持两个后端工作。该项目有完备的文本文件,并提供了一系列针对各种问题的实例以及训练好了的、用于传输学习实现常用体系的结构模型。
在编写的时候,有消息宣称Tensorflow将采用Keras作为首选的高级包。其实,这并不奇怪,因为Keras的开发者Francois Chollet本身就是谷歌的软件工程师。

▲ 使用Keras编写的LeNet CNN实现代码示例
MXNet
MXNet是一个用C ++编写的深度学习框架,具有多种语言绑定,并支持分布式计算,包括多GPU。它提供对低级结构以及更高级/符号级API的访问。在性能上被认为可以与Tensorflow、Caffe等在内的其他框架匹敌。GitHub中提供了很多关于MXNet的教程和培训示例。
Cognitive Network Toolkit (CNTK)
CNTK是由微软开发的框架,并被描述为机器学习的“Visual Studio”。对于那些使用Visual Studio进行编程的人,这可能是一种更温和、更有效的进入深度学习的方式。
DIGITS
DIGITS是由英伟达开发的,一款基于网络的深层开发工具。在很多方面,它像Caffe一样,能够使用文本文件而不是编程语言来描述网络和参数。它具有网络可视化工具,因此文本文件中的错误更容易被识别出来。此外,它还具有用于可视化学习过程的工具,并支持多个GPU。
Torch
Torch是一款成熟的机器学习框架,是用C语言编写的。它具有完备的文本,并且可以根据具体需要进行调整。由于是用C语言编写的,所以Torch的性能非常好。
PyTorch
PyTorch是Torch计算引擎的python前端,不仅能够提供Torch的高性能,还能够对GPU的提供更好支持。该框架的开发者表示,PyTorch与Torch的区别在于它不仅仅是封装,而是进行了深度集成的框架,这使得PyTorc在网络构建方面具有更高的灵活性。(如下图)
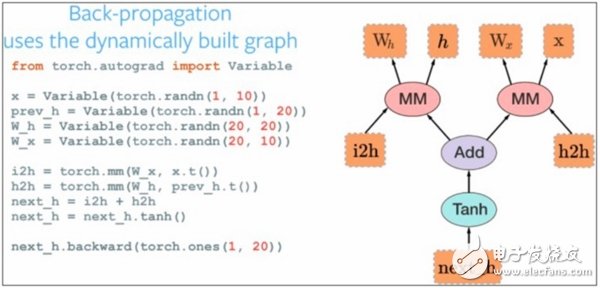
▲ PyTorch代码示例和等效方框图
Chainer
Chainer与其他框架有点不同,它将网络构建视为其计算的一部分。它的开发者介绍说,在这一框架中,大多数工具都是“定义然后运行”,这意味着你要定义架构,然后才能运行它。Chainer尝试构建并优化其架构,使其成为学习过程的一部分,或者称之为“通过运行定义”。
其他
除了上述的深度学习框架之外,还有更多的专注于具体任务的开源解决方案。例如,Nolearn专注于深度信念网络(deep belief networks); Sklearn-theano提供了一个与scikit-learn(即Python中一个重要的机器学习的库)匹配的编程语法,可以和Theano库配合使用;Paddle则可以提供更好的自然语言处理能力……
面对如此之多的深度学习框架,使用者该如何做出合适的选择?对此,LexiconAI的CEO兼创始人Matthew Rubashkin及其团队通过对不同的框架在计算机语言、教程(Tutorials)和训练样本、CNN建模能力、RNN建模能力、架构的易用性、速度、多GPU支持、Keras兼容性等方面的表现对比,总结出了以下图表:
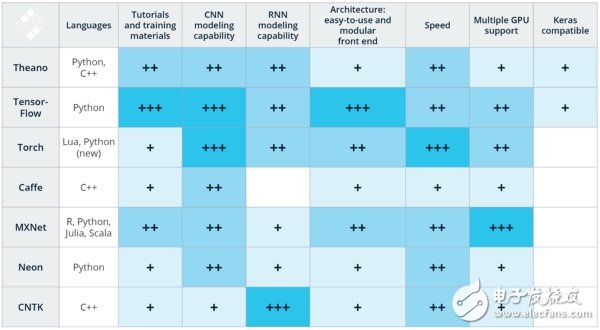
| Matthew Rubashkin毕业于加州大学伯克利分校,是UCSF的Insight数据工程研究员和博士生。曾在硅谷数据科学(SVDS)就职,并领导SVDS的深度学习研发团队进行项目研究,包括在IoT设备上的TensorFlow图像识别等等。
值得注意的是,这一结果结合了Matthew Rubashkin团队在图像和语音识别应用方面对这些技术的主观经验和公开的基准测试研究,并且只是阶段性检测,未囊括所有可用的深度学习框架。我们看到,包括DeepLearning4j、Paddle、Chainer等在内的框架都还未在其列。
以下是对应的评估依据:
计算机语言
编写框架所使用的计算机语言会影响到它的有效性。尽管许多框架具有绑定机制,允许使用者使用与编写框架不同的语言访问框架,但是编写框架所使用的语言也不可避免地在某种程度上影响后期开发的语言的灵活性。
因此,在应用深度学习模型时,最好能够使用你所熟悉的计算机语言的框架。例如,Caffe(C++)和Torch(Lua)为其代码库提供了Python绑定,但如果你想更好地使用这些技术,就必须能够熟练使用C++或者Lua。相比之下,TensorFlow和MXNet则可以支持多语言,即使使用者不能熟练使用C++,也可以很好地利用该技术。
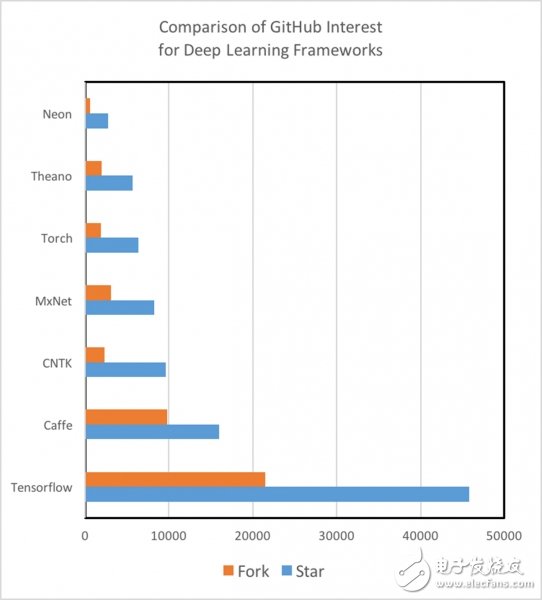
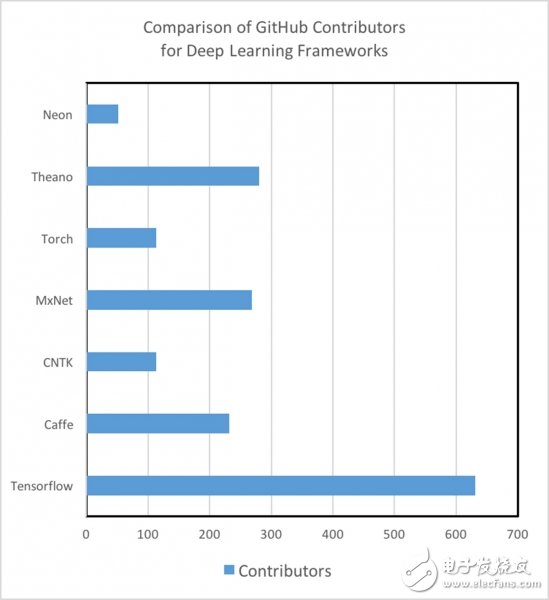
教程(Tutorials)和训练样本
框架的文本质量、覆盖范围以及示例对于有效使用框架至关重要。高质量的文本文件以及待处理的问题的示例将有助于有效解决开发者的问题。完备的文件也表明该工具已经成熟并且在短期内不会改变。
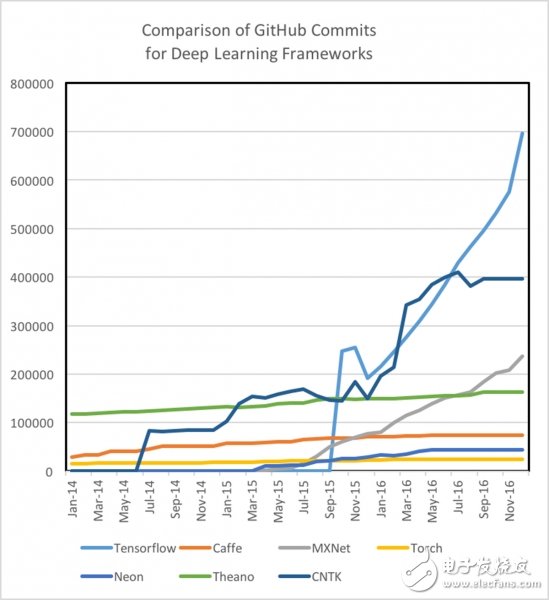
而不同的深度学习框架之间在教程和训练样本的质量和数量的需求方面存在很大的区别。举例来说,Theano、TensorFlow、Torch和MXNet由于具有很好的文本化教程(documented tutorials),所以非常易于理解和实现。另外,我们还发现,不同的框架在GitHub社区的参与度和活跃度高低不仅可以作为其未来发展的重要指标,同时也可以用来衡量通过搜索StackOverflow或Git报告事件来检测和修复bug的速度。值得注意的是,在教程数量、训练样本以及开发人员和用户社区方面,TensorFlow的需求量非常非常大(像是一个800磅重的大猩猩一样的庞然大物)。
CNN建模能力
卷积神经网络(CNN)是由一组不同的层组成,将初始数据量转换成预定义类分数的输出分数。是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现,可用于图像识别、推荐引擎和自然语言处理。此外,CNN还可以用于回归分析,如自动驾驶车辆转向角输出模型等等。CNN建模能力包括几个功能:定义模型的概率空间、预构建层的可用性以及可用于连接这些层的工具和功能。我们看到,Theano、Caffe和MXNet都具有很好的CNN建模功能,这意味着,TensorFlow能够很容易地在其InceptionV3模型上进行能力构建,Torch中包括易于使用的时间卷积集在内的优秀的CNN资源,都使得这两种技术在CNN建模功能上能够很好地区分开来。
RNN建模能力
有别于CNN,递归神经网络(RNN)可以用于语音识别、时间序列预测、图像字幕和其他需要处理顺序信息的任务。由于预先构建的RNN模型不像CNN那样多,因此,如果你有一个RNN深度学习项目,那么就必须考虑为特定技术预先实施和开源何种RNN模型,这是非常重要的。例如,Caffe拥有极少的RNN资源,而微软的CNTK和Torch则拥有丰富的RNN教程和预置模型。虽然TensorFlow也具有一些RNN资源,但TFLearn和Keras中所包含的RNN示例要比使用TensorFlow多得多。
架构
为了在特定的框架中创建和训练新的模型,至关重要的一点是要有一个易于使用而且是模块化的前端架构。检测结果表明,TensorFlow、Torch和MXNet都具有直观的模块化架构,这使得开发变得简单并且直观。相比之下,像Caffe这样的框架则需要花大量的工作来创建一个新的层。另外,我们还发现由于TensorBoard Web GUI应用程序已经被包含在内,TensorFlow在训练期间和训练之后会特别容易调试和监控。
速度
在开放源代码卷积神经网络(CNN)方面Torch和Nervana拥有基准测试的最佳性能记录,TensorFlow性能在大多数测试中也“有的一拼”,而Caffe和Theano在这方面则表现得并不突出;在递归神经网络(RNN)方面,微软则声称CNTK的训练时长最短,速度最快。当然,也有另一项直接针对RNN建模能力速度进行比较的研究表明,在Theano、Torch和TensorFlow中,Theano的表现最好。
多GPU支持
大多数深度学习应用程序需要大量的浮点运算(FLOP)。例如,百度的DeepSpeech识别模型需要10秒钟的ExaFLOPs(百万兆浮点运算)进行训练。那可是大于10的18次方的计算量!而作为领先的图形处理单元(GPU)——如英伟达的Pascal TitanX,每秒可以执行11万亿次浮点运算,在一个足够大的数据集上训练一个新的模型需要一周的时间。为了减少构建模型所需的时间,需要多台机器上的多个GPU。幸运的是,上面列出的大多数技术都提供了这种支持,比如,MXNet就具有一个高度优化的多GPU引擎。
Keras兼容性
Keras是一个用于进行快速深度学习原型设计的高级库,是一个让数据科学家能够自如地应用深度学习的工具。Keras目前支持两个后端——TensorFlow和Theano,并且还将在TensorFlow中获得正式的支持。
Matthew Rubashkin建议,当你要开始一个深度学习项目时,首先要评估好自己团队的技能和项目需求。举例来说,对于以Python为中心的团队的图像识别应用程序,他建议使用TensorFlow,因为其文本文件丰富、性能适宜并且还拥有优秀的原型设计工具。而如果是为了将RNN扩展到具有Lua能力的客户团队产品上,他则推荐使用Torch,这是因为它具有卓越的速度和RNN建模能力。
总而言之,对于大多数人而言,“从零开始”编写深度学习算法成本非常高,而利用深度学习框架中可用的巨大资源是更有效率的。如何选择更合适的框架将取决于使用者的技能和背景,以及具体项目的需求。因此,当你要开始一个深度学习项目时,的确值得花一些时间来评估可用的框架,以确保技术价值的最大化。
-
需要了解手机、天线OTA测试可以来学习一下2014-08-11 0
-
Nanopi深度学习之路(1)深度学习框架分析2018-06-04 0
-
Py之TFCudaCudnn:Win10下安装深度学习框架Tensorflow+Cuda+Cudnn最简单最快捷最详细攻略2018-12-20 0
-
利用ECS进行深度学习详细攻略2018-12-24 0
-
深度学习框架TensorFlow&TensorFlow-GPU详解2018-12-25 0
-
SAW和BAW滤波器你需要了解这些2021-05-24 0
-
深度学习是什么?了解深度学习难吗?让你快速了解深度学习的视频讲解2018-08-23 1137
-
深度学习框架你了解多少2019-07-08 2215
-
openharmony入门教程需要了解哪些2021-06-24 1540
-
深度学习框架pytorch入门与实践2023-08-17 1603
-
深度学习框架是什么?深度学习框架有哪些?2023-08-17 2744
-
深度学习框架的作用是什么2023-08-17 1569
-
深度学习框架连接技术2023-08-17 778
-
深度学习cntk框架介绍2023-08-17 1378
-
TensorFlow与PyTorch深度学习框架的比较与选择2024-07-02 972
全部0条评论

快来发表一下你的评论吧 !
