

AI生成的假新闻难以识别,那就用神经网络来对抗吧
人工智能
描述
AI生成的假新闻难以识别,那就用神经网络来对抗吧
机器之心编辑部
之前,OpenAI GPT-2 因为太能生成假新闻而不提供开源。而最近,华盛顿大学和艾伦人工智能研究所的研究者表示,要想对抗假新闻,用对应的假新闻生成器是最好的方法。研究者通过大量实验表示,最了解假新闻缺点、假新闻“造假水平”的会是原本的生成器。因此想要判别 GPT-2 生成的假新闻,还是需要先开源 GPT-2 大模型。
自然语言生成领域近期的进展令人喜忧参半。文本摘要和翻译等应用的影响是正面的,而其底层技术可以生成假新闻,且假新闻可以模仿真新闻的风格。
现代计算机安全依赖谨慎的威胁建模:从攻击者的角度确定潜在威胁和缺陷,并探索可行的解决方案。同样地,开发对假新闻的稳健防御技术也需要我们认真研究和确定这些模型的风险。
来自华盛顿大学和艾伦人工智能研究所的研究人员近期的一项研究展示了一个可控文本生成模型 Grover。给出标题“Link Found Between Vaccines and Autism”,Grover 可以生成文章内容,且 Grover 生成的内容比人类写的假消息看起来更加可信。
图 1:该研究介绍了一个能够检测和生成假新闻的模型 Grover。
开发对抗 Grover 等生成器的稳健验证技术非常重要。该研究发现,当目前最好的判别器能够获取适量训练数据时,其辨别假新闻和人类所写真新闻的准确率为 73%。
而对 Grover 最好的防御就是 Grover 本身,它可以达到 92% 的准确率,这表明开源强大生成器的重要性。研究人员进一步研究了这些结果,发现数据偏差(exposure bias)和缓解其影响的采样策略都会留下相似判别器能够察觉的缺陷。最后,该研究还讨论了这项技术的伦理问题,研究人员计划开源 Grover,帮助更好地进行假新闻检测。
Grover 生成文章示例

图 8:上图是同样标题的两篇文章,一篇是人类书写的,另一篇则是 Grover 生成的,标题来自《卫报》。右下角为人类评分者给出的分数。

针对假新闻,该研究做了什么?
在本文中,研究人员力图在假新闻大量出现前去理解并解决这一问题。他们认为这一问题属于依赖计算机安全领域,依赖于威胁建模:分析系统的潜在威胁和缺陷,并探索稳健的防御措施。
为了严谨地研究这一问题,研究人员提出了新模型 Grover。Grover 能够可控并高效地生成完整的新闻文章,不仅仅是新闻主体,也包括标题、新闻源、发布日期和作者名单,这有助于站在攻击者的角度思考问题(如图 1 所示)。
人类评分表明他们认为 Gover 生成的假消息是真实可信的,甚至比人工写成的假消息更可信。因此,开发对抗 Grover 等生成器的稳健验证技术非常重要。研究人员假设了一种情景:一个判别器可以获得 Grover 生成的 5000 条假新闻和无限条真实新闻。
在这一假设下,目前最好的假新闻判别器(深度预训练语言模型)可达到 73% 的准确率 (Peters et al., 2018; Radford et al., 2018; 2019; Devlin et al., 2018)。而使用 Grover 作为判别器时,准确率更高,可达到 92%。这一看似反直觉的发现说明,最好的假新闻生成器也是最好的假新闻判别器。
本文研究了深度预训练语言模型怎样分辨真实新闻和机器生成的文本。研究发现,由于数据偏差,在假新闻生成过程中引入了关键缺陷:即生成器是不完美的,所以根据其分布进行随机采样时,文本长度增加会导致生成结果落在分布外。然而,缓解这些影响的采样策略也会引入强大判别器能够察觉的缺陷。
该研究同时探讨了伦理问题,以便读者理解研究者在研究假新闻时的责任,以及开源此类模型的潜在不良影响 (Hecht et al., 2018)。由此,该研究提出一种临时的策略,关于如何发布此类模型、为什么开源此类模型更加安全,以及为什么迫切需要这么做。研究人员认为其提出的框架和模型提供了一个坚实的初步方案,可用于应对不断变化的 AI 假新闻问题。
具体方法
下图 2 展示了利用 Grover 生成反疫苗文章的示例。指定域名、日期和标题,当 Grover 生成文章主体后,它还可以进一步生成假的作者和更合适的标题。

图 2:如图展示了三个 Grover 生成文章的例子。在 a 行中,模型基于片段生成文章主体,但作者栏空缺。在 b 行中,模型生成了作者。在 c 行中,模型使用新生成的内容重新生成了一个更真实的标题。
架构
研究者使用了最近较为流行的 Transformer 语言模型 (Vaswani et al., 2017),Grover 的构建基于和GPT-2相同的架构 (Radford et al., 2019)。研究人员考虑了三种模型大校
最小的 Grover-Base 使用了 12 个层,有 1.17 亿参数,和 GPT 及 Bert-Base 相同。第二个模型是 Grover-Large,有 24 个层,3.45 亿参数,和 Bert-Large 相同。最大的模型 Grover-Mega 有 48 个层和 15 亿参数,与 GPT-2 相同。
数据集
研究者创建了 RealNews 大型新闻文章语料库,文章来自 Common Crawl 网站。训练 Grover 需要大量新闻文章作为元数据,但目前并没有合适的语料库,因此研究人员从 Common Crawl 中抓取信息,并限定在 5000 个 Google News 新闻类别中。
该研究使用名为“Newspaper”的 Python 包来提取每一篇文章的主体和元数据。研究者抓取 2016 年 12 月到 2019 年 3 月的 Common Crawl 新闻作为训练集,2019 年 4 月的新闻则作为验证集。去重后,RealNews 语料库有 120G 的未压缩数据。
训练
对于每一个 Grover 模型,研究人员使用随机采样的方式从 RealNews 中抽取句子,并将句子长度限定在 1024 词以内。其他超参数参见论文附录 A。在训练 Grover-Mega 时,共迭代了 80 万轮,批大小为 512,使用了 256 个 TPU v3 核。训练时间为两周。
语言建模效果:数据、上下文(context)和模型大小对结果的影响
研究人员使用 2019 年 4 月的新闻作为测试集,对比了 Grover 和标准通用语言模型的效果。测试中使用的模型分别为:通用语言模型,即没有提供上下文语境作为训练,且模型必须生成文章主体。另一种则是有上下文语境的模型,即使用完整的元数据进行训练。在这两种情况下,使用困惑度(perplexity)作为指标,并只计算文章主体。
图 3 展示了结果。首先,在提供元数据后,Grover 模型的性能有显著提升(困惑度降低了 0.6 至 0.9)。其次,当模型大小增加时,其困惑度分数下降。在上下文语境下,Grover-Mega 获得了 8.7 的困惑度。第三,数据分布依然重要:虽然有 1.17 亿参数和 3.45 亿参数的 GPT-2 模型分别可以对应 Grover-Base 和 Grover-Large,但在两种情况下 Grover 模型相比 GPT-2 都降低了超过 5 分的困惑度。这可能是因为 GPT-2 的训练集 WebText 语料库含有非新闻类文章。

图 3:使用 2019 年 4 月的新闻作为测试集,多个语言模型的性能。研究人员使用通用(Unconditional)语言模型(不使用元数据训练)和有上下文语境(Conditional)的模型(提供所有元数据训练)。在给定元数据的情况下,所有 Grover 模型都降低了超过 0.6 的困惑度分数。
使用 Nucleus Sampling 限制生成结果的方差
在 Grover 模型中采样非常直观,类似于一种从左到右的语言模型在解码时的操作。然而,选择解码算法非常重要。最大似然策略,如束搜索(beam search),对于封闭式结尾的文本生成任务表现良好,其输出和其语境所含意义相同(如机器翻译)。
这些方法在开放式结尾的文本生成任务中则会生成质量不佳的文本 (Hashimoto et al., 2019; Holtzman et al., 2019)。然而,正如该研究在第六章展示的结果,限定生成文本的方差依然很重要。
该研究主要使用 Nucleus Sampling 方式(top-p):给出阈值 p,在每个时间步,从累积概率高于 p 的词语中采样 (Holtzman et al., 2019)。研究人员同时对比了 top-k 采样方式,即在每一个时间步取具有最大概率的前 k 个 token (Fan et al., 2018)。
Grover 生成的宣传文本轻易地骗过了人类
图 4 中的结果显示了一个惊人的趋势:尽管 Grover 生成的新闻质量没有达到人类的高度,但它擅长改写宣传文本。Grover 改写后,宣传文本的总体可信度从 2.19 增至 2.42。

图 4:人工评估结果。对于 Grover 生成的文本,三个人类评分者从风格、内容和整体可信度方面进行评估;每种类别的文章取样 100 篇。结果显示,Grover 生成的宣传文本比人类书写的原始宣传文本的可信度更高。
假新闻检测
假新闻检测中的半监督假设
虽然网上有大量人类书写的文本,但大部分都时间久远。因此对于文本的检测应当设定在近一段时间。同样,由攻击方生成的 AI 假新闻数量可能十分少。因此,研究人员将假新闻检测问题当做半监督问题。假新闻判别器可以使用从 2016 年 12 月到 2019 年 3 月的大量人工写成的新闻,即整个 RealNews 训练集。
但是,判别器被限制获取近期新闻和 AI 生成的假新闻。研究者使用 2019 年 4 月的 10000 条新闻生成文章主体文本,使用另外 10000 条新闻作为人类写成的新闻文章。研究人员将这些文章进行分割,其中 10000 条用于训练(每个标签 5000),2000 用作验证集,8000 用作测试集。
研究人员考虑了两种评价方式。第一种是不成对设置,即判别器仅获得文章文本,并且需要独立地判断文章是人类写的还是机器生成的。而在成对设置中,模型获得两份具备同样元数据的文章,一份属于人类完成,一份属于机器生成。判别器必须给机器生成的文章分配高于人工完成文章的 Machine 概率。研究人员对两种评价方法的准确率都进行了评估。
判别器评价结果:Grover 在检测 Grover 生成的假新闻时表现最好
表 1 展示了所有生成器和判别器组合的实验结果。对每个组合,研究人员展示了使用不同的采样策略(top-p&top-k)超参数的评价结果(p ∈ {.9, .92, .94, .96, .98, 1.0},k ∈ )。
结果显示了几种趋势:首先,成对生成器、判别器相比非成对设置总体上更加容易检测假新闻,说明模型更难校准自己的预测。其次,模型大小对生成器和判别器之间的对抗过程非常关键。使用 Grover 判别器对 Grover 生成的文本进行检测,总体上在所有 Grover 模型中都有大约 90% 的准确率。
如果使用一个更大的生成器,准确率会下滑至低于 81%,与此相对应的是,如果判别器更大,则(检测假新闻)准确率上升至 98% 以上。最后,其他判别器总体上表现比 Grover 更差,这说明有效的判别器需要和生成器一样的归纳偏置(inductive bias)。
无法获得对应生成器又怎么样?
上文中的结果说明,当在测试阶段遇到一样的攻击方(生成器)时,在研究人员有一定数量的假新闻数据的情况下,Grover 是一个有效的假新闻判别器。但是如果放松这一假设呢?这里,研究人员考虑了攻击方使用 Grover-Mega 生成器,且有一个未知的 top-p 采样阈值。
在这一设定下,研究人员在训练中可以获得相对较弱的模型(Grover-Base 或 Grover-Large)。研究人员考虑了只有 x 个来自 Grover-Mega 的文本,并从较弱的生成器模型中采样 5000-x 个文章,采样阈值则对每一个文章都限定在 [0.9, 1.0] 之间。
研究人员在图 5 中展示了实验结果。结果说明,当只有少量 Grover-Mega 生成器文本时,从其他生成器获得的弱监督文本可以极大提升判别器的表现。16 至 256 个 Grover-Mega 数据,加上从 Grover-Large 获得的弱文本,可以使模型得到约 78% 的准确率,但没有弱文本时仅有 50% 的准确率。当来自 Grover-Mega 的文本数据增加时,准确率可提升至 92%。
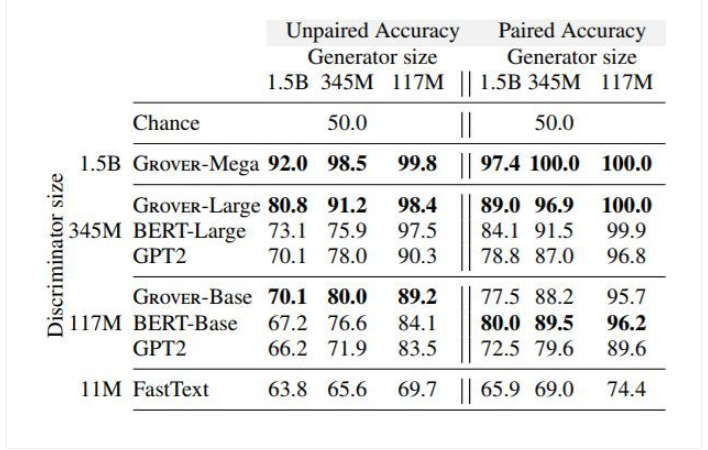
表 1:在成对和不成对设置以及不同大小架构中判别器和生成器的结果。研究人员还调整了每对生成器和判别器的生成超参数,并介绍了一组特殊的超参数,它具有最低验证准确率的判别测试准确率。与其它模型(如 BERT)相比,Grover 最擅长识别自身生成的假新闻。
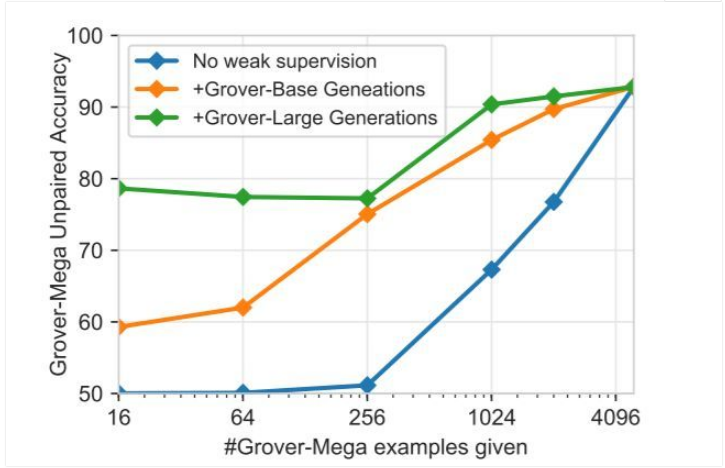
图 5:探索判别 Grover-Mega 生成结果的弱监督。在没有弱监督的情况下,判别器发现了 x 个机器生成的文本(来自 Grover Mega)。对于 Grover-Base 和 Grover-Mega,判别器发现了 5000-x 个机器生成的文本,这些文本由较弱的相关生成器给出。当给出的域内样本较少时,生成的弱文本可以提升判别器的性能表现。
模型如何区分人工手写和机器生成的文本?
等式 1:最近的最佳通用文本生成任务被认为是一个语言建模问题 (Bengio et al., 2003)。在这一问题中,需要寻找生成文本 x 的概率,此概率为该文本中每一个词以前面所有词为条件的概率之积。
为什么 Grover 在检测自己生成的假新闻时效果最好?研究人员猜想部分原因可能是数据偏差,即训练最大化等式 1 的模型仅能描述人工书写的文本(Ranzato et al., 2016)。为了验证他们的猜想,研究人员在图 6 中绘制了 Grover-Mega 在文本每个位置的困惑度,取阈值 p=0.96 和 p=1 时的文本以及人工手写的文本。
之后生成第一个 token 会导致较高的困惑度。但是,其余位置显示出一种奇怪的模式:人工书写的文本有着比随机采样文本更低的困惑度,而这个差距随着序列长度的增加而加大,表明随机采样通常会导致 Grover 生成的结果越来越脱离人类语言的分布。然而,限制方差(p=0.96)会降低由此产生的困惑度并限制其增长。
1. 限制模型方差同样产生了关键特征
但是在另一方面,限制模型的方差同样留下了一种特征。如同以前的研究采用的 top-k 采样一样 (Strobelt and Gehrmann,2019),本次研究使用的原子采样也出现了同样的现象。一个人工写成的文章中所有词都高于 top-p% 阈值的概率是 p^n,n 是文本长度。当 n 增长时,概率下降。然而,对于原子采样的文本,概率低于 1?-p 的文本被去除。因此文本中所有词的出现概率都在 top-p 以上,根据这个特征就能进行判别。
2. 特征能否被捕捉取决于对判别器的选择
对每一个时间步,从整体上来说,仅有生成器使用了 top-p 超参数。因此,如果一个判别器使用别的方式对文本进行建模,这个生成器需要更多的时间去定位被截断的 1-p 分布长尾。这可能能够解释为什么 Bert 在作为判别器时表现较 Grover 更差。
3. 方差缩减时需要谨慎避开的“甜蜜陷阱”(sweet spot)
不缩减模型方差和强力缩减模型方差都会带来问题。在缩减的参数中可能存在一个“甜蜜陷阱”(sweet spot)区域,去决定多大程度上需要截断分布,使判别变得困难。在图 7 中,研究人员展示了在不同采样阈值下的 Grover-Mega 判别器的表现。结果确实显示出了一个“甜蜜陷阱”。对于判别器,当 p 介于 0.92 和 0.98 之间时,判别工作是最困难的。
有趣的是,研究人员注意到攻击方 top-p 阈值在 Bert-Large 模型远低于这一阈值在 Grover-Large 中的值,即使两个模型有着同样的结构。这一结果支持了研究人员的猜测,即 Bert 对语言的建模方式和 Grover 非常不同。使用低 top-p 阈值似乎不能帮助模型获得丢失的长尾信息。
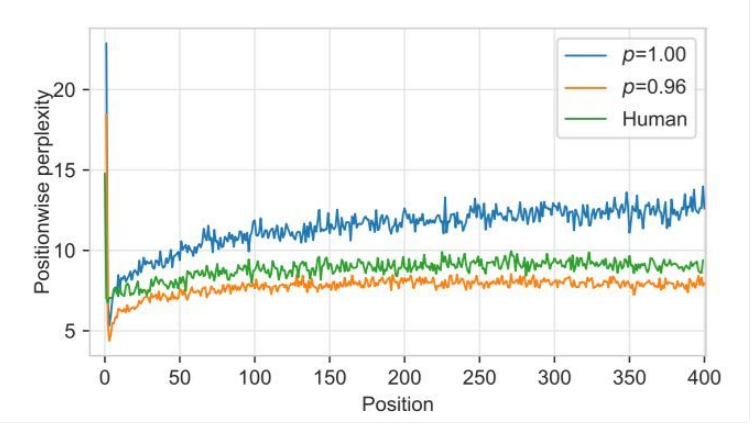
图 6:Grover-Mega 的困惑度,取自每个位置的平均值(以元数据为条件)。研究人员选取了 p=1(随机采样)和 p=0.96 时 Grover-Mega 生成的文本以及人工书写的文本。随机采样的文本有着比人工书写的文本更高的困惑度,而且这个差距随着序列长度的增加而加大。这表明,不减少方差的抽样通常会导致生成结果落在真实分布以外。
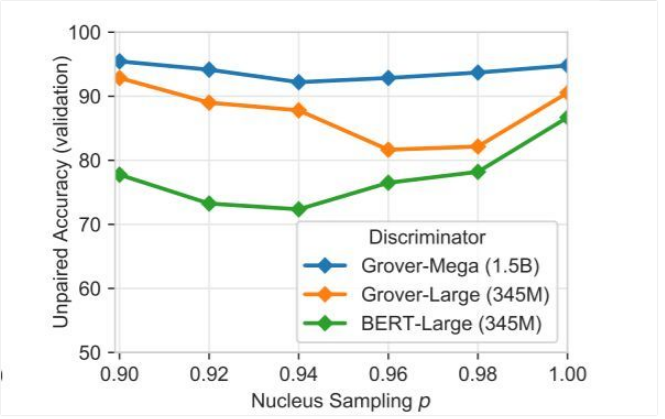
图 7:在设定了不同的方差缩减阈值时(如 p 对应原子采样和 k 对应 top-k 采样方式),将 Grover Mega 生成的新文章与真实文章区分开的未配对的验证准确率。因 p 的不同,结果也有所不同。当 p 在 0.92-0.96 之间时,区分假消息的难度最高。
总之,本文的分析表明,Grover 可能最擅长捕捉 Grover 生成的假新闻,因为它最了解假新闻的长尾分布在哪里,也因此知道 AI 假新闻的长尾分布是否被不自然地截断。
开源策略
生成器的发布很关键。首先,似乎不开源像 Grover 这样的模型对我们来说更安全。但是,Grover 能够有效检测神经网络生成的假新闻,即使生成器比其大多了(如第 5 部分所示)。如果不开源生换器,那针对对抗攻击的手段就很少了。
最后,研究人员计划公开发布 Grover-Base 和 Grover-Large,感兴趣的研究者也可以申请下载 Grover-Mega 和 RealNews。
-
粒子群优化模糊神经网络在语音识别中的应用2010-05-06 0
-
人脸识别、语音翻译、无人驾驶...这些高科技都离不开深度神经网络了!2018-05-11 0
-
基于BP神经网络的手势识别系统2018-11-13 0
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 0
-
【AI学习】第3篇--人工神经网络2020-11-05 0
-
如何使用stm32cube.ai部署神经网络?2021-10-11 0
-
轻量化神经网络的相关资料下载2021-12-14 0
-
基于深度神经网络的激光雷达物体识别系统2021-12-21 0
-
卷积神经网络模型发展及应用2022-08-02 0
-
卷积神经网络简介:什么是机器学习?2023-02-23 0
-
神经网络在雷达对抗与反对抗中的应用2010-09-09 663
-
cnn卷积神经网络模型 卷积神经网络预测模型 生成卷积神经网络模型2023-08-21 1244
-
神经网络架构有哪些2024-07-01 713
-
生成式AI与神经网络模型的区别和联系2024-07-02 746
-
人工神经网络模型的分类有哪些2024-07-05 1211
全部0条评论

快来发表一下你的评论吧 !
