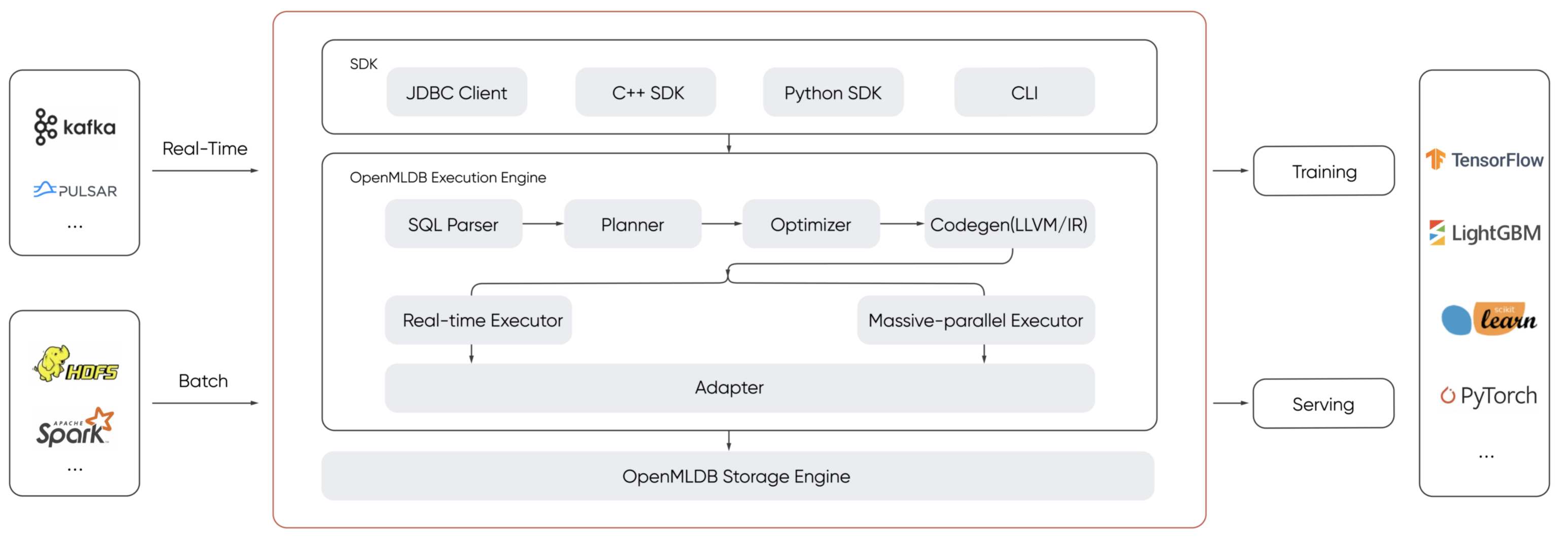
OpenMLDB是一个面向机器学习应用提供正确、高效数据供给的开源数据库。除了超过10倍的机器学习数据开发效率的提升,OpenMLDB也提供了统一的计算与存储引擎减少开发运维的复杂性与总体成本。
系统特性
-
一致性
OpenMLDB首先保证在线和离线特征计算一致性,科学家使用OpenMLDB建模生成的特征,可规避特征穿越等问题,上线后使用相同LLVM IR进行编译优化,保证与在线特征计算逻辑一致。其次保证数据存储一致性,数据从离线到在线进行实时同步,用户不需要为离线和在线管理不同数据源,也避免数据不一致对特征和模型带来的影响。
-
高性能
OpenMLDB基于C++和LLVM实现了原生SQL编译器,内置了数十种物理计划和表达式优化过程,可针对不同硬件环境动态生成二进制码,内存结构针对特征存储优化。最终特征存储空间和成本比同类产品可降低9倍,在线实时特征计算性能提升9倍,离线批处理计算性能比同类产品也提升6倍以上。
-
高可用
OpenMLDB的大规模并行计算服务和数据库存储服务,都支持多节点分布式高可用特性,可以自动Failover避免单点故障。
-
SQL支持
OpenMLDB支持用户友好的SQL接口,兼容大部分ANSI SQL语法以及针对AI场景拓展了新的SQL特性。以时序特征抽取为例,支持标准SQL的Over Window语法,还针对AI场景需求进行拓展,支持基于样本表滑窗的Window Union语法,实时计算引擎支持基于当前行的Request Mode窗口聚合计算。
-
AI优化
OpenMLDB以面向ML应用开发优化为目标,架构设计以及实现上都针对AI进行大量优化。在存储方面以高效的数据结构存储特征数据,无论是内存利用率还是实时查询效率都比同类型产品高数倍,而计算方面提供了机器学习场景常用的特殊拼表操作以及特征抽取相关UDF/UDAF支持,基本满足生产环境下机器学习特征抽取和上线的应用需求。
-
低门槛
OpenMLDB使用门槛与普通数据库接近,无论是建模科学家还是应用开发者都可以使用熟悉的SQL进行开发,并且同时支持ML应用落地所必须的离线大数据批处理服务以及在线特征计算服务,使用一个数据库产品就可以低成本实现AI落地闭环。
快速开始
使用OpenMLDB快速开发和上线ML应用,以Kaggle比赛Predict Taxi Tour Duration项目为例。
# 启动docker镜像 docker run -it 4pdosc/openmldb:0.1.0 bash # 初始化环境 sh init.sh # 导入行程历史数据到OpenMLDB python3 import.py # 使用行程数据进行模型训练 python3 train.py ./fe.sql /tmp/model.txt # 使用训练的模型搭建链接OpenMLDB的实时推理HTTP服务 sh start_predict_server.sh ./fe.sql 8887 /tmp/model.txt # 通过http请求发送一个推理请求 python3 predict.py
系统架构