

语音识别算法有哪些_语音识别特征提取方法
音频技术
描述
语音识别算法有哪些
本文列举了几种不同的语音识别算法。
第一种:基于动态时间规整(Dynamic Time Warping)的算法
在连续语音识别中仍然是主流方法。
该方法的运算量较大,但技术上较简单,识别正确率高。
在小词汇量、孤立字(词)识别系统中,也已有许多改进的DTW算法被提出。例如,利用频率尺度的DTW算法进行孤立字(词)识别的方法。
第二种:基于参数模型的隐马尔可夫模型(HMM)的方法
该算法主要用于大词汇量的语音识别系统,它需要较多的模型训练数据,较长的训练和识别时间,而且还需要较大的内存空间。
一般连续隐马尔可夫模型要比离散隐马尔可夫模型计算量大,但识别率要高。
第三种:基于非参数模型的矢量量化(VQ)的方法
该方法所需的模型训练数据,训练和识别时间,工作存储空间都很小。
但是VQ算法对于大词汇量语音识别的识别性能不如HMM好。
在孤立字(词)语音识别系统中得到了很好的应用。
另外,还有基于人工神经网络(ANN)的算法和混合算法,如ANN/HMM法,FSVQ/HMM法等。
更多语音识别算法如下:
卷积神经网络
深度学习神经网络
BP神经网络
RBF神经网络
模糊聚类神经网络
改进的T-S模糊神经网络
循环神经网络
小波神经网络
混沌神经网络
小波混沌神经网络
神经网络和遗传算法
动态优化神经网络
K均值和神经网络集成
HMM与自组织神经网络的结合
正交基函数对向传播过程神经网络
HMM和新型前馈型神经网络
特征空间随机映射
SVM多类分类算法
特征参数归一化
多频带谱减法
独立感知理论
分段模糊聚类算法VQ-HMM
优化的竞争算法
双高斯GMM特征参数
MFCC和GMM
MFCCs和PNN
SBC和SMM
MEL倒谱系数和矢量量化
DTW
LPCC和MFCC
隐马尔科夫模型HMM
语音识别特征提取方法
语音识别对特征参数有如下要求:
1. 能将语音信号转换为计算机能够处理的语音特征向量
2. 能够符合或类似人耳的听觉感知特性
3. 在一定程度上能够增强语音信号、抑制非语音信号
常用特征提取方法有如下几种:
(1)线性预测分析(LinearPredictionCoefficients,LPC)
拟人类的发声原理,通过分析声道短管级联的模型得到的。假设系统的传递函数跟全极点的数字滤波器是相似的,通常用12-16个极点就可以描述语音信号的特征。所以对于n时刻的语音信号,我们可以用之前时刻的信号的线性组合近似的模拟。然后计算语音信号的采样值和线性预测的采样值。并让这两者之间达到均方的误差(MSE)最小,就可以得到LPC。
(2)感知线性预测系数(PerceptualLinearPredictive,PLP)
一种基于听觉模型的特征参数。该参数是一种等效于LPC的特征,也是全极点模型预测多项式的一组系数。不同之处是PLP是基于人耳听觉,通过计算应用到频谱分析中,将输入语音信号经过人耳听觉模型处理,替代LPC所用的时域信号,这样的优点是有利于抗噪语音特征的提取。
(3)Tandem特征和Bottleneck特征
这是两种利用神经网络提取的两类特征。Tandem特征是神经网络输出层节点对应类别的后验概率向量降维并与MFCC或者PLP等特征拼接得到。Bottleneck特征是用一种特殊结构的神经网络提取,这种神经网络的其中一个隐含层节点数目比其他隐含层小的多,所以被称之为Bottleneck(瓶颈)层,输出的特征就是Bottleneck特征。
(4)基于滤波器组的Fbank特征(Filterbank)
亦称MFSC,Fbank特征的提取方法就是相当于MFCC去掉最后一步的离散余弦变换,跟MFCC特征相比,Fbank特征保留了更多的原始语音数据。
(5)线性预测倒谱系数(LinearPredictiveCepstralCoefficient,LPCC)
基于声道模型的重要特征参数。LPCC是丢弃了信号生成过程中的激励信息。之后用十多个倒谱系数可以代表共振峰的特性。所以可以在语音识别中取得很好的性能。
(6)梅尔频率倒谱系数(MelFrequencyCepstrumCoefficient,MFCC)
基于人耳听觉特性,梅尔频率倒谱频带划分是在Mel刻度上等距划分的,频率的尺度值与实际频率的对数分布关系更符合人耳的听觉特性,所以可以使得语音信号有着更好的表示。1980年由Davis和Mermelstein搞出来的。从那时起。在语音识别领域,MFCC可谓是鹤立鸡群,一枝独秀。
Q: MFCC为何一枝独秀
人通过声道产生声音,声道的shape决定了发出怎样的声音。声道的shape包括舌头,牙齿等。如果我们可以准确的知道这个形状,那么我们就可以对产生的音素phoneme进行准确的描述。声道的形状在语音短时功率谱的包络中显示出来。而MFCC就是一种准确描述这个包络的一种特征。
声谱图
处理语音信号,如何去描述它很重要,因为不同的描述方式放映它不同的信息,而声谱图的描述方式是最利于观测和理解的。
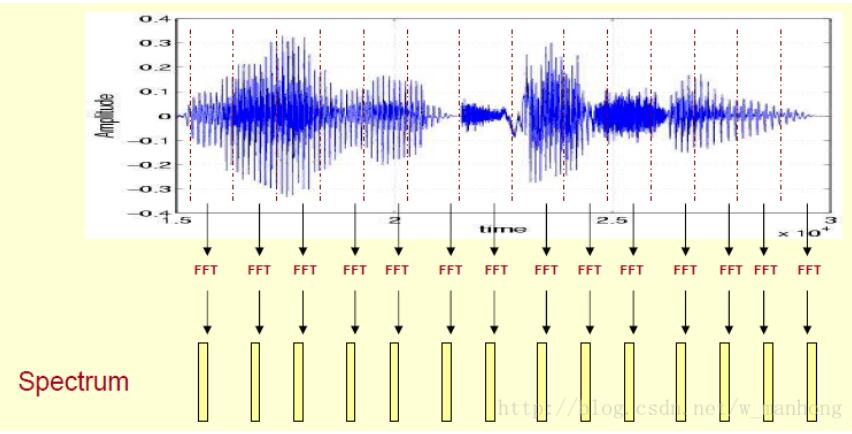
由上图可知,这段语音被分为很多帧,每帧语音都对应于一个频谱(通过短时FFT计算),频谱表示频率与能量的关系。在实际使用中,频谱图有三种,即线性振幅谱、对数振幅谱、自功率谱(对数振幅谱中各谱线的振幅都作了对数计算,所以其纵坐标的单位是dB(分贝)。这个变换的目的是使那些振幅较低的成分相对高振幅成分得以拉高,以便观察掩盖在低幅噪声中的周期信号)。
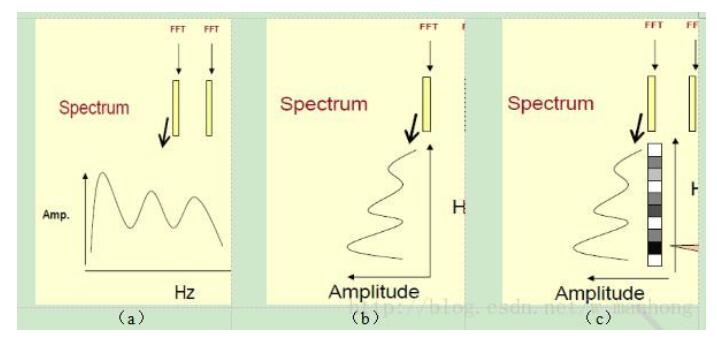
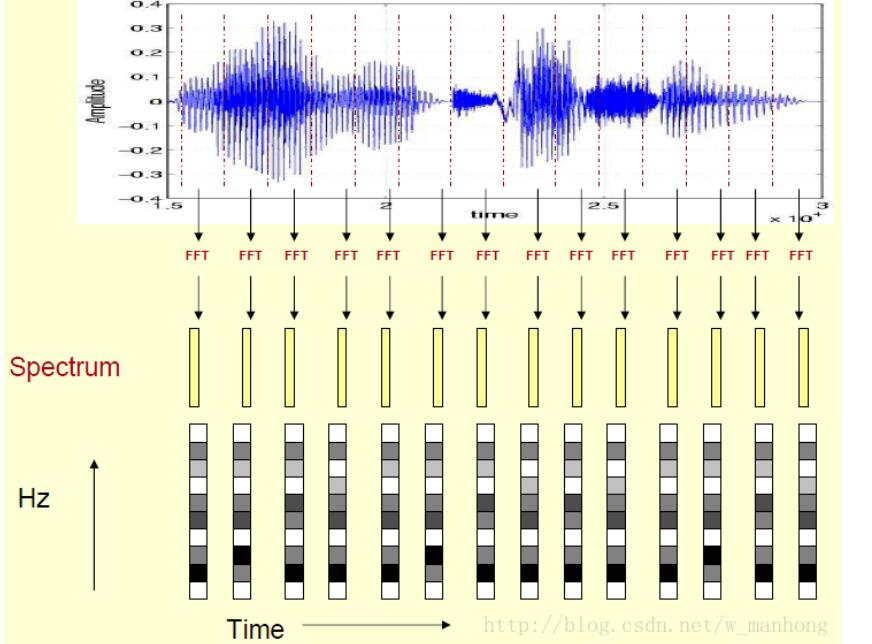
先将其中一帧语音的频谱通过坐标表示出来,如上图(a)。旋转90度,得到图(b)。把这些幅度映射到一个灰度级表示,得到了图(c)。这样操作的原因是为了增加时间维度,,得到一个随着时间变化的频谱图,这个就是描述语音信号的声谱图(spectrogram)。这样就可以显示一段语音而不是一帧语音的频谱,而且可以直观的看到静态和动态的信息。
倒谱分析(CepstrumAnalysis)
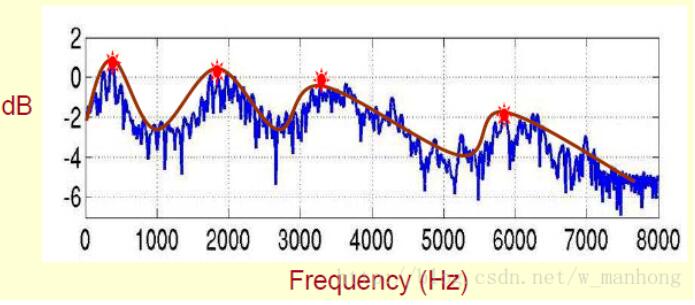
下面是一个语音的频谱图。峰值就表示语音的主要频率成分,我们把这些峰值称为共振峰(formants),而共振峰就是携带了声音的辨识属性,用它就可以识别不同的声音。因此,需要把它提取出来。要提取的不仅是共振峰的位置,还得提取它们转变的过程。所以我们提取的是频谱的包络(SpectralEnvelope)。这包络就是一条连接这些共振峰点的平滑曲线。
由上图可以看出,原始的频谱由两部分组成:包络和频谱的细节。因此需要把这两部分分离开,就可以得到包络了。按照下图的方式进行分解,在给定logX[k]的基础上,求得logH[k]和logE[k]满足logX[k]=logH[k]+logE[k]。
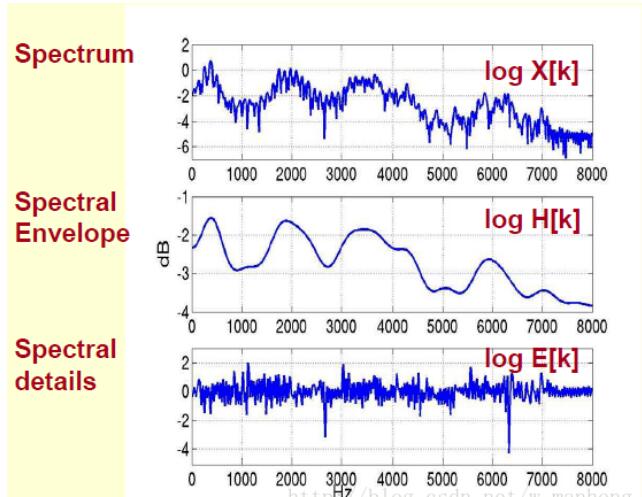
由上面这个图我们可以看到,包络主要是低频成分,而高频主要是频谱的细节。把它俩叠加起来就是原来的频谱信号了。即,h[k]是x[k]的低频部分,因此将x[k]通过一个低通滤波器就可以得到h[k]了,也就是频谱的包络。
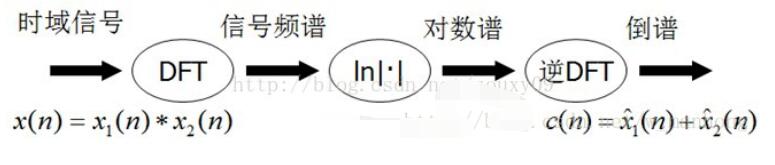
以上解卷过程的专业术语叫做同态信号处理,(另一种方法为基于线性变换)。语音本身可以看成是声道冲击信息(包括话者个性信息、语义信息,表现为频谱低频成分)经过声门激励的一个响应函数,在时域上表现为卷积形式。为将二者分离开来,求得声道共振特征和基音周期,需要把这种非线性问题转化为线性问题。第一步通过FFT将其变成了乘性信号(时域的卷积相当于频域的乘积);第二步通过取对数将乘性信号转化为加性信号;第三步进行逆变换,使其恢复为卷性信号。此时,虽然前后均是时域序列,但它们所处的离散时域显然不同,所以后者称为倒谱频域。计算过程如下图所示。
更多精彩阅读:
语音识别的两个方法_语音识别的应用有哪些
语音识别的优缺点_语音识别功能介绍
怎么实现语音识别_手机语音识别怎么设置
语音识别设置能删除吗_语音识别系统工作流程
- 相关推荐
- 语音识别
-
#硬声创作季 #语音识别 语音识别实战-16-3-语音特征提取水管工 2022-12-07
-
手背静脉特征提取算法2010-04-24 0
-
基于labview的语音识别2019-03-10 0
-
AI语音识别市场规模怎么样?2019-09-11 0
-
离线语音识别和控制的工作原理及应用2023-11-07 0
-
模式识别中的特征提取研究2009-12-12 655
-
基于EMD法的语音信号特征提取2011-10-10 888
-
基于Gabor的特征提取算法在人脸识别中的应用2013-01-22 1096
-
语音情感识别方法2017-11-23 807
-
一种新的语音信号特征提取方法2017-12-18 1098
-
基于Labview的语音模式识别MFCC原理特征提取2020-01-09 1851
-
基于自编码特征的语音声学综合特征提取2021-05-19 757
-
基于特征提取和密度聚类的钢轨识别算法2021-06-16 994
-
语音识别技术:原理、应用与未来2023-09-19 1802
-
情感语音识别的研究方法与实践2023-11-16 851
全部0条评论

快来发表一下你的评论吧 !
