

深度学习如何进行MRI图像右心室分割
未来医疗
描述
人类心脏是一台令人惊叹的机器,它能持续运转长达一个世纪而不失灵。测量心脏功能的关键方法之一是计算其射血分数,即每搏输出量占心室舒张末期容积量的百分比。而测量这个指标的第一步依赖于对心脏图像心室的分割。
问题描述
开发一个能够对心脏磁共振成像(MRI)数据集图像中的右心室自动分割的系统。到目前为止,这主要是通过经典的图像处理方法来处理的。而现代深度学习技术有可能提供更可靠、更自动化的解决方案。
2016年由Kaggle赞助的左心室分割挑战赛中的三名获奖者都采用了深度学习解决方案。然而,分割右心室(RV)则更具挑战性,因为:
在腔内存在信号强度类似于心肌的小梁; RV复杂的新月形;分割根尖图像切片的难度;个体之间的室内形状和强度存在相当大的差异,特别是在不同的疾病病例之间。
撇开医学术语不谈,要识别RV就更困难了。左心室是一个厚壁圆环,而右心室是一个形状不规则的物体,有薄的壁,有时会与周围的组织混合在一起。这是MRI快照右心室内壁和外壁(心内膜和心外膜)的手工绘制轮廓:
这是一个分割起来很容易的例子。这一个比较困难:
而这对于没有经过训练的眼睛来说完全是一个挑战:
事实上,与左心室相比,医生需要耗费两倍的时间来确定右心室的体积并生成结果。这项工作的目的是建立一个高度准确的右心室自动分割深度学习模型。模型的输出是*分割掩码*,即一个逐像素的掩码,用来表示某个像素是否是右心室的一部分或只是背景。
数据集
对于当前这个问题,深度学习需要面对的最大挑战是数据集太小。 数据集(可以访问这里)仅包含了来自于16例患者的243张医师分割的MRI图像。 另外还有3697张未标记的图像,这对于无监督或半监督技术可能会有用,但是我将这些放在了一边,因为这是一个监督学习问题。 图像尺寸为216×256像素。
由于数据集过小,人们可能会怀疑无法将其一般化到尚未看到的图像!但是很不幸,医疗上标记过的数据非常昂贵,并且很难获取到。对数据集进行处理的标准程序是对图像应用仿射变换:随机旋转、平移、缩放和剪切。此外,我实现了弹性变形,也就是对图像的局部区域进行拉伸和压缩。
应用这种图像增强算法的目的是为了防止神经网络只记住训练的样例,并强迫其学习RV是一个实心的、月牙形的、方向任意的物体。在我实现的训练框架中,我会随时对数据集应用图像变换算法,这样,神经网络就会在每次训练时看到新的随机变换。
由于大多数像素都属于背景,所以各个种类之间分布不平衡。如果将像素强度归一化在0和1之间,那么在整个数据集中,只有5%的像素属于RV腔的一部分。
在创建损失函数时,我尝试了重加权方案来平衡种类的分布情况,但最终发现未加权平均算法的表现最好。
在训练中,有20%的图像被取出来作为验证集使用。 RV分割挑战赛的组织者有一个单独的测试集,它由另外32个患者的514张MRI图像组成。我提交的预测轮廓就是使用这个测试集进行最终评估的。
还需要有一种方法来对数据集上的模型性能进行量化。RV分割挑战赛的组织者选择使用了戴斯系数。模型会输出一个掩码*X*来描述RV,而戴斯系数将*X*与由医师创建的掩码*Y*通过以下方式进行比较:
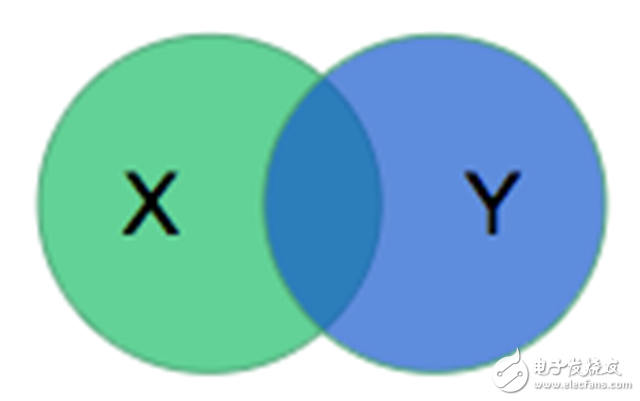

计算值是交叉区域与两区域之和的比率的两倍。对于不相交的区域,值为0;如果两区域完全一致,则值为1。
下面我们来看下模型架构。
U-net:基线模型
由于我们只有四周的时间来完成这个项目,所以我想尽快实现一个基线模型并让它运行起来。我选择了由Ronneberger、Fischer和Brox提出的u-net模型,因为它曾在生物医学分割项目中取得过成功,而且它的作者能够通过使用积极的图像增强和逐像重新加权算法并仅基于*30张图片*来训练网络。
u-net架构由一个收缩路径组成,就是将图像折叠成一组高级特征,随后是使用特征信息构建像素分割掩码的扩展路径。 u-net独特的地方就是它的“复制和合并”连接,这些连接能够将信息从早期特征图传递到构建分割掩码网络的后续部分。作者指出,这些连接允许网络同时并入高级特征和像素方面的细节。
我们使用的架构如下所示:
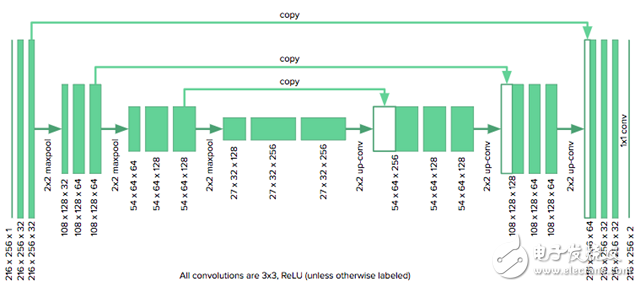
由于我们图像尺寸是u-net作者原本考虑的一半大小,所以我们需要将原始模型中的降采样层数从4个减少到3个来适应网格。我们也要用零来填充卷积,以保持图像的大小不变。该模型是用Keras实现的。
如果没有图像增强,u-net在训练数据集上的戴斯系数能达到0.99(0.01),这意味着该模型具有足够的能力来捕获RV分割问题的复杂性。然而,验证戴斯系数为0.79(0.24),所以u-net过强。图像增强改进了泛化,并将验证精度提高到了0.82(0.23),代价是将训练精度降至0.91(0.06)。
我们如何进一步地降低训练与验证之间的差距呢?正如Andrew Ng在这个很棒的谈话中描述的那样,我们可以用更多的数据(这不太可能)、正则化(dropout和批处理规范化没有效果)、或尝试新的模型架构。
扩张U-net:全局感受野
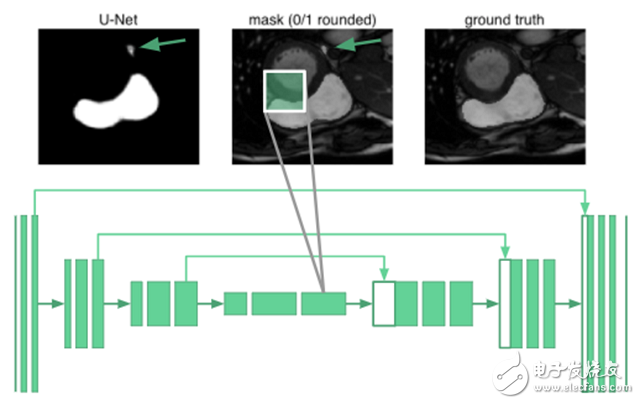
要对器官图像进行分割,需要了解器官之间排列的相关知识。事实证明,即使在u-net最深层的神经元也只有68×68像素的感受野。网络的任何部分都无法“看到”整个图像。网络不知道人类只有一个右心室。例如,下面的图片中,箭头标记的地方被错误分类了:
我们使用扩张卷积来增加网络的感受野。
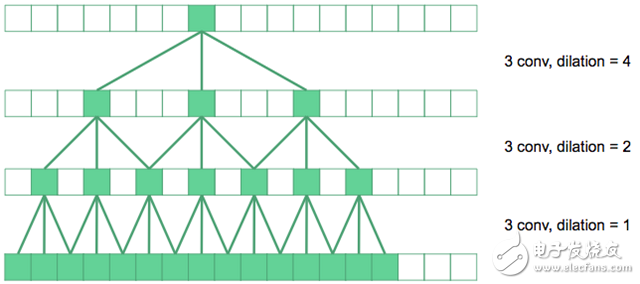
在上图中,底层的卷积是规则的3×3卷积。下一层,我们将卷积扩大了2倍,所以在原始图像中它们的有效感受野是7×7。如果顶层卷积扩大4倍,则能产生15×15的感受野。以此类推。
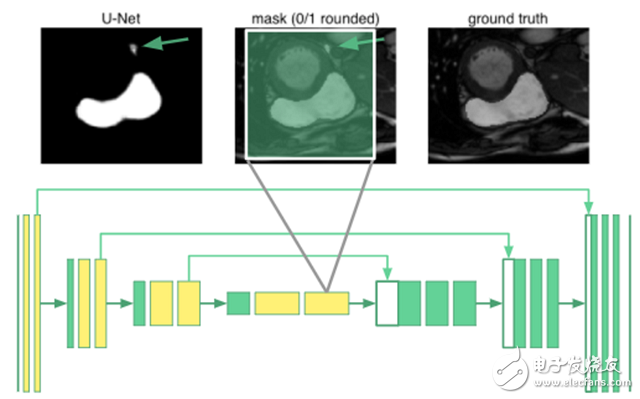
从原理上来说,黄色标记的卷积层被u-net中的扩张卷积所替代。最内层的神经元现在具有了覆盖整个输入图像的感受野。我称之为“扩张u-net”。
在数量上,扩张u-net确实提高了效果,达到了0.85(0.19)的验证戴斯分数,同时保持了0.92(0.08)的训练效果!
扩张DenseNet:一次性多个尺度
这个灵感来自于物理中的张量网络,我决定尝试使用一个新型的图像分割架构,我称之为“扩张DenseNet”。它结合了扩张卷积和DenseNet这两种想法,这样能够大大减少网络的深度和参数。
对于分割而言,我们需要来自多个尺度的全局上下文和信息来产生像素级掩码。如果我们完全依赖于扩张卷积来产生全局上下文,而不是通过降采样来将图像变得更小呢?现在,所有卷积层的大小都相同,我们可以应用DenseNet架构的关键思想,并在所有层之间使用“复制和合并”连接。扩张DenseNet的结果如下图所示:
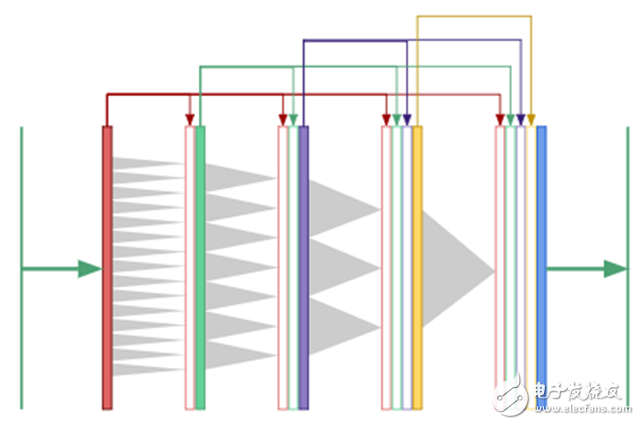
在DenseNet中,第一个卷积层的输出作为输入馈送到所有的后续层中,第二、第三层也这样。
扩张DenseNet表现不错,在验证集上得到了0.87(0.15)的戴斯得分,训练精度为0.91(0.10),同时保持了极高的参数效率!
结果
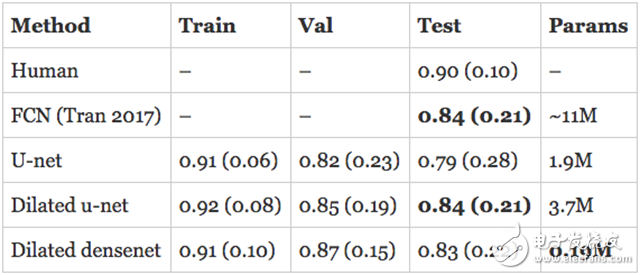
对人类在RV分割方面的评估给如何对模型的表现进行评估指明了方向。研究人员估计,人类完成RV分割任务的戴斯得分为0.90(0.10)。上面所述的已经发布的模型是完全卷积网络(FCN),测试集上的精度为0.84(0.21)。
我开发的模型在验证集上已经超过了最新的技术水平,并且正在接近人类的表现!然而,真正的评测是在测试集上评估模型的表现。此外,上面引用的数字是针对心内膜的, 那么心外膜的表现如何呢?我在心外膜上训练了一个单独的模型,并将细分轮廓提交给了组织者,希望能获得最好的成绩。
以下是结果,首先是心内膜:
这个是心外膜:
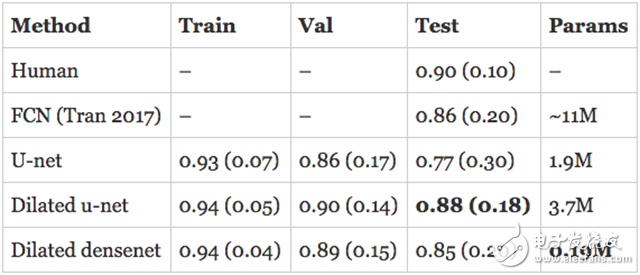
扩张u-net与心内膜上的最新技术水平相当,并超过它在心外膜上的表现。扩张DenseNet紧跟其后,仅有190K个参数。
总结
深度学习模型的表现有时候看起来似乎很神奇,但这是精心设计的结果。即使数据集很小,精心挑选的数据增强方案也可以让深度学习模型更好地一般化。
根据这些想法,创建出了最先进的模型来分割心脏MRI中的右心室。我非常高兴地看到了扩张DenseNet能够在其他图像分割评测上成功运行。
内存高效的扩张DenseNet:密集连接的网络有一个很大的缺点,它需要占用大量的内存。 而TensorFlow的实现却与众不同,它将我们限制在16GB GPU并且一个批次具有3个图像的8个层上。如果切换到之前提出的记忆高效的实现上的话,就可以创建出更深层次的体系架构来。
-
基于深度学习的场景分割算法研究2022-02-12 582
-
深度学习在医学图像分割与病变识别中的应用实战2023-09-04 0
-
利用深度学习分析实现核磁共振图像分割2017-09-22 932
-
混合熵MRI图像多阈值分割2017-12-09 968
-
主动脉夹层分割深度学习模型是如何炼成的?2018-07-17 6085
-
深度学习中图像分割的方法和应用2020-11-27 3176
-
图像分割的方法,包括传统方法和深度学习方法2021-01-08 9315
-
分析总结基于深度神经网络的图像语义分割方法2021-03-19 961
-
基于深度神经网络的图像语义分割方法2021-04-02 1016
-
IFCM脑部MRI图像分割算法的改进设计与应用研究2021-04-18 2342
-
MRI成像左心室轮廓精确分割网络GNNIU2021-05-13 769
-
基于医学影像的中国心脏心室分割方法综述2021-06-26 903
-
浅谈关于深度学习方法的图像分割2021-07-06 2203
-
深度学习中的图像分割2023-05-05 1256
-
深度学习图像语义分割指标介绍2023-10-09 396
全部0条评论

快来发表一下你的评论吧 !
